Die Replikation ist eine der gängigsten Methoden, um Hochverfügbarkeit für MySQL und MariaDB zu erreichen. Es ist durch das Hinzufügen von GTIDs viel robuster geworden und wird von Tausenden und Abertausenden von Benutzern gründlich getestet. Die MySQL-Replikation ist jedoch keine „set and forget“-Eigenschaft, sie muss auf potenzielle Probleme überwacht und gewartet werden, damit sie in gutem Zustand bleibt. In diesem Blogbeitrag möchten wir einige Tipps und Tricks zur Wartung, Fehlerbehebung und Behebung von Problemen mit der MySQL-Replikation teilen.
Wie kann man feststellen, ob die MySQL-Replikation in einem guten Zustand ist?
Dies ist zweifellos die wichtigste Fähigkeit, die jeder besitzen muss, der sich um die Einrichtung einer MySQL-Replikation kümmert. Werfen wir einen Blick darauf, wo Sie nach Informationen zum Status der Replikation suchen können. Es gibt einen kleinen Unterschied zwischen MySQL und MariaDB und wir werden auch darauf eingehen.
Slave-Status anzeigen
Dies ist zweifellos die gebräuchlichste Methode, um den Replikationsstatus auf einem Slave-Host zu überprüfen - es ist seit jeher bei uns und normalerweise der erste Ort, an den wir gehen, wenn wir vermuten, dass es ein Problem mit der Replikation gibt.
mysql> SHOW SLAVE STATUS\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.101
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000002
Read_Master_Log_Pos: 767658564
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 405
Relay_Master_Log_File: binlog.000002
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 0
Last_Error:
Skip_Counter: 0
Exec_Master_Log_Pos: 767658564
Relay_Log_Space: 606
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: 0
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 5d1e2227-07c6-11e7-8123-080027495a77
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp:
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-394233
Auto_Position: 1
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)Einige Details können sich zwischen MySQL und MariaDB unterscheiden, aber der Großteil des Inhalts wird gleich aussehen. Änderungen werden im GTID-Abschnitt sichtbar, da MySQL und MariaDB dies anders machen. Aus SHOW SLAVE STATUS können Sie einige Informationen ableiten - welcher Master verwendet wird, welcher Benutzer und welcher Port verwendet wird, um sich mit dem Master zu verbinden. Wir haben einige Daten über die aktuelle Position des Binärlogs (nicht mehr so wichtig, da wir GTID verwenden und Binlogs vergessen können) und den Status von SQL- und I/O-Replikationsthreads. Dann können Sie sehen, ob und wie die Filterung konfiguriert ist. Sie können auch einige Informationen zu Fehlern, Replikationsverzögerung, SSL-Einstellungen und GTID finden. Das obige Beispiel stammt von einem MySQL 5.7-Slave, der sich in einem fehlerfreien Zustand befindet. Sehen wir uns ein Beispiel an, bei dem die Replikation unterbrochen ist.
MariaDB [test]> show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.0.0.104
Master_User: rpl_user
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: binlog.000003
Read_Master_Log_Pos: 636
Relay_Log_File: relay-bin.000002
Relay_Log_Pos: 765
Relay_Master_Log_File: binlog.000003
Slave_IO_Running: Yes
Slave_SQL_Running: No
Replicate_Do_DB:
Replicate_Ignore_DB:
Replicate_Do_Table:
Replicate_Ignore_Table:
Replicate_Wild_Do_Table:
Replicate_Wild_Ignore_Table:
Last_Errno: 1032
Last_Error: Could not execute Update_rows_v1 event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000003, end_log_pos 609
Skip_Counter: 0
Exec_Master_Log_Pos: 480
Relay_Log_Space: 1213
Until_Condition: None
Until_Log_File:
Until_Log_Pos: 0
Master_SSL_Allowed: No
Master_SSL_CA_File:
Master_SSL_CA_Path:
Master_SSL_Cert:
Master_SSL_Cipher:
Master_SSL_Key:
Seconds_Behind_Master: NULL
Master_SSL_Verify_Server_Cert: No
Last_IO_Errno: 0
Last_IO_Error:
Last_SQL_Errno: 1032
Last_SQL_Error: Could not execute Update_rows_v1 event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000003, end_log_pos 609
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_SSL_Crl:
Master_SSL_Crlpath:
Using_Gtid: Slave_Pos
Gtid_IO_Pos: 0-1-73243
Replicate_Do_Domain_Ids:
Replicate_Ignore_Domain_Ids:
Parallel_Mode: conservative
1 row in set (0.00 sec)Dieses Beispiel stammt aus MariaDB 10.1, Sie können Änderungen am Ende der Ausgabe sehen, damit es mit MariaDB-GTIDs funktioniert. Wichtig für uns ist der Fehler - man sieht, dass im SQL-Thread etwas nicht stimmt:
Last_SQL_Error: Could not execute Update_rows_v1 event on table test.tab; Can't find record in 'tab', Error_code: 1032; handler error HA_ERR_KEY_NOT_FOUND; the event's master log binlog.000003, end_log_pos 609Wir werden dieses spezielle Problem später besprechen, für jetzt reicht es aus, dass Sie sehen, wie Sie mit SHOW SLAVE STATUS überprüfen können, ob es Fehler in der Replikation gibt.
