In Anbetracht des aktuellen Hauptanwendungsfalls einer Datenbank zum Abrufen von Daten wird es sehr wichtig, dass ihre Leistung sehr hoch ist und nur erreicht werden kann, wenn Daten auf die effizienteste Weise aus dem Speicher abgerufen werden. Es wurden viele erfolgreiche Erfindungen und Implementierungen durchgeführt, um dasselbe zu erreichen. Einer der bekannten Ansätze, der von den meisten Datenbanken übernommen wird, besteht darin, einen Index für die Tabelle zu haben.
Was ist ein Datenbankindex?
Der Datenbankindex verwaltet, wie der Name schon sagt, einen Index zu den eigentlichen Daten und verbessert dadurch die Leistung beim Abrufen von Daten aus der eigentlichen Tabelle. In einer eher datenbankbasierten Terminologie ermöglicht der Index das Abrufen von Seiten mit indizierten Daten in einem sehr minimalen Durchlauf, da die Daten in einer bestimmten Reihenfolge sortiert werden. Der Indexvorteil geht zu Lasten von zusätzlichem Speicherplatz, um zusätzliche Daten zu schreiben. Indizes sind spezifisch für die zugrunde liegende Tabelle und bestehen aus einem oder mehreren Schlüsseln (d. h. einer oder mehreren Spalten der angegebenen Tabelle). Es gibt hauptsächlich zwei Arten von Indexarchitekturen
- Clustered Index – Indexdaten werden zusammen mit anderen Teilen der Daten gespeichert und die Daten werden basierend auf dem Indexschlüssel sortiert. In dieser Kategorie kann es höchstens einen Index für eine bestimmte Tabelle geben.
- Non-Clustered Index – Indexdaten werden separat gespeichert und haben einen Zeiger auf den Speicher, in dem andere Teile der Daten gespeichert sind. Dies wird auch als sekundärer Index bezeichnet. In einer bestimmten Tabelle können beliebig viele Indizes dieser Kategorie vorhanden sein.
Es gibt verschiedene Datenstrukturen, die zur Implementierung von Indizes verwendet werden, einige der von den meisten Datenbanken weit verbreiteten sind B-Tree und Hash.
Was ist ein PostgreSQL-Index?
PostgreSQL unterstützt nur nicht gruppierte Indizes. Das bedeutet Indexdaten und vollständige Daten (im Folgenden als Heap-Daten bezeichnet ) werden in einem separaten Speicher gespeichert. Nicht gruppierte Indizes sind wie ein „Inhaltsverzeichnis“ in jedem Dokument, bei dem wir zuerst die Seitenzahl und dann diese Seitenzahlen prüfen, um den gesamten Inhalt zu lesen. Um die vollständigen Daten basierend auf einem Index zu erhalten, hält er einen Zeiger auf entsprechende Heap-Daten. Es ist das Gleiche wie nach Kenntnis der Seitennummer, es muss zu dieser Seite gehen und den tatsächlichen Inhalt der Seite abrufen.
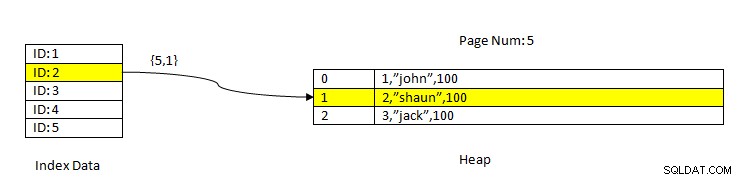 PostgreSQL:Daten lesen mit Index
PostgreSQL:Daten lesen mit Index Stellen Sie sich beispielsweise eine Tabelle mit drei Spalten und einem Index für die Spalte ID vor . Um die Daten basierend auf dem Schlüssel ID =2 zu LESEN, werden zuerst die indizierten Daten mit dem ID-Wert 2 gesucht. Diese enthält einen Zeiger (als Elementzeiger bezeichnet) in Bezug auf die Seitennummer (d. h. Blocknummer) und den Offset von Daten innerhalb dieser Seite. Im aktuellen Beispiel zeigt der Index auf Seite 5 und das zweite Zeilenelement auf der Seite, das wiederum den Offset auf die gesamten Daten (2, „Shaun“, 100) beibehält. Beachten Sie, dass ganze Daten auch die indizierten Daten enthalten, was bedeutet, dass dieselben Daten in zwei Speichern wiederholt werden.
