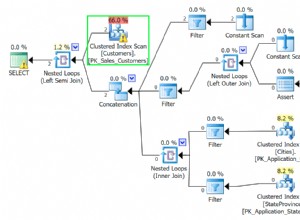
Ihre Daten sind schlecht clustered .
InnoDB speichert Zeilen mit "nahen" PKs physisch nahe beieinander. Da Ihre untergeordneten Tabellen Ersatz-PKs verwenden, werden ihre Zeilen nach dem Zufallsprinzip gespeichert. Wenn es an der Zeit ist, Berechnungen für die angegebene Zeile in der "Master"-Tabelle durchzuführen, muss DBMS überall hinspringen, um die zugehörigen Zeilen aus den untergeordneten Tabellen zu sammeln.
Versuchen Sie anstelle von Ersatzschlüsseln, "natürlichere" Schlüssel zu verwenden, mit dem PK des übergeordneten Schlüssels in der Vorderkante, ähnlich wie hier:
score_adjustments:
entry_id: INT(11), FOREIGN KEY (entries.id)
created: DATETIME
amount: INT(4)
PRIMARY KEY (entry_id, created)
rating_adjustments:
entry_id: INT(11), FOREIGN KEY (entries.id)
rating_no: INT(11)
rating: DOUBLE
PRIMARY KEY (entry_id, rating_no)
HINWEIS:Dies setzt voraus, dass created Die Auflösung von ist fein genug und die rating_no wurde hinzugefügt, um mehrere Bewertungen pro entry_id zu ermöglichen . Dies ist nur ein Beispiel - Sie können die PKs nach Ihren Bedürfnissen variieren.
Dadurch werden Zeilen "erzwungen", die zur selben entry_id gehören physisch nahe beieinander gespeichert werden, sodass eine SUM oder AVG nur durch einen Bereichsscan auf dem PK/Clustering-Schlüssel und mit sehr wenigen I/Os berechnet werden kann.
Alternativ (z. B. wenn Sie MyISAM verwenden, das kein Clustering unterstützt), Abdeckung die Abfrage mit Indizes, damit die untergeordneten Tabellen während der Abfrage überhaupt nicht berührt werden.
Darüber hinaus könnten Sie Ihr Design denormalisieren und die aktuellen Ergebnisse in der übergeordneten Tabelle zwischenspeichern:
- Speichern Sie SUM(score_adjustments.amount) als physisches Feld und passen Sie es jedes Mal über Trigger an, wenn eine Zeile aus
score_adjustmentseingefügt, aktualisiert oder gelöscht wird . - Speichern Sie SUM(rating_adjustments.rating) als "S" und COUNT(rating_adjustments.rating) als "C". Wenn eine Zeile zu
rating_adjustmentshinzugefügt wird , fügen Sie es zu S hinzu und erhöhen Sie C. Berechnen Sie S/C zur Laufzeit, um den Durchschnitt zu erhalten. Behandeln Sie Aktualisierungen und Löschungen ähnlich.