Jahrelang basierte die MySQL-Replikation auf binären Protokollereignissen – alles, was ein Slave wusste, war das genaue Ereignis und die genaue Position, die er gerade vom Master gelesen hatte. Jede einzelne Transaktion von einem Master kann in verschiedenen Binärprotokollen und an verschiedenen Positionen in diesen Protokollen geendet haben. Es war eine einfache Lösung mit Einschränkungen – komplexere Topologieänderungen könnten erfordern, dass ein Administrator die Replikation auf den beteiligten Hosts stoppt. Oder diese Änderungen könnten einige andere Probleme verursachen, z. B. konnte ein Slave nicht ohne zeitaufwendigen Neuaufbauprozess in der Replikationskette verschoben werden (wir konnten die Replikation nicht einfach von A -> B -> C auf A -> C ändern -> B, ohne die Replikation auf B und C zu stoppen). Wir alle mussten diese Einschränkungen umgehen, während wir von einer globalen Transaktionskennung träumten.
GTID wurde zusammen mit MySQL 5.6 eingeführt und brachte einige wesentliche Änderungen in der Arbeitsweise von MySQL mit sich. Zunächst einmal hat jede Transaktion eine eindeutige Kennung, die sie auf jedem Server auf die gleiche Weise identifiziert. Es ist nicht mehr wichtig, an welcher Binärlog-Position eine Transaktion aufgezeichnet wurde, alles, was Sie wissen müssen, ist die GTID:‚966073f3-b6a4-11e4-af2c-080027880ca6:4‘. GTID besteht aus zwei Teilen – der eindeutigen Kennung eines Servers, auf dem eine Transaktion zuerst ausgeführt wurde, und einer Sequenznummer. Im obigen Beispiel können wir sehen, dass die Transaktion vom Server mit der server_uuid „966073f3-b6a4-11e4-af2c-080027880ca6“ ausgeführt wurde und dass es sich um die vierte Transaktion handelt, die dort ausgeführt wird. Diese Informationen reichen aus, um komplexe Topologieänderungen durchzuführen – MySQL weiß, welche Transaktionen ausgeführt wurden und weiß daher, welche Transaktionen als nächstes ausgeführt werden müssen. Vergessen Sie binäre Protokolle, es ist alles in der GTID.
Wo finden Sie also GTIDs? Sie finden sie an zwei Stellen. Auf einem Slave finden Sie unter „show slave status;“ zwei Spalten:Retrieved_Gtid_Set und Executed_Gtid_Set. Die erste umfasst GTIDs, die vom Master per Replikation abgerufen wurden, die zweite informiert über alle Transaktionen, die auf einem bestimmten Host ausgeführt wurden - sowohl per Replikation als auch lokal ausgeführt.
Einfache Einrichtung eines Replikations-Clusters
Die Bereitstellung des MySQL-Replikationsclusters ist in ClusterControl sehr einfach (Sie können es kostenlos testen). Die einzige Voraussetzung ist, dass auf alle Hosts, auf denen Sie MySQL-Knoten bereitstellen werden, von der ClusterControl-Instanz über eine passwortlose SSH-Verbindung zugegriffen werden kann.
Wenn die Konnektivität vorhanden ist, können Sie einen Cluster bereitstellen, indem Sie die Option „Bereitstellen“ verwenden. Wenn das Assistentenfenster geöffnet ist, müssen Sie einige Entscheidungen treffen – was möchten Sie tun? Einen neuen Cluster bereitstellen? Stellen Sie einen Postgresql-Knoten bereit oder importieren Sie einen vorhandenen Cluster.
Wir möchten einen neuen Cluster bereitstellen. Anschließend wird uns der folgende Bildschirm angezeigt, in dem wir entscheiden müssen, welche Art von Cluster wir bereitstellen möchten. Lassen Sie uns die Replikation auswählen und dann die erforderlichen Details zur SSH-Konnektivität übergeben.
Wenn Sie fertig sind, klicken Sie auf Weiter. Dieses Mal müssen wir entscheiden, welchen MySQL-Anbieter wir verwenden möchten, welche Version und einige Konfigurationseinstellungen, darunter unter anderem das Passwort für das Root-Konto in MySQL.
