Ich weiß, dass Sie mit vielen Dingen gleichzeitig zu kämpfen haben, aber die beste Antwort löst das Problem, das ikegami schnell vorbei auf dem Weg, es in Perl zu tun:
Menschen tun auf Anwendungsebene oft viel mehr als nötig, weil sie nie lernen, die richtigen Dinge in der Datenbank zu tun (wie z /66768033/2766176">andere Frage was besser durch eine entsprechende SQL-Abfrage statt Perl beantwortet wird). Aber abgesehen davon tun das viele Leute, weil sie das Schema nicht ändern können. Soziale Heuristiken wie die angemessene Anwendung von Bier ebnen manchmal diesen Weg. Ein wenig Überzeugungsarbeit bei den Datenbankleuten zahlt sich später mehrfach aus. Und nebenbei:„Full-Stack-Entwickler“ verzichten oft auf eine ausgeklügelte Nutzung von Datenbanken.
Ich werde niemanden dazu bringen, die Database in Depth von C.J. Date zu lesen , aber es ist sehr wichtig, das Schema richtig zu machen. Mit Recht meine ich, dass es den geringsten Aufwand und die geringste Komplexität für seine Verwendung auferlegt. Die Dinge sollten einfach sein, und Sie sollten diese Dinge nicht auf Anwendungsebene neu anordnen müssen.
Sie möchten zählen, wie oft jede Antwort ausgewählt wird. Zählen ist etwas, das Datenbanken sehr gut können, also lassen Sie es die Datenbank tun.
Sie haben einige Fragen. Auf Fragen gibt es verschiedene Antworten. Umfragen gruppieren Sätze von Fragen. Personen antworten auf Umfragen, indem sie ihre Antworten den Fragen zuordnen.
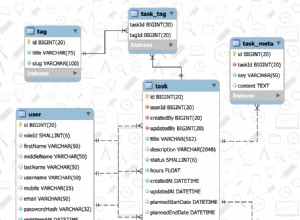
Hier ist ein einfaches Schema-Design (und irgendein Datenbanktyp wird irgendwann auftauchen und mir sagen, dass ich es nicht richtig gemacht habe, aber das ist in Ordnung). Der Trick ist, dass nichts mehrere Spalten haben muss, die nicht verwendet werden. Alles kommt in einem hübschen kleinen Paket (die "Beziehung" in "relationale Datenbank"), das leicht durch "Fremdschlüssel" (z. B. question_id, um eine Antwort auf die Frage abzubilden) mit den anderen Dingen verbunden werden kann. Antworten haben beispielsweise mehrere Zeilen für dieselbe question_id .
Wenn jemand mit den ausgefallenen Modellierungswerkzeugen hereinkommen und das Bild machen möchte, tun Sie es. Ich markiere dies als Community-Wiki.
Table: Questions
id
text
Table: Answers
id
text
question_id
Table: Surveys
id
title
Table: SurveyQuestionSet
id
survey_id
question_id
Table: Respondent
id
text
Table: Response
id
respondent_id
survey_id
question_id
answer_id
Einmal abgebildet und richtig normalisiert (lesen Sie mehr über Normalformen ). ), ist es sehr einfach, die gewünschten Daten mit SELECTs zu erhalten. Das Ideal der Normalisierung besteht einfach darin, Informationen nicht zu wiederholen oder zuzulassen, dass sie in einen inkonsistenten Zustand geraten. In diesen Formen werden viele Dinge viel einfacher zu erledigen.
Und wenn Sie solche Dinge üben möchten, den Stackoverflow Data Explorer ist ein realer Datensatz, normalisiert auf das, was ich hier präsentiert habe.
Jetzt zählen Sie einfach die Anzahl answer_id erscheint bei einer bestimmten Kombination aus Umfrage und Frage. Geschickte Verwendung von GROUP BY erledigt die ganze Arbeit für Sie. Sie müssen nicht mehr durch Zeilen iterieren und sich Dutzende von nicht verwendeten Spalten ansehen, um herauszufinden, wie sie zu zählen sind. Nicht nur das, Sie können diese Dinge auch zu Ansichten
machen , was bedeutet, dass Sie die Abfrage einmal schreiben und die Datenbank vorgibt, dass ihre Ergebnisse eine Tabelle sind. Sie können die Ansicht dann einfach abfragen (also alle JOIN s und ebenso sind versteckt), was sehr einfach ist. Auch gespeicherte Prozeduren werden oft übersehen.