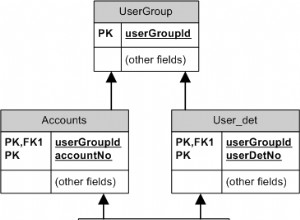
Ob Sie eine Datenbank verwenden oder nicht, hängt davon ab, wie lange Sie diese Daten aufbewahren und erweitern möchten. Es ist viel, viel einfacher, einen ganzen Solr-Index zu beschädigen (und alle Ihre Daten zu verlieren), als eine ganze Datenbank zu beschädigen. Außerdem bietet Solr keine große Unterstützung für das Ändern eines Schemas, ohne mit einem neuen Index zu beginnen. Sie könnten beispielsweise problemlos ein weiteres Feld hinzufügen, aber Sie könnten den Namen oder Typ eines Felds nicht ändern, ohne Ihren Index zu löschen.
Wenn Sie sich für eine DB entscheiden, können Sie Solr mit DataImportHandler . Für Ihr Schema sollte dies ziemlich einfach sein, aber das kann schnell schmerzhaft werden, wenn Ihre Datenbank komplexer wird. Ich denke, es ist ein Vorteil, die Hibernate-Objekte zu verwenden, die Sie bereits eingerichtet haben, und sie einfach mit Solrj einzufügen. Der andere Schmerzpunkt bei DataImportHandler ist, dass es vollständig über http gesteuert wird. Sie müssen also separate Cron-Jobs (oder einen anderen Code) verwalten, um die Zeitplanung mit wget zu handhaben oder curl .