Ein Leistungsproblem, das ich oft sehe, ist, wenn Benutzer einen Teil einer Zeichenfolge mit einer Abfrage wie der folgenden abgleichen müssen:
... WHERE SomeColumn LIKE N'%SomePortion%';
Mit einem führenden Platzhalter ist dieses Prädikat „nicht-SARG-fähig“ – nur eine schicke Art zu sagen, dass wir die relevanten Zeilen nicht finden können, indem wir eine Suche gegen einen Index auf SomeColumn verwenden .
Eine Lösung, bei der wir uns ein wenig die Finger aus dem Kopf schlagen, ist die Volltextsuche; Dies ist jedoch eine komplexe Lösung und erfordert, dass das Suchmuster aus ganzen Wörtern besteht, keine Stoppwörter verwendet und so weiter. Dies kann hilfreich sein, wenn wir nach Zeilen suchen, in denen eine Beschreibung das Wort „soft“ (oder andere Ableitungen wie „softer“ oder „softly“) enthält, aber es hilft nicht, wenn wir nach Zeichenfolgen suchen, die enthalten sein könnten innerhalb von Wörtern (oder die überhaupt keine Wörter sind, wie alle Produkt-SKUs, die "X45-B" enthalten, oder alle Nummernschilder, die die Zeichenfolge "7RA" enthalten).
Was wäre, wenn SQL Server irgendwie über alle möglichen Teile einer Zeichenfolge Bescheid wüsste? Mein Denkprozess ist entlang der Linien von trigram / trigraph in PostgreSQL. Das Grundkonzept besteht darin, dass die Engine in der Lage ist, punktuelle Lookups für Teilstrings durchzuführen, was bedeutet, dass Sie nicht die gesamte Tabelle scannen und jeden vollständigen Wert parsen müssen.
Das spezifische Beispiel, das sie dort verwenden, ist das Wort cat . Zusätzlich zum ganzen Wort kann es in Teile zerlegt werden:c , ca , und at (sie lassen a weg und t per Definition – keine nachgestellte Teilzeichenfolge darf kürzer als zwei Zeichen sein). In SQL Server brauchen wir es nicht so komplex; wir brauchen eigentlich nur das halbe Trigramm – wenn wir daran denken, eine Datenstruktur aufzubauen, die alle Teilstrings von cat enthält , brauchen wir nur diese Werte:
- Katze
- bei
- t
Wir brauchen c nicht oder ca , denn jeder, der nach LIKE '%ca%' sucht könnte den Wert 1 leicht finden, indem Sie LIKE 'ca%' verwenden stattdessen. Ebenso jeder, der nach LIKE '%at%' sucht oder LIKE '%a%' könnte einen abschließenden Platzhalter nur für diese drei Werte verwenden und den passenden finden (z. B. LIKE 'at%' findet den Wert 2 und LIKE 'a%' wird auch Wert 2 finden, ohne diese Teilstrings innerhalb von Wert 1 finden zu müssen, woher der wirkliche Schmerz kommen würde).
Da SQL Server so etwas nicht eingebaut hat, wie generieren wir ein solches Trigramm?
Eine separate Fragmenttabelle
Ich werde hier aufhören, auf „Trigramm“ zu verweisen, da dies nicht wirklich analog zu dieser Funktion in PostgreSQL ist. Im Wesentlichen werden wir eine separate Tabelle mit allen "Fragmenten" der ursprünglichen Zeichenfolge erstellen. (Also in der cat Beispielsweise gäbe es eine neue Tabelle mit diesen drei Zeilen und LIKE '%pattern%' Suchen würden gegen diese neue Tabelle gerichtet als LIKE 'pattern%' Prädikate.)
Bevor ich anfange zu zeigen, wie meine vorgeschlagene Lösung funktionieren würde, möchte ich absolut klarstellen, dass diese Lösung nicht in jedem einzelnen Fall verwendet werden sollte, in dem LIKE '%wildcard%' Suchen sind langsam. Aufgrund der Art und Weise, wie wir die Quelldaten in Fragmente "explodieren", ist sie wahrscheinlich auf kleinere Zeichenfolgen wie Adressen oder Namen beschränkt, im Gegensatz zu größeren Zeichenfolgen wie Produktbeschreibungen oder Zusammenfassungen von Sitzungen.
