SQL Server 2014 brachte viele neue Funktionen, auf deren Testen und Verwenden in ihren Umgebungen sich DBAs und Entwickler freuten, wie z. B. den aktualisierbaren gruppierten Columnstore-Index, verzögerte Dauerhaftigkeit und Pufferpoolerweiterungen. Eine Funktion, die nicht oft diskutiert wird, ist die inkrementelle Statistik. Wenn Sie keine Partitionierung verwenden, können Sie diese Funktion nicht implementieren. Aber wenn Sie partitionierte Tabellen in Ihrer Datenbank haben, könnten inkrementelle Statistiken etwas sein, auf das Sie sehnsüchtig gewartet haben.
Hinweis:Benjamin Nevarez hat in seinem Post vom Februar 2014, SQL Server 2014 Incremental Statistics, einige Grundlagen zu inkrementellen Statistiken behandelt. Und obwohl sich seit seinem Beitrag und der Veröffentlichung im April 2014 nicht viel an der Funktionsweise dieser Funktion geändert hat, schien es ein guter Zeitpunkt, um herauszufinden, wie die Aktivierung inkrementeller Statistiken die Wartungsleistung verbessern kann.
Inkrementelle Statistiken werden manchmal als Statistiken auf Partitionsebene bezeichnet, da SQL Server zum ersten Mal automatisch partitionsspezifische Statistiken erstellen kann. Eine der vorherigen Herausforderungen bei der Partitionierung war, dass Sie 1 bis n haben könnten Partitionen für eine Tabelle gab es nur eine (1) Statistik, die die Datenverteilung über alle diese Partitionen darstellte. Sie könnten gefilterte Statistiken für die partitionierte Tabelle erstellen – eine Statistik für jede Partition – um dem Abfrageoptimierer bessere Informationen über die Verteilung der Daten bereitzustellen. Dies war jedoch ein manueller Prozess und erforderte ein Skript, um sie automatisch für jede neue Partition zu erstellen.
In SQL Server 2014 verwenden Sie den STATISTICS_INCREMENTAL Option, damit SQL Server diese Statistiken auf Partitionsebene automatisch erstellt. Diese Statistiken werden jedoch nicht so verwendet, wie Sie vielleicht denken.
Ich habe bereits erwähnt, dass Sie vor 2014 gefilterte Statistiken erstellen konnten, um dem Optimierer bessere Informationen über die Partitionen zu geben. Diese inkrementellen Statistiken? Sie werden derzeit nicht vom Optimierer verwendet. Der Abfrageoptimierer verwendet immer noch nur das Haupthistogramm, das die gesamte Tabelle darstellt. (Ein Beitrag folgt, der dies demonstrieren wird!)
Was ist also der Sinn inkrementeller Statistiken? Wenn Sie davon ausgehen, dass sich nur Daten in der neuesten Partition ändern, aktualisieren Sie idealerweise nur die Statistiken für diese Partition. Sie können dies jetzt mit inkrementellen Statistiken tun – und was passiert, ist, dass die Informationen dann wieder in das Haupthistogramm zusammengeführt werden. Das Histogramm für die gesamte Tabelle wird aktualisiert, ohne dass Sie die gesamte Tabelle durchlesen müssen, um die Statistiken zu aktualisieren, und dies kann bei der Durchführung Ihrer Wartungsaufgaben hilfreich sein.
Einrichtung
Wir beginnen mit der Erstellung einer Partitionsfunktion und eines Schemas und dann einer neuen Tabelle, die wir partitionieren werden. Beachten Sie, dass ich wie in einer Produktionsumgebung eine Dateigruppe für jede Partitionsfunktion erstellt habe. Sie können das Partitionsschema in derselben Dateigruppe erstellen (z. B. PRIMARY ), wenn Sie Ihre Testdatenbank nicht einfach löschen können. Jede Dateigruppe ist außerdem einige GB groß, da wir fast 400 Millionen Zeilen hinzufügen werden.
