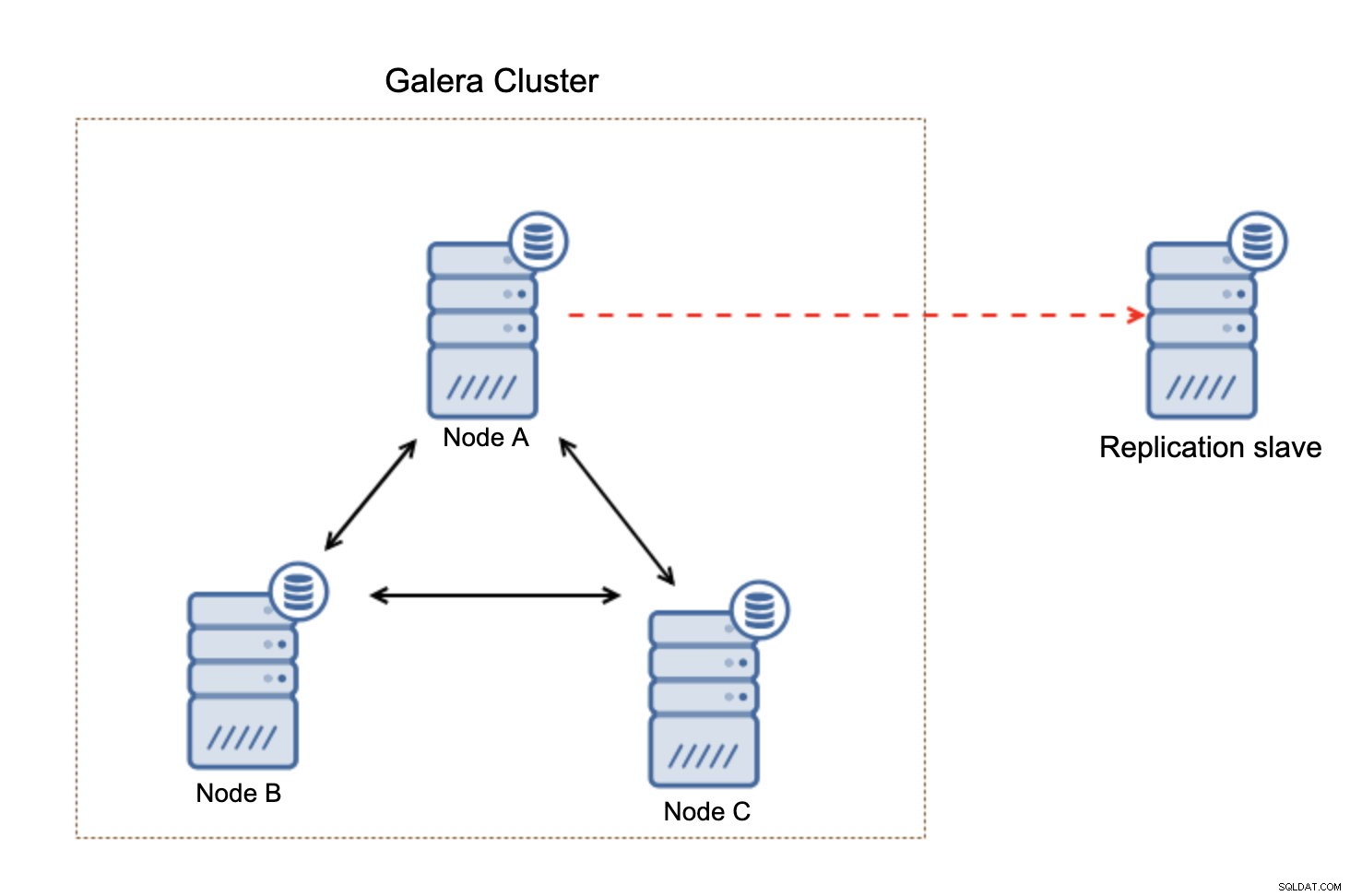
Die Verwendung des Galera-Clusters ist eine großartige Möglichkeit, eine hochverfügbare Umgebung für MySQL oder MariaDB aufzubauen. Es handelt sich um eine Shared-Nothing-Clusterumgebung, die sogar über 12-15 Knoten hinaus skaliert werden kann. Galera hat jedoch einige Einschränkungen. Es glänzt in Umgebungen mit niedriger Latenz und obwohl es über WAN verwendet werden kann, wird die Leistung durch die Netzwerklatenz begrenzt. Die Leistung von Galera kann auch beeinträchtigt werden, wenn einer der Knoten beginnt, sich falsch zu verhalten. Beispielsweise kann eine übermäßige Last auf einem der Knoten ihn verlangsamen, was zu einer langsameren Verarbeitung der Schreibvorgänge führt und sich auf alle anderen Knoten im Cluster auswirkt. Andererseits ist es ziemlich unmöglich, ein Unternehmen zu führen, ohne Ihre Daten zu analysieren. Eine solche Analyse erfordert in der Regel die Ausführung umfangreicher Abfragen, was sich deutlich von einer OLTP-Arbeitslast unterscheidet. In diesem Blog-Beitrag diskutieren wir eine einfache Möglichkeit, analytische Abfragen für Daten auszuführen, die in Galera Cluster for MySQL oder MariaDB gespeichert sind, ohne die Leistung des Core-Clusters zu beeinträchtigen.
Wie führe ich analytische Abfragen auf dem Galera-Cluster aus?
