In diesem Blogbeitrag werden wir uns einige wichtige Metriken und den Status bei der Überwachung eines Percona-Servers für MySQL ansehen, um uns bei der langfristigen Feinabstimmung der MySQL-Serverkonfiguration zu helfen. Nur zur Erinnerung:Percona Server verfügt über einige Überwachungsmetriken, die nur in diesem Build verfügbar sind. Beim Vergleich mit Version 8.0.20 sind die folgenden 51 Status nur auf Percona Server for MySQL verfügbar, die auf dem Upstream-MySQL-Community-Server von Oracle nicht verfügbar sind:
- Binlog_snapshot_file
- Binlog_snapshot_position
- Binlog_snapshot_gtid_executed
- Com_create_compression_dictionary
- Com_drop_compression_dictionary
- Com_lock_tables_for_backup
- Com_show_client_statistics
- Com_show_index_statistics
- Com_show_table_statistics
- Com_show_thread_statistics
- Com_show_user_statistics
- Innodb_background_log_sync
- Innodb_buffer_pool_pages_LRU_flushed
- Innodb_buffer_pool_pages_made_not_young
- Innodb_buffer_pool_pages_made_young
- Innodb_buffer_pool_pages_old
- Innodb_checkpoint_age
- Innodb_ibuf_free_list
- Innodb_ibuf_segment_size
- Innodb_lsn_current
- Innodb_lsn_flushed
- Innodb_lsn_last_checkpoint
- Innodb_master_thread_active_loops
- Innodb_master_thread_idle_loops
- Innodb_max_trx_id
- Innodb_oldest_view_low_limit_trx_id
- Innodb_pages0_read
- Innodb_purge_trx_id
- Innodb_purge_undo_no
- Innodb_secondary_index_triggered_cluster_reads
- Innodb_secondary_index_triggered_cluster_reads_avoided
- Innodb_buffered_aio_submitted
- Innodb_scan_pages_contiguous
- Innodb_scan_pages_disjointed
- Innodb_scan_pages_total_seek_distance
- Innodb_scan_data_size
- Innodb_scan_deleted_recs_size
- Innodb_scrub_log
- Innodb_scrub_background_page_reorganizations
- Innodb_scrub_background_page_splits
- Innodb_scrub_background_page_split_failures_underflow
- Innodb_scrub_background_page_split_failures_out_of_filespace
- Innodb_scrub_background_page_split_failures_missing_index
- Innodb_scrub_background_page_split_failures_unknown
- Innodb_encryption_n_merge_blocks_encrypted
- Innodb_encryption_n_merge_blocks_decrypted
- Innodb_encryption_n_rowlog_blocks_encrypted
- Innodb_encryption_n_rowlog_blocks_decrypted
- Innodb_encryption_redo_key_version
- Threadpool_idle_threads
- Threadpool_threads
Weitere Informationen zu jeder der oben genannten Überwachungsmetriken finden Sie auf der Seite „Erweiterter InnoDB-Status“. Beachten Sie, dass einige zusätzliche Status wie Thread-Pool nur in MySQL Enterprise von Oracle verfügbar sind. Sehen Sie sich die Percona Server for MySQL 8.0-Dokumentation an, um alle Verbesserungen speziell für diesen Build gegenüber MySQL Community Server 8.0 von Oracle zu sehen.
Um den globalen MySQL-Status abzurufen, verwenden Sie einfach eine der folgenden Anweisungen:
mysql> SHOW GLOBAL STATUS;
mysql> SHOW GLOBAL STATUS LIKE '%connect%'; -- list all status that contain string "connect"
mysql> SELECT * FROM performance_schema.global_status;
mysql> SELECT * FROM performance_schema.global_status WHERE VARIABLE_NAME LIKE '%connect%'; -- list all status that contain string "connect"Datenbankstatus und Übersicht
Wir beginnen mit dem Betriebszeitstatus, der Anzahl der Sekunden, die der Server aktiv war.