Wie hilft INDEX, die Leistung zu verbessern? Nun, um einen beliebigen INDEX-Datensatz auszuwählen, scannt es nicht alle Seiten nacheinander, sondern muss nur einige der Seiten teilweise scannen, wobei die zugrunde liegende Index-Datenstruktur verwendet wird. Aber es gibt eine Wendung, da jeder Datensatz, der aus Indexdaten gefunden wird, in Heap-Daten nach ganzen Daten suchen muss, was viele zufällige E/A verursacht und als langsamer als sequenzielle E/A angesehen wird. Nur wenn also ein kleiner Prozentsatz der Datensätze ausgewählt wird (was anhand der Kosten des PostgreSQL-Optimierers entschieden wird), wählt nur PostgreSQL den Index-Scan, andernfalls verwendet es weiterhin den Sequence-Scan, obwohl es einen Index für die Tabelle gibt.
Zusammenfassend lässt sich sagen, dass die Indexerstellung zwar die Leistung beschleunigt, sie jedoch sorgfältig ausgewählt werden sollte, da sie einen Mehraufwand in Bezug auf die Speicherung und eine verschlechterte INSERT-Leistung verursacht.
Jetzt fragen wir uns vielleicht, falls wir nur den Indexteil der Daten benötigen, können wir nur von der Indexspeicherseite abrufen? Nun, die Antwort darauf hängt direkt damit zusammen, wie MVCC auf dem Indexspeicher arbeitet, wie im Folgenden erklärt wird.
Verwendung von MVCC für die Indizierung
Wie Heap-Seiten verwaltet die Indexseite mehrere Versionen des Indextupels, jedoch keine Sichtbarkeitsinformationen. Wie in meinem vorherigen MVCC erklärt blog, um eine geeignete sichtbare Version von Tupeln zu bestimmen, muss die Transaktion verglichen werden. Die Transaktion, die das eingefügte/aktualisierte/gelöschte Tupel enthält, wird zusammen mit dem Heap-Tupel verwaltet, aber dasselbe wird nicht mit dem Index-Tupel verwaltet. Dies geschieht ausschließlich, um Speicherplatz zu sparen, und ist ein Kompromiss zwischen Speicherplatz und Leistung.
Nun zurück zur ursprünglichen Frage, da die Sichtbarkeitsinformationen im Index-Tupel nicht vorhanden sind, muss das entsprechende Heap-Tupel konsultiert werden, um zu sehen, ob die ausgewählten Daten sichtbar sind. Obwohl andere Teile der Daten aus dem Heap-Tupel nicht erforderlich sind, müssen Sie dennoch auf die Heap-Seiten zugreifen, um die Sichtbarkeit zu überprüfen. Aber auch hier gibt es eine Wendung, falls alle Tupel auf einer bestimmten Seite (Seite, auf die der Index zeigt, z von der Indexseite. Dieser Sonderfall wird „Index Only Scan“ genannt. Um dies zu unterstützen, verwaltet PostgreSQL eine Sichtbarkeitskarte für jede Seite, um die Sichtbarkeit auf Seitenebene zu überprüfen.