Ein praktischeres Beispiel als cat ist, sich Sales.Customer anzusehen Tabelle in der WideWorldImporters-Beispieldatenbank. Es hat Adresszeilen (beide nvarchar(60) ), mit den wertvollen Adressinformationen in der Spalte DeliveryAddressLine2 (aus unbekannten Gründen). Vielleicht sucht jemand nach jemandem, der in einer Straße namens Hudecova wohnt , also führen sie eine Suche wie diese aus:
SELECT CustomerID, DeliveryAddressLine2
FROM Sales.Customers
WHERE DeliveryAddressLine2 LIKE N'%Hudecova%';
/* This returns two rows:
CustomerID DeliveryAddressLine2
---------- ----------------------
61 1695 Hudecova Avenue
181 1846 Hudecova Crescent
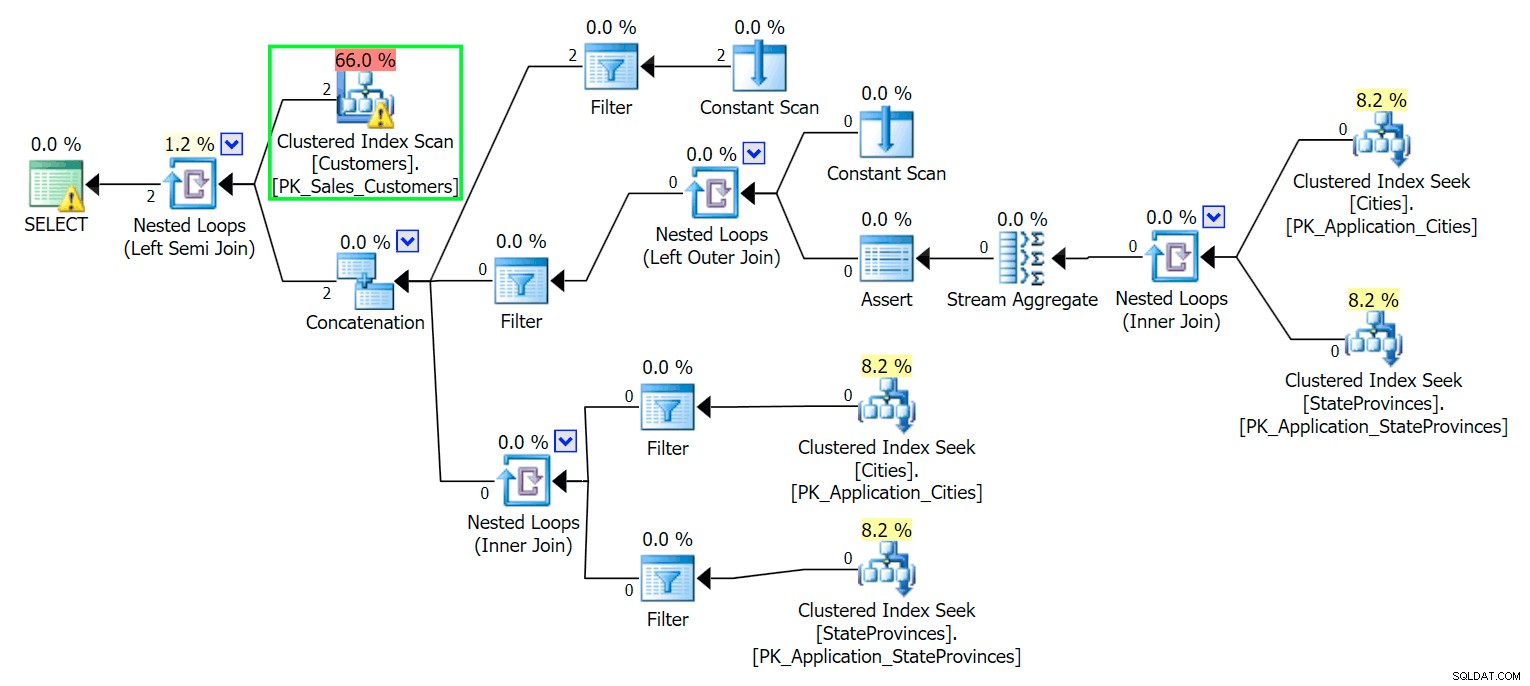
*/ Wie zu erwarten, muss SQL Server einen Scan durchführen, um diese beiden Zeilen zu finden. Was einfach sein sollte; Aufgrund der Komplexität der Tabelle ergibt diese triviale Abfrage jedoch einen sehr chaotischen Ausführungsplan (der Scan wird hervorgehoben und enthält eine Warnung für verbleibende E/A):
Bleich. Um unser Leben einfach zu halten und sicherzustellen, dass wir nicht einem Haufen Ablenkungsmanöver nachjagen, erstellen wir eine neue Tabelle mit einer Teilmenge der Spalten, und zu Beginn fügen wir einfach dieselben zwei Zeilen von oben ein:
CREATE TABLE Sales.CustomersCopy ( CustomerID int IDENTITY(1,1) CONSTRAINT PK_CustomersCopy PRIMARY KEY, CustomerName nvarchar(100) NOT NULL, DeliveryAddressLine1 nvarchar(60) NOT NULL, DeliveryAddressLine2 nvarchar(60) ); GO INSERT Sales.CustomersCopy ( CustomerName, DeliveryAddressLine1, DeliveryAddressLine2 ) SELECT CustomerName, DeliveryAddressLine1, DeliveryAddressLine2 FROM Sales.Customers WHERE DeliveryAddressLine2 LIKE N'%Hudecova%';
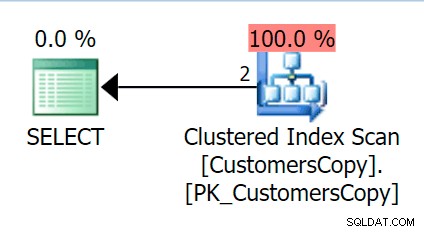