USE [AdventureWorks2014_Partition]; GO /* add filesgroups */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2015]; /* add files */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2011.ndf', NAME = N'2011', SIZE = 1024MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2012.ndf', NAME = N'2012', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2013.ndf', NAME = N'2013', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2014.ndf', NAME = N'2014', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2015.ndf', NAME = N'2015', SIZE = 2048MB, MAXSIZE = 4096MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2015]; /* create partition function */ CREATE PARTITION FUNCTION [OrderDateRangePFN] ([datetime]) AS RANGE RIGHT FOR VALUES ( '20110101', -- everything in 2011 '20120101', -- everything in 2012 '20130101', -- everything in 2013 '20140101', -- everything in 2014 '20150101' -- everything in 2015 ); GO /* create partition scheme */ CREATE PARTITION SCHEME [OrderDateRangePScheme] AS PARTITION [OrderDateRangePFN] TO ([PRIMARY], [FG2011], [FG2012], [FG2013], [FG2014], [FG2015]); GO /* create the table */ CREATE TABLE [dbo].[Orders] ( [PurchaseOrderID] [int] NOT NULL, [EmployeeID] [int] NULL, [VendorID] [int] NULL, [TaxAmt] [money] NULL, [Freight] [money] NULL, [SubTotal] [money] NULL, [Status] [tinyint] NOT NULL, [RevisionNumber] [tinyint] NULL, [ModifiedDate] [datetime] NULL, [ShipMethodID] [tinyint] NULL, [ShipDate] [datetime] NOT NULL, [OrderDate] [datetime] NOT NULL, [TotalDue] [money] NULL ) ON [OrderDateRangePScheme] (OrderDate);
Bevor wir die Daten hinzufügen, erstellen wir den gruppierten Index und beachten, dass die Syntax den WITH (STATISTICS_INCREMENTAL = ON) enthält Möglichkeit:
/* add the clustered index and enable incremental stats */ ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ( [OrderDate], [PurchaseOrderID] ) WITH (STATISTICS_INCREMENTAL = ON) ON [OrderDateRangePScheme] ([OrderDate]);
Was hier interessant ist, ist, wenn Sie sich die ALTER TABLE ansehen Eintrag in MSDN, enthält er diese Option nicht. Sie finden ihn nur im ALTER INDEX Eintrag… aber das funktioniert. Wenn Sie der Dokumentation buchstabengetreu folgen möchten, würden Sie Folgendes ausführen:
/* add the clustered index and enable incremental stats */ ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ( [OrderDate], [PurchaseOrderID] ) ON [OrderDateRangePScheme] ([OrderDate]); GO ALTER INDEX [OrdersPK] ON [dbo].[Orders] REBUILD WITH (STATISTICS_INCREMENTAL = ON);