Alle com_*-Status sind die Anweisungszählervariablen, die angeben, wie oft jede Anweisung ausgeführt wurde. Für jeden Anweisungstyp gibt es eine Statusvariable. Beispielsweise zählen com_delete und com_update DELETE- bzw. UPDATE-Anweisungen. com_delete_multi und com_update_multi sind ähnlich, gelten aber für DELETE- und UPDATE-Anweisungen, die eine Mehrtabellensyntax verwenden.
Um alle laufenden Prozesse von MySQL aufzulisten, führen Sie einfach eine der folgenden Anweisungen aus:
mysql> SHOW PROCESSLIST;
mysql> SHOW FULL PROCESSLIST;
mysql> SELECT * FROM information_schema.processlist;
mysql> SELECT * FROM information_schema.processlist WHERE command <> 'sleep'; -- list all active processes except 'sleep' command.Verbindungen und Threads
Aktuelle Verbindungen
Das Verhältnis der aktuell offenen Verbindungen (Verbindungsthread). Wenn das Verhältnis hoch ist, weist dies darauf hin, dass viele gleichzeitige Verbindungen zum MySQL-Server bestehen, und könnte zu einem „Zu viele Verbindungen“-Fehler führen. So erhalten Sie den Verbindungsprozentsatz:
Current connections(%) = (threads_connected / max_connections) x 100Ein guter Wert sollte bei 80 % und darunter liegen. Versuchen Sie, die Variable max_connections zu erhöhen, oder überprüfen Sie die Verbindungen mit SHOW FULL PROCESSLIST. Wenn der Fehler „Zu viele Verbindungen“ auftritt, ist der MySQL-Datenbankserver für Nicht-Superuser nicht mehr verfügbar, bis einige Verbindungen freigegeben werden. Beachten Sie, dass das Erhöhen der max_connections-Variablen möglicherweise auch den Speicherverbrauch von MySQL erhöhen könnte.
Maximale Verbindungen aller Zeiten
Das Verhältnis der maximalen jemals beobachteten Verbindungen zum MySQL-Server. Eine einfache Berechnung wäre:
Max connections ever seen(%) = (max_used_connections / max_connections) x 100Der gute Wert sollte unter 80% liegen. Wenn das Verhältnis hoch ist, weist dies darauf hin, dass MySQL einmal eine hohe Anzahl von Verbindungen erreicht hat, was zu dem Fehler „zu viele Verbindungen“ führen würde. Überprüfen Sie das aktuelle Verbindungsverhältnis, um festzustellen, ob es tatsächlich konstant niedrig bleibt. Erhöhen Sie andernfalls die Variable max_connections. Überprüfen Sie den max_used_connections_time-Status, um anzugeben, wann der max_used_connections-Status seinen aktuellen Wert erreicht hat.
Thread-Cache-Trefferrate
Der Status von threads_created ist die Anzahl der Threads, die zur Verarbeitung von Verbindungen erstellt wurden. Wenn threads_created groß ist, sollten Sie den Wert thread_cache_size erhöhen. Die Cache-Hit/Miss-Rate kann wie folgt berechnet werden:
Threads cache hit rate (%) = (threads_created / connections) x 100Es ist ein Bruchteil, der einen Hinweis auf die Thread-Cache-Trefferrate gibt. Je näher weniger als 50 %, desto besser. Wenn Ihr Server Hunderte von Verbindungen pro Sekunde sieht, sollten Sie thread_cache_size normalerweise hoch genug setzen, damit die meisten neuen Verbindungen zwischengespeicherte Threads verwenden.