Eine weitere wichtige Information, die von SHOW SLAVE STATUS kommt, ist – wie stark unser Slave lagg. Sie können dies in der Spalte „Seconds_Behind_Master“ überprüfen. Diese Metrik ist besonders wichtig, wenn Sie wissen, dass Ihre Anwendung in Bezug auf veraltete Lesevorgänge empfindlich ist.
In ClusterControl können Sie diese Daten im Bereich „Übersicht“ nachverfolgen:
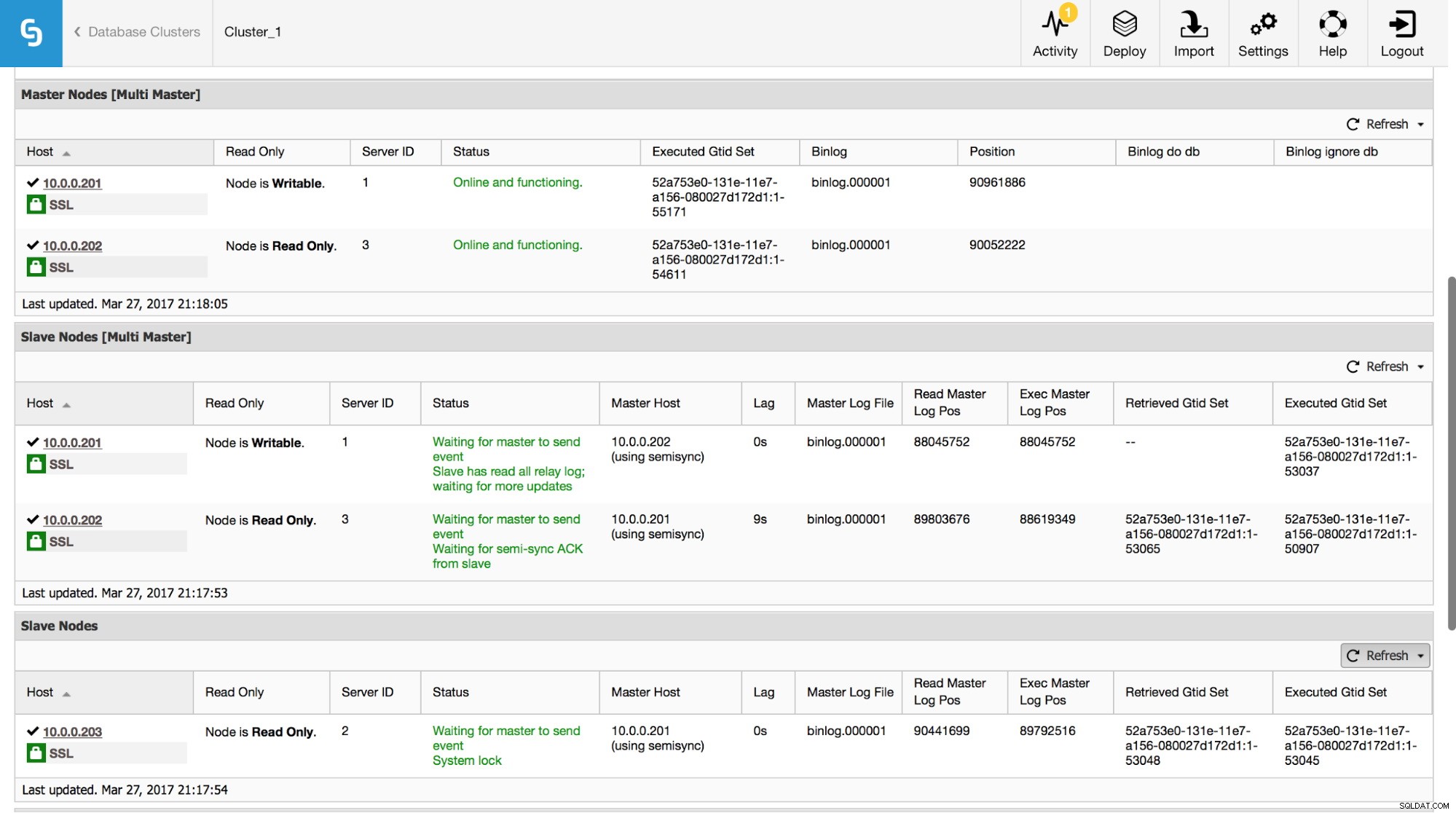
Wir haben alle wichtigen Informationen des Befehls SHOW SLAVE STATUS sichtbar gemacht. Sie können den Status der Replikation überprüfen, wer Master ist, ob es eine Replikationsverzögerung gibt oder nicht, binäre Log-Positionen. Sie können auch abgerufene und ausgeführte GTIDs finden.
Leistungsschema
Ein weiterer Ort, an dem Sie nach Informationen zur Replikation suchen können, ist das performance_schema. Dies gilt nur für MySQL 5.7 von Oracle – frühere Versionen und MariaDB erfassen diese Daten nicht.
mysql> SHOW TABLES FROM performance_schema LIKE 'replication%';
+---------------------------------------------+
| Tables_in_performance_schema (replication%) |
+---------------------------------------------+
| replication_applier_configuration |
| replication_applier_status |
| replication_applier_status_by_coordinator |
| replication_applier_status_by_worker |
| replication_connection_configuration |
| replication_connection_status |
| replication_group_member_stats |
