Heutzutage ist Docker das gängigste Tool zum Erstellen, Bereitstellen und Ausführen von Anwendungen mithilfe von Containern. Es ermöglicht uns, eine Anwendung mit allen Teilen zu packen, die sie benötigt, wie Bibliotheken und andere Abhängigkeiten, und alles als ein Paket zu versenden. Es könnte als virtuelle Maschine betrachtet werden, aber anstatt ein vollständiges virtuelles Betriebssystem zu erstellen, ermöglicht Docker Anwendungen, denselben Linux-Kernel wie das System zu verwenden, auf dem sie ausgeführt werden, und erfordert nur, dass Anwendungen mit Dingen ausgeliefert werden, auf denen noch nicht ausgeführt wird dem Host-Rechner. Dies führt zu einer erheblichen Leistungssteigerung und reduziert die Größe der Anwendung.
Im Falle von Docker-Images werden sie mit einer vordefinierten Betriebssystemversion geliefert und die Pakete werden auf eine Weise installiert, die von der Person festgelegt wurde, die das Image erstellt hat. Es ist möglich, dass Sie ein anderes Betriebssystem verwenden oder die Pakete auf andere Weise installieren möchten. In diesen Fällen sollten Sie ein sauberes Betriebssystem-Docker-Image verwenden und die Software von Grund auf neu installieren.
Die Replikation ist eine gängige Funktion in einer Datenbankumgebung. Wenn Sie also nach der Bereitstellung der TimescaleDB-Docker-Images ein Replikations-Setup konfigurieren möchten, müssen Sie dies manuell über den Container tun, indem Sie eine Docker-Datei oder sogar ein Skript verwenden. Diese Aufgabe könnte komplex sein, wenn Sie keine Docker-Kenntnisse haben.
In diesem Blog werden wir sehen, wie wir TimescaleDB über Docker bereitstellen können, indem wir ein TimescaleDB-Docker-Image verwenden, und dann werden wir sehen, wie wir es von Grund auf neu installieren, indem wir ein CentOS-Docker-Image und ClusterControl verwenden.
So stellen Sie TimescaleDB mit einem Docker-Image bereit
Sehen wir uns zunächst an, wie TimescaleDB mithilfe eines Docker-Images bereitgestellt wird, das auf Docker Hub verfügbar ist.
$ docker search timescaledb
NAME DESCRIPTION STARS OFFICIAL AUTOMATED
timescale/timescaledb An open-source time-series database optimize… 52Wir nehmen das erste Ergebnis. Also müssen wir dieses Bild ziehen:
$ docker pull timescale/timescaledbUnd führen Sie die Knotencontainer aus, die einen lokalen Port dem Datenbankport im Container zuordnen:
$ docker run -d --name timescaledb1 -p 7551:5432 timescale/timescaledb
$ docker run -d --name timescaledb2 -p 7552:5432 timescale/timescaledbNachdem Sie diese Befehle ausgeführt haben, sollten Sie diese Docker-Umgebung erstellt haben:
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
6d3bfc75fe39 timescale/timescaledb "docker-entrypoint.s…" 15 minutes ago Up 15 minutes 0.0.0.0:7552->5432/tcp timescaledb2
748d5167041f timescale/timescaledb "docker-entrypoint.s…" 16 minutes ago Up 16 minutes 0.0.0.0:7551->5432/tcp timescaledb1Jetzt können Sie mit den folgenden Befehlen auf jeden Knoten zugreifen:
$ docker exec -ti [db-container] bash
$ su postgres
$ psql
psql (9.6.13)
Type "help" for help.
postgres=#Wie Sie sehen können, enthält dieses Docker-Image standardmäßig eine TimescaleDB 9.6-Version und ist auf Alpine Linux v3.9 installiert. Sie können eine andere TimescaleDB-Version verwenden, indem Sie das Tag ändern:
$ docker pull timescale/timescaledb:latest-pg11Anschließend können Sie einen Datenbankbenutzer erstellen, die Konfiguration Ihren Anforderungen entsprechend ändern oder die Replikation zwischen den Knoten manuell konfigurieren.
So stellen Sie TimescaleDB mit ClusterControl bereit
Sehen wir uns nun an, wie Sie TimescaleDB mit Docker bereitstellen, indem Sie ein CentOS-Docker-Image (centos) und ein ClusterControl-Docker-Image (severalnines/clustercontrol) verwenden.
Zuerst stellen wir einen ClusterControl-Docker-Container mit der neuesten Version bereit, also müssen wir das multiplenines/clustercontrol-Docker-Image ziehen.
$ docker pull severalnines/clustercontrolDann führen wir den ClusterControl-Container aus und veröffentlichen den Port 5000, um darauf zuzugreifen.
