Laut Wikipedia „ist eine Masseneinfügung ein Prozess oder eine Methode, die von einem Datenbankverwaltungssystem bereitgestellt wird, um mehrere Datenzeilen in eine Datenbanktabelle zu laden.“ Wenn wir diese Erklärung gemäß der BULK INSERT-Anweisung anpassen, ermöglicht die Masseneinfügung das Importieren externer Datendateien in SQL Server. Angenommen, unsere Organisation hat eine CSV-Datei mit 1.500.000 Zeilen und wir möchten diese Datei in eine bestimmte Tabelle in SQL Server importieren, damit wir die BULK INSERT-Anweisung in SQL Server problemlos verwenden können. Sicherlich können wir mehrere Importmethoden finden, um diesen CSV-Dateiimportprozess zu handhaben, z. wir können bcp (b ulk c opy p Programm), SQL Server Import/Export-Assistent oder SQL Server Integration Service-Paket. Die BULK INSERT-Anweisung ist jedoch viel schneller und robuster als die Verwendung anderer Methoden. Ein weiterer Vorteil der Bulk-Insert-Anweisung besteht darin, dass sie mehrere Parameter bietet, die dabei helfen, die Einstellungen des Bulk-Insert-Prozesses zu bestimmen.
Zuerst beginnen wir mit einem sehr einfachen Beispiel und gehen dann verschiedene anspruchsvolle Szenarien durch.
Vorbereitung
Bevor wir mit den Beispielen beginnen, benötigen wir eine Beispiel-CSV-Datei. Daher werden wir eine Beispiel-CSV-Datei von der E for Excel-Website herunterladen, wo Sie verschiedene Beispiel-CSV-Dateien mit einer anderen Zeilennummer finden können. Den Link findet ihr am Ende des Artikels. In unseren Szenarien verwenden wir 1.500.000 Verkaufsdatensätze. Laden Sie eine ZIP-Datei herunter, entpacken Sie die CSV-Datei und legen Sie sie auf Ihrem lokalen Laufwerk ab.

CSV-Datei in SQL Server-Tabelle importieren
Szenario-1:Ziel- und CSV-Datei haben die gleiche Anzahl an Spalten
In diesem ersten Szenario importieren wir die CSV-Datei in der einfachsten Form in die Zieltabelle. Ich habe meine Beispiel-CSV-Datei auf Laufwerk C:abgelegt und jetzt erstellen wir eine Tabelle, in die wir Daten aus der CSV-Datei importieren.
DROP TABLE IF EXISTS Sales CREATE TABLE [dbo].[Sales]( [Region] [varchar](50) , [Country] [varchar](50) , [ItemType] [varchar](50) NULL, [SalesChannel] [varchar](50) NULL, [OrderPriority] [varchar](50) NULL, [OrderDate] datetime, [OrderID] bigint NULL, [ShipDate] datetime, [UnitsSold] float, [UnitPrice] float, [UnitCost] float, [TotalRevenue] float, [TotalCost] float, [TotalProfit] float )
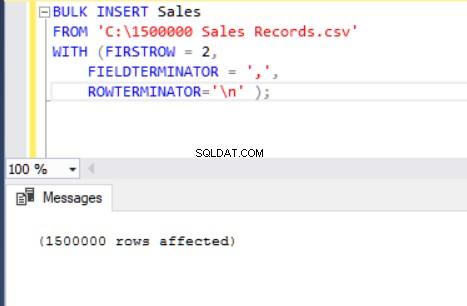
Die folgende BULK INSERT-Anweisung importiert die CSV-Datei in die Sales-Tabelle.
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' );
Nun erklären wir die Parameter der obigen Bulk-Insert-Anweisung.
Der FIRSTROW-Parameter gibt den Startpunkt der Einfügeanweisung an. Im folgenden Beispiel möchten wir Spaltenüberschriften überspringen, also setzen wir diesen Parameter auf 2.

