Load-Balancer sind eine wesentliche Komponente jedes hochverfügbaren Datenbank-Setups. Sie werden verwendet, um die Kapazität und Zuverlässigkeit Ihrer kritischen Systeme und Anwendungen zu erhöhen, indem sie verhindern, dass ein Server überlastet wird. Wir sprechen im Multiplenines-Blog viel über sie, z. B. warum Sie sie brauchen und wie sie funktionieren. Einer der beliebtesten Load Balancer für MySQL und MariaDB ist HAProxy.
Funktionsmäßig ist HAProxy nicht mit ProxySQL oder MaxScale vergleichbar. HAProxy ist jedoch ein schneller, robuster Load Balancer, der in jeder Umgebung einwandfrei funktioniert, solange die Anwendung die Lese-/Schreibaufteilung durchführen und SELECT-Abfragen an ein Backend und alle Schreibvorgänge und SELECT...FOR UPDATE an ein separates senden kann Backend.
Es ist sehr wichtig, alle von HAProxy zur Verfügung gestellten Metriken im Auge zu behalten; Sie müssen in der Lage sein, den Status Ihres Proxys zu kennen, insbesondere um zu wissen, ob Sie auf Probleme gestoßen sind.
ClusterControl stellt seit jeher eine HAProxy-Statusseite zur Verfügung, die den Status des Proxys in Echtzeit anzeigt. Mit den neuen Prometheus-basierten SCUMM-Dashboards (Severalnines ClusterControl Unified Monitoring &Management) ist es jetzt möglich, leicht zu verfolgen, wie sich diese Metriken im Laufe der Zeit ändern.
Dieser Blogbeitrag untersucht die verschiedenen Metriken, die im HAProxy SCUMM-Dashboard angezeigt werden.
Erkunden des HAProxy-Dashboards in ClusterControl
Alle Prometheus- und SCUMM-Dashboards sind in ClusterControl standardmäßig deaktiviert. Um sie jedoch für einen bestimmten Cluster