Wenn wir jetzt die gleiche Abfrage ausführen, die wir für die Haupttabelle ausgeführt haben, erhalten wir etwas viel Vernünftigeres, das wir uns als Ausgangspunkt ansehen können. Dies wird immer noch ein Scan sein, egal was wir tun – wenn wir einen Index mit DeliveryAddressLine2 hinzufügen Als führende Schlüsselspalte erhalten wir höchstwahrscheinlich einen Index-Scan mit einer Schlüsselsuche, je nachdem, ob der Index die Spalten in der Abfrage abdeckt. So erhalten wir einen Clustered-Index-Scan:
Als Nächstes erstellen wir eine Funktion, die diese Adresswerte in Fragmente „explodiert“. Wir würden 1846 Hudecova Crescent erwarten , um beispielsweise den folgenden Satz von Fragmenten zu haben:
- Hudecova-Halbmond von 1846
- 846 Hudecova Halbmond
- 46 Hudecova Halbmond
- 6 Hudecova Halbmond
- Hudecova-Halbmond
- Hudecova-Halbmond
- udecova Halbmond
- decova Crescent
- ecova Crescent
- Cova Crescent
- Eizellenhalbmond
- va Crescent
- ein Halbmond
- Halbmond
- Halbmond
- neuer
- eszent
- Duft
- Cent
- ent
- nicht
- t
Es ist ziemlich trivial, eine Funktion zu schreiben, die diese Ausgabe erzeugt – wir brauchen nur einen rekursiven CTE, der verwendet werden kann, um jedes Zeichen über die gesamte Länge der Eingabe schrittweise durchzugehen:
CREATE FUNCTION dbo.CreateStringFragments( @input nvarchar(60) )
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN
(
WITH x(x) AS
(
SELECT 1 UNION ALL SELECT x+1 FROM x WHERE x < (LEN(@input))
)
SELECT Fragment = SUBSTRING(@input, x, LEN(@input)) FROM x
);
GO
SELECT Fragment FROM dbo.CreateStringFragments(N'1846 Hudecova Crescent');
-- same output as above bulleted list Lassen Sie uns nun eine Tabelle erstellen, die alle Adressfragmente speichert und zu welchem Kunden sie gehören:
CREATE TABLE Sales.CustomerAddressFragments ( CustomerID int NOT NULL, Fragment nvarchar(60) NOT NULL, CONSTRAINT FK_Customers FOREIGN KEY(CustomerID) REFERENCES Sales.CustomersCopy(CustomerID) ); CREATE CLUSTERED INDEX s_cat ON Sales.CustomerAddressFragments(Fragment, CustomerID);
Dann können wir es wie folgt füllen:
INSERT Sales.CustomerAddressFragments(CustomerID, Fragment) SELECT c.CustomerID, f.Fragment FROM Sales.CustomersCopy AS c CROSS APPLY dbo.CreateStringFragments(c.DeliveryAddressLine2) AS f;
Für unsere beiden Werte fügt dies 42 Zeilen ein (eine Adresse hat 20 Zeichen und die andere 22). Jetzt wird unsere Abfrage zu:
SELECT c.CustomerID, c.DeliveryAddressLine2
FROM Sales.CustomersCopy AS c
INNER JOIN Sales.CustomerAddressFragments AS f
ON f.CustomerID = c.CustomerID
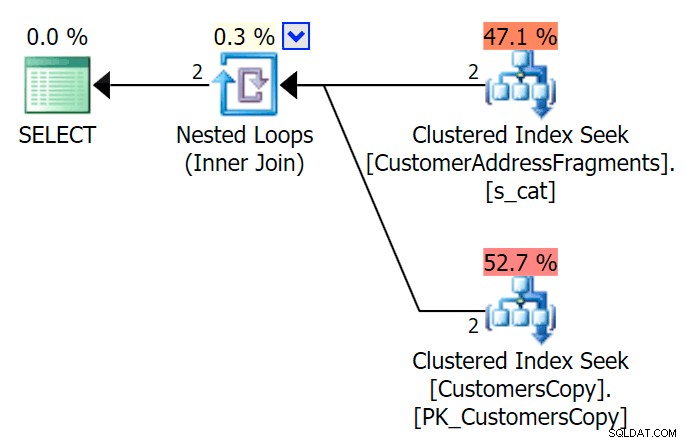
AND f.Fragment LIKE N'Hudecova%'; Hier ist ein viel schönerer Plan – zwei gruppierte Indizes *suchen* und eine verschachtelte Schleife verbinden:
Wir können dies auch auf andere Weise tun, indem wir EXISTS verwenden :
SELECT c.CustomerID, c.DeliveryAddressLine2
FROM Sales.CustomersCopy AS c
WHERE EXISTS
(
SELECT 1 FROM Sales.CustomerAddressFragments
WHERE CustomerID = c.CustomerID
AND Fragment LIKE N'Hudecova%'
); Hier ist dieser Plan, der auf den ersten Blick teurer aussieht – er scannt die CustomersCopy-Tabelle. Wir werden gleich sehen, warum dies der bessere Abfrageansatz ist:
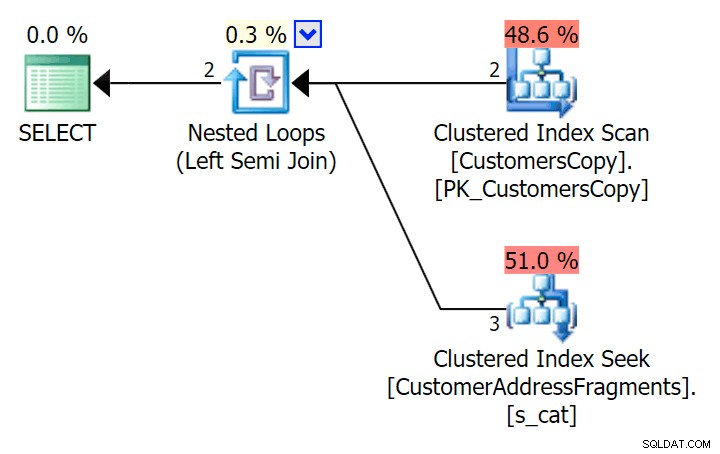
Bei diesem riesigen Datensatz mit 42 Zeilen sind die Unterschiede in Dauer und E/A so winzig, dass sie irrelevant sind (und tatsächlich sieht der Scan gegen die Basistabelle bei dieser geringen Größe in Bezug auf E/A billiger aus O als die anderen beiden Pläne, die die Fragmenttabelle verwenden):

Was wäre, wenn wir diese Tabellen mit viel mehr Daten füllen würden? Meine Kopie von Sales.Customers hat 663 Zeilen, also wenn wir das gegen sich selbst kreuzen, würden wir ungefähr 440.000 Zeilen bekommen. Lassen Sie uns also einfach 400 KB zusammenfassen und eine viel größere Tabelle erstellen:
TRUNCATE TABLE Sales.CustomerAddressFragments; DELETE Sales.CustomersCopy; DBCC FREEPROCCACHE WITH NO_INFOMSGS; INSERT Sales.CustomersCopy WITH (TABLOCKX) (CustomerName, DeliveryAddressLine1, DeliveryAddressLine2) SELECT TOP (400000) c1.CustomerName, c1.DeliveryAddressLine1, c2.DeliveryAddressLine2 FROM Sales.Customers c1 CROSS JOIN Sales.Customers c2 ORDER BY NEWID(); -- fun for distribution -- this will take a bit longer - on my system, ~4 minutes -- probably because I didn't bother to pre-expand files INSERT Sales.CustomerAddressFragments WITH (TABLOCKX) (CustomerID, Fragment) SELECT c.CustomerID, f.Fragment FROM Sales.CustomersCopy AS c CROSS APPLY dbo.CreateStringFragments(c.DeliveryAddressLine2) AS f; -- repeated for compressed version of the table -- 7.25 million rows, 278MB (79MB compressed; saving those tests for another day)
Um nun Leistung und Ausführungspläne bei einer Vielzahl möglicher Suchparameter zu vergleichen, habe ich die obigen drei Abfragen mit diesen Prädikaten getestet:
| Abfrage | Prädikate | ||||
|---|---|---|---|---|---|
| WO DeliveryLineAddress2 LIKE … | N'%Hudecova%' | N'%cova%' | N'%ova%' | N'%va%' | |
| VERBINDE … WO Fragment WIE … | N'Hudecova%' | N'cova%' | N'ova%' | N'va%' | |
| WO VORHANDEN (… WO Fragment WIE …) | |||||
Wenn wir Buchstaben aus dem Suchmuster entfernen, würde ich erwarten, dass mehr Zeilen ausgegeben werden und möglicherweise andere Strategien vom Optimierer gewählt werden. Mal sehen, wie es für jedes Muster gelaufen ist:
Hudecova%
Für dieses Muster war der Scan für die LIKE-Bedingung immer noch derselbe; Mit mehr Daten sind die Kosten jedoch viel höher. Bei dieser Zeilenanzahl (1.206) zahlen sich die Suchvorgänge in der Fragments-Tabelle wirklich aus, selbst bei sehr niedrigen Schätzungen. Der EXISTS-Plan fügt eine eindeutige Sortierung hinzu, die Sie zu den Kosten hinzufügen würden, obwohl in diesem Fall weniger Lesevorgänge ausgeführt werden:

 Planen Sie den JOIN zur Fragmenttabelle
Planen Sie den JOIN zur Fragmenttabelle 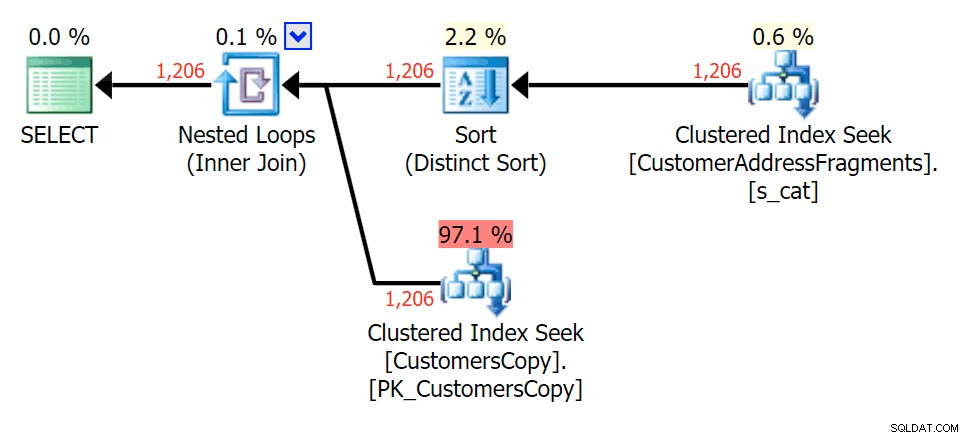 Planen Sie EXISTS anhand der Fragmenttabelle