FIELDTERMINATOR definiert das Zeichen, das Felder voneinander trennt. SQL Server erkennt jedes Feld auf diese Weise. ROWTERMINATOR unterscheidet sich nicht wesentlich von FIELDTERMINATOR. Es definiert den Trenncharakter von Zeilen. In der Beispiel-CSV-Datei ist das Feldabschlusszeichen sehr deutlich und es ist ein Komma (,). Aber wie können wir einen Feldterminator erkennen? Öffnen Sie die CSV-Datei in Notepad++ und navigieren Sie dann zu View->Show Symbol->Show All Charters und finden Sie dann die CRLF-Zeichen am Ende jedes Feldes heraus.
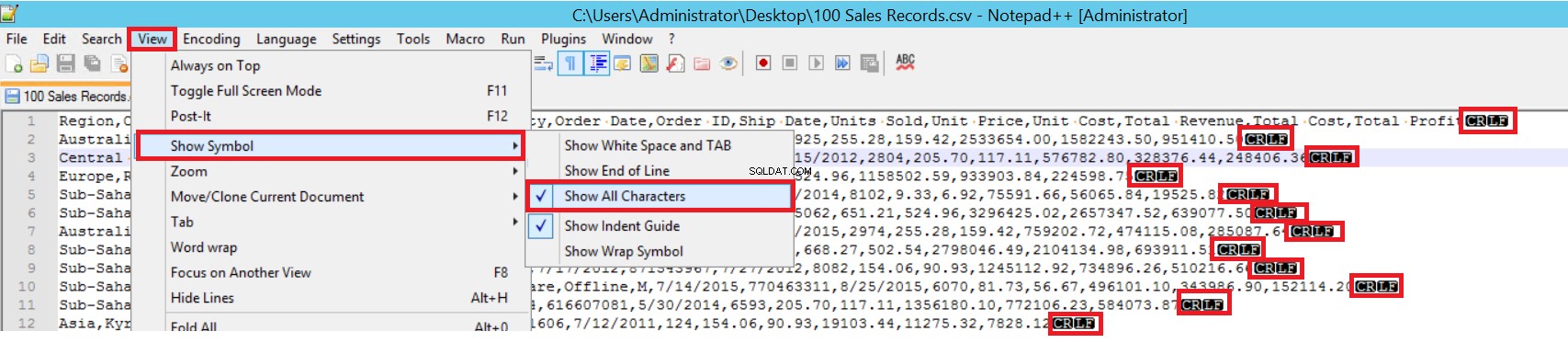
CR =Wagenrücklauf und LF =Zeilenvorschub. Sie werden verwendet, um einen Zeilenumbruch in einer Textdatei zu markieren, und dies wird durch das Zeichen „\n“ in der Masseneinfügeanweisung angezeigt.
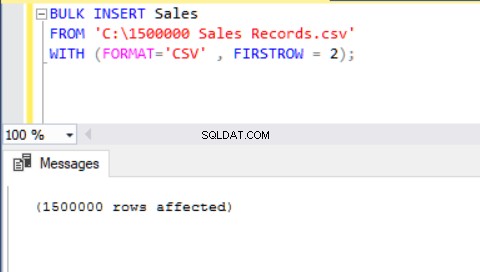
Eine andere Methode zum Importieren einer CSV-Datei in eine Tabelle mit Hilfe der Masseneinfügung ist die Verwendung des FORMAT-Parameters. Bitte beachten Sie, dass der Parameter FORMAT nur in SQL Server 2017 und späteren Versionen verfügbar ist.
BULK INSERT Sales FROM 'C:\1500000 Sales Records.csv' WITH (FORMAT='CSV' , FIRSTROW = 2);
Jetzt werden wir ein anderes Szenario analysieren.