Wie bereits erwähnt, ist es machbar, lange laufende Abfragen direkt auf einem Galera-Cluster auszuführen, aber vielleicht keine so gute Idee. Abhängig von der Hardware kann dies eine akzeptable Lösung sein (wenn Sie starke Hardware verwenden und keine Multithread-Analysearbeitslast ausführen), aber selbst wenn die CPU-Auslastung kein Problem darstellt, ist die Tatsache, dass einer der Knoten eine gemischte Arbeitslast hat ( OLTP und OLAP) werden allein einige Performance-Herausforderungen mit sich bringen. OLAP-Abfragen entfernen Daten, die für Ihre OLTP-Workload erforderlich sind, aus dem Pufferpool, wodurch Ihre OLTP-Abfragen verlangsamt werden. Glücklicherweise gibt es eine einfache, aber effiziente Möglichkeit, die analytische Arbeitslast von regulären Abfragen zu trennen - einen asynchronen Replikations-Slave.
Der Replikations-Slave ist eine sehr einfache Lösung – alles, was Sie brauchen, ist nur ein weiterer Host, der bereitgestellt werden kann, und die asynchrone Replikation muss vom Galera-Cluster zu diesem Knoten konfiguriert werden. Bei der asynchronen Replikation wirkt sich der Slave in keiner Weise auf den Rest des Clusters aus. Egal, ob es stark ausgelastet ist oder andere (weniger leistungsstarke) Hardware verwendet, es wird einfach weiter vom Kerncluster repliziert. Das Worst-Case-Szenario ist, dass der Replikations-Slave hinterherhinkt, aber dann liegt es an Ihnen, die Multithread-Replikation zu implementieren oder den Replikations-Slave schließlich zu skalieren.