$ docker run -d --name clustercontrol -p 5000:80 severalnines/clustercontrolJetzt können wir die ClusterControl-Benutzeroberfläche unter https://[Docker_Host]:5000/clustercontrol öffnen und einen standardmäßigen Administratorbenutzer und ein Kennwort erstellen.
Das offizielle Docker-Image von CentOS wird ohne SSH-Dienst geliefert, daher installieren wir es und ermöglichen die Verbindung vom ClusterControl-Knoten ohne Kennwort mithilfe eines SSH-Schlüssels.
$ docker search centos
NAME DESCRIPTION STARS OFFICIAL AUTOMATED
centos The official build of CentOS. 5378 [OK]Also ziehen wir das offizielle Docker-Image von CentOS.
$ docker pull centosUnd dann führen wir zwei Knotencontainer aus, timescale1 und timescale2, die mit ClusterControl verknüpft sind, und wir ordnen einen lokalen Port zu, um eine Verbindung zur Datenbank herzustellen (optional).
$ docker run -dt --privileged --name timescale1 -p 8551:5432 --link clustercontrol:clustercontrol centos /usr/sbin/init
$ docker run -dt --privileged --name timescale2 -p 8552:5432 --link clustercontrol:clustercontrol centos /usr/sbin/initDa wir den SSH-Dienst installieren und konfigurieren müssen, müssen wir den Container mit privilegierten und /usr/sbin/init-Parametern ausführen, um den Dienst innerhalb des Containers verwalten zu können.
Nachdem Sie diese Befehle ausgeführt haben, sollten wir diese Docker-Umgebung erstellt haben:
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
230686d8126e centos "/usr/sbin/init" 4 seconds ago Up 3 seconds 0.0.0.0:8552->5432/tcp timescale2
c0e7b245f7fe centos "/usr/sbin/init" 23 seconds ago Up 22 seconds 0.0.0.0:8551->5432/tcp timescale1
7eadb6bb72fb severalnines/clustercontrol "/entrypoint.sh" 2 weeks ago Up About an hour (healthy) 22/tcp, 443/tcp, 3306/tcp, 9500-9501/tcp, 9510-9511/tcp, 9999/tcp, 0.0.0.0:5000->80/tcp clustercontrolWir können auf jeden Knoten mit dem folgenden Befehl zugreifen:
$ docker exec -ti [db-container] bashWie bereits erwähnt, müssen wir den SSH-Dienst installieren, also installieren wir ihn, erlauben den Root-Zugriff und legen das Root-Passwort für jeden Datenbankcontainer fest:
$ docker exec -ti [db-container] yum update -y
$ docker exec -ti [db-container] yum install -y openssh-server openssh-clients
$ docker exec -it [db-container] sed -i 's|^#PermitRootLogin.*|PermitRootLogin yes|g' /etc/ssh/sshd_config
$ docker exec -it [db-container] systemctl start sshd
$ docker exec -it [db-container] passwdDer letzte Schritt besteht darin, das passwortlose SSH für alle Datenbankcontainer einzurichten. Dazu müssen wir die IP-Adresse für jeden Datenbankknoten kennen. Um es zu wissen, können wir den folgenden Befehl für jeden Knoten ausführen:
$ docker inspect [db-container] |grep IPAddress
"IPAddress": "172.17.0.5",Hängen Sie dann an die interaktive Konsole des ClusterControl-Containers an:
$ docker exec -it clustercontrol bashUnd kopieren Sie den SSH-Schlüssel in alle Datenbankcontainer:
$ ssh-copy-id 172.17.0.5Nachdem wir die Serverknoten eingerichtet und ausgeführt haben, müssen wir unseren Datenbankcluster bereitstellen. Um es einfach zu machen, verwenden wir ClusterControl.
Um eine Bereitstellung von ClusterControl durchzuführen, öffnen Sie die ClusterControl-Benutzeroberfläche unter https://[Docker_Host]:5000/clustercontrol, wählen Sie dann die Option „Bereitstellen“ und befolgen Sie die angezeigten Anweisungen.