Abfrageleistung
Vollständige Tabellenscans
Das Verhältnis von Full-Table-Scans, eine Operation, die das Lesen des gesamten Inhalts einer Tabelle erfordert, anstatt nur ausgewählte Teile mithilfe eines Index. Dieser Wert ist hoch, wenn Sie viele Abfragen ausführen, die eine Sortierung der Ergebnisse oder Tabellenscans erfordern. Im Allgemeinen deutet dies darauf hin, dass Tabellen nicht ordnungsgemäß indiziert sind oder dass Ihre Abfragen nicht so geschrieben sind, dass sie die vorhandenen Indizes nutzen. So berechnen Sie den Prozentsatz der vollständigen Tabellenscans:
Full table scans (%) = (handler_read_rnd_next + handler_read_rnd) /
(handler_read_rnd_next + handler_read_rnd + handler_read_first + handler_read_next + handler_read_key + handler_read_prev)
x 100Der gute Wert sollte unter 25% liegen. Untersuchen Sie die Ausgabe des MySQL-Protokolls für langsame Abfragen, um die suboptimalen Abfragen herauszufinden.
Vollständigen Beitritt auswählen
Der Status von select_full_join ist die Anzahl der Joins, die Table Scans durchführen, weil sie keine Indizes verwenden. Wenn dieser Wert nicht 0 ist, sollten Sie die Indizes Ihrer Tabellen sorgfältig überprüfen.
Bereichsprüfung auswählen
Der Status von select_range_check ist die Anzahl der Joins ohne Schlüssel, die die Schlüsselverwendung nach jeder Zeile überprüfen. Wenn dieser nicht 0 ist, sollten Sie die Indizes Ihrer Tabellen sorgfältig überprüfen.
Pässe sortieren
Das Verhältnis der Zusammenführungsdurchgänge, die der Sortieralgorithmus ausführen musste. Wenn dieser Wert hoch ist, sollten Sie den Wert von sort_buffer_size und read_rnd_buffer_size erhöhen. Eine einfache Verhältnisberechnung ist:
Sort passes = sort_merge_passes / (sort_scan + sort_range)Ein Verhältniswert kleiner als 3 sollte ein guter Wert sein. Wenn Sie sort_buffer_size oder read_rnd_buffer_size erhöhen möchten, versuchen Sie, in kleinen Schritten zu erhöhen, bis Sie das akzeptable Verhältnis erreichen.
InnoDB-Leistung
InnoDB-Pufferpool-Trefferrate
Das Verhältnis, wie oft Ihre Seiten aus dem Arbeitsspeicher statt von der Festplatte abgerufen werden. Wenn der Wert während des frühen MySQL-Starts niedrig ist, geben Sie dem Pufferpool bitte etwas Zeit zum Aufwärmen. Um die Pufferpool-Trefferrate abzurufen, verwenden Sie die SHOW ENGINE INNODB STATUS-Anweisung:
mysql> SHOW ENGINE INNODB STATUS\G
...
----------------------
BUFFER POOL AND MEMORY
----------------------
...
Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000
...Der beste Wert ist 1000 / 10000 Trefferquote. Bei einem niedrigeren Wert zeigt beispielsweise die Trefferquote von 986/1000 an, dass von 1000 gelesenen Seiten 986 Mal Seiten im RAM gelesen werden konnten. Die verbleibenden 14 Mal musste MySQL die Seiten von der Festplatte lesen. Einfach gesagt, 1000/1000 ist der beste Wert, den wir hier zu erreichen versuchen, was bedeutet, dass die häufig abgerufenen Daten vollständig in den Arbeitsspeicher passen.
Das Erhöhen der Variable innodb_buffer_pool_size wird viel dazu beitragen, mehr Platz für MySQL zu schaffen. Stellen Sie jedoch vorher sicher, dass Sie über ausreichende RAM-Ressourcen verfügen. Das Entfernen redundanter Indizes könnte ebenfalls hilfreich sein. Wenn Sie mehrere Buffer Pool-Instanzen haben, stellen Sie sicher, dass die Trefferquote für jede Instanz 1000/1000 erreicht.
Dirty Pages von InnoDB
Das Verhältnis, wie oft InnoDB geleert werden muss. Während der Schreiblast ist es normal, dass dieser Prozentsatz ansteigt.