Sobald der Replikations-Slave betriebsbereit ist, sollten Sie die schwereren Abfragen darauf ausführen und den Galera-Cluster auslagern. Dies kann je nach Setup und Umgebung auf verschiedene Arten erfolgen. Wenn Sie ProxySQL verwenden, können Sie Abfragen auf der Grundlage des Quellhosts, des Benutzers, des Schemas oder sogar der Abfrage selbst problemlos an den analytischen Slave richten. Andernfalls liegt es an Ihrer Anwendung, analytische Anfragen an den richtigen Host zu senden.
Das Einrichten eines Replikations-Slaves ist nicht sehr komplex, kann aber dennoch schwierig sein, wenn Sie mit MySQL und Tools wie xtrabackup nicht vertraut sind. Der gesamte Prozess würde darin bestehen, das Repository auf einem neuen Server einzurichten und die MySQL-Datenbank zu installieren. Dann müssen Sie diesen Host mit Daten aus dem Galera-Cluster bereitstellen. Sie können dafür xtrabackup verwenden, aber andere Tools wie mydumper/myloader oder sogar mysqldump funktionieren auch (solange Sie sie korrekt ausführen). Sobald die Daten da sind, müssen Sie die Replikation zwischen einem Master-Galera-Knoten und dem Replikations-Slave einrichten. Schließlich müssten Sie Ihre Proxy-Schicht neu konfigurieren, um den neuen Slave einzuschließen und den Datenverkehr dorthin zu leiten, oder Änderungen daran vornehmen, wie sich Ihre Anwendung mit der Datenbank verbindet, um einen Teil der Last auf den Replikations-Slave umzuleiten.
Es ist wichtig zu beachten, dass dieses Setup nicht belastbar ist. Wenn der „Master“-Galera-Knoten ausfallen würde, wird die Replikationsverbindung unterbrochen und es wird eine manuelle Aktion erforderlich sein, um die Replik von einem anderen Master-Knoten im Galera-Cluster abzusklaven.
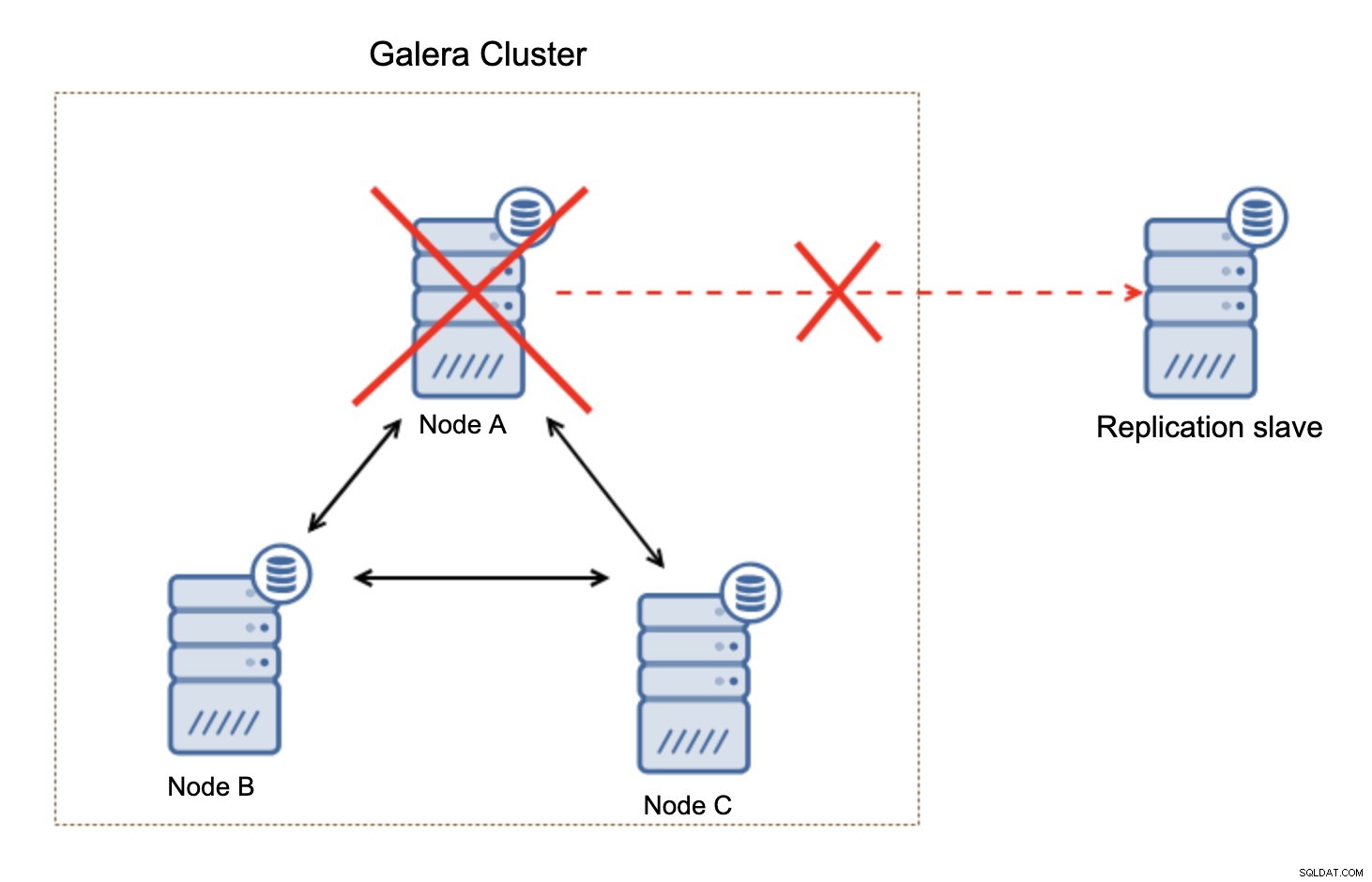