| replication_group_members |
+---------------------------------------------+
8 rows in set (0.00 sec)Nachfolgend finden Sie einige Beispiele für Daten, die in einigen dieser Tabellen verfügbar sind.
mysql> select * from replication_connection_status\G
*************************** 1. row ***************************
CHANNEL_NAME:
GROUP_NAME:
SOURCE_UUID: 5d1e2227-07c6-11e7-8123-080027495a77
THREAD_ID: 32
SERVICE_STATE: ON
COUNT_RECEIVED_HEARTBEATS: 1
LAST_HEARTBEAT_TIMESTAMP: 2017-03-17 19:41:34
RECEIVED_TRANSACTION_SET: 5d1e2227-07c6-11e7-8123-080027495a77:715599-724966
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
1 row in set (0.00 sec)mysql> select * from replication_applier_status_by_worker\G
*************************** 1. row ***************************
CHANNEL_NAME:
WORKER_ID: 0
THREAD_ID: 31
SERVICE_STATE: ON
LAST_SEEN_TRANSACTION: 5d1e2227-07c6-11e7-8123-080027495a77:726086
LAST_ERROR_NUMBER: 0
LAST_ERROR_MESSAGE:
LAST_ERROR_TIMESTAMP: 0000-00-00 00:00:00
1 row in set (0.00 sec)Wie Sie sehen können, können wir den Status der Replikation, den letzten Fehler, den empfangenen Transaktionssatz und einige weitere Daten überprüfen. Was wichtig ist – wenn Sie die Multithread-Replikation aktiviert haben, sehen Sie in der Tabelle „replication_applier_status_by_worker“ den Status jedes einzelnen Workers – dies hilft Ihnen, den Replikationsstatus für jeden der Worker-Threads zu verstehen.