Szenario-2:Die Zieltabelle hat mehr Spalten als die CSV-Datei
In diesem Szenario fügen wir der Sales-Tabelle einen Primärschlüssel hinzu, und in diesem Fall werden die Gleichheitsspaltenzuordnungen unterbrochen. Jetzt erstellen wir die Sales-Tabelle mit einem Primärschlüssel, versuchen, die CSV-Datei über den Bulk-Insert-Befehl zu importieren, und erhalten dann eine Fehlermeldung.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
Id INT PRIMARY KEY IDENTITY (1,1),
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' );
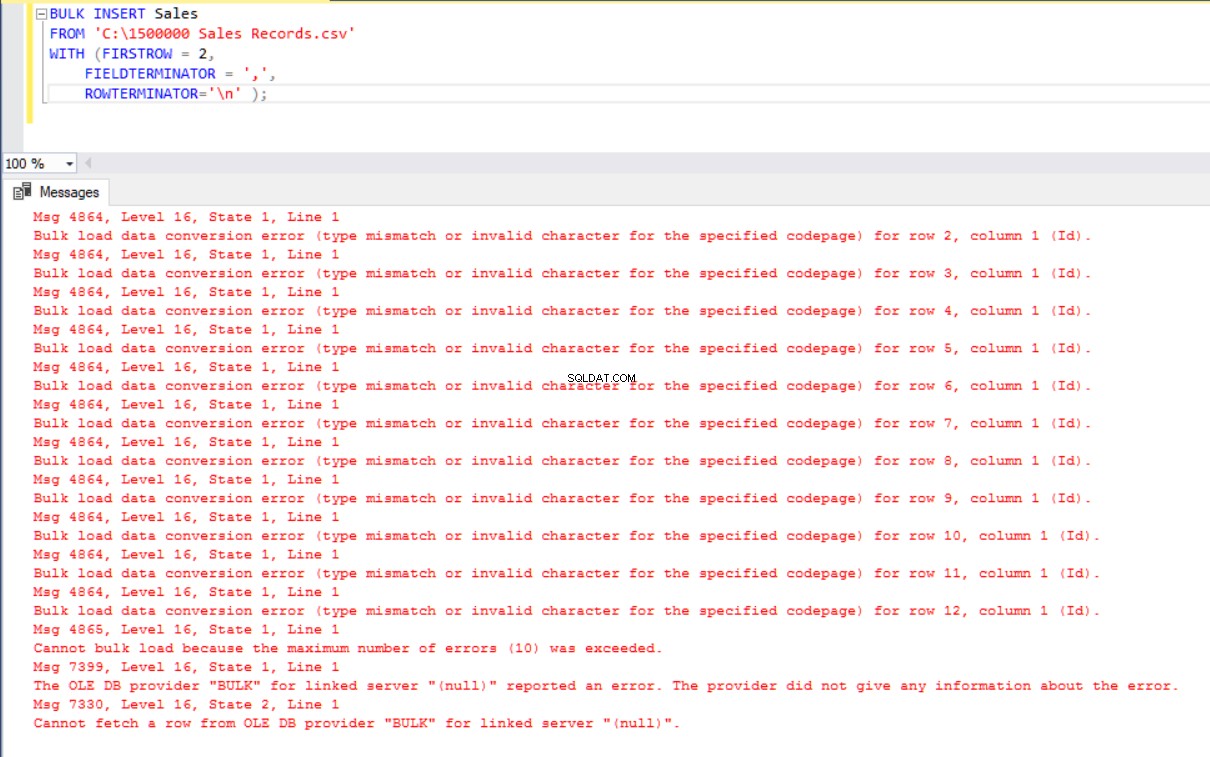
Um diesen Fehler zu umgehen, erstellen wir eine Ansicht der Sales-Tabelle mit Zuordnungsspalten zur CSV-Datei und importieren die CSV-Daten über diese Ansicht in die Sales-Tabelle.
DROP VIEW IF EXISTS VSales
GO
CREATE VIEW VSales
AS
SELECT Region ,
Country ,
ItemType ,
SalesChannel ,
OrderPriority ,
OrderDate ,
OrderID ,
ShipDate ,
UnitsSold ,
UnitPrice ,
UnitCost ,
TotalRevenue,
TotalCost,
TotalProfit from Sales
GO
BULK INSERT VSales
FROM 'C:\1500000 Sales Records.csv'
WITH ( FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Szenario-3:Wie kann man eine CSV-Datei trennen und in eine kleine Stapelgröße laden?