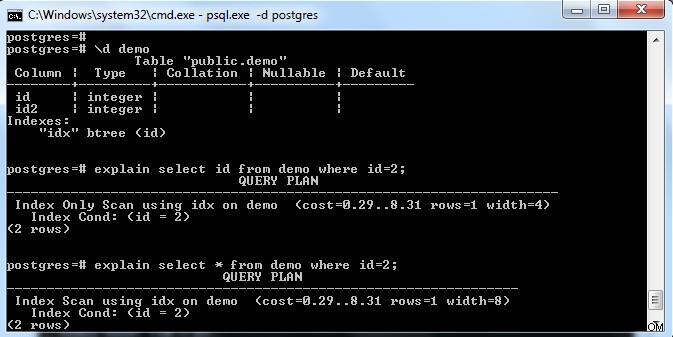
Wie im obigen Bild gezeigt, gibt es einen Index für die Tabelle „demo“ mit einem Schlüssel für die Spalte „id“. Wenn wir versuchen, nur das Indexfeld (d. h. die ID) auszuwählen, wird „Nur Index-Scan“ ausgewählt (wobei die verweisende Seite vollständig sichtbar ist).
Clustered-Index
Es gibt keine Unterstützung für direkte gruppierte Indizes in PostgreSQL, aber es gibt eine indirekte Möglichkeit, dies teilweise zu erreichen. Dies wird durch die folgenden SQL-Befehle erreicht:
CLUSTER [VERBOSE] table_name [ USING index_name ]
CLUSTER [VERBOSE]Der erste Befehl weist die Datenbank an, eine Tabelle unter Verwendung des angegebenen Indexes zu gruppieren (d. h. die Tabelle zu sortieren). Dieser Index sollte bereits erstellt worden sein. Diese Gruppierung ist nur eine einmalige Operation und ihre Auswirkung bleibt nach der nachfolgenden Operation an dieser Tabelle nicht bestehen, d. h. wenn mehr Datensätze eingefügt/aktualisiert werden, bleibt die Tabelle möglicherweise nicht geordnet. Wenn der Benutzer die Tabelle dennoch gruppiert (geordnet) halten möchte, kann er den ersten Befehl verwenden, ohne einen Indexnamen anzugeben.
Der zweite Befehl ist nur nützlich, um die Tabelle neu zu gruppieren (d. h. die Tabelle, die bereits mit einem Index gruppiert wurde). Dieser Befehl gruppiert alle Tabellen in der aktuellen Datenbank neu, die für den aktuell verbundenen Benutzer sichtbar sind.
In der folgenden Abbildung beispielsweise gibt das erste SELECT Datensätze in unsortierter Reihenfolge zurück, da es keinen Clustered-Index gibt. Obwohl es bereits einen nicht gruppierten Index gibt, werden die Datensätze aus dem Heap-Bereich ausgewählt, in dem die Datensätze nicht sortiert sind.
Das zweite SELECT gibt die Datensätze sortiert nach der Spalte „id“ zurück, da sie mit dem Index, der die Spalte „id“ enthält, geclustert wurden.
Das dritte SELECT gibt teilweise Datensätze in sortierter Reihenfolge zurück, aber neu eingefügte Datensätze werden nicht sortiert. Das vierte SELECT gibt wieder alle Datensätze in sortierter Reihenfolge zurück, da die Tabelle erneut geclustert wurde
 PostgreSQL-Clusterbefehl
PostgreSQL-Clusterbefehl Indextyp
PostgreSQL bietet die folgenden Arten von Indizes:
- B-Baum
- Hash
- GiST
- GIN
- BRIN
Jeder Indextyp implementiert verschiedene Arten von zugrunde liegenden Datenstrukturen, die für verschiedene Arten von Abfragen am besten geeignet sind. Standardmäßig wird ein B-Tree-Index erstellt, der ein weit verbreiteter Index ist. Einzelheiten zu jedem Indextyp werden in einem zukünftigen Blog behandelt.