Eine einfache Rechnung wäre:
InnoDB dirty pages(%) = (innodb_buffer_pool_pages_dirty / innodb_buffer_pool_pages_total) x 100Ein guter Wert sollte bei 75 % und darunter liegen. Wenn der Prozentsatz fehlerhafter Seiten lange Zeit hoch bleibt, sollten Sie den Pufferpool vergrößern oder schnellere Festplatten verwenden, um Leistungsengpässe zu vermeiden.
InnoDB wartet auf Checkpoint
Das Verhältnis, wie oft InnoDB eine Seite lesen oder erstellen muss, auf der keine sauberen Seiten verfügbar sind. Normalerweise erfolgen Schreibvorgänge in den InnoDB Buffer Pool im Hintergrund. Wenn es jedoch erforderlich ist, eine Seite zu lesen oder zu erstellen, und keine sauberen Seiten verfügbar sind, muss auch zuerst gewartet werden, bis die Seiten geleert sind. Der Zähler innodb_buffer_pool_wait_free zählt, wie oft dies passiert ist. Um das Verhältnis von InnoDB-Wartezeiten für Checkpoints zu berechnen, können wir die folgende Berechnung verwenden:
InnoDB waits for checkpoint = innodb_buffer_pool_wait_free / innodb_buffer_pool_write_requestsWenn innodb_buffer_pool_wait_free größer als 0 ist, ist dies ein starker Hinweis darauf, dass der InnoDB-Pufferpool zu klein ist und Operationen an einem Prüfpunkt warten mussten. Durch Erhöhen von innodb_buffer_pool_size wird normalerweise innodb_buffer_pool_wait_free sowie dieses Verhältnis verringert. Ein guter Verhältniswert sollte unter 1 bleiben.
InnoDB wartet auf Redolog
Das Verhältnis von Redo-Log-Konkurrenz. Überprüfen Sie innodb_log_waits und wenn es weiter zunimmt, erhöhen Sie die innodb_log_buffer_size. Es kann auch bedeuten, dass die Festplatten zu langsam sind und die Festplatten-E/A nicht aufrechterhalten können, möglicherweise aufgrund einer Spitzenschreiblast. Verwenden Sie die folgende Berechnung, um das Redo-Log-Warteverhältnis zu berechnen:
InnoDB waits for redolog = innodb_log_waits / innodb_log_writesEin guter Verhältniswert sollte unter 1 liegen. Andernfalls erhöhen Sie die innodb_log_buffer_size.
Tabellen
Tabellen-Cache-Nutzung
Das Verhältnis der Tabellen-Cache-Nutzung für alle Threads. Eine einfache Berechnung wäre:
Table cache usage(%) = (opened_tables / table_open_cache) x 100Der gute Wert sollte unter 80% liegen. Erhöhen Sie die Variable table_open_cache, bis der Prozentsatz einen guten Wert erreicht.
Tabellen-Cache-Trefferquote
Das Verhältnis der Nutzung von Tabellen-Cache-Treffern. Eine einfache Berechnung wäre:
Table cache hit ratio(%) = (open_tables / opened_tables) x 100Ein guter Wert für die Trefferquote sollte 90 % und mehr betragen. Erhöhen Sie andernfalls die table_open_cache-Variable, bis die Trefferquote einen guten Wert erreicht.