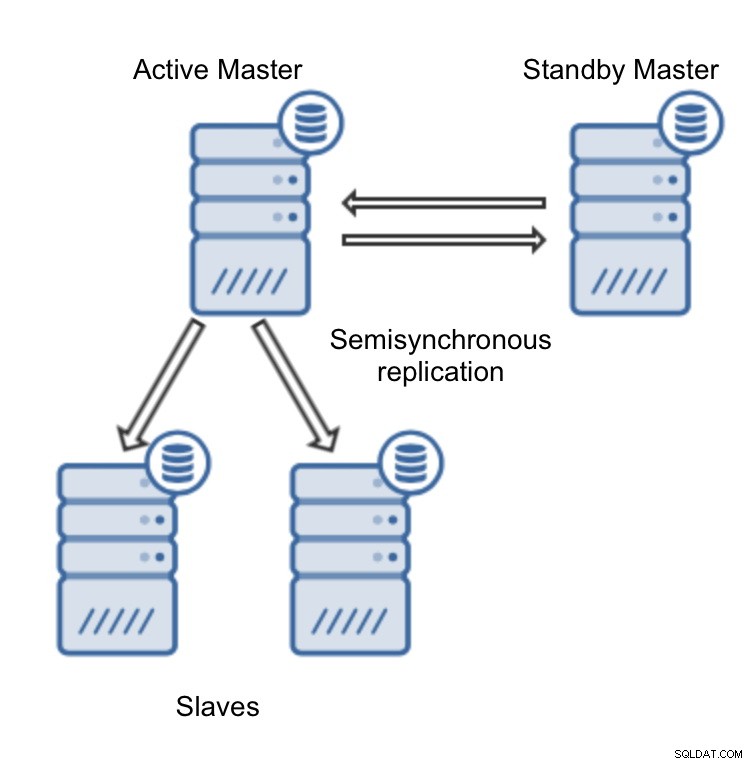
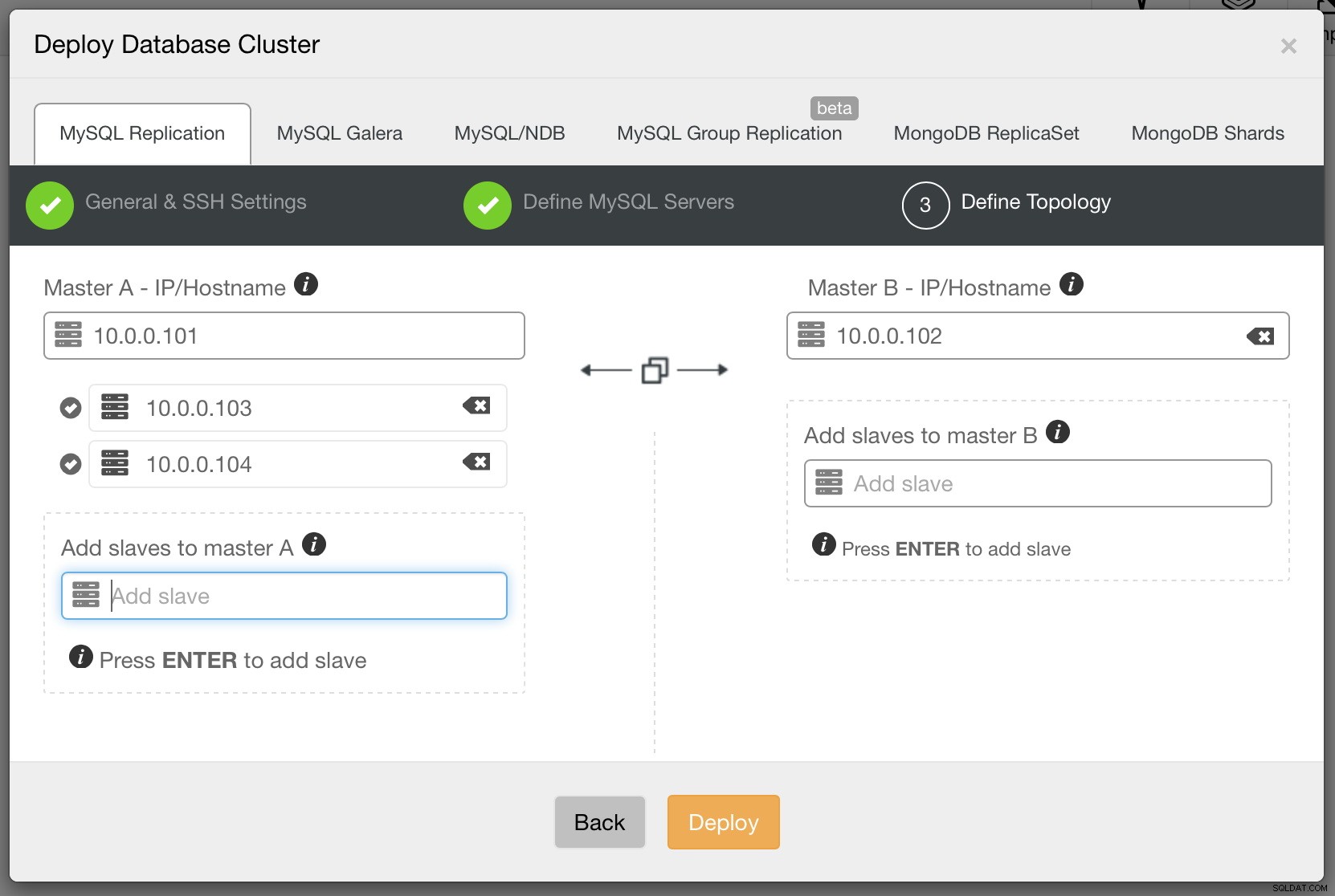
Schließlich müssen wir uns für die Replikationstopologie entscheiden – Sie können entweder ein typisches Master-Slave-Setup verwenden oder ein komplexeres, aktives Standby-Master-Master-Paar (+ Slaves, falls Sie sie hinzufügen möchten) erstellen. Sobald Sie fertig sind, klicken Sie einfach auf „Bereitstellen“ und in wenigen Minuten sollte Ihr Cluster bereitgestellt sein.
