In den letzten paar Blogs haben wir behandelt, wie man einen Galera-Cluster auf Docker betreibt, ob auf eigenständigem Docker oder auf Multi-Host-Docker Swarm mit Overlay-Netzwerk. In diesem Blogbeitrag werden wir uns mit der Ausführung von Galera Cluster auf Kubernetes befassen, einem Orchestrierungstool zum Ausführen von Containern in großem Maßstab. Einige Teile sind unterschiedlich, z. B. wie die Anwendung eine Verbindung zum Cluster herstellen soll, wie Kubernetes Failover handhabt und wie der Lastenausgleich in Kubernetes funktioniert.
Kubernetes vs. Docker Swarm
Unser oberstes Ziel ist es sicherzustellen, dass Galera Cluster zuverlässig in einer Containerumgebung läuft. Wir haben zuvor über Docker Swarm berichtet, und es stellte sich heraus, dass das Ausführen von Galera Cluster darauf eine Reihe von Blockern hat, die verhindern, dass es produktionsbereit ist. Unsere Reise geht jetzt weiter mit Kubernetes, einem produktionstauglichen Container-Orchestrierungstool. Mal sehen, welches Maß an „Produktionsbereitschaft“ es unterstützen kann, wenn ein zustandsbehafteter Dienst wie Galera Cluster ausgeführt wird.
Bevor wir weitermachen, wollen wir einige der wichtigsten Unterschiede zwischen Kubernetes (1.6) und Docker Swarm (17.03) hervorheben, wenn Galera Cluster auf Containern ausgeführt wird:
- Kubernetes unterstützt zwei Zustandsprüfungstests:Lebendigkeit und Bereitschaft. Dies ist wichtig, wenn ein Galera-Cluster auf Containern ausgeführt wird, da ein Live-Galera-Container nicht bedeutet, dass er einsatzbereit ist und in das Load-Balancing-Set aufgenommen werden sollte (denken Sie an einen Joiner/Donor-Status). Docker Swarm unterstützt nur eine Integritätsprüfungsprobe, ähnlich der Lebendigkeit von Kubernetes, ein Container ist entweder fehlerfrei und läuft weiter oder ist fehlerhaft und wird neu geplant. Lesen Sie hier für Details.
- Kubernetes verfügt über ein UI-Dashboard, auf das über „kubectl-Proxy“ zugegriffen werden kann.
- Docker Swarm unterstützt nur Round-Robin-Load-Balancing (Ingress), während Kubernetes die geringste Verbindung verwendet.
- Docker Swarm unterstützt Routing-Mesh, um einen Dienst im externen Netzwerk zu veröffentlichen, während Kubernetes etwas Ähnliches namens NodePort unterstützt, sowie externe Load Balancer (GCE GLB/AWS ELB) und externe DNS-Namen (wie für v1.7)
Kubernetes mit Kubeadm installieren
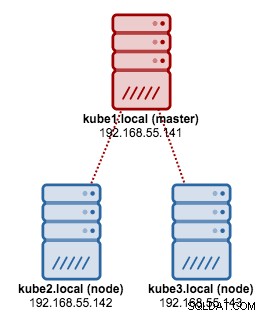