bereitzustellen, ist nur ein Klick erforderlich. Wenn Sie mehrere Cluster mit ClusterControl überwachen, können Sie dieselbe Prometheus-Instanz für jeden Cluster wiederverwenden.
Nach der Bereitstellung können Sie auf das HAProxy-Dashboard zugreifen. Werfen wir einen Blick auf die im Dashboard verfügbaren Daten:
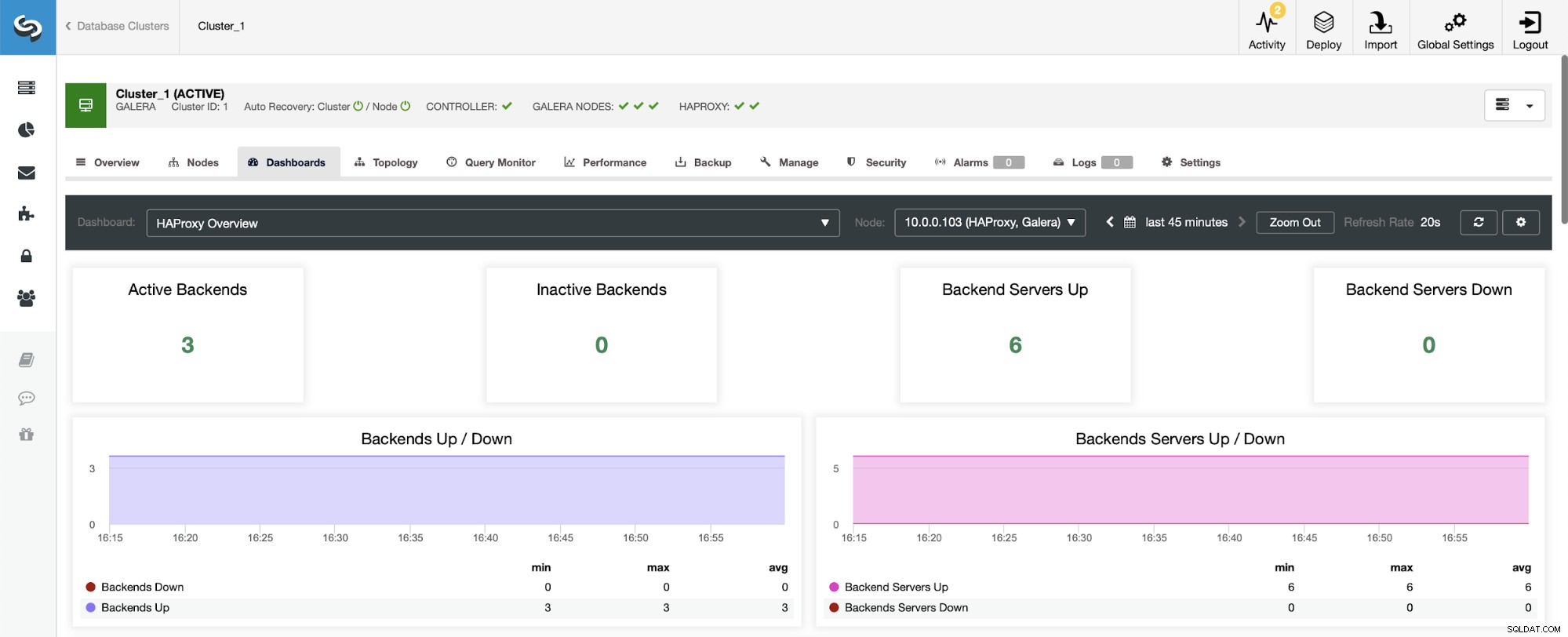
Das erste, was Sie sehen werden, wenn Sie zum HAProxy-Dashboard navigieren, ist Informationen über den Zustand Ihrer Backends. Beachten Sie hier bitte, dass das, was Sie sehen, vom Clustertyp und davon abhängen kann, wie Sie HAProxy bereitgestellt haben. In diesem Fall haben wir einen Galera-Cluster bereitgestellt, und HAProxy wurde im Round-Robin-Verfahren bereitgestellt. Daher sehen Sie drei Backends für Lesevorgänge und drei für Schreibvorgänge – insgesamt sechs. Aus diesem Grund sehen Sie auch alle Backends als „Up“ gekennzeichnet.