Dies ist keine große Sache, insbesondere wenn Sie die Replikation mit GTID (Global Transaction ID) verwenden, aber Sie müssen feststellen, dass die Replikation fehlerhaft ist, und dann die manuelle Maßnahme ergreifen.
Wie richte ich den asynchronen Slave zu Galera Cluster mit ClusterControl ein?
Wenn Sie ClusterControl verwenden, kann der gesamte Prozess glücklicherweise automatisiert werden und erfordert nur eine Handvoll Klicks. Der Anfangszustand wurde bereits mit ClusterControl eingerichtet - ein 3-Knoten-Galera-Cluster mit 2 ProxySQL-Knoten und 2 Keepalived-Knoten für eine hohe Verfügbarkeit von Datenbank und Proxy-Ebene.
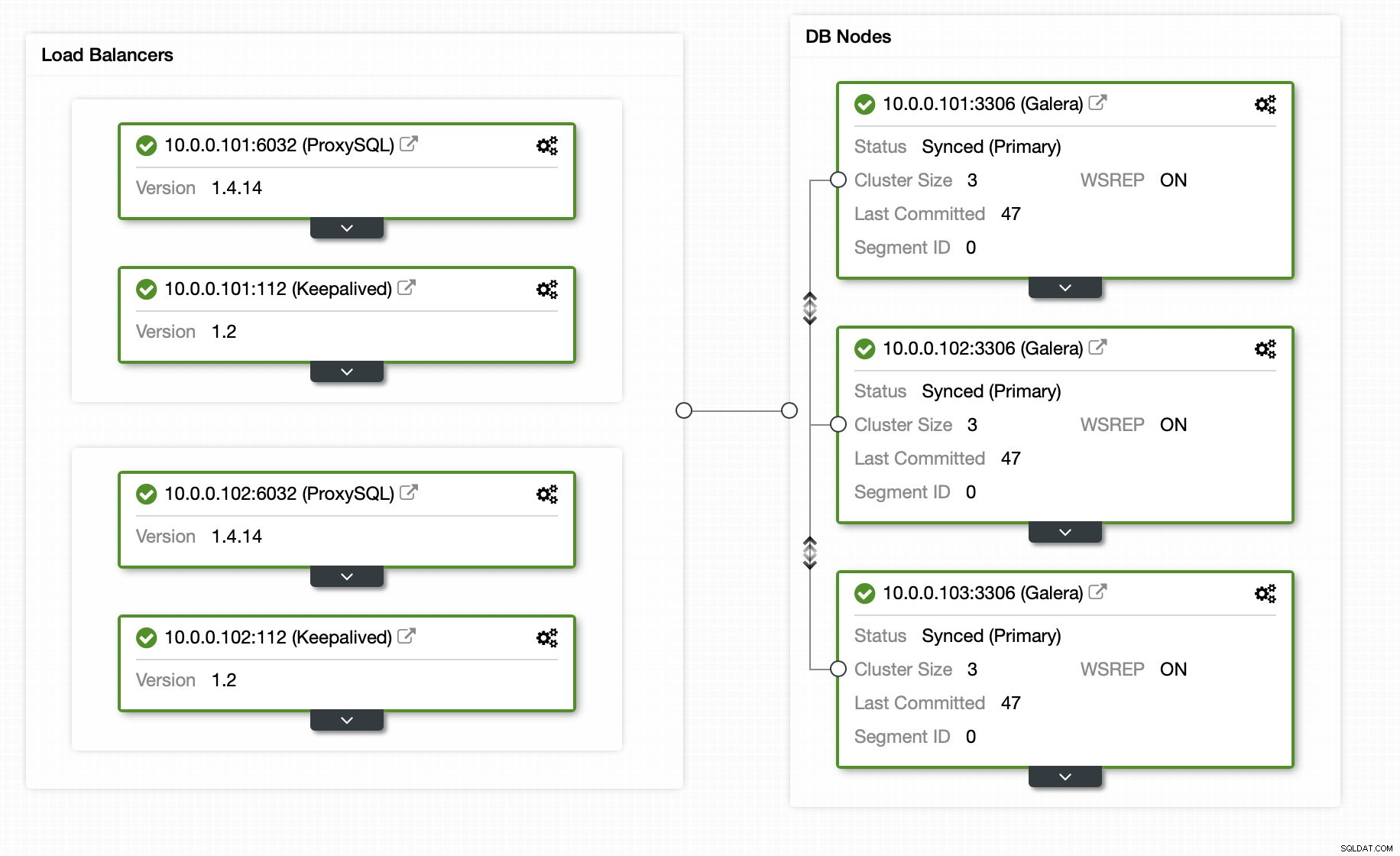
Das Hinzufügen des Replikations-Slaves ist nur einen Klick entfernt:
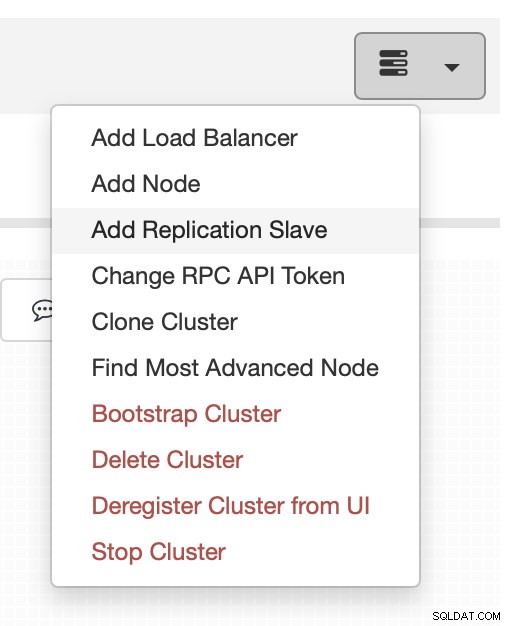
Die Replikation erfordert natürlich die Aktivierung von Binärlogs. Wenn Sie auf Ihren Galera-Knoten keine Binlogs aktiviert haben, können Sie dies auch über ClusterControl tun. Bitte beachten Sie, dass die Aktivierung von Binärprotokollen einen Neustart des Knotens erfordert, um die Konfigurationsänderungen zu übernehmen.
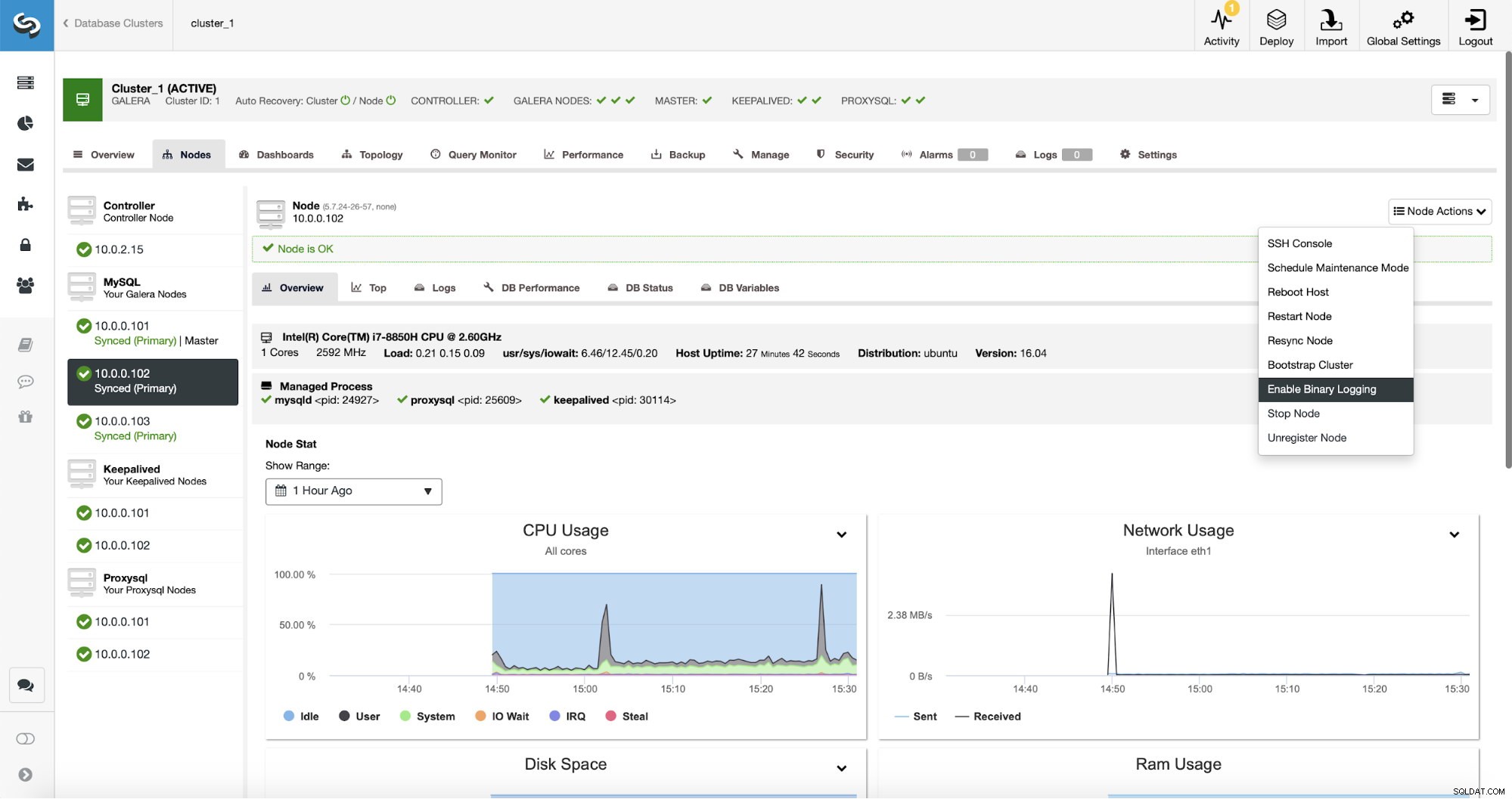
Selbst wenn auf einem Knoten im Cluster Binärprotokolle aktiviert sind (im obigen Screenshot als „Master“ gekennzeichnet), ist es dennoch gut, das Binärprotokoll auf mindestens einem weiteren Knoten zu aktivieren. ClusterControl kann den Replikations-Slave automatisch umschalten, nachdem es festgestellt hat, dass der Master-Galera-Knoten abgestürzt ist, aber dafür ist ein anderer Master-Knoten mit aktivierten Binärprotokollen erforderlich, oder er hat nichts, auf das er umschalten kann.