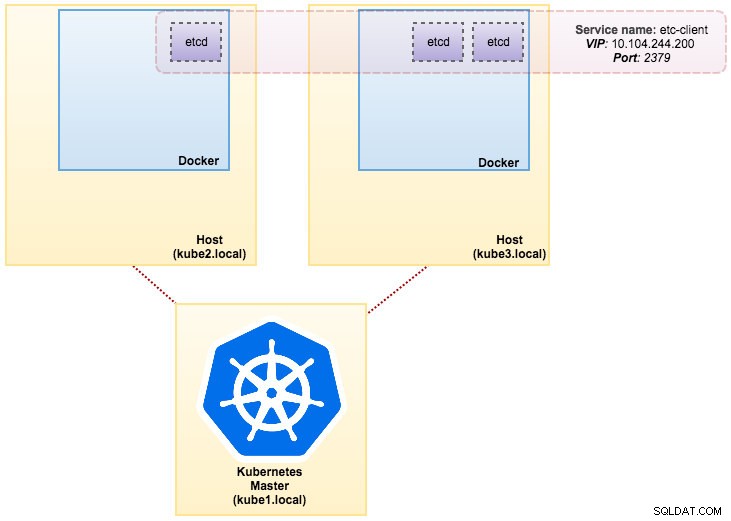
Wir werden kubeadm verwenden, um einen Kubernetes-Cluster mit 3 Knoten auf CentOS 7 zu installieren. Er besteht aus 1 Master und 2 Knoten (Minions). Unsere physische Architektur sieht so aus:
1. Installieren Sie kubelet und Docker auf allen Knoten:
$ ARCH=x86_64
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-${ARCH}
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg
https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
EOF
$ setenforce 0
$ yum install -y docker kubelet kubeadm kubectl kubernetes-cni
$ systemctl enable docker && systemctl start docker
$ systemctl enable kubelet && systemctl start kubelet2. Initialisieren Sie auf dem Master den Master, kopieren Sie die Konfigurationsdatei, richten Sie das Pod-Netzwerk mit Weave ein und installieren Sie Kubernetes Dashboard:
$ kubeadm init
$ cp /etc/kubernetes/admin.conf $HOME/
$ export KUBECONFIG=$HOME/admin.conf
$ kubectl apply -f https://git.io/weave-kube-1.6
$ kubectl create -f https://git.io/kube-dashboard3. Dann auf den anderen verbleibenden Knoten:
$ kubeadm join --token 091d2a.e4862a6224454fd6 192.168.55.140:64434. Stellen Sie sicher, dass die Knoten bereit sind:
$ kubectl get nodes
NAME STATUS AGE VERSION
kube1.local Ready 1h v1.6.3
kube2.local Ready 1h v1.6.3
kube3.local Ready 1h v1.6.3Wir haben jetzt einen Kubernetes-Cluster für die Galera-Cluster-Bereitstellung.
Galera-Cluster auf Kubernetes
In diesem Beispiel werden wir einen MariaDB Galera-Cluster 10.1 mit Docker-Image aus unserem DockerHub-Repository bereitstellen. Die in dieser Bereitstellung verwendeten YAML-Definitionsdateien finden Sie im Verzeichnis example-kubernetes im Github-Repository.
Kubernetes unterstützt eine Reihe von Bereitstellungscontrollern. Um einen Galera-Cluster bereitzustellen, kann man Folgendes verwenden:
- ReplicaSet
- StatefulSet
Jeder von ihnen hat seine eigenen Vor- und Nachteile. Wir werden uns jeden einzelnen von ihnen ansehen und sehen, was der Unterschied ist.
Voraussetzungen
Das von uns erstellte Image erfordert ein etcd (eigenständig oder Cluster) für die Diensterkennung. Um einen etcd-Cluster auszuführen, muss jede etcd-Instanz mit unterschiedlichen Befehlen ausgeführt werden, daher verwenden wir den Pods-Controller anstelle von Deployment und erstellen einen Dienst namens „etcd-client“ als Endpunkt für etcd-Pods. Die Definitionsdatei etcd-cluster.yaml sagt alles.