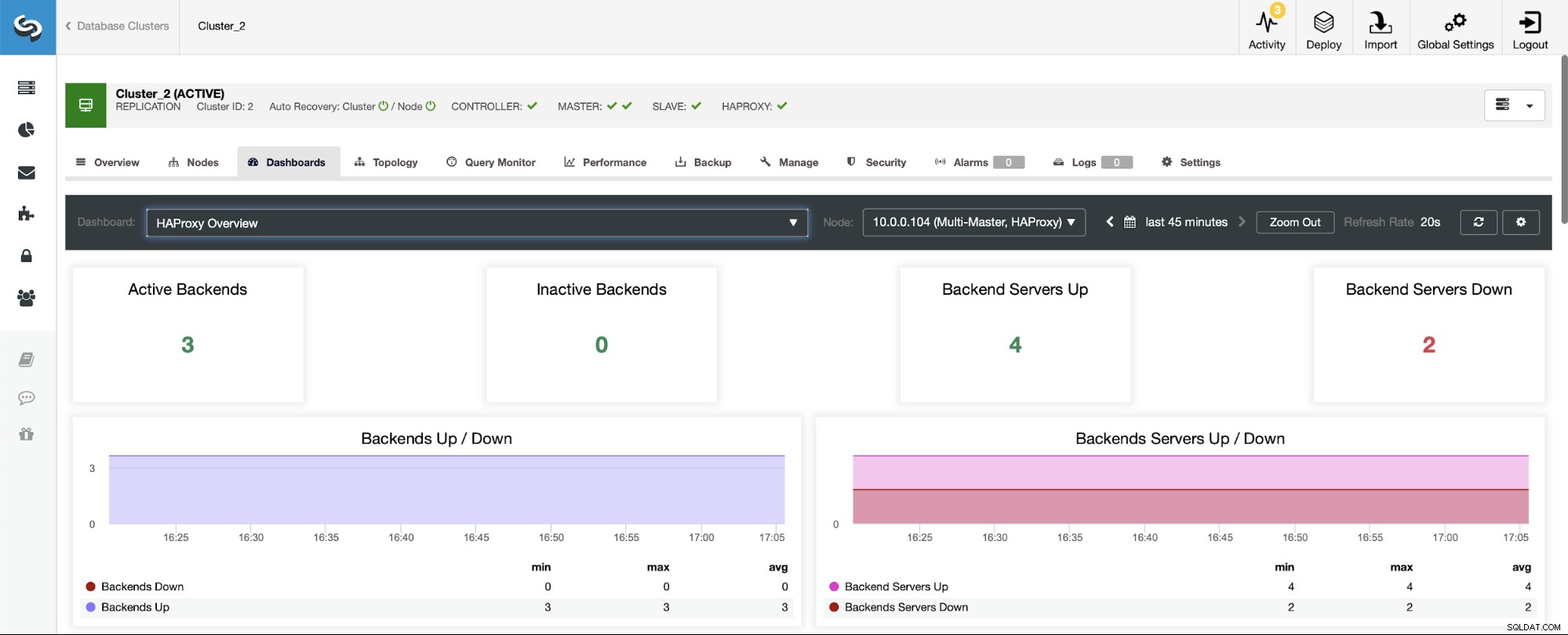
In einem Szenario mit einem Replikations-Cluster sehen die Dinge anders aus, da der HAProxy in einer Lese-/Schreib-Aufteilung bereitgestellt wird und die Skripte nur einen Host (Master) im Writer-Host am Laufen halten Backend.
Beachten Sie, deshalb sehen Sie unten zwei Backend-Server, die als „Down“ gekennzeichnet sind:
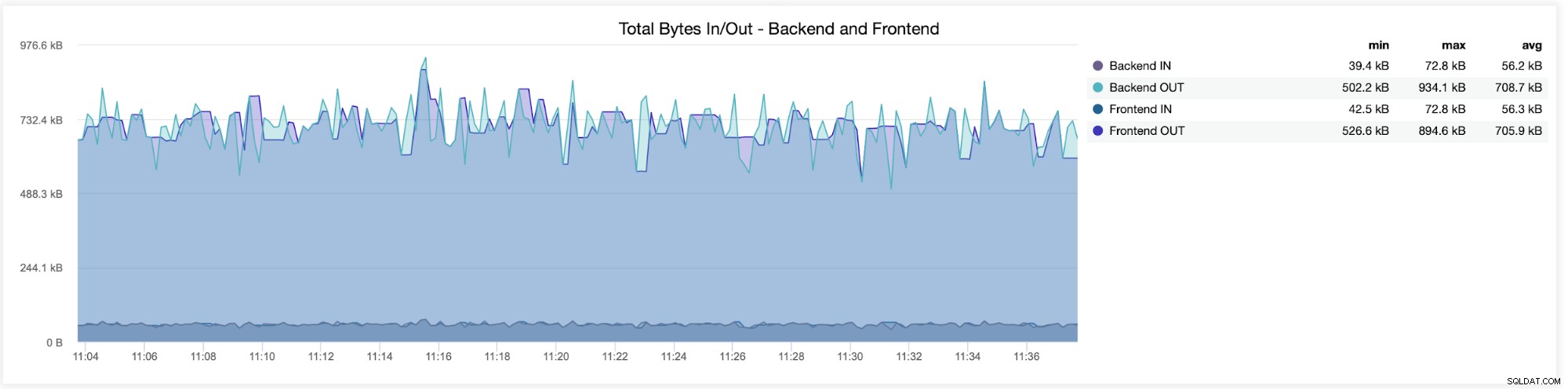
In der folgenden Grafik sehen Sie die von beiden gesendeten und empfangenen Daten Backend (von HAProxy zu den Datenbankservern) und Frontend (zwischen HAProxy und Client-Hosts):
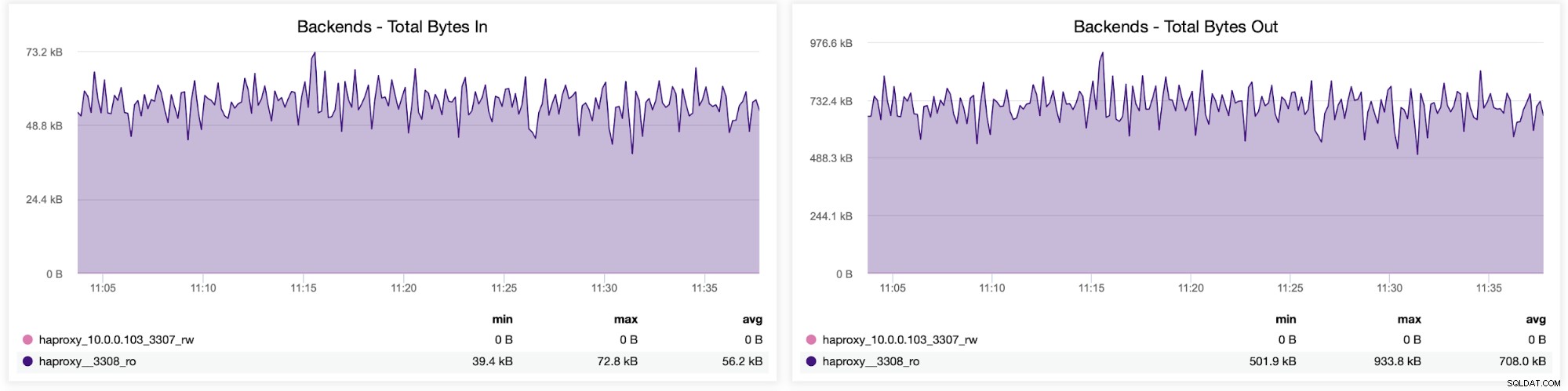