Sobald dies erledigt ist, sehen Sie Ihren Cluster in der Clusterliste der Benutzeroberfläche von ClusterControl.
Wenn die Replikation läuft, können wir uns genauer ansehen, wie GTID funktioniert.
Fehlerhafte Transaktionen – wo liegt das Problem?
Wie wir zu Beginn dieses Beitrags erwähnt haben, haben GTIDs die Art und Weise, wie Menschen über die MySQL-Replikation denken sollten, erheblich verändert. Es geht um Gewohnheiten. Nehmen wir an, aus irgendeinem Grund hat eine Anwendung einen Schreibvorgang auf einem der Slaves ausgeführt. Es hätte nicht passieren dürfen, aber überraschenderweise passiert es die ganze Zeit. Infolgedessen wird die Replikation mit einem doppelten Schlüsselfehler beendet. Es gibt mehrere Möglichkeiten, mit einem solchen Problem umzugehen. Eine davon wäre, die fehlerhafte Zeile zu löschen und die Replikation neu zu starten. Eine andere wäre, das Binärprotokollereignis zu überspringen und dann die Replikation neu zu starten.
STOP SLAVE SQL_THREAD; SET GLOBAL sql_slave_skip_counter = 1; START SLAVE SQL_THREAD;Beide Wege sollten die Replikation wieder zum Laufen bringen, aber sie können Datendrift einführen, daher ist es notwendig, daran zu denken, dass die Slave-Konsistenz nach einem solchen Ereignis überprüft werden sollte (pt-table-checksum und pt-table-sync funktionieren hier gut).
Wenn bei der Verwendung von GTID ein ähnliches Problem auftritt, werden Sie einige Unterschiede feststellen. Das Löschen der problematischen Zeile scheint das Problem zu beheben, die Replikation sollte beginnen können. Die andere Methode mit sql_slave_skip_counter funktioniert überhaupt nicht – sie gibt einen Fehler zurück. Denken Sie daran, dass es jetzt nicht um Binlog-Ereignisse geht, sondern nur darum, ob GTID ausgeführt wird oder nicht.
Warum scheint das Löschen der Zeile das Problem nur zu beheben? Eines der wichtigsten Dinge, die Sie in Bezug auf GTID beachten sollten, ist, dass ein Slave beim Verbinden mit dem Master prüft, ob ihm Transaktionen fehlen, die auf dem Master ausgeführt wurden. Diese werden fehlerhafte Transaktionen genannt. Wenn ein Slave solche Transaktionen findet, führt er sie aus. Nehmen wir an, wir haben folgendes SQL ausgeführt, um eine anstößige Zeile zu löschen:
DELETE FROM mytable WHERE id=100;Lassen Sie uns den Slave-Status anzeigen:
Master_UUID: 966073f3-b6a4-11e4-af2c-080027880ca6
Retrieved_Gtid_Set: 966073f3-b6a4-11e4-af2c-080027880ca6:1-29
Executed_Gtid_Set: 84d15910-b6a4-11e4-af2c-080027880ca6:1,
966073f3-b6a4-11e4-af2c-080027880ca6:1-29,Und sehen Sie, woher 84d15910-b6a4-11e4-af2c-080027880ca6:1 kommt:
mysql> SHOW VARIABLES LIKE 'server_uuid'\G
*************************** 1. row ***************************
Variable_name: server_uuid
Value: 84d15910-b6a4-11e4-af2c-080027880ca6
1 row in set (0.00 sec)Wie Sie sehen können, haben wir 29 Transaktionen, die vom Master kamen, UUID von 966073f3-b6a4-11e4-af2c-080027880ca6 und eine, die lokal ausgeführt wurde. Nehmen wir an, dass wir irgendwann ein Failover durchführen und der Master (966073f3-b6a4-11e4-af2c-080027880ca6) zum Slave wird. Es überprüft seine Liste der ausgeführten GTIDs und findet diese nicht:84d15910-b6a4-11e4-af2c-080027880ca6:1. Als Ergebnis wird das zugehörige SQL ausgeführt:
DELETE FROM mytable WHERE id=100;Damit haben wir nicht gerechnet… Wenn in der Zwischenzeit das Binlog mit dieser Transaktion auf dem alten Slave gelöscht wird, dann wird sich der neue Slave nach dem Failover beschweren:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'Wie erkennt man fehlerhafte Transaktionen?
