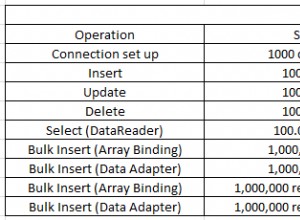
Ab einer bestimmten Anzahl von Datensätzen wird der IN Prädikat über ein SELECT wird schneller als das über eine Liste von Konstanten.
Siehe diesen Artikel in meinem Blog zum Leistungsvergleich:
Wenn die in der Abfrage verwendete Spalte im IN -Klausel wird wie folgt indiziert:
SELECT *
FROM table1
WHERE unindexed_column IN
(
SELECT indexed_column
FROM table2
)
, dann wird diese Abfrage einfach auf ein EXISTS optimiert (die nur einen Eintrag für jeden Datensatz aus table1 verwendet )
Leider MySQL ist nicht in der Lage, HASH SEMI JOIN auszuführen oder MERGE SEMI JOIN die noch effizienter sind (insbesondere wenn beide Spalten indiziert sind).