Sie können auch die Verkehrsverteilung zwischen Backends in Ihrer HAProxy-Konfiguration überprüfen. In diesem Fall haben wir zwei Backends und die Abfragen werden über Port 3308 gesendet, der als Round-Robin-Zugangspunkt zu unserem Galera-Cluster fungiert:
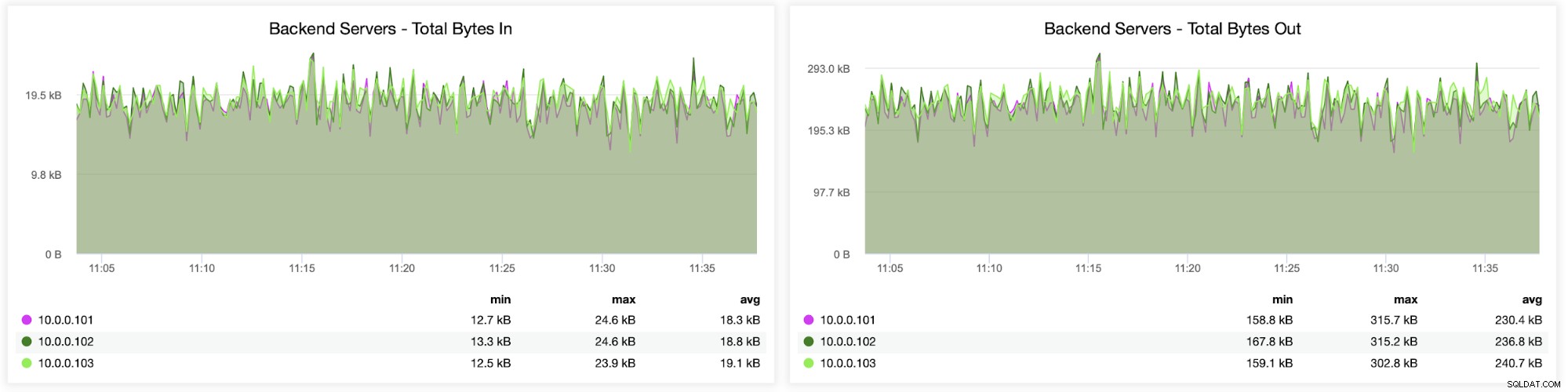
Als Nächstes können Sie sehen, wie der Datenverkehr auf alle Backend-Server verteilt wurde. In diesem Szenario wurden die Daten aufgrund des Round-Robin-Zugriffsmusters mehr oder weniger gleichmäßig auf alle drei Galera-Backend-Server verteilt:
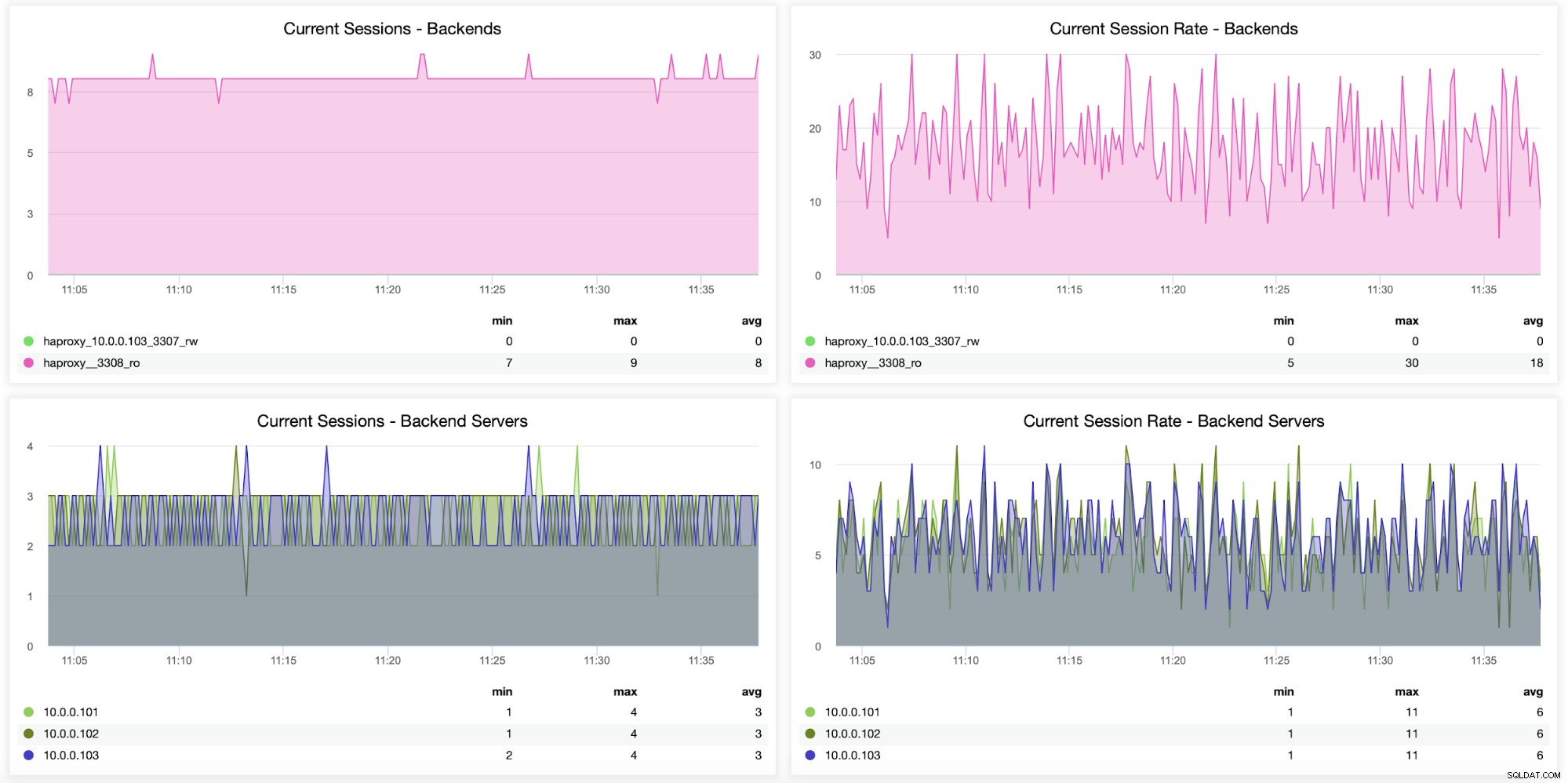
Informationen zu Sitzungen, einschließlich der Anzahl Sitzungen, die von HAProxy zum Backend geöffnet wurden Server, können ebenfalls überwacht werden, wie in der folgenden Grafik zu sehen ist. Sie können auch nachverfolgen, wie oft pro Sekunde eine neue Sitzung für das Backend geöffnet wurde und wie diese Metriken pro Backend-Server aussehen.