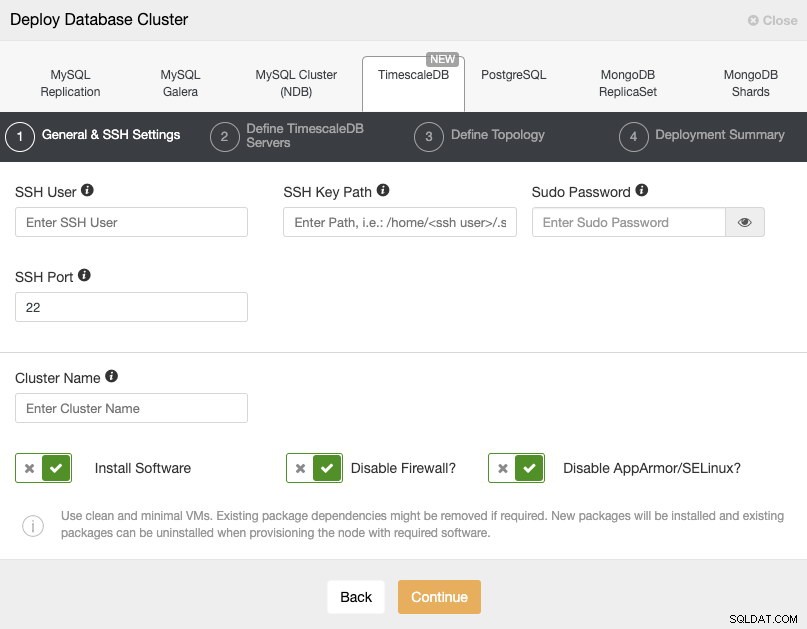
Bei der Auswahl von TimescaleDB müssen wir Benutzer, Schlüssel oder Passwort und Port angeben, um eine SSH-Verbindung zu unseren Servern herzustellen. Wir brauchen auch einen Namen für unseren neuen Cluster und wenn wir möchten, dass ClusterControl die entsprechende Software und Konfigurationen für uns installiert.
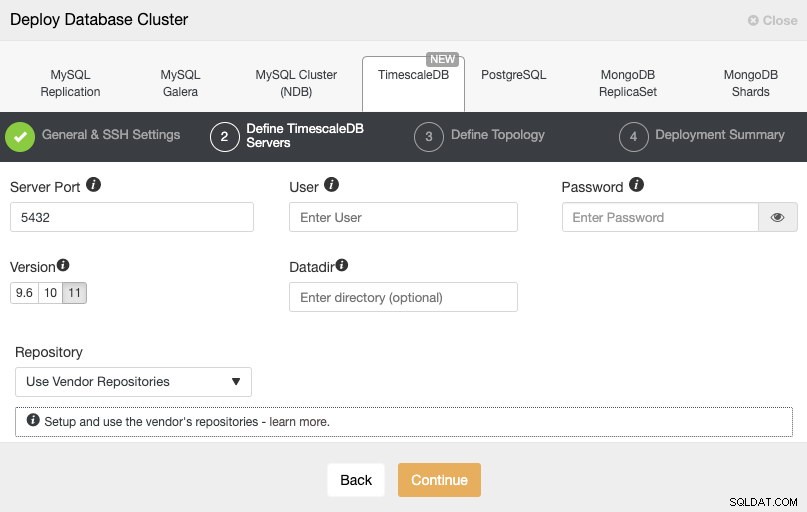
Nach dem Einrichten der SSH-Zugangsinformationen müssen wir den Datenbankbenutzer, die Version und das Datadir (optional) definieren. Wir können auch angeben, welches Repository verwendet werden soll.
Im nächsten Schritt müssen wir unsere Server zu dem Cluster hinzufügen, den wir erstellen werden.
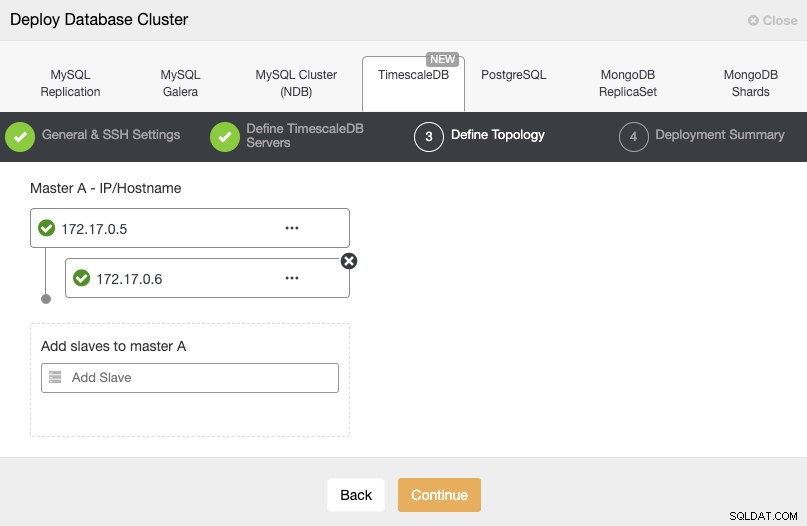
Hier müssen wir die IP-Adresse verwenden, die wir zuvor von jedem Container erhalten haben.
Im letzten Schritt können wir wählen, ob unsere Replikation synchron oder asynchron sein soll.
Wir können den Status der Erstellung unseres neuen Clusters über den Aktivitätsmonitor von ClusterControl überwachen.