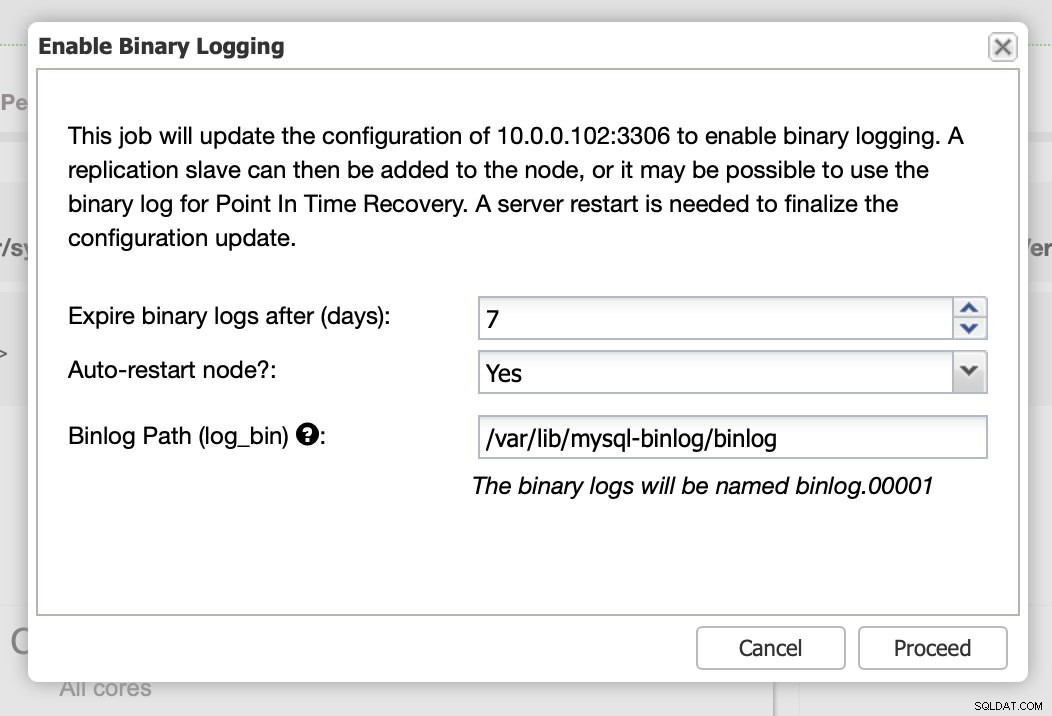
Wie bereits erwähnt, erfordert das Aktivieren von Binärprotokollen einen Neustart. Sie können es entweder sofort durchführen oder einfach die Konfigurationsänderungen vornehmen und den Neustart zu einem anderen Zeitpunkt durchführen.
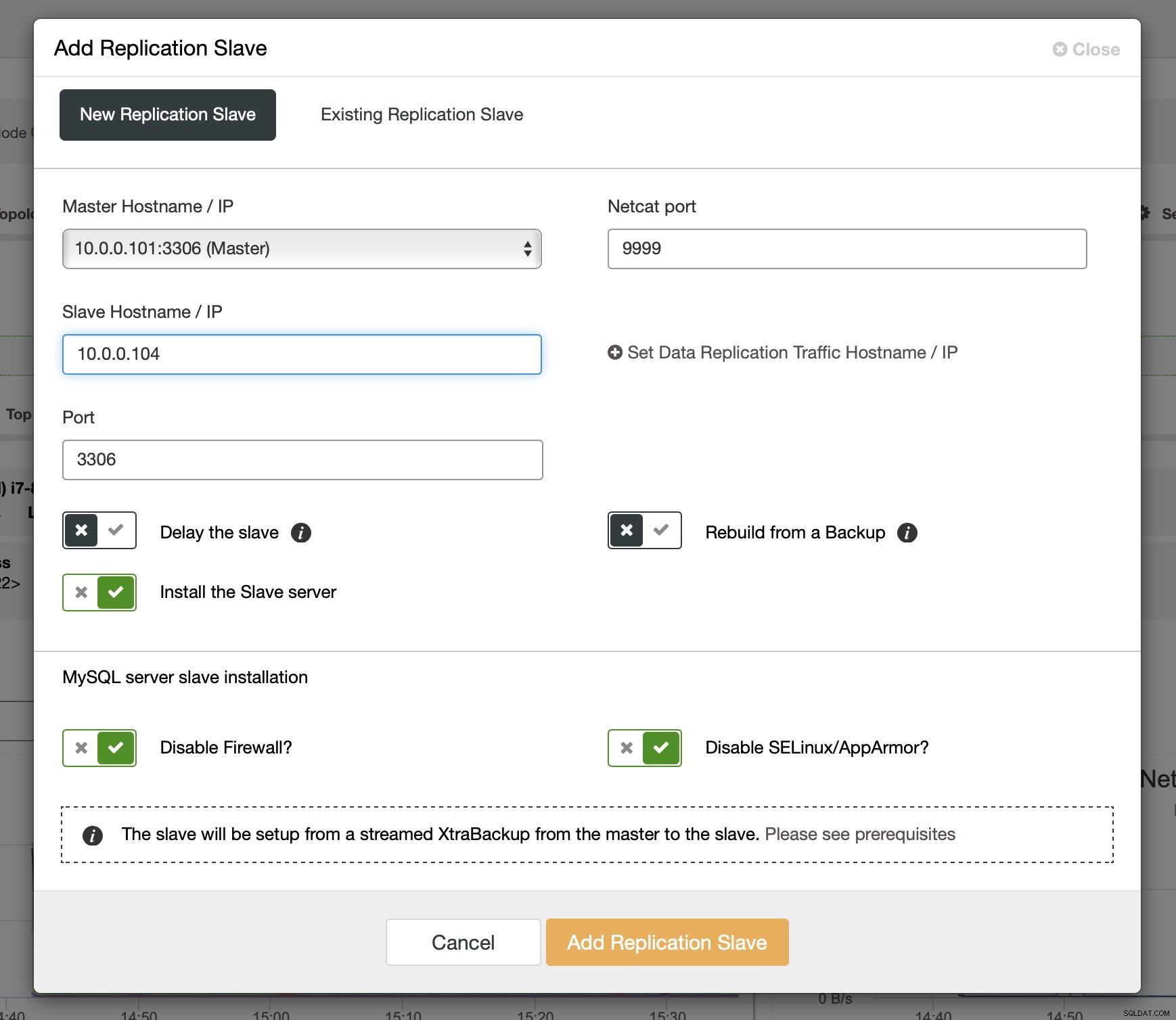
Nachdem Binlogs auf einigen der Galera-Knoten aktiviert wurden, können Sie mit dem Hinzufügen des Replikations-Slaves fortfahren. Im Dialog müssen Sie den Master-Host auswählen, den Hostnamen oder die IP-Adresse des Slaves übergeben. Wenn Sie aktuelle Backups