Nachdem der gruppierte Index für das Partitionsschema erstellt wurde, laden wir unsere Daten und prüfen dann, wie viele Zeilen pro Partition vorhanden sind (beachten Sie, dass dies über 7 Minuten dauert). Auf meinem Laptop möchten Sie möglicherweise weniger Zeilen hinzufügen, je nachdem, wie viel Speicherplatz (und Zeit) Sie zur Verfügung haben):
/* load some data */
SET NOCOUNT ON;
DECLARE @Loops SMALLINT = 0;
DECLARE @Increment INT = 5000;
WHILE @Loops < 10000 -- adjust this to increase or decrease the number
-- of rows in the table, 10000 = 40 millon rows
BEGIN
INSERT [dbo].[Orders]
( [PurchaseOrderID]
,[EmployeeID]
,[VendorID]
,[TaxAmt]
,[Freight]
,[SubTotal]
,[Status]
,[RevisionNumber]
,[ModifiedDate]
,[ShipMethodID]
,[ShipDate]
,[OrderDate]
,[TotalDue]
)
SELECT
[PurchaseOrderID] + @Increment
, [EmployeeID]
, [VendorID]
, [TaxAmt]
, [Freight]
, [SubTotal]
, [Status]
, [RevisionNumber]
, [ModifiedDate]
, [ShipMethodID]
, [ShipDate]
, [OrderDate]
, [TotalDue]
FROM [Purchasing].[PurchaseOrderHeader];
CHECKPOINT;
SET @Loops = @Loops + 1;
SET @Increment = @Increment + 5000;
END
/* Check to see how much data exists per partition */
SELECT
$PARTITION.[OrderDateRangePFN]([o].[OrderDate]) AS [Partition Number]
, MIN([o].[OrderDate]) AS [Min_Order_Date]
, MAX([o].[OrderDate]) AS [Max_Order_Date]
, COUNT(*) AS [Rows In Partition]
FROM [dbo].[Orders] AS [o]
GROUP BY $PARTITION.[OrderDateRangePFN]([o].[OrderDate])
ORDER BY [Partition Number];
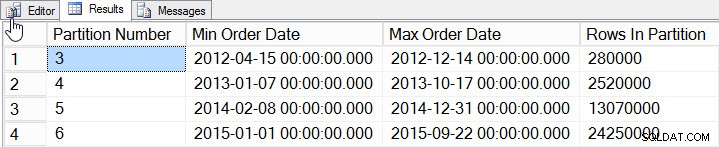 Daten pro Partition
Daten pro Partition
Wir haben Daten für 2012 bis 2015 hinzugefügt, mit deutlich mehr Daten für 2014 und 2015. Sehen wir uns an, wie unsere Statistiken aussehen:
DBCC SHOW_STATISTICS ('dbo.Orders',[OrdersPK]);
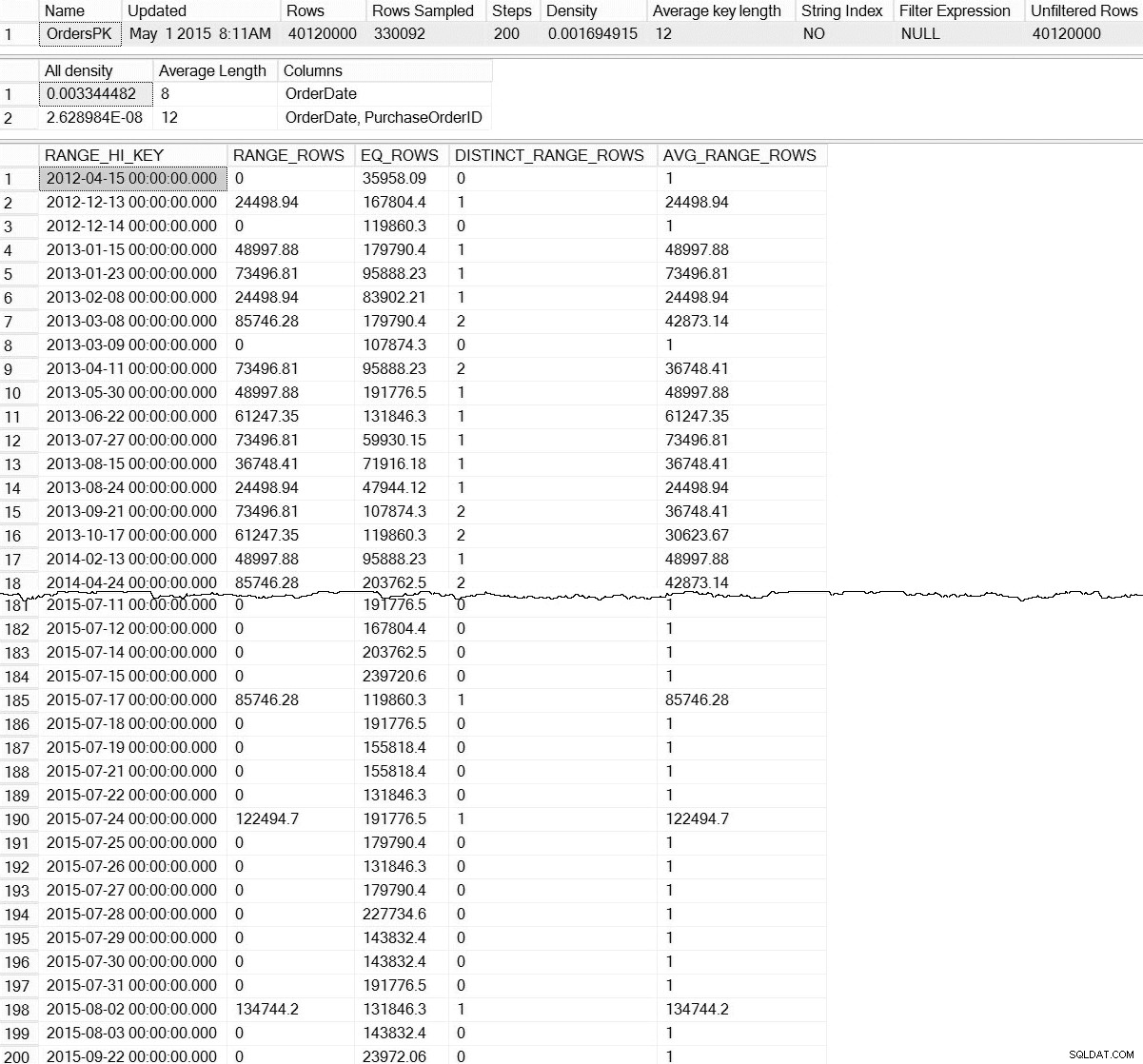 DBCC SHOW_STATISTICS-Ausgabe für dbo.Orders (zum Vergrößern klicken)
DBCC SHOW_STATISTICS-Ausgabe für dbo.Orders (zum Vergrößern klicken)
Mit dem Standard DBCC SHOW_STATISTICS Befehl haben wir keine Informationen über Statistiken auf Partitionsebene. Keine Angst; wir sind nicht völlig dem Untergang geweiht – es gibt eine undokumentierte dynamische Verwaltungsfunktion, sys.dm_db_stats_properties_internal . Denken Sie daran, dass undokumentiert bedeutet, dass es nicht unterstützt wird (es gibt keinen MSDN-Eintrag für das DMF) und dass es jederzeit ohne Warnung von Microsoft geändert werden kann. Das heißt, es ist ein guter Anfang, um sich ein Bild davon zu machen, was für unsere inkrementellen Statistiken vorhanden ist:
SELECT *
FROM [sys].[dm_db_stats_properties_internal](OBJECT_ID('dbo.Orders'),1)