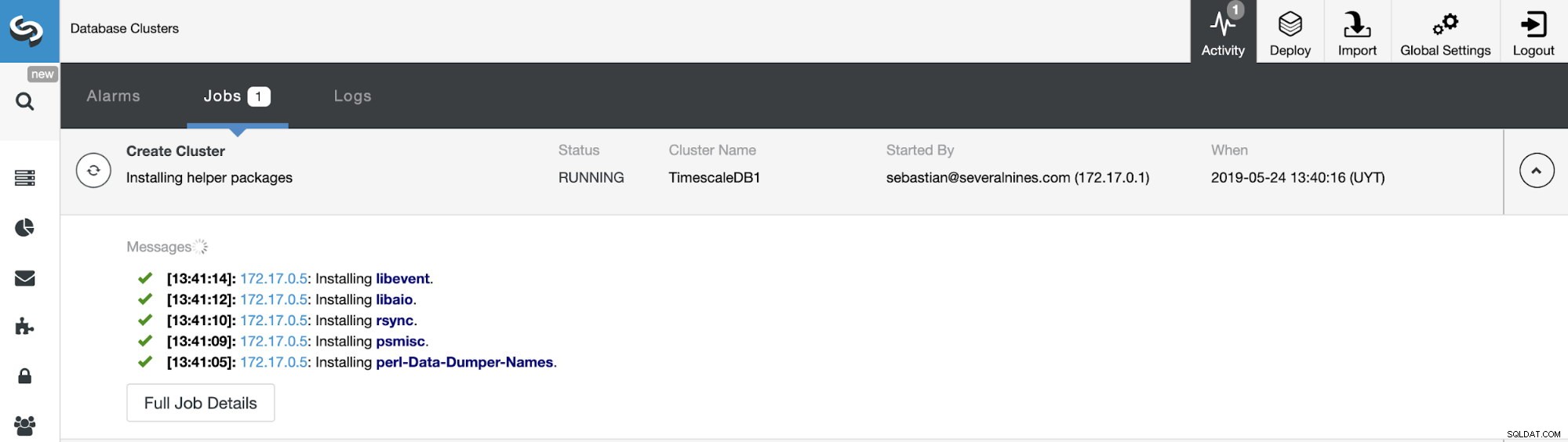
Sobald die Aufgabe abgeschlossen ist, können wir unseren Cluster im Hauptbildschirm von ClusterControl sehen.

Beachten Sie, dass Sie, wenn Sie weitere Standby-Knoten hinzufügen möchten, dies über die ClusterControl-Benutzeroberfläche im Menü „Cluster-Aktionen“ tun können.
Wenn Ihr TimescaleDB-Cluster auf Docker ausgeführt wird und Sie möchten, dass ClusterControl ihn verwaltet, um alle Funktionen dieses Systems wie Überwachung, Sicherung, automatisches Failover und noch mehr nutzen zu können, können Sie auf die gleiche Weise einfach ausführen ClusterControl-Container im selben Docker-Netzwerk wie die Datenbankcontainer. Die einzige Anforderung besteht darin, sicherzustellen, dass auf den Zielcontainern SSH-bezogene Pakete installiert sind (openssh-server, openssh-clients). Erlauben Sie dann passwortloses SSH von ClusterControl zu den Datenbankcontainern. Wenn Sie fertig sind, verwenden Sie die Funktion „Import Existing Server/Cluster“ und der Cluster sollte in ClusterControl importiert werden.
Ein mögliches Problem beim Ausführen von Containern ist die Zuweisung von IP-Adressen oder Hostnamen. Ohne ein Orchestrierungstool wie Kubernetes könnten die IP-Adresse oder der Hostname anders sein, wenn Sie die Knoten stoppen und neue Container erstellen, bevor Sie sie erneut starten. Sie haben eine andere IP-Adresse für die alten Knoten und ClusterControl geht davon aus, dass alle Knoten in einer Umgebung mit einer dedizierten IP-Adresse oder einem dedizierten Hostnamen ausgeführt werden. Nachdem sich die IP-Adresse geändert hat, sollten Sie den Cluster erneut in ClusterControl importieren. Es gibt viele Problemumgehungen für dieses Problem. Sie können diesen Link überprüfen, um Kubernetes mit StatefulSet zu verwenden, oder diesen, um Container ohne Orchestrierungstool auszuführen.
Schlussfolgerung
Wie wir sehen konnten, sollte die Bereitstellung von TimescaleDB mit Docker einfach sein, wenn Sie keine Replikations- oder Failover-Umgebung konfigurieren und keine Änderungen an der Betriebssystemversion oder der Datenbankpaketinstallation vornehmen möchten.
Mit ClusterControl können Sie Ihren TimescaleDB-Cluster mit Docker importieren oder bereitstellen, indem Sie das von Ihnen bevorzugte Betriebssystem-Image verwenden, sowie die Überwachungs- und Verwaltungsaufgaben wie Sicherung und automatisches Failover/Wiederherstellung automatisieren.