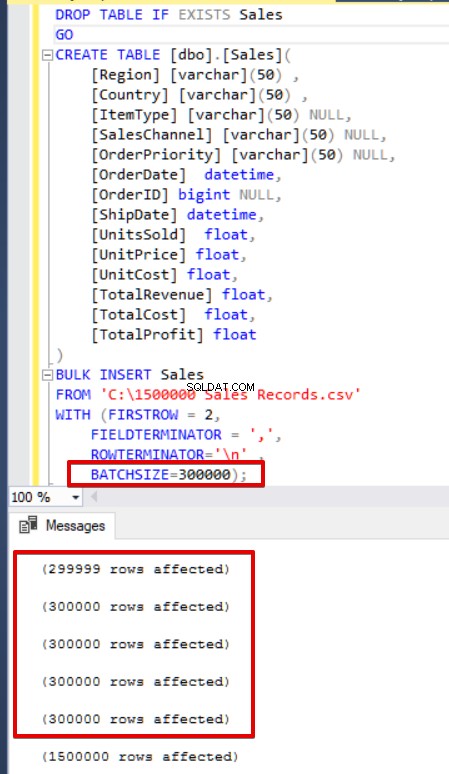
SQL Server erwirbt während des Masseneinfügungsvorgangs eine Sperre für die Zieltabelle. Wenn Sie den BATCHSIZE-Parameter nicht festlegen, öffnet SQL Server standardmäßig eine Transaktion und fügt die gesamten CSV-Daten in diese Transaktion ein. Wenn Sie jedoch den BATCHSIZE-Parameter festlegen, teilt SQL Server die CSV-Daten gemäß diesem Parameterwert. Im folgenden Beispiel teilen wir die gesamten CSV-Daten in mehrere Sätze mit jeweils 300.000 Zeilen auf. Somit werden die Daten 5 Mal importiert.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
batchsize=300000 );
Wenn Ihre Masseneinfügeanweisung den Parameter für die Stapelgröße (BATCHSIZE) nicht enthält, tritt ein Fehler auf, und SQL Server setzt den gesamten Masseneinfügungsprozess zurück. Wenn Sie dagegen den Batchgrößenparameter auf Bulk-Insert-Anweisung setzen, setzt SQL Server nur diesen geteilten Teil zurück, an dem der Fehler aufgetreten ist. Es gibt keinen optimalen oder besten Wert für diesen Parameter, da dieser Parameterwert gemäß den Anforderungen Ihres Datenbanksystems geändert werden kann.