Die folgenden zwei Diagramme zeigen die maximale Anzahl von Sitzungen pro Back-End-Server und wann Konnektivitätsprobleme sind aufgetreten. Dies kann für Debugging-Zwecke sehr nützlich sein, wenn Sie auf Ihrer HAProxy-Instanz auf einen Konfigurationsfehler stoßen und die Verbindungen abbrechen.
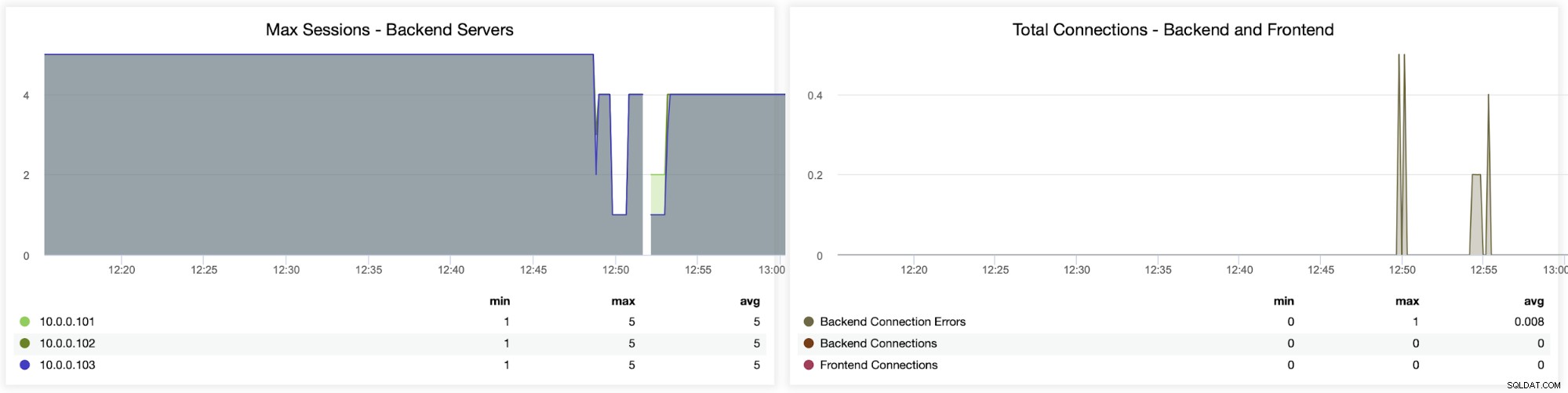
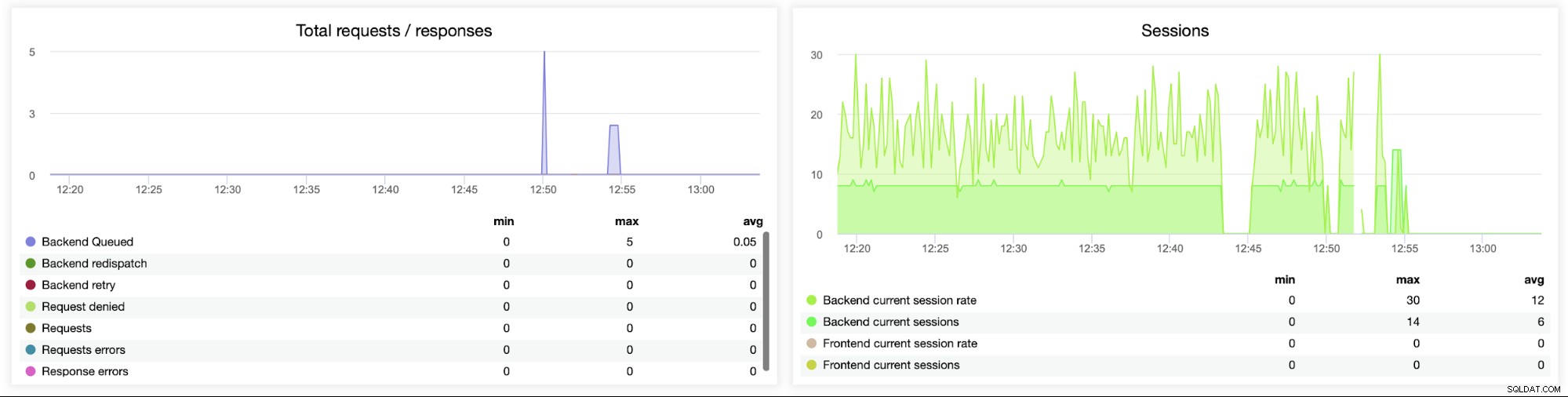
Dieses nächste Diagramm ist möglicherweise wertvoller, da es verschiedene Metriken im Zusammenhang mit Fehlern zeigt B. Fehler, Anforderungsfehler, Wiederholungen auf der Backend-Seite usw. Es gibt auch ein „Sitzungen“-Diagramm, das einen Überblick über die Sitzungsmetriken zeigt.
