„Waitstats hilft uns, leistungsbezogene Zähler zu identifizieren. Warteinformationen allein reichen jedoch nicht aus, um Leistungsprobleme genau zu diagnostizieren. Die Warteschlangenkomponente unserer Methodik stammt von Performance Monitor-Zählern, die einen Überblick über die Systemleistung aus Ressourcensicht bieten.“Tom Davidson, Opening Microsoft's Performance-Tuning Toolbox
SQL Server Pro Magazine, Dezember 2003
Seit Tom Davidson 2006 den obigen Artikel sowie das bekannte Whitepaper „SQL Server 2005 Waits and Queues“ veröffentlichte, wird Waits and Queues als Methode zur Leistungsoptimierung von SQL Server verwendet. In Kombination mit Ressourcenmetriken können Waits wertvoll sein Bewertung bestimmter Leistungsmerkmale der Workload und Unterstützung bei der Lenkung von Optimierungsbemühungen. Waits-Daten werden von vielen SQL Server-Leistungsüberwachungslösungen an die Oberfläche gebracht, und ich war von Anfang an ein Befürworter der Optimierung mithilfe dieser Methode. Der Ansatz hatte Einfluss auf das Design des SQL Sentry-Leistungs-Dashboards, das Wartezeiten flankiert von Warteschlangen (wichtige Ressourcenmetriken) darstellt, um einen umfassenden Überblick über die Serverleistung zu liefern.
Einige scheinen jedoch Davidsons Argument in Bezug auf die Bedeutung von Ressourcen verfehlt zu haben und verlassen sich fast ausschließlich auf Wartezeiten, um ein Bild der Abfrageleistung und des Systemzustands zu erhalten. Wartestatistiken kommen direkt von der SQL Server-Engine und sind einfach zu nutzen und zu kategorisieren. Wartende Abfragen bedeuten wartende Anwendungen und Benutzer, und niemand wartet gerne! Es ist einfacher, Tuning mit Wartezeiten als die einzige Lösung für schnellere Abfragen und Anwendungen zu predigen, als die ganze Geschichte zu erzählen, was aufwändiger ist.
Leider kann ein auf Wartezeiten fokussierter Ansatz zum Ausschluss der Ressourcenanalyse in die Irre führen und im schlimmsten Fall dazu führen, dass Sie im Blindflug sind. Die SentryOne-Teammitglieder Kevin Kline und Steve Wright haben dies bereits hier und hier angesprochen. In diesem Beitrag werde ich tiefer in einige aktuelle Forschungsergebnisse eintauchen, die von Query Store ermöglicht wurden und ein neues Licht darauf geworfen haben, wie mangelhaft Waits-Exclusive-Tuning wirklich sein kann.
Die häufigsten Suchanfragen, die keine waren
Kürzlich kontaktierte mich ein SentryOne-Kunde wegen Leistungsbedenken mit seiner SentryOne-Datenbank. Das Herzstück jeder SentryOne-Überwachungsumgebung ist eine einzelne SQL Server-Datenbank, und dieser Kunde überwachte etwa 600 Server mit unserer Software. In dieser Größenordnung ist es nicht ungewöhnlich, dass gelegentlich Probleme mit der Abfrageleistung auftreten und ein wenig optimiert wird, und einige angeblich neue Abfragen in der Workload waren die Quelle ihrer Bedenken.
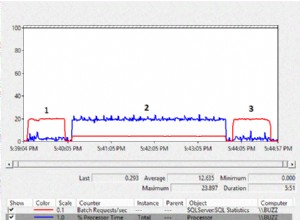
Ich nahm an einer Bildschirmfreigabesitzung teil, um einen Blick darauf zu werfen, und der Kunde präsentierte mir zuerst Daten von einem anderen System, das auch die SentryOne-Datenbank überwachte. Das System verwendete einen Waits-Ansatz auf Abfrageebene und zeigte, dass zwei gespeicherte Prozeduren für etwa die Hälfte der Waits auf dem SQL Sentry-Datenbankserver verantwortlich sind. Das war ungewöhnlich, da diese beiden Prozeduren immer sehr schnell ablaufen und noch nie auf ein echtes Performance-Problem in unserer Datenbank hindeuteten. Verwirrt wechselte ich zu SQL Sentry, um zu sehen, was es uns zeigen würde, und war überrascht zu sehen, dass im gleichen Zeitraum die Prozedur Nr. 1 im anderen System Nr. 6, Nr. 7 und Nr. 8 in Bezug auf die Gesamtdauer, CPU, war bzw. logische Lesevorgänge:
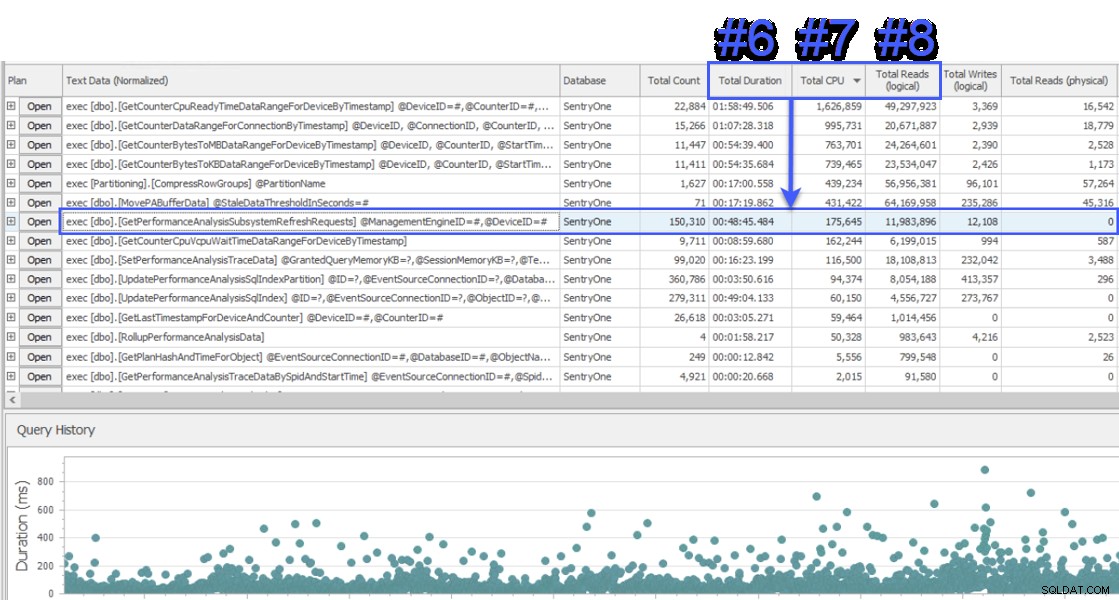 Ansicht „Top SQL“ von SQL Sentry
Ansicht „Top SQL“ von SQL Sentry
Aus Sicht des Ressourcenverbrauchs bedeutete dies, dass die Abfragen darüber 75 % der Gesamtdauer, 87 % der gesamten CPU und 88 % der logischen Lesevorgänge ausmachten. Darüber hinaus war das Verfahren Nr. 2 im anderen System nicht einmal unter den Top 30 in SQL Sentry, in keiner Weise! Diese beiden Suchanfragen waren weit entfernt von den Top 2 und den Suchanfragen, die den größten Teil der tatsächlichen ausmachten Verbrauch auf dem System stark unterrepräsentiert waren.