Messwertüberwachung mit ClusterControl
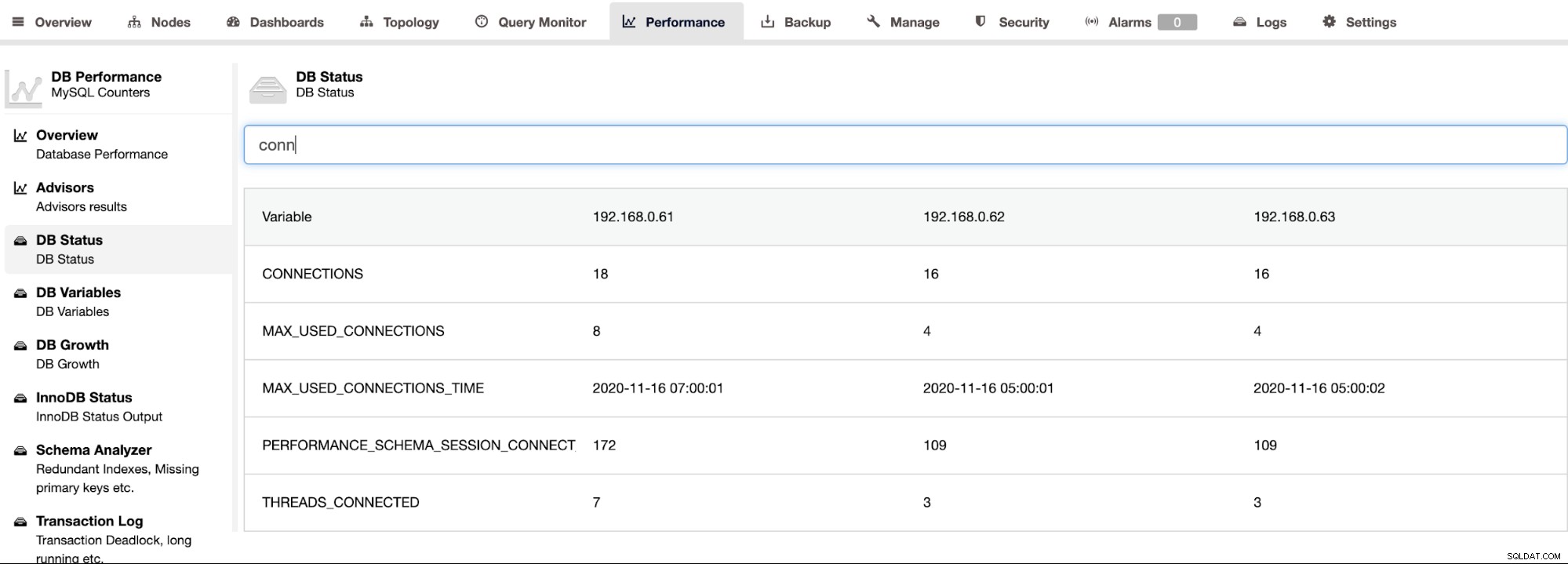
ClusterControl unterstützt Percona Server für MySQL und bietet eine aggregierte Ansicht aller Knoten in einem Cluster auf der Seite „ClusterControl -> Leistung -> DB-Status“. Dies bietet einen zentralisierten Ansatz zum Suchen nach dem gesamten Status auf allen Hosts mit der Möglichkeit, den Status zu filtern, wie im folgenden Screenshot gezeigt:
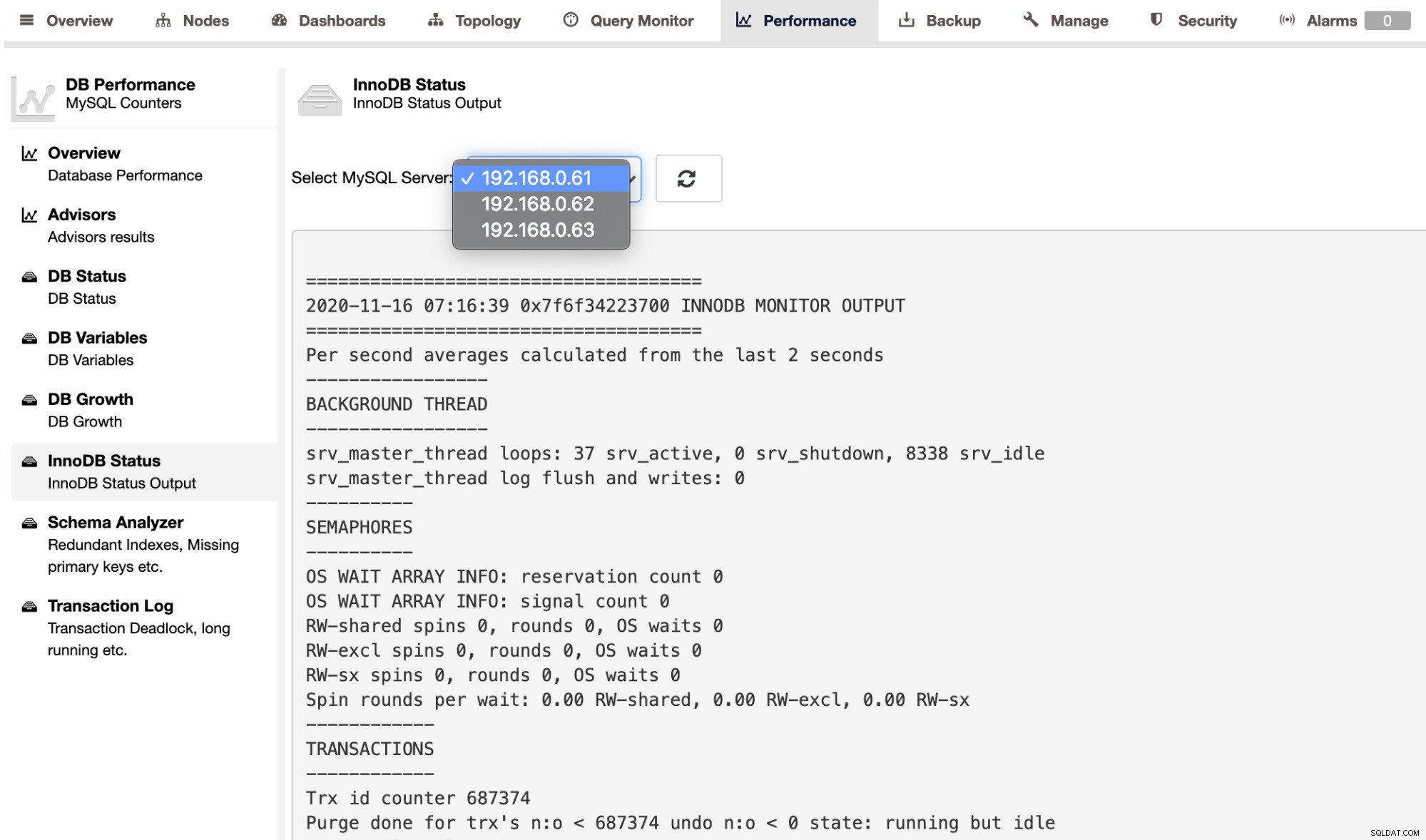
