Ich habe das gleiche Bedürfnis, und hier ist, wie ich Ihr Problem mit der Aktienbewegung angegangen bin (das auch zu meinem Problem wurde).
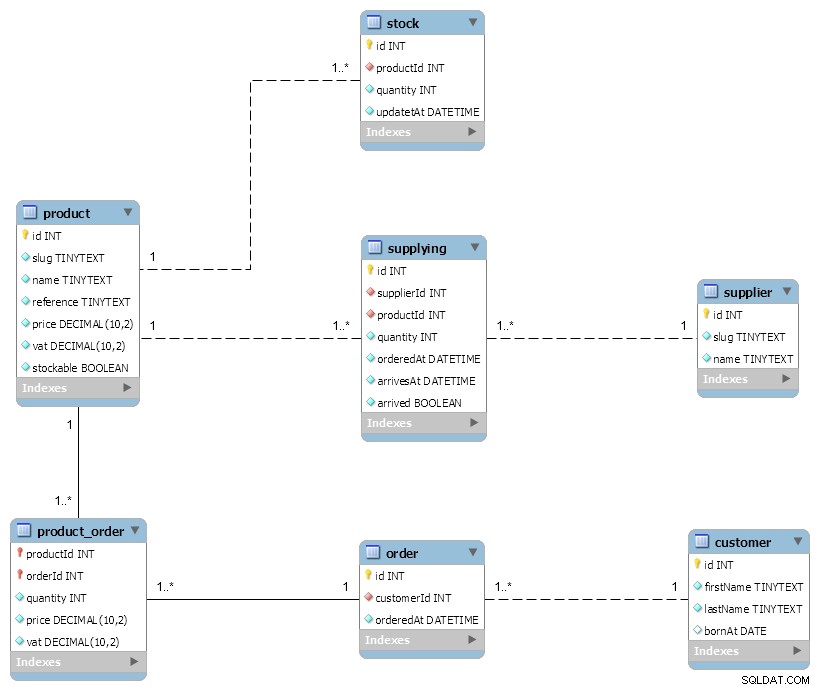
Um Lagerbewegungen (+/-) zu modellieren, habe ich meine supplying und meine order Tische. Lieferungen gelten als mein +Vorrat und meine Bestellungen als mein -Vorrat.
Wenn wir damit aufhören, könnten wir unseren tatsächlichen Bestand berechnen, der in diese SQL-Abfrage transkribiert würde:
SELECT
id,
name,
sup.length - ord.length AS 'stock'
FROM
product
# Computes the number of items arrived
INNER JOIN (
SELECT
productId,
SUM(quantity) AS 'length'
FROM
supplying
WHERE
arrived IS TRUE
GROUP BY
productId
) AS sup ON sup.productId = product.id
# Computes the number of order
INNER JOIN (
SELECT
productId,
SUM(quantity) AS 'length'
FROM
product_order
GROUP BY
productId
) AS ord ON ord.productId = product.id
Was so etwas geben würde wie:
id name stock
=========================
1 ASUS Vivobook 3
2 HP Spectre 10
3 ASUS Zenbook 0
...
Während dies Ihnen eine Tabelle sparen könnte, können Sie damit nicht skalieren, daher die Tatsache, dass die meisten Modellierungen (imho) einen Zwischen-stock verwenden Tabelle, hauptsächlich aus Leistungsgründen.
Einer der Nachteile ist die Datenduplizierung, da Sie die obige Abfrage erneut ausführen müssen, um Ihren Bestand zu aktualisieren (siehe updatedAt Spalte).
Die gute Seite ist die Client-Performance. Sie liefern schnellere Antworten über Ihre API.
Ich denke, ein weiterer Nachteil könnte sein, wenn Sie stark frequentierte Geschäfte verwalten. Sie könnten sich vorstellen, eine weitere Tabelle zu erstellen, die die Tatsache speichert, dass ein Bestand neu berechnet wird, und den Benutzer warten zu lassen, bis die Neuberechnung abgeschlossen ist (Push-Anforderung oder lange Abfrage), um zu prüfen, ob alle seine Artikel noch verfügbar sind (Stock>=Benutzernachfrage). Aber das ist ein anderer Deal...
Wie auch immer, selbst wenn die Bestandsneuberechnungsabfrage anonyme Unterabfragen verwendet, sollte sie in den meisten relativ mittelgroßen Geschäften ziemlich schnell genug sein.
Hinweis
Sie sehen in der product_order , ich habe den Preis und die Mehrwertsteuer dupliziert. Dies aus Gründen der Zuverlässigkeit:um den Preis zum Zeitpunkt des Kaufs einzufrieren und um die Gesamtsumme mit vielen Dezimalstellen neu berechnen zu können (ohne dabei Cents zu verlieren).
Hoffe, es hilft jemandem, der vorbeikommt.
Bearbeiten
In der Praxis verwende ich es mit Laravel , und ich verwende einen Konsolenbefehl , die meinen Produktbestand im Stapel berechnet (ich verwende auch einen optionalen Parameter, um nur für eine bestimmte Produkt-ID zu berechnen), sodass mein Bestand immer korrekt ist (relativ zur obigen Abfrage), und ich die Bestandstabelle nie manuell aktualisiere.