MySQL bietet zwei Funktionen, die sehr praktisch sind, wenn Sie GTID-Sets auf verschiedenen Hosts vergleichen möchten.
GTID_SUBSET() nimmt zwei GTID-Sätze und prüft, ob der erste Satz ein Untersatz des zweiten ist.
Nehmen wir an, wir haben folgenden Zustand.
Meister:
mysql> show master status\G
*************************** 1. row ***************************
File: binlog.000002
Position: 160205927
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set: 8a6962d2-b907-11e4-bebc-080027880ca6:1-153,
9b09b44a-b907-11e4-bebd-080027880ca6:1,
ab8f5793-b907-11e4-bebd-080027880ca6:1-2
1 row in set (0.00 sec)Sklave:
mysql> show slave status\G
[...]
Retrieved_Gtid_Set: 8a6962d2-b907-11e4-bebc-080027880ca6:1-153,
9b09b44a-b907-11e4-bebd-080027880ca6:1
Executed_Gtid_Set: 8a6962d2-b907-11e4-bebc-080027880ca6:1-153,
9b09b44a-b907-11e4-bebd-080027880ca6:1,
ab8f5793-b907-11e4-bebd-080027880ca6:1-4Wir können überprüfen, ob der Slave irgendwelche fehlerhaften Transaktionen hat, indem wir das folgende SQL ausführen:
mysql> SELECT GTID_SUBSET('8a6962d2-b907-11e4-bebc-080027880ca6:1-153,ab8f5793-b907-11e4-bebd-080027880ca6:1-4', '8a6962d2-b907-11e4-bebc-080027880ca6:1-153, 9b09b44a-b907-11e4-bebd-080027880ca6:1, ab8f5793-b907-11e4-bebd-080027880ca6:1-2') as is_subset\G
*************************** 1. row ***************************
is_subset: 0
1 row in set (0.00 sec)Sieht so aus, als ob es fehlerhafte Transaktionen gibt. Wie identifizieren wir sie? Wir können eine andere Funktion verwenden, GTID_SUBTRACT()
mysql> SELECT GTID_SUBTRACT('8a6962d2-b907-11e4-bebc-080027880ca6:1-153,ab8f5793-b907-11e4-bebd-080027880ca6:1-4', '8a6962d2-b907-11e4-bebc-080027880ca6:1-153, 9b09b44a-b907-11e4-bebd-080027880ca6:1, ab8f5793-b907-11e4-bebd-080027880ca6:1-2') as mising\G
*************************** 1. row ***************************
mising: ab8f5793-b907-11e4-bebd-080027880ca6:3-4
1 row in set (0.01 sec)Unsere fehlenden GTIDs sind ab8f5793-b907-11e4-bebd-080027880ca6:3-4 – diese Transaktionen wurden auf dem Slave ausgeführt, aber nicht auf dem Master.
Wie kann man Probleme lösen, die durch fehlerhafte Transaktionen verursacht wurden?
Es gibt zwei Möglichkeiten:Leere Transaktionen einfügen oder Transaktionen aus dem GTID-Verlauf ausschließen.
Um leere Transaktionen einzufügen, können wir die folgende SQL verwenden:
mysql> SET gtid_next='ab8f5793-b907-11e4-bebd-080027880ca6:3';
Query OK, 0 rows affected (0.01 sec)mysql> begin ; commit;
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.01 sec)mysql> SET gtid_next='ab8f5793-b907-11e4-bebd-080027880ca6:4';
Query OK, 0 rows affected (0.00 sec)mysql> begin ; commit;
Query OK, 0 rows affected (0.00 sec)
Query OK, 0 rows affected (0.01 sec)mysql> SET gtid_next=automatic;
Query OK, 0 rows affected (0.00 sec)Dies muss auf jedem Host in der Replikationstopologie ausgeführt werden, auf dem diese GTIDs nicht ausgeführt werden. Wenn der Master verfügbar ist, können Sie diese Transaktionen dort einfügen und sie in der Kette nach unten replizieren lassen. Wenn der Master nicht verfügbar ist (z. B. abgestürzt), müssen diese leeren Transaktionen auf jedem Slave ausgeführt werden. Oracle hat ein Tool namens mysqlslavetrx entwickelt, das diesen Prozess automatisieren soll.