Sie können die INNODB-STATUS-Ausgabe von SHOW ENGINE für einen einzelnen Server abrufen Verwenden Sie die Seite Leistung -> InnoDB-Status, wie unten gezeigt:
ClusterControl bietet auch integrierte Advisors, mit denen Sie Ihre Datenbank verfolgen können Leistung. Auf diese Funktion kann unter ClusterControl -> Performance -> Advisors:
zugegriffen werden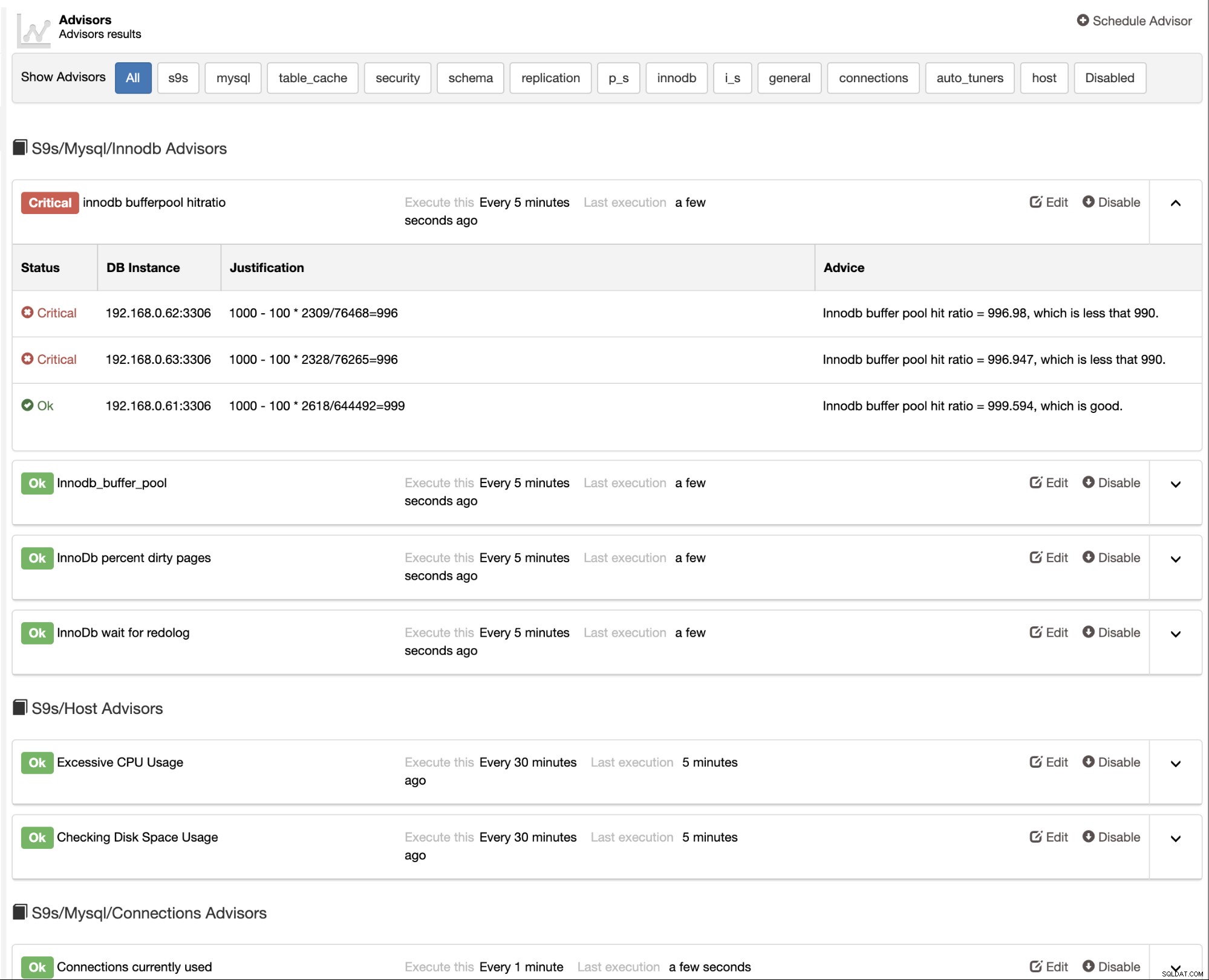
Advisors sind im Wesentlichen Miniprogramme, die von ClusterControl in einem geplanten Timing wie Cron ausgeführt werden