Um einen etcd-Cluster mit 3 Pods bereitzustellen, führen Sie einfach Folgendes aus:
$ kubectl create -f etcd-cluster.yamlÜberprüfen Sie, ob der etcd-Cluster bereit ist:
$ kubectl get po,svc
NAME READY STATUS RESTARTS AGE
po/etcd0 1/1 Running 0 1d
po/etcd1 1/1 Running 0 1d
po/etcd2 1/1 Running 0 1d
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/etcd-client 10.104.244.200 <none> 2379/TCP 1d
svc/etcd0 10.100.24.171 <none> 2379/TCP,2380/TCP 1d
svc/etcd1 10.108.207.7 <none> 2379/TCP,2380/TCP 1d
svc/etcd2 10.101.9.115 <none> 2379/TCP,2380/TCP 1dUnsere Architektur sieht jetzt etwa so aus:
 Severalnines MySQL on Docker:How to Containerize Your DatabaseEntdecken Sie alles, was Sie verstehen müssen, wenn Sie erwägen, einen MySQL-Dienst darauf auszuführen Top of Docker-Container-VirtualisierungLaden Sie das White Paper herunter
Severalnines MySQL on Docker:How to Containerize Your DatabaseEntdecken Sie alles, was Sie verstehen müssen, wenn Sie erwägen, einen MySQL-Dienst darauf auszuführen Top of Docker-Container-VirtualisierungLaden Sie das White Paper herunter ReplicaSet verwenden
Ein ReplicaSet stellt sicher, dass zu jedem Zeitpunkt eine bestimmte Anzahl von Pod-Repliken ausgeführt werden. Ein Deployment ist jedoch ein übergeordnetes Konzept, das ReplicaSets verwaltet und deklarative Aktualisierungen für Pods zusammen mit vielen anderen nützlichen Funktionen bereitstellt. Daher wird empfohlen, Deployments zu verwenden, anstatt ReplicaSets direkt zu verwenden, es sei denn, Sie benötigen eine benutzerdefinierte Update-Orchestrierung oder überhaupt keine Updates. Wenn Sie Bereitstellungen verwenden, müssen Sie sich keine Gedanken über die Verwaltung der von ihnen erstellten ReplicaSets machen. Bereitstellungen besitzen und verwalten ihre ReplicaSets.
In unserem Fall verwenden wir Deployment als Workload-Controller, wie in dieser YAML-Definition gezeigt. Wir können das Galera Cluster ReplicaSet und den Dienst direkt erstellen, indem wir den folgenden Befehl ausführen:
$ kubectl create -f mariadb-rs.ymlÜberprüfen Sie, ob der Cluster bereit ist, indem Sie sich ReplicaSet (rs), Pods (po) und Services (svc) ansehen:
$ kubectl get rs,po,svc
NAME DESIRED CURRENT READY AGE
rs/galera-251551564 3 3 3 5h
NAME READY STATUS RESTARTS AGE
po/etcd0 1/1 Running 0 1d
po/etcd1 1/1 Running 0 1d
po/etcd2 1/1 Running 0 1d
po/galera-251551564-8c238 1/1 Running 0 5h
po/galera-251551564-swjjl 1/1 Running 1 5h
po/galera-251551564-z4sgx 1/1 Running 1 5h
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/etcd-client 10.104.244.200 <none> 2379/TCP 1d
svc/etcd0 10.100.24.171 <none> 2379/TCP,2380/TCP 1d
svc/etcd1 10.108.207.7 <none> 2379/TCP,2380/TCP 1d
svc/etcd2 10.101.9.115 <none> 2379/TCP,2380/TCP 1d
svc/galera-rs 10.107.89.109 <nodes> 3306:30000/TCP 5h