Ein anderer Ansatz besteht darin, die GTIDs aus dem Verlauf zu entfernen:
Sklave stoppen:
mysql> STOP SLAVE;Executed_Gtid_Set auf dem Slave ausgeben:
mysql> SHOW MASTER STATUS\GGTID-Info zurücksetzen:
RESET MASTER;Setzen Sie GTID_PURGED auf einen korrekten GTID-Satz. basierend auf Daten von SHOW MASTER STATUS. Sie sollten fehlerhafte Transaktionen aus dem Satz ausschließen.
SET GLOBAL GTID_PURGED='8a6962d2-b907-11e4-bebc-080027880ca6:1-153, 9b09b44a-b907-11e4-bebd-080027880ca6:1, ab8f5793-b907-11e4-bebd-080027880ca6:1-2';Slave starten.
mysql> START SLAVE\GIn jedem Fall sollten Sie die Konsistenz Ihrer Slaves mit pt-table-checksum und pt-table-sync (falls erforderlich) überprüfen - fehlerhafte Transaktionen können zu einer Datendrift führen.
Failover in ClusterControl
Ab Version 1.4 hat ClusterControl seine Failover-Behandlungsprozesse für die MySQL-Replikation verbessert. Sie können immer noch einen manuellen Masterwechsel durchführen, indem Sie einen der Slaves zum Master hochstufen. Die restlichen Slaves werden dann auf den neuen Master umgeschaltet. Ab Version 1.4 verfügt ClusterControl auch über die Fähigkeit, bei Ausfall des Masters ein vollautomatisches Failover durchzuführen. Wir haben es ausführlich in einem Blogbeitrag behandelt, der ClusterControl und automatisiertes Failover beschreibt. Wir möchten noch eine Funktion erwähnen, die direkt mit dem Thema dieses Beitrags zusammenhängt.
Standardmäßig führt ClusterControl das Failover auf „sichere Weise“ durch – zum Zeitpunkt des Failovers (oder des Switchovers, wenn es der Benutzer ist, der einen Master-Switch ausgeführt hat), wählt ClusterControl einen Master-Kandidaten aus und überprüft dann, ob dieser Knoten keine fehlerhaften Transaktionen hat was sich auf die Replikation auswirken würde, sobald sie zum Master befördert wird. Wenn eine fehlerhafte Transaktion erkannt wird, stoppt ClusterControl den Failover-Prozess und der Master-Kandidat wird nicht zu einem neuen Master befördert.
Wenn Sie zu 100 % sicher sein möchten, dass ClusterControl einen neuen Master fördert, selbst wenn einige Probleme (wie fehlerhafte Transaktionen) erkannt werden, können Sie dies mit der Einstellung replication_stop_on_error=0 in der cmon-Konfiguration tun. Wie wir besprochen haben, kann dies natürlich zu Problemen mit der Replikation führen - Slaves können anfangen, nach einem binären Log-Ereignis zu fragen, das nicht mehr verfügbar ist.
Um solche Fälle zu handhaben, haben wir experimentelle Unterstützung für den Wiederaufbau von Sklaven hinzugefügt. Wenn Sie replication_auto_rebuild_slave=1 in der cmon-Konfiguration setzen und Ihr Slave mit dem folgenden Fehler in MySQL als ausgefallen markiert wird, versucht ClusterControl, den Slave mit Daten vom Master neu zu erstellen:
Schwerer Fehler 1236 vom Master beim Lesen von Daten aus dem Binärlog:'Der Slave verbindet sich mit CHANGE MASTER TO MASTER_AUTO_POSITION =1, aber der Master hat Binärlogs gelöscht, die GTIDs enthalten, die der Slave benötigt.'
Eine solche Einstellung ist möglicherweise nicht immer geeignet, da der Wiederherstellungsprozess eine erhöhte Last auf dem Master verursacht. Es kann auch sein, dass Ihr Datensatz sehr groß ist und ein regelmäßiger Neuaufbau nicht möglich ist - deshalb ist dieses Verhalten standardmäßig deaktiviert.