Load Balancer sind eine wesentliche Komponente für die Hochverfügbarkeit von Datenbanken. insbesondere wenn Topologieänderungen für Anwendungen transparent gemacht werden und eine Read-Write-Split-Funktionalität implementiert wird. ClusterControl bietet eine Reihe von Funktionen zum sicheren Bereitstellen, Überwachen und Konfigurieren der branchenführenden Open-Source-Load-Balancing-Technologien.
Im vergangenen Jahr haben wir die Unterstützung für ProxySQL hinzugefügt und mehrere Verbesserungen für HAProxy und Maxscale von MariaDB hinzugefügt. Wir setzen diese Tradition mit der neuesten Version von ClusterControl 1.5 fort.
Basierend auf dem Feedback, das wir von unseren Benutzern erhalten haben, haben wir die Verwaltung von ProxySQL verbessert. Wir haben auch Unterstützung für HAProxy und Keepalived hinzugefügt, um auf PostgreSQL-Clustern ausgeführt zu werden.
In diesem Blogpost werden wir uns diese Verbesserungen ansehen...
ProxySQL - Verbesserungen der Benutzerverwaltung
Zuvor erlaubte Ihnen die Benutzeroberfläche nur, einen neuen Benutzer zu erstellen oder einen vorhandenen hinzuzufügen, einen nach dem anderen. Ein Feedback, das wir von unseren Benutzern erhalten haben, war, dass es ziemlich schwierig ist, eine große Anzahl von Benutzern zu verwalten. Wir haben zugehört und in ClusterControl 1.5 ist es jetzt möglich, große Gruppen von Benutzern zu importieren. Schauen wir uns an, wie Sie das tun können. Zunächst müssen Sie Ihr ProxySQL bereitstellen. Gehen Sie dann zum ProxySQL-Knoten, und auf der Registerkarte „Benutzer“ sollte die Schaltfläche „Benutzer importieren“ angezeigt werden.

Sobald Sie darauf klicken, öffnet sich ein neues Dialogfeld:

Hier sehen Sie alle Benutzer, die ClusterControl auf Ihrem Cluster erkannt hat. Sie können durch sie blättern und diejenigen auswählen, die Sie importieren möchten. Sie können auch alle Benutzer in einer aktuellen Ansicht auswählen oder deren Auswahl aufheben.

