ClusterControl 1.7.1 führt eine neue Funktion namens Create Cluster from Backup ein, mit der Sie einen neuen MySQL- oder Postgres-basierten Cluster bereitstellen und Daten darauf aus einer Sicherung wiederherstellen können. Dieser Blog-Beitrag zeigt, wie diese neue Funktion funktioniert und wie diese Art der Automatisierung zu Verbesserungen Ihres Infrastrukturbetriebs führen kann.
Einführung:Cluster aus Backup erstellen
Die Sicherungsverwaltung ist die beliebteste Funktion unserer Benutzer, und wir haben sie gerade auf die nächste Stufe gehoben. Diese neue Funktionalität klingt einfach - ClusterControl 1.7.1 ist in der Lage, einen neuen Cluster aus einem bestehenden Backup bereitzustellen. Es sind jedoch mehrere Verfahren und Prüfungen erforderlich, um einen produktionstauglichen Cluster direkt aus einem Backup bereitzustellen. Die Wiederherstellung selbst bringt ihre eigenen Herausforderungen mit sich, wie zum Beispiel:
- Konsequenzen der vollständigen oder teilweisen Wiederherstellung
- Grundsicherung und Reihenfolge der inkrementellen Sicherungen (für inkrementelle Sicherung)
- Backup-Entschlüsselung (falls verschlüsselt)
- Optionen des Wiederherstellungswerkzeugs
- Dekomprimierung (falls komprimiert)
- Backup-Streaming vom Quell- zum Zielserver
- Speicherplatznutzung während und nach der Wiederherstellung
- Bericht über den Fortschritt der Wiederherstellung
Kombinieren Sie das Obige mit der Komplexität und Wiederholungshäufigkeit von Aufgaben zur Bereitstellung von Datenbankclustern, können Sie Zeit sparen und das Risiko bei der Ausführung fehleranfälliger Verfahren verringern. Der schwierigste Teil aus der Sicht des Benutzers ist die Auswahl des Backups, aus dem wiederhergestellt werden soll. ClusterControl kümmert sich hinter den Kulissen um das ganze schwere Heben und meldet das Endergebnis, sobald es fertig ist.
Die Schritte sind im Grunde einfach:
- Passwortloses SSH vom ClusterControl-Knoten zu den neuen Servern einrichten.
- Wählen Sie ein logisches Backup aus der Backup-Liste oder erstellen Sie eines unter Backups -> Backup erstellen .
- Klicken Sie auf Wiederherstellen -> Cluster aus Sicherung erstellen und folgen Sie dem Bereitstellungsassistenten.
Diese Funktion wurde derzeit speziell für MySQL Galera Cluster und PostgreSQL entwickelt. Folgendes würden Sie in der Benutzeroberfläche sehen, nachdem Sie bei einer vorhandenen Sicherung auf „Wiederherstellen“ geklickt haben:

Die untere Option ist das, wonach wir suchen. Als nächstes folgt der Zusammenfassungsdialog für das ausgewählte Backup vor der Bereitstellungskonfiguration:

Als nächstes wird derselbe Datenbank-Cluster-Bereitstellungsassistent für den jeweiligen Cluster (MySQL Galera Cluster oder PostgreSQL) angezeigt, um einen neuen Cluster zu konfigurieren:

Beachten Sie, dass Sie den gleichen Datenbank-Root/Admin-Benutzernamen und das gleiche Passwort wie in der Sicherung angeben müssen. Andernfalls würde die Bereitstellung beim Starten des ersten Knotens auf halbem Weg fehlschlagen. Im Allgemeinen finden Wiederherstellungs- und Bereitstellungsverfahren in der folgenden Reihenfolge statt:
- Installieren Sie notwendige Software und Abhängigkeiten auf allen Datenbankknoten.
- Starte den ersten Knoten.
- Backup auf dem ersten Knoten streamen und wiederherstellen (mit Auto-Neustart-Flag).
- Konfigurieren und fügen Sie die restlichen Knoten hinzu.
Ein neuer Datenbank-Cluster wird unter ClusterControl-Cluster-Dashboard aufgelistet, sobald der Job abgeschlossen ist.
Was können Sie davon profitieren?
Es gibt eine Reihe von Dingen, die Sie von dieser Funktion profitieren könnten, wie in den folgenden Abschnitten erläutert wird.
Testen Sie Ihren Datensatz unter verschiedenen Bedingungen
Manchmal fragen Sie sich vielleicht, ob die neue Datenbankversion für Ihre Datenbank-Workload funktionieren oder funktionieren würde, und das Ausprobieren ist der einzige Weg, dies herauszufinden. Hier kommt diese Funktion ins Spiel. Es ermöglicht Ihnen, Tests und Benchmarks für viele beteiligte Variablen durchzuführen, die sich auf die Datenbankstabilität oder -leistung auswirken würden, z. B. die zugrunde liegende Hardware, Softwareversion, Anbieter und Datenbank- oder Anwendungsworkloads.
Als einfaches Beispiel gibt es eine große Verbesserung bei der DDL-Ausführung zwischen MySQL 5.6 und MySQL 5.7. Die folgende DROP-Operation für eine Tabelle mit 10 Millionen Zeilen beweist alles:
mysql-5.7> ALTER TABLE sbtest1 DROP COLUMN xx;
Query OK, 0 rows affected (1 min 58.12 sec)mysql-5.6> ALTER TABLE sbtest1 DROP COLUMN xx;
Query OK, 0 rows affected (2 min 23.74 sec)Wenn wir einen anderen Cluster zum Vergleich haben, können wir tatsächlich die Verbesserung messen und eine Migration rechtfertigen.
Datenbankmigration mit logischem Backup
Logisches Backup wie mysqldump und pg_dumpall ist der sicherste Weg, Ihre Daten von einer Version oder einem Anbieter zu einem anderen zu aktualisieren, herunterzustufen oder zu migrieren. Alle logischen Sicherungen können zur Datenbankmigration verwendet werden. Die Schritte zum Datenbank-Upgrade sind im Grunde einfach:
- Erstellen (oder planen) Sie ein logisches Backup – mysqldump für MySQL oder pg_dumpall für PostgreSQL
- Passwortloses SSH vom ClusterControl-Knoten zu den neuen Servern einrichten.
- Wählen Sie ein erstelltes logisches Backup aus der Backup-Liste aus.
- Klicken Sie auf Wiederherstellen -> Cluster aus Sicherung erstellen und folgen Sie dem Bereitstellungsassistenten.
- Überprüfen Sie die Datenwiederherstellung auf dem neuen Cluster.
- Verweisen Sie Ihre Anwendung auf den neuen Cluster.
Schnellere gesamte Cluster-Wiederherstellungszeit
Stellen Sie sich einen katastrophalen Ausfall vor, der die Ausführung Ihres Clusters verhindert, wie zum Beispiel ein zentralisierter Speicherausfall, der alle damit verbundenen virtuellen Maschinen betrifft, Sie könnten fast sofort einen Ersatzcluster erhalten (vorausgesetzt, die Sicherungsdateien werden außerhalb der ausgefallenen Datenbankknoten gespeichert). , das ofensichtliche erklären). Diese Funktion kann über den s9s-Client automatisiert werden, wo Sie einen Job über die Befehlszeilenschnittstelle auslösen können, zum Beispiel:
$ s9s cluster \
--create \
--cluster-type=postgresql \
--nodes="192.168.0.101?master;192.168.0.102?slave;192.168.0.103?slave" \
--provider-version=11 \
--db-admin=postgres \
--db-admin-passwd='s3cr3tP455' \
--os-user=root \
--os-key-file=/root/.ssh/id_rsa \
--cluster-name="PostgreSQL 9.6 - Test"
--backup-id=214 \
--logBeachten Sie bei der Verwendung dieser Funktion, dass Sie denselben Admin-Benutzernamen und dasselbe Kennwort verwenden, die in der Sicherung gespeichert sind. Auch das passwortlose SSH zu allen Datenbankknoten muss vorher konfiguriert werden. Andernfalls, wenn Sie es lieber interaktiv konfigurieren möchten, verwenden Sie einfach die Web-Benutzeroberfläche.
Skalieren über asynchrone Replikation
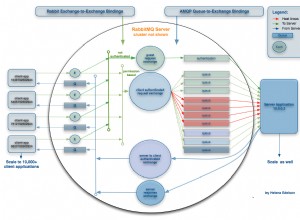
Für MySQL Galera Cluster hat der neu erstellte Cluster die Möglichkeit, über die asynchrone MySQL-Replikation herausskaliert zu werden. Angenommen, wir haben bereits einen neuen Cluster im Büro basierend auf der letzten Sicherung des Produktionsclusters im Rechenzentrum wiederhergestellt, und wir möchten, dass der Bürocluster weiterhin vom Produktionscluster repliziert, wie im folgenden Diagramm dargestellt:

Sie können dann den asynchronen Replikationslink folgendermaßen einrichten:
-
Wählen Sie einen Knoten in der Produktion aus und aktivieren Sie die binäre Protokollierung (falls deaktiviert). Gehen Sie zu Nodes -> wählen Sie einen Node -> Node Actions -> Enable Binary Logging.
-
Aktivieren Sie die binäre Protokollierung auf allen Knoten für den Office-Cluster. Diese Aktion erfordert einen fortlaufenden Neustart, der automatisch durchgeführt wird, wenn Sie im Dropdown-Menü „Knoten automatisch neu starten“ „Ja“ auswählen:

Andernfalls können Sie diesen Vorgang ohne Ausfallzeit ausführen, indem Sie Verwalten -> Upgrade -> Rollender Neustart verwenden (oder einen Knoten nach dem anderen manuell neu starten).
-
Erstellen Sie einen Replikationsbenutzer auf dem Produktionscluster, indem Sie Verwalten -> Schemata und Benutzer -> Benutzer -> Neuen Benutzer erstellen verwenden:

-
Wählen Sie dann einen Knoten aus, der auf den Master-Knoten im Produktionscluster repliziert werden soll, und richten Sie den Replikationslink ein:
mysql> CHANGE MASTER master_host = 'prod-mysql1', master_user = 'slave', master_password = 'slavepassw0rd', master_auto_position = 1; mysql> START SLAVE; -
Überprüfen Sie, ob die Replikation ausgeführt wird:
Stellen Sie sicher, dass Slave_IO_Thread und Slave_SQL_thread „Ja“ melden. Der Cluster des Büros sollte beginnen, den Master-Knoten einzuholen, wenn er hinterherhinkt.mysql> SHOW SLAVE STATUS\G
Das war's erstmal, Leute!