zur Hand haben (was Sie tun sollten), können Sie eines verwenden, um den Slave bereitzustellen. Andernfalls stellt ClusterControl es mit xtrabackup bereit - alle aktuellen Masterdaten werden zum Slave gestreamt und dann wird die Replikation konfiguriert.
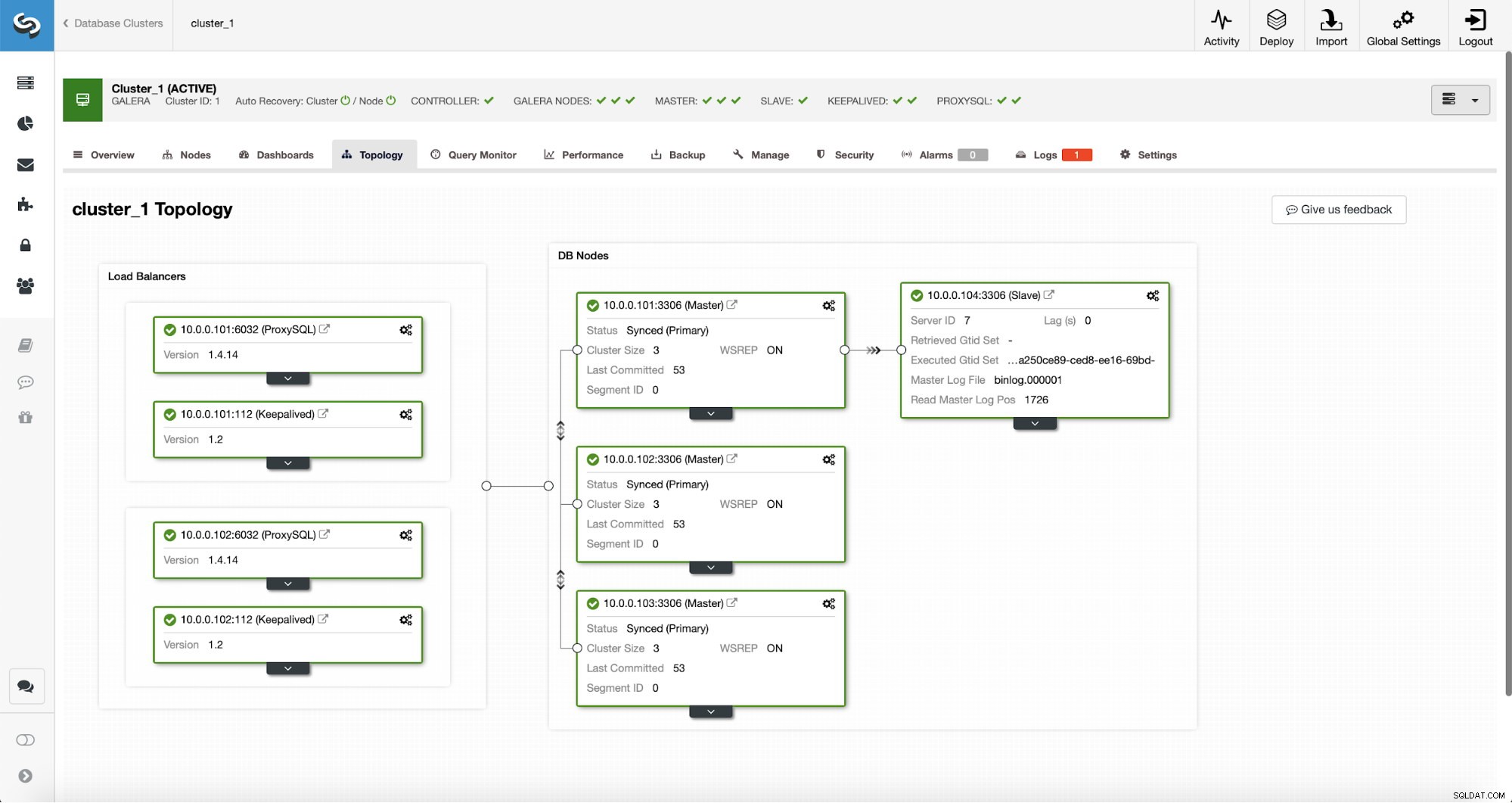
Nach Abschluss des Auftrags wurde dem Cluster ein Replikations-Slave hinzugefügt. Wie bereits erwähnt, wird, sollte 10.0.0.101 sterben, ein anderer Host im Galera-Cluster als Master ausgewählt und ClusterControl wird automatisch 10.0.0.104 von einem anderen Knoten abhängig machen.