Sobald Sie mit der Eingabe in das Suchfeld beginnen, filtert ClusterControl nicht übereinstimmende Ergebnisse heraus und schränkt die Liste nur auf Benutzer ein, die für Ihre Suche relevant sind.
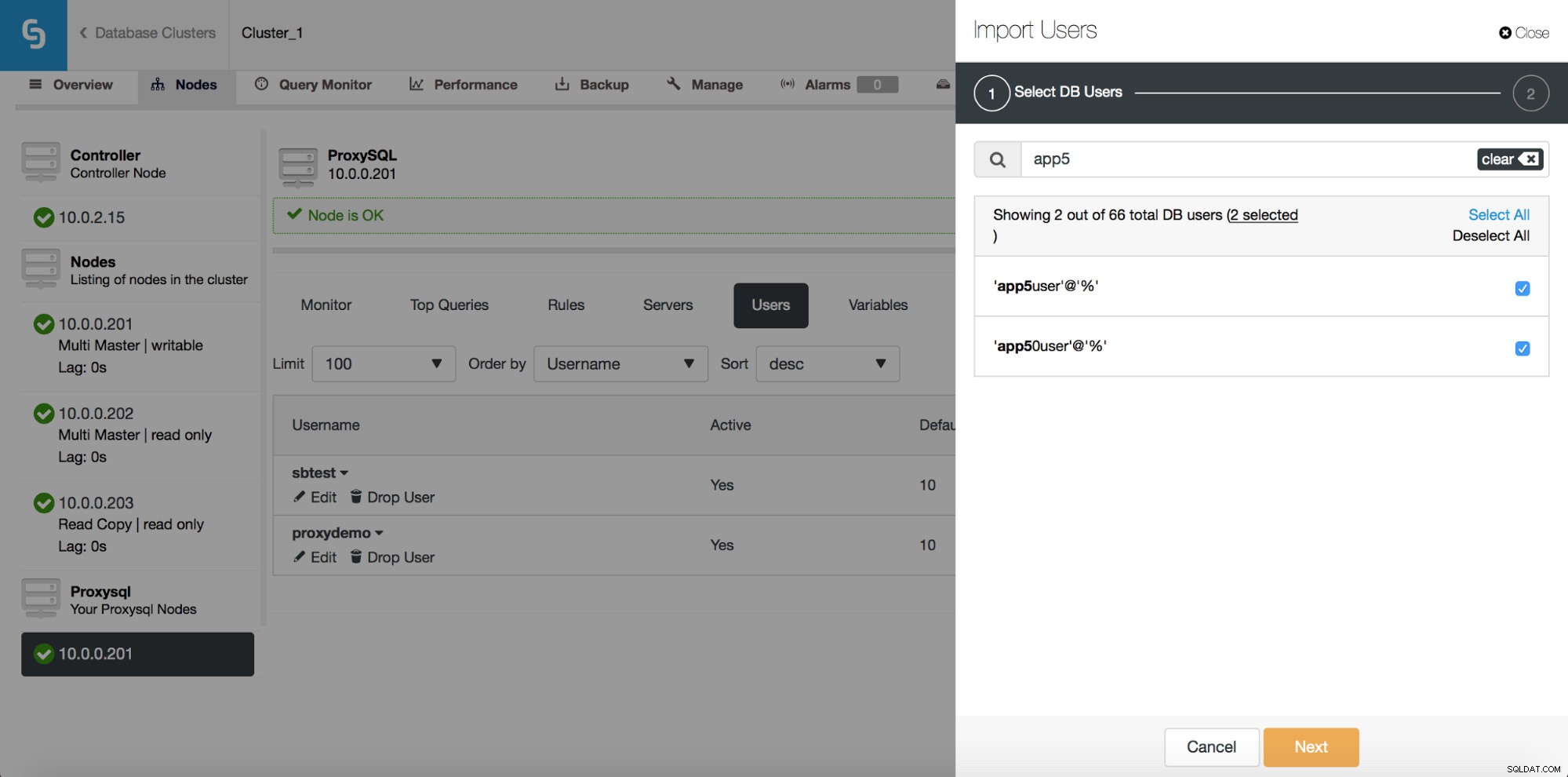
Mit der Schaltfläche „Alle auswählen“ können Sie alle Benutzer auswählen, die Ihrer Suche entsprechen. Nachdem Sie Benutzer ausgewählt haben, die Sie importieren möchten, können Sie natürlich das Suchfeld löschen und eine neue Suche starten:

Bitte beachten Sie „(7 ausgewählt)“ – es zeigt Ihnen, wie viele Benutzer insgesamt (nicht nur aus dieser Suche) Sie zum Importieren ausgewählt haben. Sie können auch darauf klicken, um nur die Benutzer anzuzeigen, die Sie zum Importieren ausgewählt haben.

Wenn Sie mit Ihrer Auswahl zufrieden sind, können Sie auf „Weiter“ klicken, um zum nächsten Bildschirm zu gelangen.

Hier müssen Sie entscheiden, was die Standard-Hostgruppe für jeden Benutzer sein soll. Sie können dies auf Benutzerbasis oder global tun, für die gesamte Gruppe oder eine Untergruppe von Benutzern, die sich aus einer Suche ergeben.

Sobald Sie auf die Schaltfläche „Benutzer importieren“ klicken, werden Benutzer importiert und auf der Registerkarte „Benutzer“ angezeigt.
ProxySQL - Scheduler-Verwaltung
Der Scheduler von ProxySQL ist ein Cron-ähnliches Modul, das es ProxySQL ermöglicht, externe Skripte in regelmäßigen Abständen zu starten. Der Zeitplan kann sehr granular sein – bis zu einer Ausführung pro Millisekunde. Normalerweise wird der Scheduler zum Ausführen von Galera-Prüfskripten (wie proxysql_galera_checker.sh) verwendet, aber er kann auch verwendet werden, um jedes andere Skript Ihrer Wahl auszuführen. In der Vergangenheit hat ClusterControl den Scheduler verwendet, um das Galera-Checker-Skript bereitzustellen, aber dies wurde nicht in der Benutzeroberfläche angezeigt. Ab ClusterControl 1.5 haben Sie nun die volle Kontrolle.

Wie Sie sehen können, wurde alle 2 Sekunden (2000 Millisekunden) ein Skript ausgeführt - dies ist die Standardkonfiguration für den Galera-Cluster.

Der obige Screenshot zeigt uns Optionen zum Bearbeiten bestehender Einträge. Bitte beachten Sie, dass ProxySQL bis zu 5 Argumente für die Skripte unterstützt, die es über den Planer ausführt.