svc/kubernetes 10.96.0.1 <none> 443/TCP 1dAus der obigen Ausgabe können wir unsere Pods und Dienste wie folgt veranschaulichen:
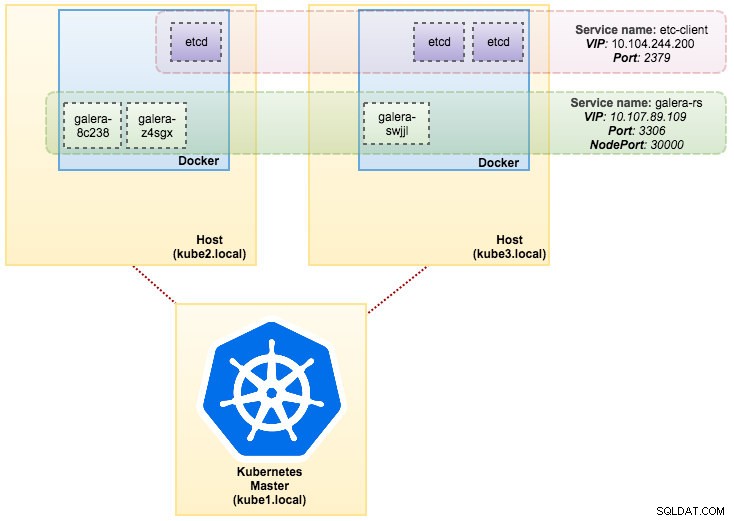
Das Ausführen von Galera Cluster auf ReplicaSet ähnelt der Behandlung als zustandslose Anwendung. Es orchestriert das Erstellen, Löschen und Aktualisieren von Pods und kann für Horizontal Pod Autoscales (HPA) verwendet werden, d. h. ein ReplicaSet kann automatisch skaliert werden, wenn es bestimmte Schwellenwerte oder Ziele erfüllt (CPU-Auslastung, Pakete pro Sekunde, Anforderung pro Sekunde). usw.).
Wenn einer der Kubernetes-Knoten ausfällt, werden neue Pods auf einem verfügbaren Knoten geplant, um die gewünschten Replikate zu erfüllen. Mit dem Pod verknüpfte Volumes werden gelöscht, wenn der Pod gelöscht oder neu geplant wird. Der Pod-Hostname wird nach dem Zufallsprinzip generiert, wodurch es schwieriger wird, nachzuverfolgen, wo der Container hingehört, indem man sich einfach den Hostnamen ansieht.
All dies funktioniert ziemlich gut in Test- und Staging-Umgebungen, in denen Sie einen vollständigen Container-Lebenszyklus wie Bereitstellung, Skalierung, Aktualisierung und Zerstörung ohne Abhängigkeiten durchführen können. Das Hoch- und Herunterskalieren ist einfach, indem Sie die YAML-Datei aktualisieren und an den Kubernetes-Cluster senden oder den Skalierungsbefehl verwenden:
$ kubectl scale replicaset galera-rs --replicas=5StatefulSet verwenden
StatefulSet, bekannt als PetSet in der Version vor 1.6, ist der beste Weg, Galera Cluster in der Produktion bereitzustellen, weil:
- Durch das Löschen und/oder Herunterskalieren eines StatefulSets werden die dem StatefulSet zugeordneten Volumes nicht gelöscht. Dies geschieht, um die Datensicherheit zu gewährleisten, was im Allgemeinen wertvoller ist als eine automatische Bereinigung aller zugehörigen StatefulSet-Ressourcen.
- Für ein StatefulSet mit N Replikaten werden Pods bei der Bereitstellung nacheinander erstellt, in der Reihenfolge von {0 .. N-1 }.
- Wenn Pods gelöscht werden, werden sie in umgekehrter Reihenfolge von {N-1 beendet .. 0}.
- Bevor ein Skalierungsvorgang auf einen Pod angewendet wird, müssen alle seine Vorgänger ausgeführt und bereit sein.
- Bevor ein Pod beendet wird, müssen alle seine Nachfolger vollständig heruntergefahren werden.
StatefulSet bietet erstklassige Unterstützung für Stateful-Container. Es bietet eine Bereitstellungs- und Skalierungsgarantie. Wenn ein Galera-Cluster mit drei Knoten erstellt wird, werden drei Pods in der Reihenfolge db-0, db-1, db-2 bereitgestellt. db-1 wird nicht bereitgestellt, bevor db-0 „Running and Ready“ ist, und db-2 wird nicht bereitgestellt, bis db-1 „Running and Ready“ ist. Wenn db-0 fehlschlagen sollte, nachdem db-1 „Running and Ready“ ist, aber bevor db-2 gestartet wird, wird db-2 nicht gestartet, bis db-0 erfolgreich neu gestartet wurde und „Running and Ready“ wird.