Planen Sie EXISTS anhand der Fragmenttabelle cova%
Wenn wir einige Buchstaben von unserem Prädikat entfernen, sehen wir die Lesevorgänge tatsächlich etwas höher als beim ursprünglichen Clustered-Index-Scan, und jetzt über -Schätzen Sie die Zeilen. Trotzdem bleibt unsere Dauer bei beiden Fragmentabfragen deutlich geringer; der Unterschied ist diesmal subtiler – beide haben Sorten (nur EXISTS ist verschieden):

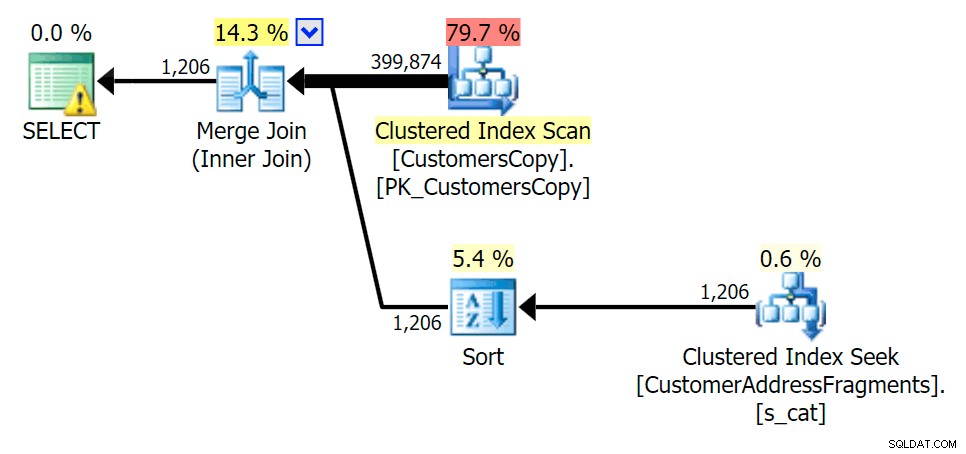 Planen Sie den JOIN zur Fragmenttabelle
Planen Sie den JOIN zur Fragmenttabelle 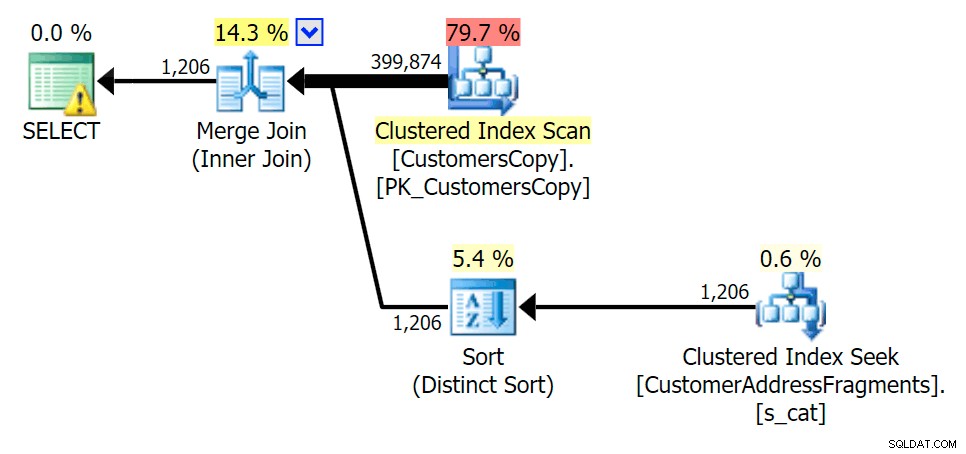 Planen Sie EXISTS anhand der Fragmenttabelle
Planen Sie EXISTS anhand der Fragmenttabelle ova%
Das Entfernen eines zusätzlichen Buchstabens änderte nicht viel; Es ist jedoch erwähnenswert, wie stark die geschätzten und tatsächlichen Zeilen hier springen – was bedeutet, dass dies ein häufiges Muster von Teilzeichenfolgen sein kann. Die ursprüngliche LIKE-Abfrage ist immer noch etwas langsamer als die Fragment-Abfragen.

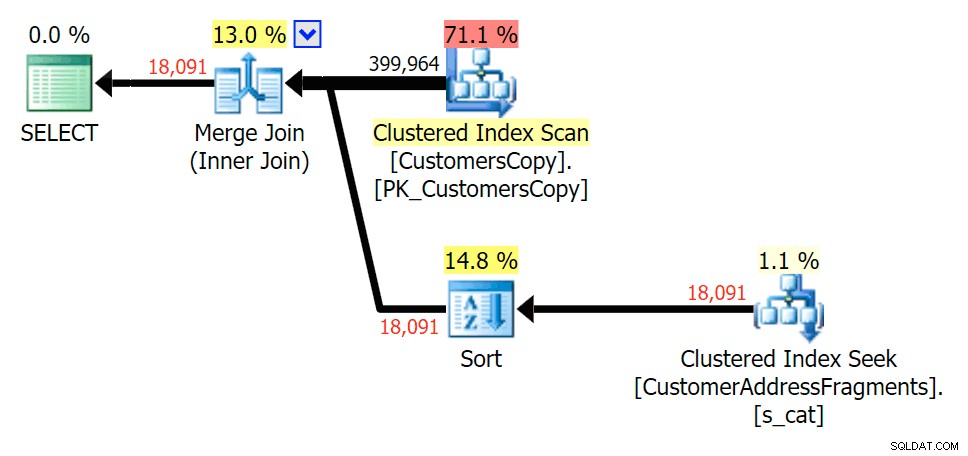 Planen Sie den JOIN zur Fragmenttabelle
Planen Sie den JOIN zur Fragmenttabelle 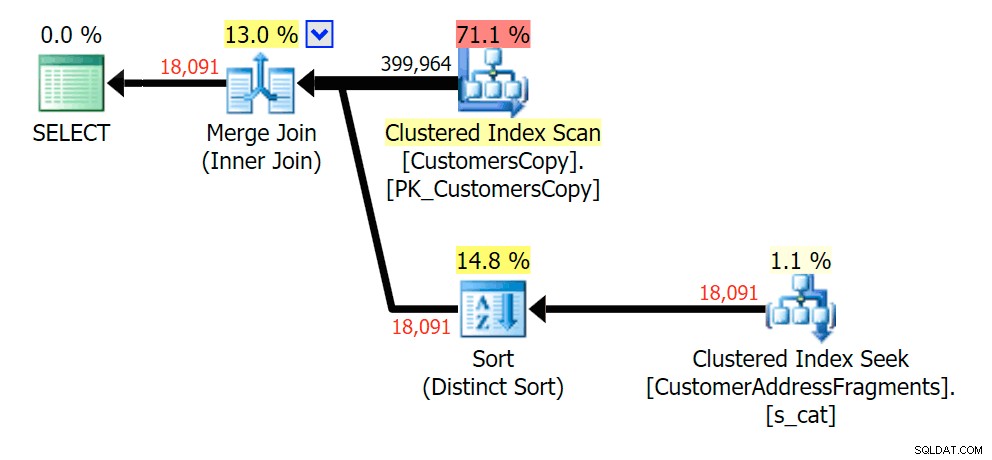 Planen Sie EXISTS anhand der Fragmenttabelle
Planen Sie EXISTS anhand der Fragmenttabelle va%
Bis auf zwei Buchstaben führt dies zu unserer ersten Diskrepanz. Beachten Sie, dass der JOIN mehr produziert Zeilen als die ursprüngliche Abfrage oder die EXISTS. Warum sollte das so sein?

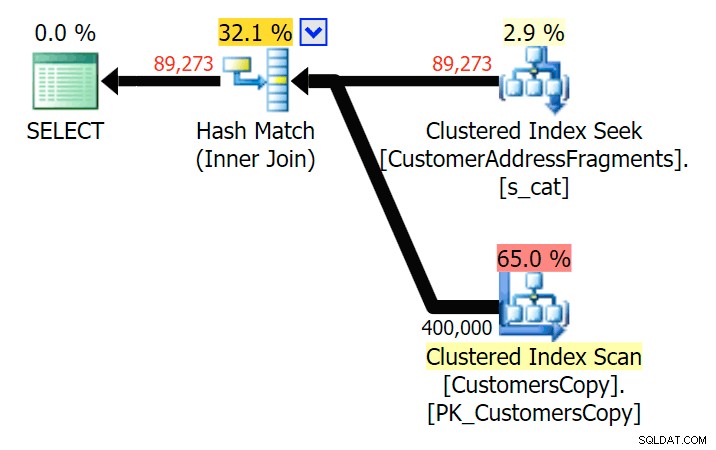 Planen Sie den JOIN zur Fragmenttabelle
Planen Sie den JOIN zur Fragmenttabelle 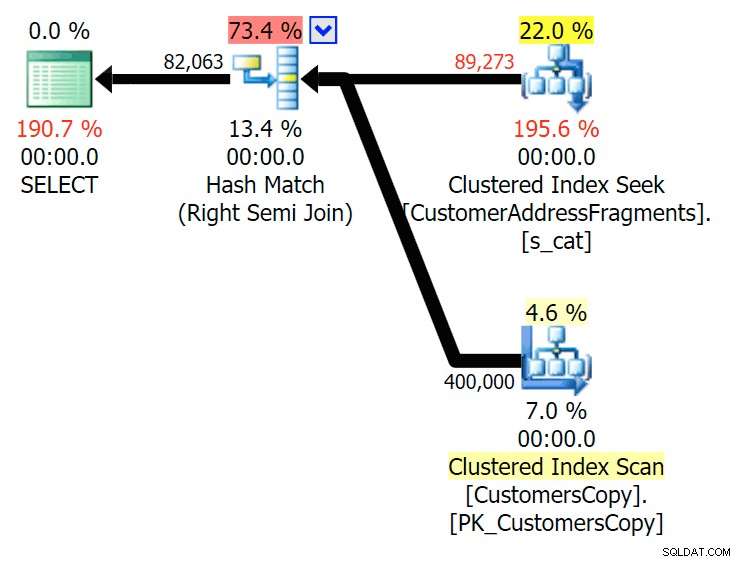 Planen Sie EXISTS anhand der Fragmenttabelle Wir müssen nicht weit suchen. Denken Sie daran, dass es ein Fragment gibt, das mit jedem aufeinanderfolgenden Zeichen in der ursprünglichen Adresse beginnt, was so etwas wie