Sonstiges:Teil- und Ausdrucksindex
Wir haben nur über Indizes für eine oder mehrere Spalten einer Tabelle gesprochen, aber es gibt zwei weitere Möglichkeiten, Indizes auf PostgreSQL zu erstellen
- Teilindex: Ein Teilindex ist ein Index, der unter Verwendung der Teilmenge einer Schlüsselspalte für eine bestimmte Tabelle erstellt wurde. Die Teilmenge wird durch den bedingten Ausdruck definiert, der während der Indexerstellung angegeben wird. Mit dem Teilindex wird also Speicherplatz zum Speichern von Indexdaten eingespart. Der Benutzer sollte die Bedingung also so wählen, dass es sich nicht um sehr häufige Werte handelt, da für häufigere (gemeinsame) Werte ohnehin kein Index-Scan gewählt wird. Der Rest der Funktionalität bleibt gleich wie bei einem normalen Index. Beispiel:Teilindex
- Ausdrucksindex: Ausdrucksindizes bieten eine weitere Art von Flexibilität in PostgreSQL. Alle bisher besprochenen Indizes, einschließlich Teilindizes, befinden sich in einem bestimmten Satz von Spalten. Was aber, wenn eine Abfrage den Zugriff auf eine Tabelle basierend auf dem Ausdruck (Ausdruck mit einer oder mehreren Spalten) beinhaltet, wird ohne einen Ausdrucksindex kein Index-Scan gewählt. Um also schnell auf diese Art von Abfragen zugreifen zu können, ermöglicht PostgreSQL die Erstellung eines Indexes für einen Ausdruck. Der Rest der Funktionalität bleibt gleich wie bei einem normalen Index.
 Beispiel:Ausdrucksindex
Beispiel:Ausdrucksindex
Indexspeicher in InnoDB
Die Verwendung und Funktionalität von Index ist größtenteils die gleiche wie in PostgreSQL mit einem großen Unterschied in Bezug auf Clustered Index.
InnoDB unterstützt zwei Kategorien von Indizes:
- Cluster-Index
- Sekundärindex
Clustered-Index
Clustered Index ist eine spezielle Art von Index in InnoDB. Hier werden die indizierten Daten nicht separat gespeichert, sondern sind Teil der gesamten Zeilendaten. Mit anderen Worten, der Clustered-Index erzwingt lediglich die physische Sortierung der Tabellendaten anhand der Schlüsselspalte des Index. Es kann als „Wörterbuch“ betrachtet werden, in dem die Daten nach dem Alphabet sortiert sind.
Da der Clustered-Index Zeilen anhand eines Indexschlüssels sortiert, kann es nur einen Clustered-Index geben. Außerdem muss es einen geclusterten Index geben, da InnoDB diesen verwendet, um Daten während verschiedener Datenoperationen optimal zu manipulieren.
Clustered-Indizes werden automatisch (als Teil der Tabellenerstellung) unter Verwendung einer der Tabellenspalten gemäß der folgenden Priorität erstellt:
- Verwenden des Primärschlüssels, wenn der Primärschlüssel als Teil der Tabellenerstellung erwähnt wird.
- Wählt eine eindeutige Spalte, in der alle Schlüsselspalten NICHT NULL sind.
- Andernfalls wird intern ein versteckter Clustered-Index für eine Systemspalte generiert, der die Zeilen-ID jeder Zeile enthält.
Im Gegensatz zum nicht geclusterten Index von PostgreSQL greift InnoDB mit dem geclusterten Index schneller auf eine Zeile zu, da die Indexsuche direkt zur Seite mit allen Zeilendaten führt und somit zufällige I/Os vermieden werden.
Auch das Abrufen der Tabellendaten in sortierter Reihenfolge mit dem Clustered-Index ist sehr schnell, da alle Daten bereits sortiert sind und auch ganze Daten verfügbar sind.
Sekundärindex
Der explizit in InnoDB erstellte Index wird als sekundärer Index betrachtet, der dem nicht gruppierten PostgreSQL-Index ähnelt. Jeder Datensatz im sekundären Indexspeicher enthält Primärschlüsselspalten der Zeilen (die zum Erstellen des Clustered Index verwendet wurden) und auch die Spalten, die zum Erstellen eines sekundären Index angegeben wurden.