Replikationsverzögerung
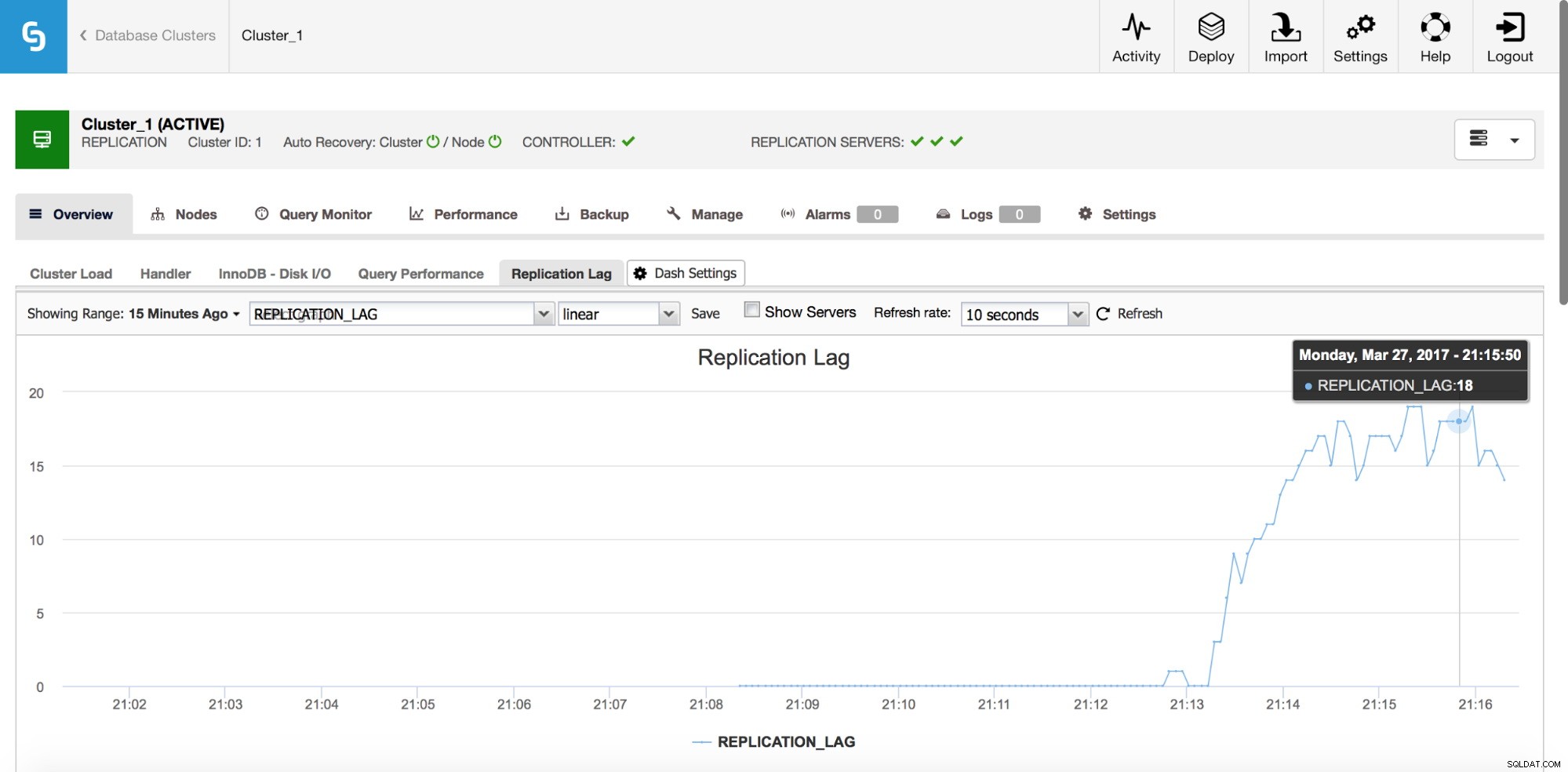
Verzögerung ist definitiv eines der häufigsten Probleme, mit denen Sie bei der Arbeit mit der MySQL-Replikation konfrontiert werden. Eine Replikationsverzögerung tritt auf, wenn einer der Slaves nicht mit der Anzahl der vom Master ausgeführten Schreibvorgänge Schritt halten kann. Die Gründe können unterschiedlich sein - andere Hardwarekonfiguration, stärkere Belastung des Slaves, hoher Grad an Schreibparallelisierung auf dem Master, der serialisiert werden muss (wenn Sie Single-Thread für die Replikation verwenden), oder die Schreibvorgänge können nicht im gleichen Umfang parallelisiert werden wie bisher auf dem Master gewesen (wenn Sie die Multithread-Replikation verwenden).
Wie erkennt man es?