Arbeitsplätze. Sie können einen Advisor planen, indem Sie auf die Schaltfläche "Advisor planen" klicken und einen beliebigen vorhandenen Advisor aus der Developer Studio-Objektstruktur auswählen:
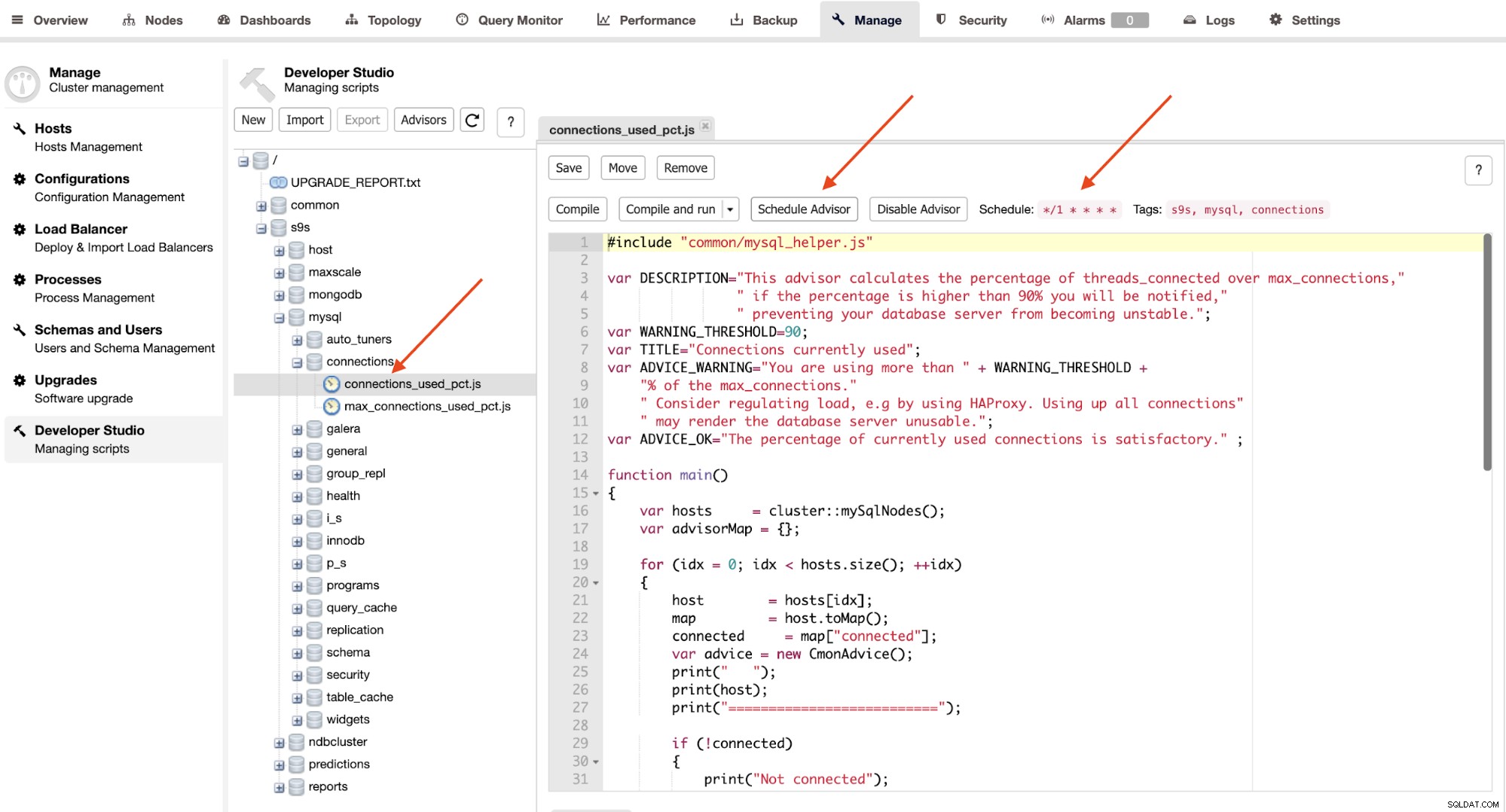
Klicken Sie auf die Schaltfläche „Schedule Advisor“, um das Planungsargument festzulegen Pass und auch die Tags des Beraters. Sie können den Ratgeber auch so kompilieren, dass die Ausgabe sofort angezeigt wird, indem Sie auf die Schaltfläche „Kompilieren und ausführen“ klicken, wo Sie die folgende Ausgabe unter den „Nachrichten“ darunter sehen sollten:

Sie können Ihren eigenen Ratgeber erstellen, indem Sie sich auf dieses Entwicklerhandbuch beziehen, das in geschrieben ist ClusterControl Domain Specific Language (sehr ähnlich zu Javascript), oder passen Sie einen vorhandenen Advisor an Ihre Überwachungsrichtlinien an. Kurz gesagt, die Überwachung von ClusterControl kann durch ClusterControl Advisors um unbegrenzte Möglichkeiten erweitert werden.