Da wir ProxySQL verwenden, müssen wir es konfigurieren. Wir werden ProxySQL einen neuen Server hinzufügen.
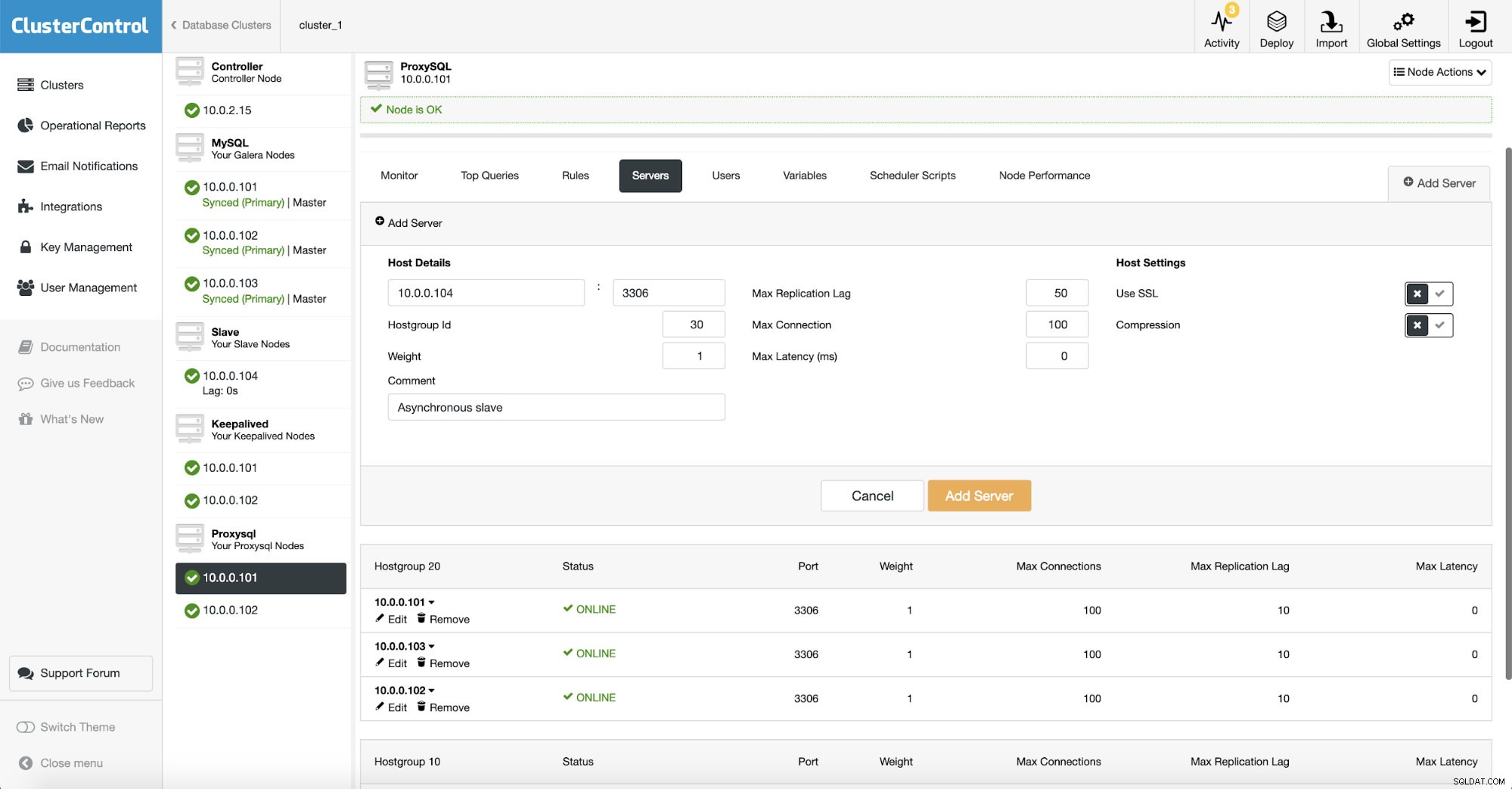
Wir haben eine weitere Hostgruppe (30) erstellt, in der wir unseren asynchronen Slave platziert haben. Wir haben auch „Max. Replikationsverzögerung“ von standardmäßig 10 auf 50 Sekunden erhöht. Es hängt von Ihren Geschäftsanforderungen ab, wie stark der Analyse-Slave verzögert werden kann, bevor es zu einem Problem wird.