Es gibt einige Methoden, um die Replikationsverzögerung zu erkennen. Als erstes können Sie „Seconds_Behind_Master“ in der Ausgabe SHOW SLAVE STATUS überprüfen – es wird Ihnen sagen, ob der Slave verzögert oder nicht. Es funktioniert in den meisten Fällen gut, aber in komplexeren Topologien, wenn Sie Zwischen-Master verwenden, auf Hosts irgendwo in der Replikationskette, ist es möglicherweise nicht präzise. Eine andere, bessere Lösung besteht darin, sich auf externe Tools wie pt-heartbeat zu verlassen. Die Idee ist einfach - es wird eine Tabelle erstellt, die unter anderem eine Zeitstempelspalte enthält. Diese Spalte wird auf dem Master in regelmäßigen Abständen aktualisiert. Auf einem Slave können Sie dann den Zeitstempel aus dieser Spalte mit der aktuellen Zeit vergleichen - es wird Ihnen sagen, wie weit der Slave hinterher ist.
Unabhängig davon, wie Sie die Verzögerung berechnen, stellen Sie sicher, dass Ihre Hosts zeitlich synchron sind. Verwenden Sie ntpd oder andere Mittel zur Zeitsynchronisierung - wenn es eine Zeitabweichung gibt, sehen Sie eine "falsche" Verzögerung auf Ihren Slaves.
Wie kann man Verzögerungen reduzieren?
Diese Frage ist nicht leicht zu beantworten. Kurz gesagt, es hängt davon ab, was die Verzögerung verursacht und was zu einem Engpass wurde. Es gibt zwei typische Muster:Der Slave ist E/A-gebunden, was bedeutet, dass sein E/A-Subsystem die Menge an Schreib- und Lesevorgängen nicht bewältigen kann. Zweitens – Slave ist CPU-gebunden, was bedeutet, dass der Replikations-Thread die gesamte CPU verwendet, die er kann (ein Thread kann nur einen CPU-Kern verwenden), und es ist immer noch nicht genug, um alle Schreibvorgänge zu verarbeiten.
Wenn die CPU ein Engpass ist, kann die Lösung so einfach sein wie die Verwendung von Multithread-Replikation. Erhöhen Sie die Anzahl der Arbeitsthreads, um eine höhere Parallelisierung zu ermöglichen. Es ist jedoch nicht immer möglich - in einem solchen Fall möchten Sie vielleicht ein wenig mit Gruppen-Commit-Variablen (sowohl für MySQL als auch für MariaDB) spielen, um Commits für einen kleinen Zeitraum zu verzögern (wir sprechen hier von Millisekunden) und auf diese Weise , Erhöhung der Parallelisierung von Commits.
Wenn das Problem in der E/A liegt, ist das Problem etwas schwieriger zu lösen. Natürlich sollten Sie Ihre InnoDB-E/A-Einstellungen überprüfen - vielleicht gibt es Raum für Verbesserungen. Wenn my.cnf-Tuning nicht hilft, haben Sie nicht allzu viele Optionen – verbessern Sie Ihre Abfragen (wo immer es möglich ist) oder aktualisieren Sie Ihr I/O-Subsystem auf etwas Leistungsfähigeres.
Die meisten Proxys (z. B. alle Proxys, die von ClusterControl bereitgestellt werden können:ProxySQL, HAProxy und MaxScale) geben Ihnen die Möglichkeit, einen Slave aus der Rotation zu entfernen, wenn die Replikationsverzögerung einen vordefinierten Schwellenwert überschreitet. Dies ist keineswegs eine Methode, um Lags zu reduzieren, aber es kann hilfreich sein, veraltete Lesevorgänge zu vermeiden und als Nebeneffekt die Belastung eines Slaves zu verringern, was ihm helfen sollte, aufzuholen.
Natürlich kann die Abfrageoptimierung in beiden Fällen eine Lösung sein – es ist immer gut, Abfragen zu verbessern, die CPU- oder E/A-lastig sind.
