Percona XtraDB Cluster ist eine sehr bekannte Hochverfügbarkeitslösung in der MySQL-Welt. Es basiert auf Galera Cluster und bietet eine praktisch synchrone Replikation über mehrere Knoten hinweg. Wie bei jeder Datenbank ist es entscheidend, den Überblick darüber zu behalten, was im System passiert, ob die Leistung auf dem erwarteten Niveau liegt und wenn nicht, wo der Engpass liegt. Dies ist von größter Bedeutung, um in Situationen, in denen die Leistung beeinträchtigt wird, richtig reagieren zu können. Natürlich verfügt Percona XtraDB Cluster über mehrere Metriken, und es ist nicht immer klar, welche davon die wichtigsten sind, um den Zustand der Datenbank zu verfolgen. In diesem Blog besprechen wir einige der wichtigsten Kennzahlen, die Sie bei der Arbeit mit PXC im Auge behalten sollten.
Um es deutlich zu machen, werden wir uns auf die Metriken konzentrieren, die nur für PXC und Galera gelten, wir werden keine Metriken für MySQL oder InnoDB abdecken. Diese Metriken wurden in unseren vorherigen Blogs diskutiert.
Werfen wir einen Blick auf einige der wichtigsten Informationen, die uns PXC präsentiert.
Flusskontrolle
Flusskontrolle ist so ziemlich die wichtigste Metrik, die Sie in jedem Galera-Cluster überwachen können, also lassen Sie uns ein wenig Hintergrundwissen haben. Galera ist ein nahezu synchroner Multi-Master-Cluster. Es ist möglich, Schreibvorgänge auf jedem der Datenbankknoten auszuführen, die sie bilden. Jeder Schreibvorgang muss an alle Knoten im Cluster gesendet werden, um sicherzustellen, dass er angewendet werden kann – dieser Vorgang wird als Zertifizierung bezeichnet. Keine Transaktion kann angewendet werden, bevor alle Knoten zustimmen, dass sie festgeschrieben werden kann. Wenn einer der Knoten Leistungsprobleme hat, die es ihm unmöglich machen, den Datenverkehr zu bewältigen, beginnt er mit der Ausgabe von Nachrichten zur Flusssteuerung, die den Rest des Clusters über die Leistungsprobleme informieren und sie auffordern sollen, die Arbeitslast zu reduzieren und den Verspäteten zu helfen Knoten, um den Rest des Clusters einzuholen.