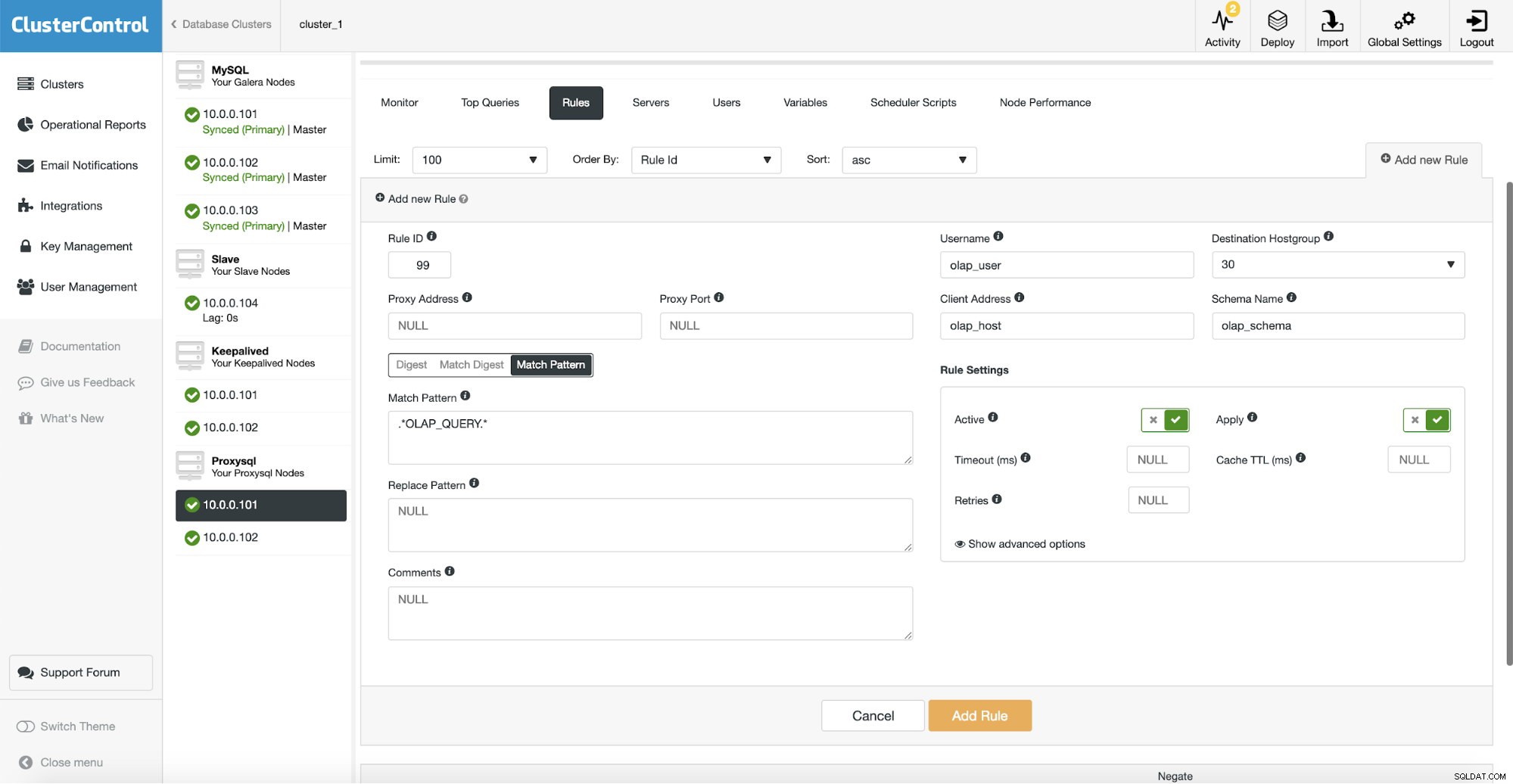
Danach müssen wir eine Abfrageregel konfigurieren, die unserem OLAP-Datenverkehr entspricht, und ihn an die OLAP-Hostgruppe (30) weiterleiten. Auf dem obigen Screenshot haben wir mehrere Felder ausgefüllt - dies ist nicht obligatorisch. In der Regel müssen Sie höchstens eins oder zwei davon verwenden. Der obige Screenshot dient als Beispiel, damit wir leicht erkennen können, dass Sie Abfragen mithilfe von Schema (wenn Sie ein separates Schema mit analytischen Daten haben), Hostname/IP (wenn OLAP-Abfragen von einem bestimmten Host ausgeführt werden), Benutzer (wenn die Anwendung verwendet bestimmten Benutzer für analytische Abfragen. Sie können Abfragen auch direkt abgleichen, indem Sie entweder eine vollständige Abfrage übergeben oder sie mit SQL-Kommentaren markieren und ProxySQL alle Abfragen mit einer „OLAP_QUERY“-Zeichenfolge an unsere analytische Hostgruppe weiterleiten lässt.
Wie Sie sehen können, konnten wir dank ClusterControl mit nur wenigen Klicks einen Replikations-Slave für Galera Cluster bereitstellen. Einige mögen argumentieren, dass MySQL nicht die am besten geeignete Datenbank für analytische Workloads ist, und wir stimmen dem tendenziell zu. Sie können dieses Setup einfach erweitern, indem Sie ClickHouse verwenden und eine Replikation vom asynchronen Slave zum spaltenorientierten ClickHouse-Datenspeicher für eine viel bessere Leistung analytischer Abfragen einrichten. Wir haben dieses Setup in einem der früheren Blogbeiträge beschrieben.