Fehlerhafte Transaktionen
Fehlerhafte Transaktionen sind Transaktionen, die nur auf einem Slave ausgeführt wurden, nicht auf dem Master. Kurz gesagt, sie machen einen Sklaven unvereinbar mit dem Herrn. Bei Verwendung der GTID-basierten Replikation kann dies zu ernsthaften Problemen führen, wenn der Slave zum Master befördert wird. Wir haben einen ausführlichen Beitrag zu diesem Thema und wir empfehlen Ihnen, sich damit zu beschäftigen und sich damit vertraut zu machen, wie Sie Probleme mit fehlerhaften Transaktionen erkennen und beheben können. Wir haben dort auch Informationen darüber aufgenommen, wie ClusterControl fehlerhafte Transaktionen erkennt und behandelt.
Keine Binlog-Datei auf dem Master
Wie identifiziere ich das Problem?
Unter Umständen kann es vorkommen, dass sich ein Slave mit einem Master verbindet und nach einer nicht existierenden Binärlogdatei fragt. Ein Grund dafür könnte die fehlerhafte Transaktion sein – irgendwann wurde eine Transaktion auf einem Slave ausgeführt und später wird dieser Slave zum Master. Andere Hosts, die so konfiguriert sind, dass sie von diesem Master abhängen, werden nach dieser fehlenden Transaktion fragen. Wenn es vor langer Zeit ausgeführt wurde, besteht die Möglichkeit, dass binäre Protokolldateien bereits gelöscht wurden.
Ein weiteres, typischeres Beispiel:Sie möchten einen Slave mithilfe von xtrabackup bereitstellen. Sie kopieren das Backup auf einen Host, wenden das Protokoll an, ändern den Eigentümer des MySQL-Datenverzeichnisses – typische Vorgänge, die Sie zum Wiederherstellen eines Backups ausführen. Sie führen aus
SET GLOBAL gtid_purged=basierend auf den Daten von xtrabackup_binlog_info und Sie führen CHANGE MASTER TO … MASTER_AUTO_POSITION=1 aus (dies ist in MySQL, MariaDB hat einen etwas anderen Prozess), starten den Slave und erhalten am Ende einen Fehler wie:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'in MySQL oder:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'Could not find GTID state requested by slave in any binlog files. Probably the slave state is too old and required binlog files have been purged.'in MariaDB.
Dies bedeutet im Grunde, dass der Master nicht über alle Binärprotokolle verfügt, die zum Ausführen aller fehlenden Transaktionen erforderlich sind. Höchstwahrscheinlich ist die Sicherung zu alt und der Master hat bereits einige der Binärprotokolle gelöscht, die zwischen der Erstellung der Sicherung und der Bereitstellung des Slaves erstellt wurden.
Wie kann dieses Problem gelöst werden?
Leider können Sie in diesem speziellen Fall nicht viel tun. Wenn Sie einige MySQL-Hosts haben, die Binärprotokolle länger speichern als der Master, können Sie versuchen, diese Protokolle zu verwenden, um fehlende Transaktionen auf dem Slave wiederzugeben. Schauen wir uns an, wie es gemacht werden kann.
Werfen wir zunächst einen Blick auf die älteste GTID in den Binärlogs des Masters:
mysql> SHOW BINARY LOGS\G
*************************** 1. row ***************************
Log_name: binlog.000021
File_size: 463
1 row in set (0.00 sec)„binlog.000021“ ist also die neueste (und einzige) Datei. Sehen wir uns an, was der erste GTID-Eintrag in dieser Datei ist:
example@sqldat.com:~# mysqlbinlog /var/lib/mysql/binlog.000021
/*!50530 SET @@SESSION.PSEUDO_SLAVE_MODE=1*/;
/*!50003 SET @example@sqldat.com@COMPLETION_TYPE,COMPLETION_TYPE=0*/;
DELIMITER /*!*/;
# at 4
#170320 10:39:51 server id 1 end_log_pos 123 CRC32 0x5644fc9b Start: binlog v 4, server v 5.7.17-11-log created 170320 10:39:51