Wir werden die Kubernetes-Implementierung von persistentem Speicher namens PersistentVolume und PersistentVolumeClaim verwenden. Dies soll die Datenpersistenz sicherstellen, wenn der Pod auf den anderen Knoten umgeplant wurde. Auch wenn Galera Cluster die exakte Kopie der Daten auf jedem Replikat bereitstellt, ist es für Fehlerbehebungs- und Wiederherstellungszwecke gut, wenn die Daten in jedem Pod persistent sind.
Um einen persistenten Speicher zu erstellen, müssen wir zuerst PersistentVolume für jeden Pod erstellen. PVs sind Volume-Plugins wie Volumes in Docker, haben aber einen Lebenszyklus, der unabhängig von jedem einzelnen Pod ist, der das PV verwendet. Da wir einen Galera-Cluster mit 3 Knoten bereitstellen werden, müssen wir 3 PVs erstellen:
apiVersion: v1
kind: PersistentVolume
metadata:
name: datadir-galera-0
labels:
app: galera-ss
podindex: "0"
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 10Gi
hostPath:
path: /data/pods/galera-0/datadir
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: datadir-galera-1
labels:
app: galera-ss
podindex: "1"
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 10Gi
hostPath:
path: /data/pods/galera-1/datadir
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: datadir-galera-2
labels:
app: galera-ss
podindex: "2"
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 10Gi
hostPath:
path: /data/pods/galera-2/datadirDie obige Definition zeigt, dass wir 3 PV erstellen werden, die dem physischen Pfad der Kubernetes-Knoten mit 10 GB Speicherplatz zugeordnet sind. Wir haben ReadWriteOnce definiert, was bedeutet, dass das Volume von nur einem einzigen Knoten mit Lese-/Schreibzugriff gemountet werden kann. Speichern Sie die obigen Zeilen in mariadb-pv.yml und senden Sie sie an Kubernetes:
$ kubectl create -f mariadb-pv.yml
persistentvolume "datadir-galera-0" created
persistentvolume "datadir-galera-1" created
persistentvolume "datadir-galera-2" createdDefinieren Sie als Nächstes die PersistentVolumeClaim-Ressourcen:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: mysql-datadir-galera-ss-0
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
selector:
matchLabels:
app: galera-ss
podindex: "0"
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: mysql-datadir-galera-ss-1
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
selector:
matchLabels:
app: galera-ss
podindex: "1"
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: mysql-datadir-galera-ss-2
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
selector:
matchLabels:
app: galera-ss
podindex: "2"Die obige Definition zeigt, dass wir die PV-Ressourcen beanspruchen und die spec.selector.matchLabels verwenden möchten um nach unserem PV zu suchen (metadata.labels.app:galera-ss ) basierend auf dem jeweiligen Pod-Index (metadata.labels.podindex ) von Kubernetes zugewiesen. Der metadata.name Die Ressource muss das unter spec.templates.containers definierte Format „{volumeMounts.name}-{pod}-{ordinal index}“ verwenden damit Kubernetes weiß, welcher Einhängepunkt den Anspruch dem Pod zuordnen soll.