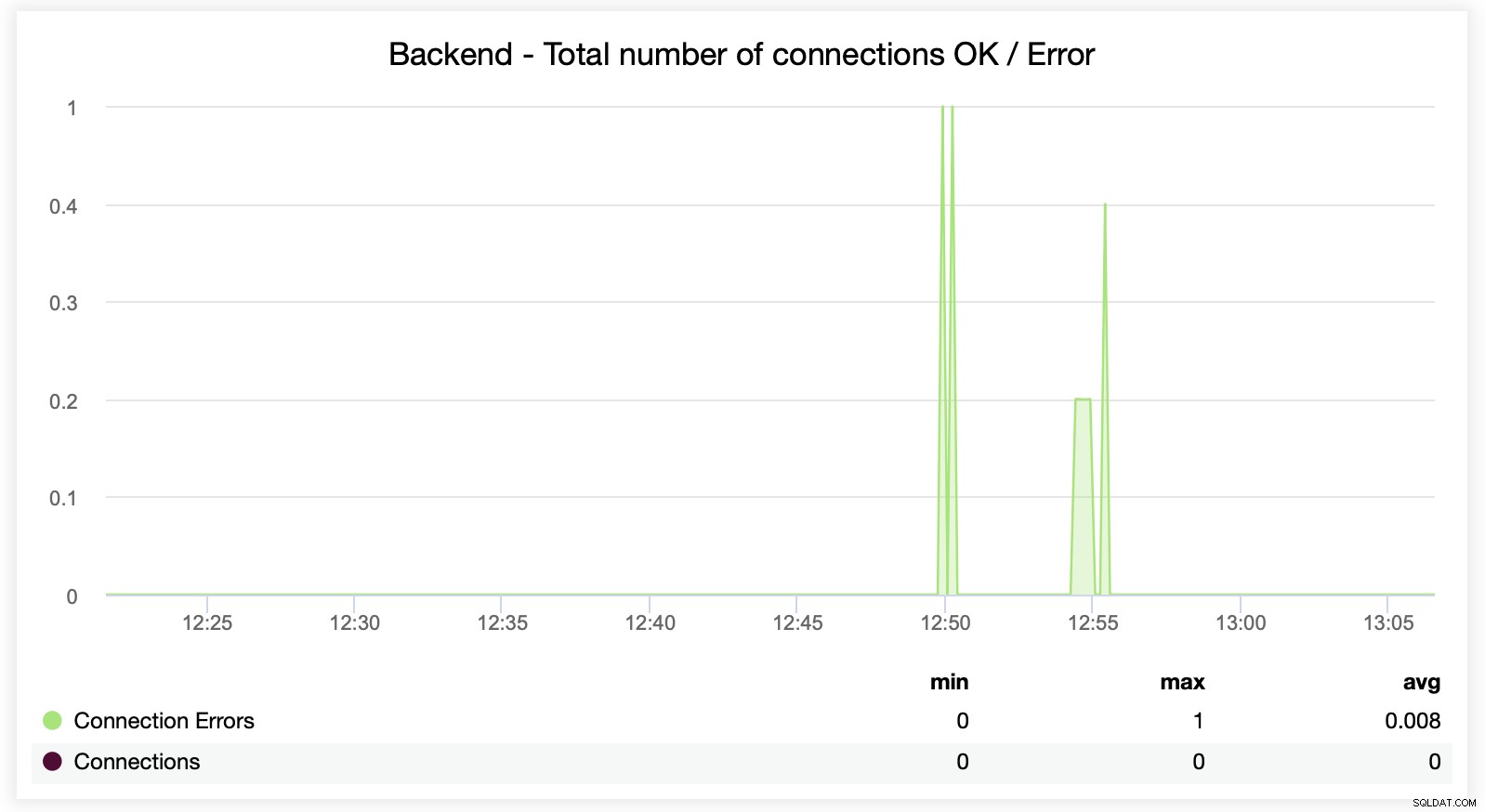
Hier können Sie sehen, dass ClusterControl die Verbindungsfehler in Echtzeit verfolgt, Dies kann helfen, den genauen Zeitpunkt zu bestimmen, zu dem die Probleme aufgetreten sind.
