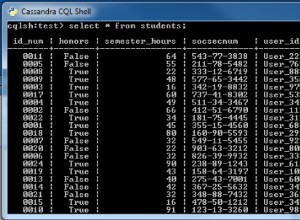
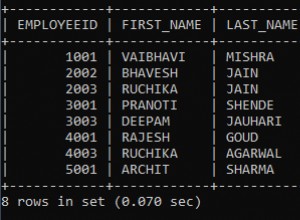
Antimuster?
Im Normalfall ist die zweite Tabelle Anti-Pattern im Kontext des Datenbankdesigns. Und mehr noch, es hat einen bestimmten Namen:Entity-Attribute-Value (EAV). Es gibt einige Fälle, in denen die Verwendung dieses Designs gerechtfertigt ist, aber das sind seltene Fälle - und selbst dort kann es vermieden werden.
Warum EAV schlecht ist
Unterstützung der Datenintegrität
Trotz der Tatsache, dass eine solche Struktur "flexibler" oder "fortschrittlicher" zu sein scheint, hat dieses Design Schwächen.
- Unmöglich, obligatorische Attribute zu erstellen . Sie können einige Attribute nicht obligatorisch machen, da das Attribut jetzt als Zeile gespeichert wird – und das einzige Zeichen dafür, dass das Attribut nicht gesetzt ist – ist, dass die entsprechende Zeile in der Tabelle fehlt. SQL erlaubt es Ihnen nicht, eine solche Einschränkung nativ zu erstellen - daher müssen Sie dies in der Anwendung überprüfen - und, ja, jedes Mal Ihre Tabelle abfragen
- Vermischung von Datentypen . Sie können keine SQL-Standarddatentypen verwenden. Weil Ihre Wertspalte ein "Supertyp" für alle darin gespeicherten Werte sein muss. Das heißt - Sie müssen generell alle Daten als Rohstrings speichern . Dann werden Sie sehen, wie mühsam es ist, mit Datumsangaben wie mit Strings zu arbeiten, jedes Mal Datentypen umzuwandeln, die Datenintegrität zu prüfen usw.
- Unmöglich, referenzielle Integrität zu erzwingen . Im Normalfall können Sie den Fremdschlüssel verwenden, um Ihre Werte auf diejenigen einzuschränken, die in der übergeordneten Tabelle definiert sind. Aber nicht in diesem Fall - das liegt daran, dass die referenzielle Integrität auf jede Zeile in der Tabelle angewendet wird, aber nicht auf Zeilenwerte. Also - Sie werden diesen Vorteil verlieren - und es ist einer der grundlegenden in Bezug DB
- Unmöglich, Attributnamen festzulegen . Das bedeutet - Sie können den Attributnamen auf DB-Ebene nicht richtig einschränken. Sie schreiben beispielsweise
"customer_name"als Attributname im ersten Fall - und ein anderer Entwickler wird das vergessen und"name_of_customer"verwenden . Und ... es ist in Ordnung, DB wird das bestehen und Sie werden am Ende Stunden damit verbringen, diesen Fall zu debuggen.
Zeilenrekonstruktion
Außerdem wird die Zeilenrekonstruktion im allgemeinen Fall schrecklich sein. Wenn Sie beispielsweise 5 Attribute haben, sind das 5 Selbsttabellen JOIN -s. Schade für so einen auf den ersten Blick einfachen Fall. Ich möchte mir also gar nicht vorstellen, wie Sie 20 Attribute pflegen.
Kann es gerechtfertigt sein?
Mein Punkt ist - nein. In RDBMS wird es immer einen Weg geben, dies zu vermeiden. Es ist schrecklich. Und wenn EAV verwendet werden soll, ist die beste Wahl möglicherweise nicht-relational Datenbanken.