Speichern Sie die obigen Zeilen in mariadb-pvc.yml und senden Sie sie an Kubernetes:
$ kubectl create -f mariadb-pvc.yml
persistentvolumeclaim "mysql-datadir-galera-ss-0" created
persistentvolumeclaim "mysql-datadir-galera-ss-1" created
persistentvolumeclaim "mysql-datadir-galera-ss-2" createdUnser persistenter Speicher ist jetzt bereit. Wir können dann die Galera-Cluster-Bereitstellung starten, indem wir eine StatefulSet-Ressource zusammen mit einer Headless-Service-Ressource erstellen, wie in mariadb-ss.yml gezeigt:
$ kubectl create -f mariadb-ss.yml
service "galera-ss" created
statefulset "galera-ss" createdRufen Sie jetzt die Zusammenfassung unserer StatefulSet-Bereitstellung ab:
$ kubectl get statefulsets,po,pv,pvc -o wide
NAME DESIRED CURRENT AGE
statefulsets/galera-ss 3 3 1d galera severalnines/mariadb:10.1 app=galera-ss
NAME READY STATUS RESTARTS AGE IP NODE
po/etcd0 1/1 Running 0 7d 10.36.0.1 kube3.local
po/etcd1 1/1 Running 0 7d 10.44.0.2 kube2.local
po/etcd2 1/1 Running 0 7d 10.36.0.2 kube3.local
po/galera-ss-0 1/1 Running 0 1d 10.44.0.4 kube2.local
po/galera-ss-1 1/1 Running 1 1d 10.36.0.5 kube3.local
po/galera-ss-2 1/1 Running 0 1d 10.44.0.5 kube2.local
NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM STORAGECLASS REASON AGE
pv/datadir-galera-0 10Gi RWO Retain Bound default/mysql-datadir-galera-ss-0 4d
pv/datadir-galera-1 10Gi RWO Retain Bound default/mysql-datadir-galera-ss-1 4d
pv/datadir-galera-2 10Gi RWO Retain Bound default/mysql-datadir-galera-ss-2 4d
NAME STATUS VOLUME CAPACITY ACCESSMODES STORAGECLASS AGE
pvc/mysql-datadir-galera-ss-0 Bound datadir-galera-0 10Gi RWO 4d
pvc/mysql-datadir-galera-ss-1 Bound datadir-galera-1 10Gi RWO 4d
pvc/mysql-datadir-galera-ss-2 Bound datadir-galera-2 10Gi RWO 4dAn diesem Punkt kann unser auf StatefulSet ausgeführter Galera-Cluster wie im folgenden Diagramm dargestellt werden:
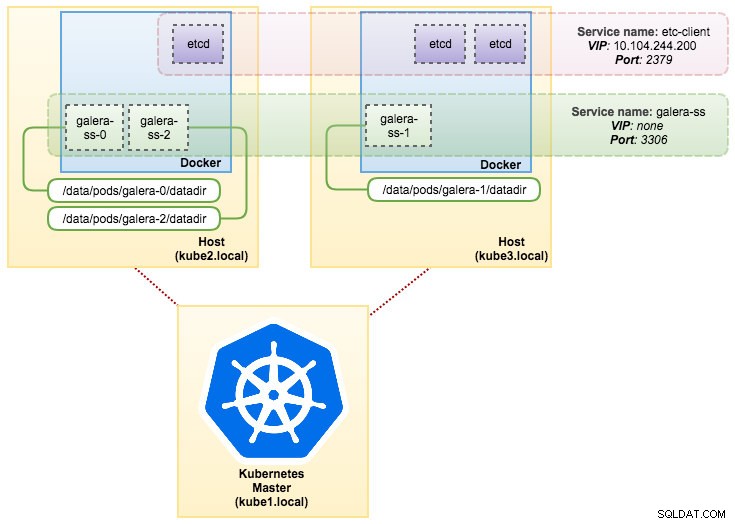
Die Ausführung auf StatefulSet garantiert konsistente Kennungen wie Hostname, IP-Adresse, Netzwerk-ID, Cluster-Domain, Pod-DNS und Speicher. Dadurch kann sich der Pod leicht von anderen in einer Gruppe von Pods unterscheiden. Das Volume wird auf dem Host beibehalten und nicht gelöscht, wenn der Pod gelöscht oder auf einen anderen Knoten verschoben wird. Dies ermöglicht eine Datenwiederherstellung und reduziert das Risiko eines vollständigen Datenverlusts.