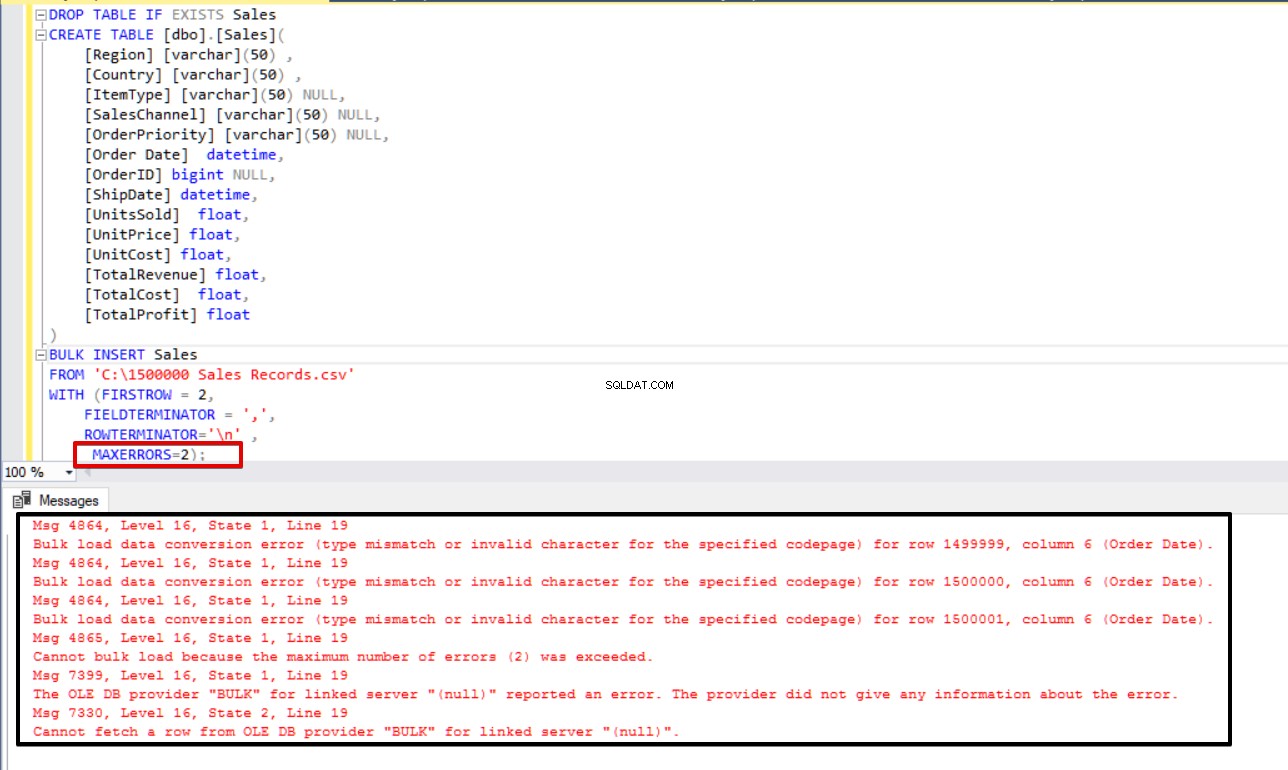
Szenario-4:So stornieren Sie die Importprozess bei Fehlermeldung?
Wenn in einigen Massenkopier-Szenarien ein Fehler auftritt, möchten wir möglicherweise entweder den Massenkopiervorgang abbrechen oder den Vorgang fortsetzen. Mit dem Parameter MAXERRORS können wir die maximale Anzahl von Fehlern angeben. Wenn der Masseneinfügungsprozess diesen maximalen Fehlerwert erreicht, wird der Massenimportvorgang abgebrochen und rückgängig gemacht. Der Standardwert für diesen Parameter ist 10.
Im folgenden Beispiel werden wir den Datentyp in 3 Zeilen der CSV-Datei absichtlich beschädigen und den MAXERRORS-Parameter auf 2 setzen. Als Ergebnis wird der gesamte Masseneinfügungsvorgang abgebrochen, da die Fehlernummer den maximalen Fehlerparameter überschreitet.

DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2);
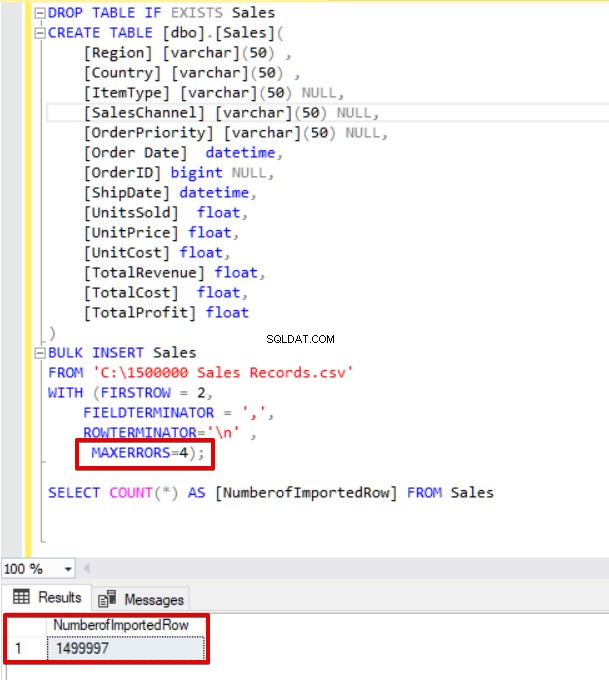
Jetzt ändern wir den Parameter max error auf 4. Als Ergebnis überspringt die Bulk-Insert-Anweisung diese Zeilen und fügt Zeilen mit der richtigen Datenstruktur ein und schließt den Bulk-Insert-Prozess ab.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=4);