ORDER BY [node_id];
 Histogramminformationen von dm_db_stats_properties_internal (zum Vergrößern klicken)
Histogramminformationen von dm_db_stats_properties_internal (zum Vergrößern klicken)
Das ist viel interessanter. Hier sehen wir den Beweis, dass Statistiken auf Partitionsebene (und mehr) existieren. Da dieses DMF nicht dokumentiert ist, müssen wir etwas interpretieren. Für heute konzentrieren wir uns auf die ersten sieben Zeilen in der Ausgabe, wobei die erste Zeile das Histogramm für die gesamte Tabelle darstellt (beachten Sie die rows Wert von 40 Millionen), und die nachfolgenden Zeilen stellen die Histogramme für jede Partition dar. Leider ist die partition_number Der Wert in diesem Histogramm stimmt nicht mit der Partitionsnummer aus sys.dm_db_index_physical_stats überein für die rechtsbasierte Partitionierung (es korreliert richtig für die linksbasierte Partitionierung). Beachten Sie auch, dass diese Ausgabe auch den last_updated enthält und modification_counter Spalten, die bei der Fehlerbehebung hilfreich sind, und es kann verwendet werden, um Wartungsskripts zu entwickeln, die Statistiken basierend auf Alter oder Zeilenänderungen intelligent aktualisieren.
Minimierung des Wartungsaufwands
Der Hauptwert der inkrementellen Statistik ist derzeit die Möglichkeit, Statistiken für eine Partition zu aktualisieren und diese mit dem Histogramm auf Tabellenebene zusammenzuführen, ohne die Statistik für die gesamte Tabelle aktualisieren zu müssen (und daher die gesamte Tabelle zu lesen). Um dies in Aktion zu sehen, aktualisieren wir zuerst die Statistiken für die Partition, die die Daten von 2015 enthält, Partition 5, und wir zeichnen die benötigte Zeit auf und erstellen einen Schnappschuss der sys.dm_io_virtual_file_stats DMF vorher und nachher, um zu sehen, wie viel E/A auftritt:
SET STATISTICS TIME ON; SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #FirstCapture FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; UPDATE STATISTICS [dbo].[Orders]([OrdersPK]) WITH RESAMPLE ON PARTITIONS(6); GO SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #SecondCapture FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; SELECT f.file_id, f.name, f.physical_name, (s.num_of_bytes_read - f.num_of_bytes_read)/1024 MB_Read, (s.num_of_bytes_written - f.num_of_bytes_written)/1024 MB_Written FROM #FirstCapture AS f INNER JOIN #SecondCapture AS s ON f.database_id = s.database_id AND f.file_id = s.file_id;
Ausgabe:
SQL Server-Ausführungszeiten:CPU-Zeit =203 ms, verstrichene Zeit =240 ms.