Auf der negativen Seite ist die Bereitstellungszeit N-1 Mal (N =Replikate) länger, da Kubernetes beim Bereitstellen, Umplanen oder Löschen der Ressourcen die ordinale Reihenfolge einhält. Es wäre ein bisschen mühsam, das PV und die Ansprüche vorzubereiten, bevor Sie über die Skalierung Ihres Clusters nachdenken. Beachten Sie, dass das Aktualisieren eines vorhandenen StatefulSets derzeit ein manueller Prozess ist, bei dem Sie nur spec.replicas aktualisieren können im Moment.
Verbindung mit Galera Cluster Service und Pods herstellen
Es gibt mehrere Möglichkeiten, wie Sie eine Verbindung zum Datenbank-Cluster herstellen können. Sie können sich direkt mit dem Port verbinden. Im Dienstbeispiel „galera-rs“ verwenden wir NodePort, wodurch der Dienst auf der IP jedes Knotens an einem statischen Port (dem NodePort) verfügbar gemacht wird. Ein ClusterIP-Dienst, an den der NodePort-Dienst weiterleitet, wird automatisch erstellt. Sie können den NodePort-Dienst von außerhalb des Clusters kontaktieren, indem Sie {NodeIP}:{NodePort} anfordern .
Beispiel um sich extern mit dem Galera Cluster zu verbinden:
(external)$ mysql -udb_user -ppassword -h192.168.55.141 -P30000
(external)$ mysql -udb_user -ppassword -h192.168.55.142 -P30000
(external)$ mysql -udb_user -ppassword -h192.168.55.143 -P30000Innerhalb des Kubernetes-Netzwerkbereichs können sich Pods intern über die Cluster-IP oder den Dienstnamen verbinden, was mit dem folgenden Befehl abgerufen werden kann:
$ kubectl get services -o wide
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
etcd-client 10.104.244.200 <none> 2379/TCP 1d app=etcd
etcd0 10.100.24.171 <none> 2379/TCP,2380/TCP 1d etcd_node=etcd0
etcd1 10.108.207.7 <none> 2379/TCP,2380/TCP 1d etcd_node=etcd1
etcd2 10.101.9.115 <none> 2379/TCP,2380/TCP 1d etcd_node=etcd2
galera-rs 10.107.89.109 <nodes> 3306:30000/TCP 4h app=galera-rs
galera-ss None <none> 3306/TCP 3m app=galera-ss
kubernetes 10.96.0.1 <none> 443/TCP 1d <none>Aus der Dienstliste können wir sehen, dass die Galera Cluster ReplicaSet Cluster-IP 10.107.89.109 ist. Intern kann ein anderer Pod über diese IP-Adresse oder diesen Dienstnamen unter Verwendung des exponierten Ports 3306:
auf die Datenbank zugreifen(etcd0 pod)$ mysql -udb_user -ppassword -hgalera-rs -P3306 -e 'select @@hostname'
+------------------------+
| @@hostname |
+------------------------+
| galera-251551564-z4sgx |
+------------------------+Sie können sich auch von jedem Pod aus an Port 30000 mit dem externen NodePort verbinden:
(etcd0 pod)$ mysql -udb_user -ppassword -h192.168.55.143 -P30000 -e 'select @@hostname'
+------------------------+
| @@hostname |
+------------------------+
| galera-251551564-z4sgx |
+------------------------+Die Verbindung zu den Back-End-Pods wird entsprechend auf der Grundlage des Algorithmus der geringsten Verbindung ausgeglichen.
Zusammenfassung
An dieser Stelle erscheint es im Vergleich zu Docker Swarm viel vielversprechender, Galera Cluster auf Kubernetes in der Produktion zu betreiben. Wie im letzten Blogbeitrag besprochen, werden die geäußerten Bedenken anders angegangen, wenn es darum geht, wie Kubernetes Container in StatefulSet orchestriert (obwohl es sich in v1.6 noch um eine Beta-Funktion handelt). Wir hoffen, dass der vorgeschlagene Ansatz dazu beitragen wird, Galera Cluster auf Containern in großem Maßstab in der Produktion auszuführen.