Planen Sie EXISTS anhand der Fragmenttabelle Wir müssen nicht weit suchen. Denken Sie daran, dass es ein Fragment gibt, das mit jedem aufeinanderfolgenden Zeichen in der ursprünglichen Adresse beginnt, was so etwas wie 899 Valentova Road bedeutet wird zwei Zeilen in der Fragmenttabelle haben, die mit va beginnen (Groß- und Kleinschreibung beiseite). Sie stimmen also auf beiden Fragment = N'Valentova Road' überein und Fragment = N'va Road' . Ich erspare Ihnen die Suche und gebe ein einzelnes Beispiel von vielen: SELECT TOP (2) c.CustomerID, c.DeliveryAddressLine2, f.Fragment FROM Sales.CustomersCopy AS c INNER JOIN Sales.CustomerAddressFragments AS f ON c.CustomerID = f.CustomerID WHERE f.Fragment LIKE N'va%' AND c.DeliveryAddressLine2 = N'899 Valentova Road' AND f.CustomerID = 351; /* CustomerID DeliveryAddressLine2 Fragment ---------- -------------------- -------------- 351 899 Valentova Road va Road 351 899 Valentova Road Valentova Road */
Dies erklärt ohne weiteres, warum der JOIN mehr Zeilen erzeugt; Wenn Sie die Ausgabe der ursprünglichen LIKE-Abfrage abgleichen möchten, sollten Sie EXISTS verwenden. Dass die richtigen Ergebnisse meist auch weniger ressourcenintensiv erzielt werden können, ist nur ein Bonus. (Ich wäre nervös, wenn Leute sich für JOIN entscheiden würden, wenn dies die immer effizientere Option wäre – Sie sollten korrekte Ergebnisse immer der Sorge um die Leistung vorziehen.)
Zusammenfassung
Das ist in diesem speziellen Fall klar – mit einer Adressspalte von nvarchar(60) und eine maximale Länge von 26 Zeichen – das Aufteilen jeder Adresse in Fragmente kann eine gewisse Erleichterung bei ansonsten teuren „führenden Wildcard“-Suchen bringen. Die bessere Auszahlung scheint zu erfolgen, wenn das Suchmuster größer und folglich einzigartiger ist. Ich habe auch gezeigt, warum EXISTS in Szenarien besser ist, in denen mehrere Übereinstimmungen möglich sind – mit einem JOIN erhalten Sie eine redundante Ausgabe, es sei denn, Sie fügen eine „größte n pro Gruppe“-Logik hinzu.
