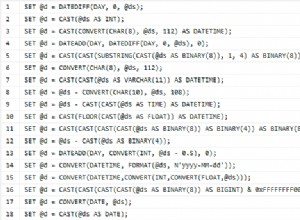
Es hört sich so an, als ob Sie sich hauptsächlich um die Leistung kümmern.
Ein paar Leute haben vorgeschlagen, in 3 Tabellen aufzuteilen (Kategorietabelle plus entweder einfache Querverweistabelle oder eine ausgefeiltere Art der Modellierung der Baumhierarchie, wie verschachtelte Menge oder materialisierter Pfad), was das erste war, was ich dachte, als ich Ihre Frage las .
Bei Indizes hat ein vollständig normalisierter Ansatz wie dieser (der zwei JOINs hinzufügt) immer noch eine "ziemlich gute" Leseleistung. Ein Problem ist, dass ein INSERT oder UPDATE für ein Ereignis jetzt auch ein oder mehrere INSERT/UPDATE/DELETEs für die Querverweistabelle enthalten kann, was bei MyISAM bedeutet, dass die Querverweistabelle gesperrt ist, und bei InnoDB, dass die Zeilen gesperrt sind. Wenn Ihre Datenbank also mit einer beträchtlichen Anzahl von Schreibvorgängen beschäftigt ist, werden Sie größere Konfliktprobleme haben, als wenn nur die Ereigniszeilen gesperrt wären.
Ich persönlich würde diesen vollständig normalisierten Ansatz vor der Optimierung ausprobieren. Aber ich gehe davon aus, dass Sie wissen, was Sie tun, dass Ihre Annahmen richtig sind (Kategorien ändern sich nie) und Sie ein Nutzungsmuster haben (viele Schreibvorgänge), das eine weniger normalisierte, flache Struktur erfordert. Das ist völlig in Ordnung und Teil dessen, worum es bei NoSQL geht.
SET vs. "viele Spalten"
Zu Ihrer eigentlichen Frage „SET vs. viele Kolumnen“ kann ich sagen, dass ich mit zwei Unternehmen mit intelligenten Ingenieuren zusammengearbeitet habe (deren Produkte CRM-Webanwendungen waren … eines war eigentlich Veranstaltungsmanagement), und beide verwendet den "viele Spalten"-Ansatz für diese Art von statischen Satzdaten.
Mein Rat wäre, über alle Abfragen nachzudenken, die Sie in dieser Tabelle durchführen werden (gewichtet nach ihrer Häufigkeit) und wie die Indizes funktionieren würden.
Erstens benötigen Sie bei dem Ansatz "viele Spalten" Indizes für jede dieser Spalten, damit Sie SELECT FROM events WHERE CategoryX = TRUE ausführen können . Mit den Indizes ist das eine superschnelle Abfrage.
Im Gegensatz zu SET müssen Sie für diese Abfrage bitweises AND (&), LIKE oder FIND_IN_SET() verwenden. Das bedeutet, dass die Abfrage keinen Index verwenden kann und alle Zeilen linear durchsuchen muss (Sie können dies mit EXPLAIN überprüfen). Langsame Abfrage!
Das ist der Hauptgrund, warum SET eine schlechte Idee ist – sein Index ist nur nützlich, wenn Sie nach genauen Kategoriengruppen auswählen. SET funktioniert hervorragend, wenn Sie Kategorien nach Ereignis auswählen, aber nicht umgekehrt.
Das Hauptproblem bei dem weniger normalisierten Ansatz „viele Spalten“ (im Vergleich zu vollständig normalisiert) besteht darin, dass er nicht skaliert. Wenn Sie 5 Kategorien haben und sie sich nie ändern, gut, aber wenn Sie 500 haben und sie ändern, ist das ein großes Problem. In Ihrem Szenario mit etwa 30, die sich nie ändern, besteht das Hauptproblem darin, dass es einen Index für jede Spalte gibt. Wenn Sie also häufig schreiben, werden diese Abfragen aufgrund der Anzahl der zu aktualisierenden Indizes langsamer. Wenn Sie sich für diesen Ansatz entscheiden, sollten Sie das MySQL-Protokoll für langsame Abfragen überprüfen, um sicherzustellen, dass es keine Ausreißer für langsame Abfragen aufgrund von Konflikten zu Stoßzeiten gibt.
Wenn es sich in Ihrem Fall um eine typische leselastige Webanwendung handelt, halte ich es für wahrscheinlich vernünftig, den Ansatz „viele Spalten“ zu wählen (wie dies bei den beiden CRM-Produkten aus demselben Grund der Fall war). Es ist auf jeden Fall schneller als SET für diese SELECT-Abfrage.
TL;DR Verwenden Sie SET nicht, da die Abfrage "Ereignisse nach Kategorie auswählen" langsam ist.