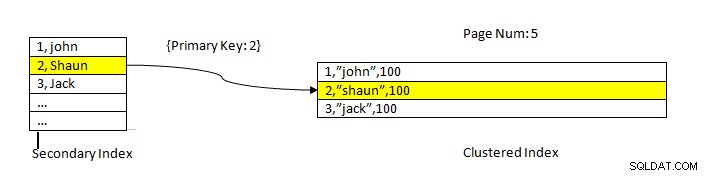 InnoDB:Daten werden mit Index gelesen
InnoDB:Daten werden mit Index gelesen Das Abrufen von Daten mithilfe eines sekundären Indexes ist ähnlich wie im Falle von PostgreSQL, außer dass die InnoDB-Sekundärindexsuche einen Primärschlüssel als Zeiger zum Abrufen der verbleibenden Daten aus dem Clustered-Index liefert.
Wie in der obigen Abbildung gezeigt, befindet sich der gruppierte Index beispielsweise in der Spalte ID, Tabellendaten werden also nach denselben sortiert. Der sekundäre Index befindet sich in der Spalte „Name “, so dass wir sehen können, dass der sekundäre Index sowohl ID als auch Namenswert hat. Sobald wir mithilfe des sekundären Index nachschlagen, findet er den entsprechenden Slot mit dem entsprechenden Schlüsselwert. Dann wird der entsprechende Primärschlüssel verwendet, um auf den verbleibenden Teil der Daten aus dem Clustered-Index zu verweisen.
MVCC für Index
Der Clustered Index MVCC verwendet das traditionelle InnoDB Undo Model (eigentlich dasselbe wie Whole Data MVCC, da der Clustered Index nichts anderes als ganze Daten ist).
Aber die sekundäre Index-MVCC-Nutzung ist ein etwas anderer Ansatz, um MVCC beizubehalten. Bei der Aktualisierung des sekundären Indexes wird der alte Indexeintrag mit einer Löschmarkierung versehen und neue Datensätze werden in denselben Speicher eingefügt, d. h. UPDATE ist nicht vorhanden. Schließlich werden alte Indexeinträge gelöscht. Inzwischen ist Ihnen vielleicht aufgefallen, dass der Sekundärindex MVCC von InnoDB fast identisch mit dem MVCC-Modell von PostgreSQL ist.
Indextyp
InnoDB unterstützt nur B-Tree-Indextypen und muss daher beim Erstellen des Indexes nicht angegeben werden.
Sonstiges:Adaptive Hash-Indizes
Wie im vorherigen Abschnitt erwähnt, unterstützt InnoDB nur B-Tree-Index, aber es gibt eine Wendung. InnoDB hat die Funktion, automatisch zu erkennen, ob die Abfrage von der Erstellung eines Hash-Index profitieren kann und auch ganze Daten der Tabelle in den Speicher passen, dann tut es dies automatisch.
Der Hash-Index wird abhängig von der Abfrage unter Verwendung des vorhandenen B-Tree-Index erstellt. Wenn mehrere sekundäre B-Tree-Indizes vorhanden sind, wird derjenige ausgewählt, der gemäß der Abfrage qualifiziert ist. Der erstellte Hash-Index ist nicht vollständig, er erstellt nur einen Teilindex gemäß dem Datennutzungsmuster.
Dies ist eine der wirklich leistungsstarken Funktionen zur dynamischen Verbesserung der Abfrageleistung.
Schlussfolgerung
Die Verwendung eines beliebigen Indexes in einer beliebigen Datenbank ist wirklich hilfreich, um die READ-Leistung zu verbessern, verschlechtert jedoch gleichzeitig die INSERT/UPDATE-Leistung, da zusätzliche Daten geschrieben werden müssen. Daher sollte der Index sehr weise gewählt und nur erstellt werden, wenn die Indexschlüssel als Prädikat zum Abrufen von Daten verwendet werden.
InnoDB bietet ein sehr gutes Feature in Bezug auf den Clustered Index, der je nach Anwendungsfall sehr nützlich sein kann. Außerdem ist die adaptive Hash-Indizierung sehr leistungsfähig.
Während PostgreSQL verschiedene Arten von Indizes bereitstellt, die wirklich Optionen für die Reichweite von Funktionen bieten können, und je nach geschäftlichem Anwendungsfall einer oder alle verwendet werden können. Auch die partiellen und die Ausdrucksindizes sind je nach Anwendungsfall sehr nützlich.