Warnhinweise
Ich werde der Erste sein, der zugibt, dass diese Lösung unvollkommen, unvollständig und nicht gründlich ausgearbeitet ist:
- Sie müssen die Fragmenttabelle mithilfe von Triggern mit der Basistabelle synchronisieren – am einfachsten wäre es, für Einfügungen und Aktualisierungen alle Zeilen für diese Kunden zu löschen und sie erneut einzufügen, und für Löschungen natürlich die Zeilen aus den Fragmenten zu entfernen Tisch.
- Wie bereits erwähnt, funktionierte diese Lösung besser für diese spezifische Datengröße und möglicherweise nicht so gut für andere Zeichenfolgenlängen. Es würde weitere Tests erfordern, um sicherzustellen, dass es für Ihre Spaltengröße, Durchschnittswertlänge und typische Suchparameterlänge geeignet ist.
- Da wir viele Kopien von Fragmenten wie "Crescent" und "Street" haben werden (ganz egal, alle gleichen oder ähnlichen Straßennamen und Hausnummern), könnten wir es weiter normalisieren, indem wir jedes einzelne Fragment in einer Fragmenttabelle speichern, und dann noch eine weitere Tabelle, die als Viele-zu-Viele-Verbindungstabelle fungiert. Das wäre viel umständlicher einzurichten, und ich bin mir nicht sicher, ob es viel zu gewinnen gäbe.
- Ich habe die Seitenkomprimierung noch nicht vollständig untersucht, es scheint, dass dies – zumindest theoretisch – einige Vorteile bringen könnte. Ich habe auch das Gefühl, dass eine Columnstore-Implementierung in einigen Fällen ebenfalls von Vorteil sein kann.
Wie auch immer, alles in allem wollte ich es nur als sich entwickelnde Idee teilen und um Feedback zu seiner Praktikabilität für bestimmte Anwendungsfälle bitten. Ich kann in einem zukünftigen Beitrag auf weitere Einzelheiten eingehen, wenn Sie mir mitteilen können, welche Aspekte dieser Lösung Sie interessieren.