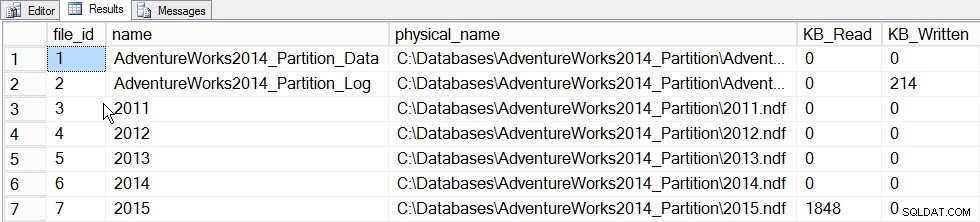 File_stats-Daten nach dem Aktualisieren einer Partition
File_stats-Daten nach dem Aktualisieren einer Partition
Wenn wir uns die sys.dm_db_stats_properties_internal ansehen Ausgabe sehen wir, dass last_updated sowohl für das Histogramm 2015 als auch für das Histogramm auf Tabellenebene geändert (sowie einige andere Knoten, die später untersucht werden):
 Aktualisierte Histogramminformationen von dm_db_stats_properties_internal
Aktualisierte Histogramminformationen von dm_db_stats_properties_internal
Jetzt aktualisieren wir die Statistiken mit einem FULLSCAN für die Tabelle, und wir werden file_stats davor und danach noch einmal schnappen:
SET STATISTICS TIME ON; SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #FirstCapture2 FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; UPDATE STATISTICS [dbo].[Orders]([OrdersPK]) WITH FULLSCAN SELECT fs.database_id, fs.file_id, mf.name, mf.physical_name, fs.num_of_bytes_read, fs.num_of_bytes_written INTO #SecondCapture2 FROM sys.dm_io_virtual_file_stats(DB_ID(), NULL) AS fs INNER JOIN sys.master_files AS mf ON fs.database_id = mf.database_id AND fs.file_id = mf.file_id; SELECT f.file_id, f.name, f.physical_name, (s.num_of_bytes_read - f.num_of_bytes_read)/1024 MB_Read, (s.num_of_bytes_written - f.num_of_bytes_written)/1024 MB_Written FROM #FirstCapture2 AS f INNER JOIN #SecondCapture2 AS s ON f.database_id = s.database_id AND f.file_id = s.file_id;
Ausgabe:
SQL Server-Ausführungszeiten:CPU-Zeit =12720 ms, verstrichene Zeit =13646 ms
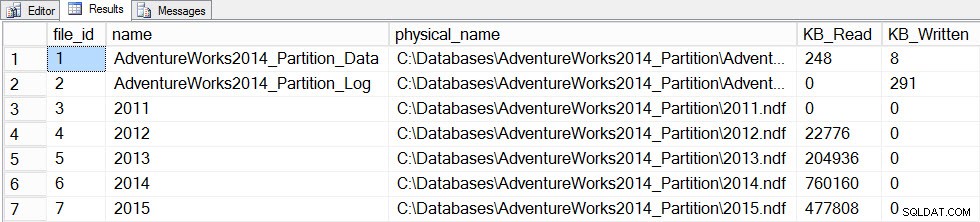 Dateistatistikdaten nach Aktualisierung mit einem vollständigen Scan
Dateistatistikdaten nach Aktualisierung mit einem vollständigen Scan
Das Update dauerte deutlich länger (13 Sekunden gegenüber ein paar hundert Millisekunden) und erzeugte viel mehr I/O. Wenn wir sys.dm_db_stats_properties_internal überprüfen wieder finden wir das last_updated geändert für alle Histogramme:
 Histogramminformationen von dm_db_stats_properties_internal nach einem vollständigen Scan
Histogramminformationen von dm_db_stats_properties_internal nach einem vollständigen Scan
Zusammenfassung
Obwohl inkrementelle Statistiken noch nicht vom Abfrageoptimierer verwendet werden, um Informationen über jede Partition bereitzustellen, bieten sie einen Leistungsvorteil beim Verwalten von Statistiken für partitionierte Tabellen. Wenn Statistiken nur für ausgewählte Partitionen aktualisiert werden müssen, können nur diese aktualisiert werden. Die neuen Informationen werden dann mit dem Histogramm auf Tabellenebene zusammengeführt, wodurch der Optimierer aktuellere Informationen erhält, ohne dass die Kosten für das Lesen der gesamten Tabelle anfallen. Wir hoffen, dass diese Statistiken auf Partitionsebene in Zukunft werden vom Optimierer verwendet werden. Bleiben Sie dran…