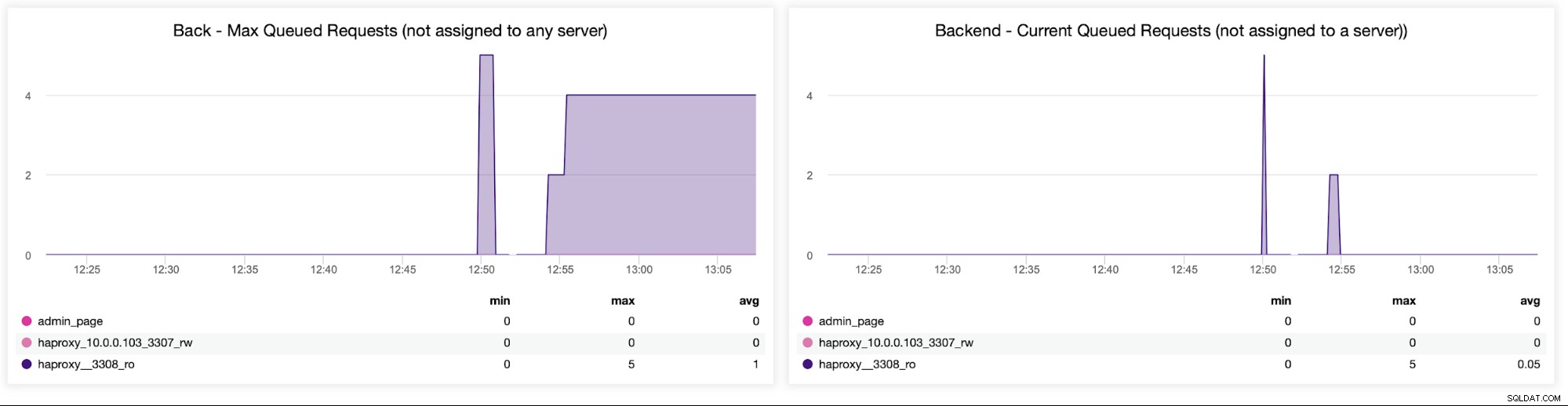
Schließlich sehen wir uns die folgenden zwei Diagramme zu Anfragen in der Warteschlange an . HAProxy stellt Anfragen an das Backend in eine Warteschlange, wenn die Backend-Server überlastet sind. Dies kann zB auf überlastete Datenbankserver hinweisen, die keinen Traffic mehr verarbeiten können.
Abschluss
Das Bereitstellen und Überwachen Ihres HAProxy-Load-Balancers in ClusterControl kann dazu beitragen, die Verwaltung und Überwachung Ihrer Verbindungen zu vereinfachen. Ein klarer Einblick in die Leistung Ihrer Back-Ends, Verkehrsverteilung, Sitzungsmetriken, Verbindungsfehler und die Anzahl der Anfragen in der Warteschlange kann dazu beitragen, die Verfügbarkeit und Skalierbarkeit jedes Datenbank-Setups sicherzustellen.
ClusterControl macht das Einrichten und Überwachen von Load Balancern für jede Datenbankkonfiguration zum Kinderspiel. Sie verwenden ClusterControl noch nicht? Wenn Sie sich selbst davon überzeugen möchten, wie einfach es ist, Ihren HAProxy-Load-Balancer mit ClusterControl bereitzustellen und zu überwachen, laden wir Sie zu einer kostenlosen 30-tägigen Testversion der Plattform ein, an die keine Bedingungen geknüpft sind. Eine ausführlichere Anleitung dazu, warum und wie HAProxy für den Lastenausgleich verwendet wird, finden Sie in unserem Tutorial zum MySQL-Lastenausgleich mit HAProxy.