Wenn Sie möchten, dass dem Planer ein neues Skript hinzugefügt wird, können Sie auf die Schaltfläche „Neues Skript hinzufügen“ klicken, und Ihnen wird ein Bildschirm wie der obige angezeigt. Sie können auch eine Vorschau anzeigen, wie das vollständige Skript bei der Ausführung aussehen wird. Nachdem Sie alle „Argument“-Felder ausgefüllt und das Intervall definiert haben, können Sie auf die Schaltfläche „Add New Script“ klicken.

Als Ergebnis wird ein Skript zum Planer hinzugefügt und in der Liste der geplanten Skripts angezeigt.
Laden Sie noch heute das Whitepaper PostgreSQL-Verwaltung und -Automatisierung mit ClusterControl herunterErfahren Sie, was Sie wissen müssen, um PostgreSQL bereitzustellen, zu überwachen, zu verwalten und zu skalierenLaden Sie das Whitepaper herunterPostgreSQL – Erstellen des Hochverfügbarkeits-Stacks
Das Einrichten der Replikation mit automatischem Failover ist gut, aber Anwendungen benötigen eine einfache Möglichkeit, den beschreibbaren Master zu verfolgen. Daher haben wir zusätzlich zu den PostgreSQL-Clustern Unterstützung für HAProxy und Keepalived hinzugefügt. Dadurch können unsere PostgreSQL-Benutzer einen vollständigen Stack mit hoher Verfügbarkeit mithilfe von ClusterControl bereitstellen.

Auf der Unterregisterkarte „Load Balancer“ können Sie jetzt HAProxy bereitstellen – wenn Sie damit vertraut sind, wie ClusterControl die MySQL-Replikation bereitstellt, handelt es sich um ein sehr ähnliches Setup. Wir installieren HAProxy auf einem bestimmten Host, zwei Backends, lesen auf Port 3308 und schreiben auf Port 3307. Es verwendet tcp-check und erwartet, dass eine bestimmte Zeichenfolge zurückgegeben wird. Um diese Zeichenfolge zu erzeugen, werden die folgenden Schritte auf allen Datenbankknoten ausgeführt. Zunächst einmal ist xinet.d so konfiguriert, dass ein Dienst auf Port 9201 ausgeführt wird (um Verwechslungen mit dem MySQL-Setup zu vermeiden, das Port 9200 verwendet).
# default: on
# description: postgreschk
service postgreschk
{
flags = REUSE
socket_type = stream
port = 9201
wait = no
user = root
server = /usr/local/sbin/postgreschk
log_on_failure += USERID
disable = no
#only_from = 0.0.0.0/0
only_from = 0.0.0.0/0
per_source = UNLIMITEDDer Dienst führt das Skript /usr/local/sbin/postgreschk aus, das den Status von PostgreSQL validiert und angibt, ob ein bestimmter Host verfügbar ist und um welchen Hosttyp es sich handelt (Master oder Slave). Wenn alles in Ordnung ist, gibt es den von HAProxy erwarteten String zurück.
Genau wie bei MySQL werden HAProxy-Knoten in PostgreSQL-Clustern in der Benutzeroberfläche angezeigt und es kann auf die Statusseite zugegriffen werden:

Hier können Sie beide Backends sehen und überprüfen, ob nur der Master für das R/W-Backend aktiv ist und auf alle Knoten über das schreibgeschützte Backend zugegriffen werden kann. Sie können auch einige Statistiken über Verkehr und Verbindungen erhalten.
HAProxy trägt zur Verbesserung der Hochverfügbarkeit bei, kann jedoch zu einem Single Point of Failure werden. Wir müssen noch einen Schritt weiter gehen und mithilfe von Keepalived Redundanz konfigurieren.

Unter Verwalten -> Load Balancer -> Keepalived wählen Sie die HAProxy-Hosts aus, die Sie verwenden möchten, und Keepalived wird darüber mit einer virtuellen IP bereitgestellt, die an die Schnittstelle Ihrer Wahl angehängt ist.
Von nun an sollte die gesamte Konnektivität zum VIP gehen, das an einen der HAProxy-Knoten angeschlossen wird. Wenn dieser Knoten ausfällt, nimmt Keepalived die VIP auf diesem Knoten herunter und bringt sie auf einem anderen HAProxy-Knoten hoch.
Das war es für die in ClusterControl 1.5 eingeführten Load-Balancing-Funktionen. Probieren Sie sie aus und lassen Sie uns wissen, wie Sie