Sie können nachverfolgen, wann Knoten eine künstliche Pause einführen mussten, damit ihre hinterherhinkenden Peers aufholen konnten, indem Sie die Metrik für pausierte Flusssteuerung (wsrep_flow_control_paused) verwenden:

Sie können auch nachverfolgen, ob der Knoten Nachrichten zur Flusssteuerung sendet oder empfängt (wsrep_flow_control_recv und wsrep_flow_control_sent).
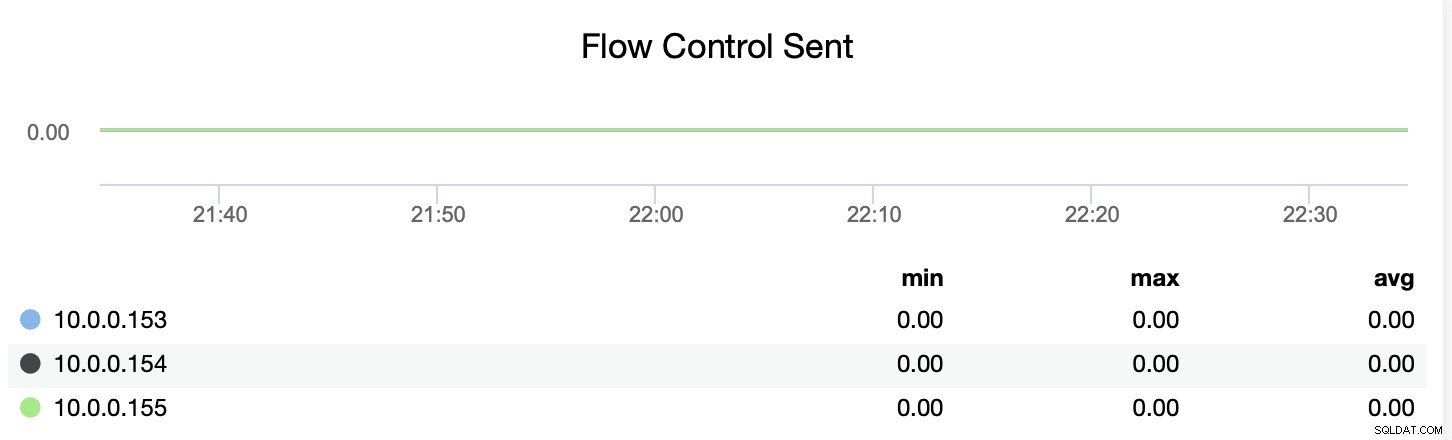
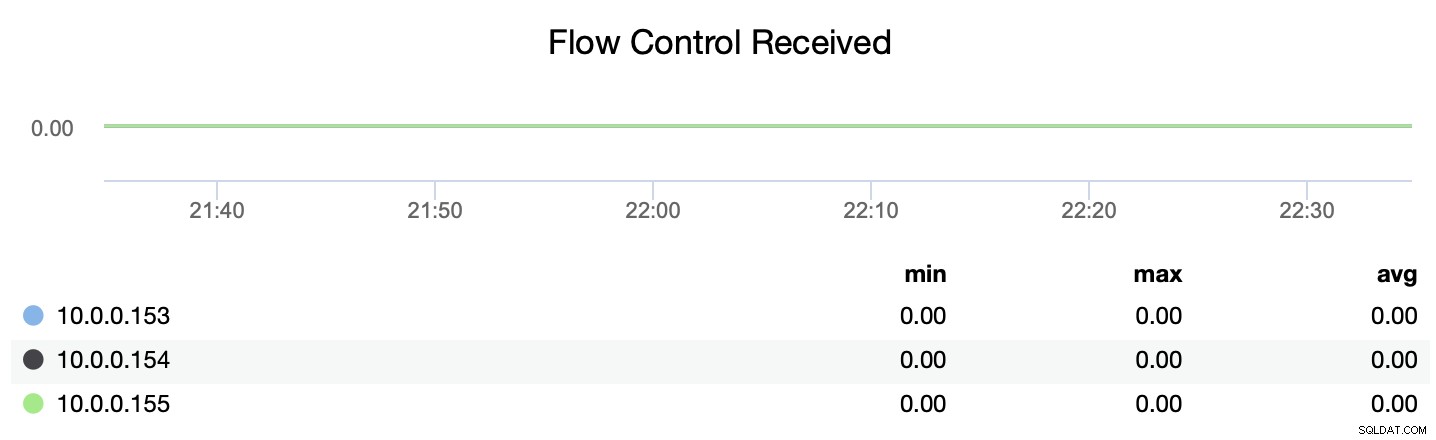
Diese Informationen helfen Ihnen, besser zu verstehen, welcher Knoten auf demselben Knoten keine Leistung erbringt Niveau wie seinesgleichen. Sie können sich dann auf diesen Knoten konzentrieren und versuchen zu verstehen, was das Problem ist und wie Sie den Engpass beseitigen können.
Sende- und Empfangswarteschlangen
Diese Metriken hängen irgendwie mit der Flusskontrolle zusammen. Wie wir besprochen haben, kann ein Knoten anderen Knoten im Cluster hinterherhinken. Dies kann durch eine ungleichmäßige Aufteilung der Arbeitslast oder durch andere Gründe verursacht werden (ein Prozess, der im Hintergrund ausgeführt wird, eine Sicherung oder einige benutzerdefinierte, umfangreiche Abfragen). Bevor die Flusskontrolle einsetzt, versuchen verzögerte Knoten, die eingehenden Writesets in der Empfangswarteschlange (wsrep_local_recv_queue) zu speichern, in der Hoffnung, dass die Auswirkungen auf die Leistung vorübergehend sind und sie sehr bald aufholen können. Nur wenn die Warteschlange zu groß wird (dies wird durch die gcs.fc_limit-Einstellung geregelt), werden Nachrichten zur Flusskontrolle über den Cluster gesendet.

Sie können sich eine Empfangswarteschlange als frühe Markierung vorstellen, die das dort anzeigt Probleme mit der Leistung auftreten und die Flusskontrolle eingreifen kann.