# Warning: this binlog is either in use or was not closed properly.
BINLOG '
d7HPWA8BAAAAdwAAAHsAAAABAAQANS43LjE3LTExLWxvZwAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA
AAAAAAAAAAAAAAAAAAAAAAAAEzgNAAgAEgAEBAQEEgAAXwAEGggAAAAICAgCAAAACgoKKioAEjQA
AZv8RFY=
'/*!*/;
# at 123
#170320 10:39:51 server id 1 end_log_pos 194 CRC32 0x5c096d62 Previous-GTIDs
# 5d1e2227-07c6-11e7-8123-080027495a77:1-1106668
# at 194
#170320 11:21:26 server id 1 end_log_pos 259 CRC32 0xde21b300 GTID last_committed=0 sequence_number=1
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106669'/*!*/;
# at 259Wie wir sehen können, lautet der älteste verfügbare Binärlog-Eintrag:5d1e2227-07c6-11e7-8123-080027495a77:1106669
Wir müssen auch überprüfen, was die letzte GTID ist, die in der Sicherung enthalten ist:
example@sqldat.com:~# cat /var/lib/mysql/xtrabackup_binlog_info
binlog.000017 194 5d1e2227-07c6-11e7-8123-080027495a77:1-1106666
Es ist:5d1e2227-07c6-11e7-8123-080027495a77:1-1106666, also fehlen uns zwei Ereignisse:
5d1e2227-07c6-11e7-8123-080027495a77:1106667-1106668
Mal sehen, ob wir diese Transaktionen auf anderen Sklaven finden können.
mysql> SHOW BINARY LOGS;
+---------------+------------+
| Log_name | File_size |
+---------------+------------+
| binlog.000001 | 1074130062 |
| binlog.000002 | 764366611 |
| binlog.000003 | 382576490 |
+---------------+------------+
3 rows in set (0.00 sec)Es scheint, dass „binlog.000003“ das neueste Binärlog ist. Wir müssen prüfen, ob unsere fehlenden GTIDs darin zu finden sind:
slave2:~# mysqlbinlog /var/lib/mysql/binlog.000003 | grep "5d1e2227-07c6-11e7-8123-080027495a77:110666[78]"
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106667'/*!*/;
SET @@SESSION.GTID_NEXT= '5d1e2227-07c6-11e7-8123-080027495a77:1106668'/*!*/;Bitte denken Sie daran, dass Sie möglicherweise Binlog-Dateien außerhalb des Produktionsservers kopieren möchten, da ihre Verarbeitung etwas Last hinzufügen kann. Da wir überprüft haben, dass diese GTIDs existieren, können wir sie extrahieren:
slave2:~# mysqlbinlog --exclude-gtids='5d1e2227-07c6-11e7-8123-080027495a77:1-1106666,5d1e2227-07c6-11e7-8123-080027495a77:1106669' /var/lib/mysql/binlog.000003 > to_apply_on_slave1.sqlNach einem kurzen scp können wir diese Ereignisse auf den Slave anwenden
slave1:~# mysql -ppass < to_apply_on_slave1.sqlAnschließend können wir überprüfen, ob diese GTIDs angewendet wurden, indem wir uns die Ausgabe von SHOW SLAVE STATUS:
ansehen Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'
Last_SQL_Errno: 0
Last_SQL_Error:
Replicate_Ignore_Server_Ids:
Master_Server_Id: 1
Master_UUID: 5d1e2227-07c6-11e7-8123-080027495a77
Master_Info_File: mysql.slave_master_info
SQL_Delay: 0
SQL_Remaining_Delay: NULL
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updates
Master_Retry_Count: 86400
Master_Bind:
Last_IO_Error_Timestamp: 170320 10:45:04
Last_SQL_Error_Timestamp:
Master_SSL_Crl:
Master_SSL_Crlpath:
Retrieved_Gtid_Set:
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-1106668Executed_GTID_set sieht gut aus, daher können wir Slave-Threads starten:
mysql> START SLAVE;
Query OK, 0 rows affected (0.00 sec)Lassen Sie uns überprüfen, ob es gut funktioniert hat. Wir werden wieder die Ausgabe von SHOW SLAVE STATUS verwenden:
Master_SSL_Crlpath:
Retrieved_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1106669
Executed_Gtid_Set: 5d1e2227-07c6-11e7-8123-080027495a77:1-1106669Sieht gut aus, es läuft!
Eine andere Methode zur Lösung dieses Problems besteht darin, ein weiteres Mal ein Backup zu erstellen und den Slave erneut mit frischen Daten bereitzustellen. Dies wird sehr wahrscheinlich schneller und definitiv zuverlässiger sein. Es kommt nicht oft vor, dass Sie unterschiedliche Binlog-Bereinigungsrichtlinien auf Master und Slaves haben)
Wir werden im nächsten Blogbeitrag weitere Arten von Replikationsproblemen diskutieren.