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales
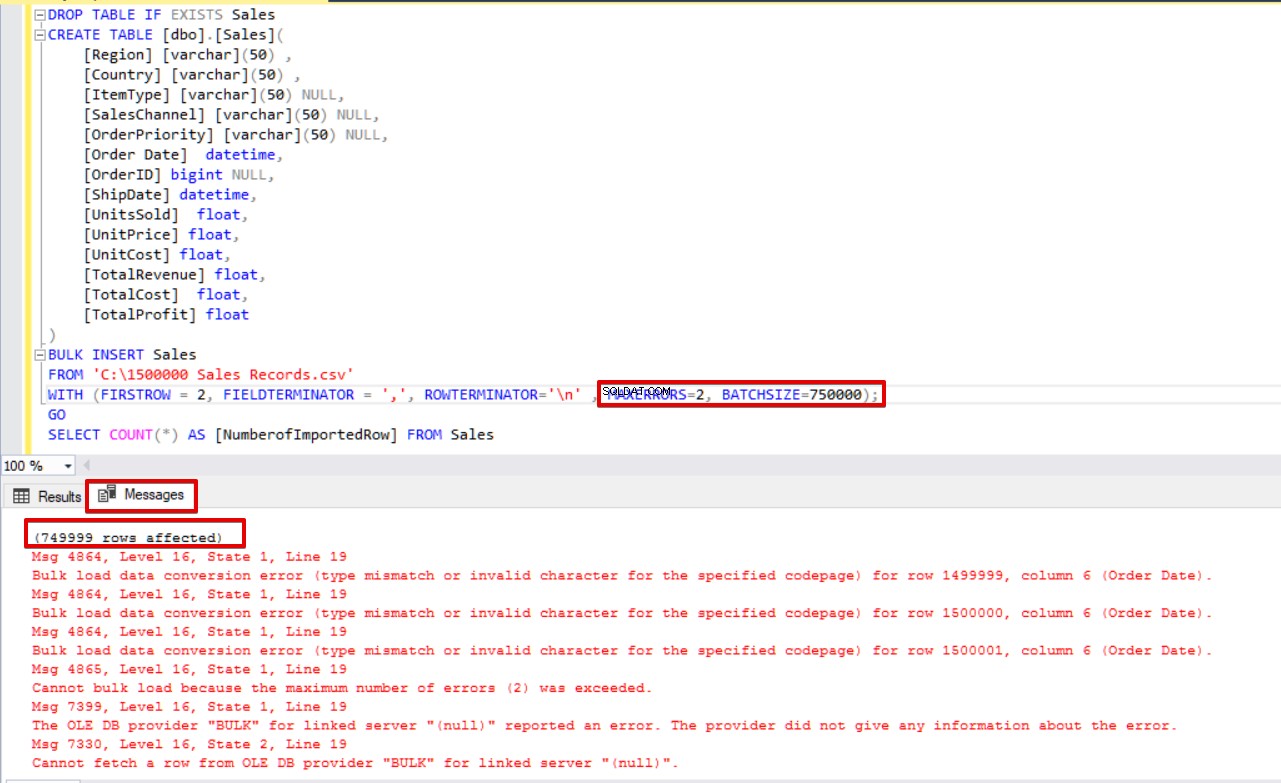
Wenn wir außerdem die Parameter für die Stapelgröße und den maximalen Fehler gleichzeitig verwenden, bricht der Massenkopiervorgang nicht den gesamten Einfügevorgang ab, sondern nur den geteilten Teil.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2,
BATCHSIZE=750000);
GO
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales
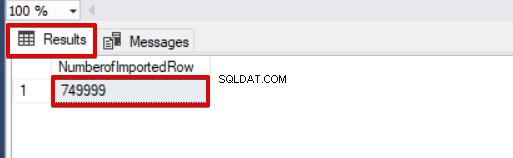
In diesem ersten Teil dieser Artikelserie haben wir die Grundlagen der Verwendung des Bulk-Insert-Vorgangs in SQL Server besprochen und mehrere Szenarien analysiert, die realitätsnah sind.
SQL Server-Masseneinfügung – Teil 2
Nützliche Links:
Massenbeilage
E für Excel – Beispiel-CSV-Dateien / Datensätze zum Testen (bis 1,5 Millionen Datensätze)
Notepad++-Download
Nützliches Tool:
dbForge Data Pump – ein SSMS-Add-In zum Füllen von SQL-Datenbanken mit externen Quelldaten und zum Migrieren von Daten zwischen Systemen.