Auf der anderen Seite teilt Ihnen die Sendewarteschlange (wsrep_local_send_queue) mit, dass der Knoten nicht in der Lage ist, die Writesets an andere Mitglieder des Clusters zu senden, was auf Probleme mit der Netzwerkkonnektivität hinweisen kann (die Writesets nach das Netzwerk ist nicht wirklich ressourcenintensiv).
Parallelisierungsmetriken
Der Percona XtraDB-Cluster kann so konfiguriert werden, dass er mehrere Threads verwendet, um die eingehenden Writesets anzuwenden – es ermöglicht ihm, mehrere Threads besser zu handhaben, die sich mit dem Cluster verbinden und gleichzeitig Schreibvorgänge ausgeben. Es gibt zwei Hauptmetriken, die Sie im Auge behalten sollten.
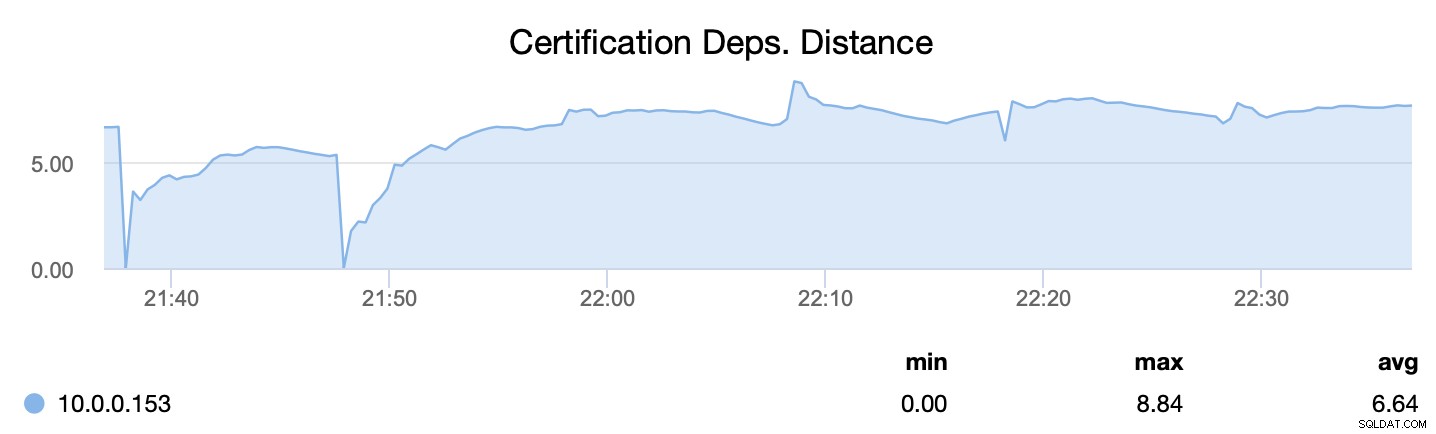
Als erstes teilt uns wsrep_cert_deps_distance mit, was das Parallelisierungspotenzial ist – wie viele Writesets potenziell gleichzeitig angewendet werden können. Basierend auf diesem Wert können Sie die Anzahl der parallelen Slave-Threads (wsrep_slave_threads) konfigurieren, die beim Anwenden eingehender Writesets arbeiten. Als Faustregel gilt, dass es keinen Sinn macht, mehr Threads als den Wert von wsrep_cert_deps_distance.
zu konfigurieren 
Die zweite Metrik hingegen sagt uns, wie effizient wir den Prozess des Anwendens von Writesets parallelisieren konnten - wsrep_apply_oooe sagt uns, wie oft der Anwendende damit begonnen hat, Writesets in falscher Reihenfolge anzuwenden (was auf eine bessere Parallelisierung hinweist). ).
Fazit
Wie Sie sehen können, gibt es im Percona XtraDB-Cluster einige Metriken, die es wert sind, betrachtet zu werden. Wie bereits zu Beginn dieses Blogs erwähnt, handelt es sich hierbei natürlich um Metriken, die eng mit PXC und dem Galera-Cluster im Allgemeinen zusammenhängen.
Sie sollten auch regelmäßige MySQL- und InnoDB-Metriken im Auge behalten, um den Zustand Ihrer Datenbank besser zu verstehen. Und denken Sie daran, dass Sie diese Technologie mit der ClusterControl Community Edition kostenlos überwachen können.