In Bezug auf Ihren Kommentar:
@MarcB die Datenbank ist normalisiert, der CSV-String kommt von der Benutzeroberfläche. "Get me data for the following people:101.202.303"
Diese Antwort konzentriert sich nur auf die durch ein Komma getrennten Zahlen. Denn wie sich herausstellt, haben Sie nicht einmal von FIND_IN_SET gesprochen immerhin.
Ja, Sie können erreichen, was Sie wollen. Sie erstellen eine vorbereitete Anweisung, die eine Zeichenfolge als Parameter akzeptiert, wie in dieser aktuellen Antwort
von mir. Sehen Sie sich in dieser Antwort den zweiten Block an, der CREATE PROCEDURE anzeigt und sein zweiter Parameter, der eine Zeichenfolge wie (1,2,3) akzeptiert . Ich werde gleich auf diesen Punkt zurückkommen.
Nicht, dass Sie es sehen müssen, @spraff, aber andere könnten es tun. Die Mission besteht darin, den type zu erhalten !=ALL und possible_keys und keys von Explain, nicht null anzuzeigen, wie Sie in Ihrem zweiten Block gezeigt haben. Allgemeine Informationen zu diesem Thema finden Sie im Artikel Understanding EXPLAIN-Ausgabe
und die MySQL-Handbuchseite mit dem Titel EXPLAIN Zusätzliche Informationen
.
Nun zurück zu (1,2,3) Referenz oben. Wir wissen aus Ihrem Kommentar und Ihrer zweiten Explain-Ausgabe in Ihrer Frage, dass sie die folgenden gewünschten Bedingungen erfüllt:
- type =range (und insbesondere nicht ALL) . Siehe hierzu die oben stehenden Dokumente.
- Schlüssel ist nicht null
Dies sind genau die Bedingungen, die Sie in Ihrer zweiten Explain-Ausgabe und der Ausgabe haben, die mit der folgenden Abfrage angezeigt werden kann:
explain
select * from ratings where id in (2331425, 430364, 4557546, 2696638, 4510549, 362832, 2382514, 1424071, 4672814, 291859, 1540849, 2128670, 1320803, 218006, 1827619, 3784075, 4037520, 4135373, ... use your imagination ..., ..., 4369522, 3312835);
wo ich 999 Werte in diesem in habe Klauselliste. Das ist ein Beispiel aus dieser Antwort
von mir in Anhang D generiert dann eine solche zufällige CSV-Zeichenfolge, umgeben von öffnenden und schließenden Klammern.
Und beachten Sie die folgende Explain-Ausgabe für dieses 999-Element in der folgenden Klausel:

Ziel erreicht. Sie erreichen dies mit einer gespeicherten Prozedur ähnlich der, die ich zuvor in diesem Link
erwähnt habe mit einem PREPARED STATEMENT
(und diese Dinge verwenden concat() gefolgt von einem EXECUTE ).
Der Index wird verwendet, ein Tablescan (dh schlecht) wird nicht erlebt. Weitere Lektüren sind The range Join Type
, jede Referenz, die Sie auf MySQL's Cost-Based Optimizer (CBO) finden können, diese Antwort
von vladr, obwohl veraltet, mit einem Auge auf ANALYZE TABLE
teilweise, insbesondere nach wesentlichen Datenänderungen. Beachten Sie, dass die Ausführung von ANALYZE bei extrem großen Datensätzen viel Zeit in Anspruch nehmen kann. Manchmal viele viele Stunden.
SQL-Injection-Angriffe:
Die Verwendung von Zeichenfolgen, die an gespeicherte Prozeduren übergeben werden, ist ein Angriffsvektor für SQL-Injection-Angriffe. Es müssen Vorkehrungen getroffen werden, um dies zu verhindern, wenn vom Benutzer bereitgestellte Daten verwendet werden. Wenn Ihre Routine auf Ihre eigenen von Ihrem System generierten IDs angewendet wird, sind Sie auf der sicheren Seite. Beachten Sie jedoch, dass SQL-Injection-Angriffe der zweiten Ebene auftreten, wenn Daten durch Routinen eingefügt wurden, die diese Daten bei einer vorherigen Einfügung oder Aktualisierung nicht bereinigt haben. Angriffe, die zuvor über Daten ausgeführt und später verwendet wurden (eine Art Zeitbombe).
Diese Antwort ist also Fertig größtenteils.
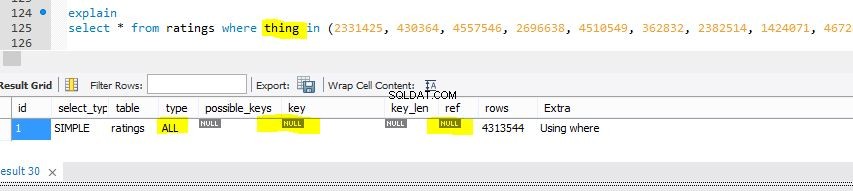
Das Folgende ist eine Ansicht derselben Tabelle mit einer geringfügigen Änderung, um zu zeigen, was für ein gefürchteter Tablescan würde wie in der vorherigen Abfrage aussehen (aber gegen eine nicht indizierte Spalte namens thing ).
Schauen Sie sich unsere aktuelle Tabellendefinition an:
CREATE TABLE `ratings` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`thing` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5046214 DEFAULT CHARSET=utf8;
select min(id), max(id),count(*) as theCount from ratings;
+---------+---------+----------+
| min(id) | max(id) | theCount |
+---------+---------+----------+
| 1 | 5046213 | 4718592 |
+---------+---------+----------+
Beachten Sie, dass die Spalte thing war zuvor eine nullable int-Spalte.
update ratings set thing=id where id<1000000;
update ratings set thing=id where id>=1000000 and id<2000000;
update ratings set thing=id where id>=2000000 and id<3000000;
update ratings set thing=id where id>=3000000 and id<4000000;
update ratings set thing=id where id>=4000000 and id<5100000;
select count(*) from ratings where thing!=id;
-- 0 rows
ALTER TABLE ratings MODIFY COLUMN thing int not null;
-- current table definition (after above ALTER):
CREATE TABLE `ratings` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`thing` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5046214 DEFAULT CHARSET=utf8;
Und dann das Explain, das ein Tablescan ist (gegen die Spalte thing ):