Ich war immer davon ausgegangen, dass es eine stärkere Korrelation zwischen den Top-Kellnern und den Top-Ressourcenverbrauchern gibt, hatte aber noch nie einen direkten Vergleich auf Abfrageebene wie diesen durchgeführt, daher waren diese Ergebnisse gelinde gesagt überraschend. Mein Interesse war geweckt und ich beschloss, nachzuforschen, um festzustellen, ob diese Situation typisch oder ungewöhnlich war.
Query Store 2017 zur Rettung
In SQL Server 2017 und höher erfasst der Abfragespeicher zusätzlich zum Verbrauch von Abfrageressourcen Wartezeiten auf Abfrageebene. Erin Stellato hat hier einen großartigen Beitrag zu Query Store Waits geschrieben. Es ist weniger Overhead und genauer als das Abfragen von Waits DMVs jede Sekunde in der Hoffnung, Abfragen während der Übertragung abzufangen, der Standardansatz, der von anderen Tools verwendet wird, einschließlich des oben genannten.
SQL Sentry hat aufgrund dieser Bedenken hinsichtlich Overhead und Genauigkeit immer Wartezeiten erfasst, jedoch auf Ebene der SQL Server-Instanz. Detaillierte Abfragewartezeiten sind auf Anfrage über den integrierten Plan-Explorer verfügbar, und wir evaluieren die Erweiterung der Wartezeiten auf Instanzebene mit Daten auf Abfrageebene aus dem Abfragespeicher, sofern verfügbar.
Für dieses Unterfangen habe ich die Hilfe des SentryOne Product Advisory Council in Anspruch genommen, einer Gruppe von SentryOne-Kunden, -Partnern und -Freunden aus der Branche, die an einem privaten Slack-Kanal teilnehmen. Ich habe dieses Skript geteilt, um die Daten der letzten 8 Stunden aus dem Query Store zu übertragen, und habe Ergebnisse für 11 Produktionsserver in mehreren Branchen zurückerhalten, darunter Finanzdienstleistungen, Spieleveröffentlichung, Fitness-Tracking und Versicherungen.
Wartekategorien des Abfragespeichers sind hier dokumentiert. Alle Kategorien wurden in die Analyse einbezogen, außer diesen, die aus den genannten Gründen entfernt wurden:
- Parallelität – Es kann die Wartezeit einer Abfrage weit über ihre tatsächliche Dauer hinaus in die Höhe treiben, da mehrere Threads die damit verbundenen Wartezeiten abwerfen und die Korrelation mit der Dauer und anderen Metriken verwirren können. Obwohl die CXPACKET/CXCONSUMER-Aufteilung hilfreich ist, bedeutet CXPACKET weiterhin nur, dass Sie Parallelität haben und nicht unbedingt problematisch oder umsetzbar ist.
- Prozessor – Die Signalwartezeit kann hilfreich sein, um CPU-Engpässe durch Korrelation mit Ressourcenwartezeiten zu ermitteln, aber Query Store enthält derzeit nur SOS_SCHEDULER_YIELD in dieser Kategorie, was keine Wartezeit im herkömmlichen Sinne ist, wie hier behandelt wird. Es eignet sich nicht für einen einfachen Vergleich oder eine Korrelation, insbesondere wenn sich SQL Server auf einer VM befindet, die sich auf einem überbelegten Host befindet. Beispielsweise betrugen die CPU-Wartezeiten im Abfragespeicher auf einem Server 227 % der gesamten CPU-Zeit für alle Abfragen ohne Parallelität, was nicht möglich sein sollte.
- Benutzerwartezeit undLeerlauf – Diese Kategorien bestehen ausschließlich aus Timer- und Warteschlangenwartezeiten und wurden aus dem gleichen Grund ausgeschlossen, aus dem man diese Arten immer ausschließen sollte – sie sind harmlos und verursachen nur Lärm.
Übrigens habe ich kürzlich mit dem Vater des Abfragespeichers, Conor Cunningham, über die Wahrscheinlichkeit zukünftiger Änderungen an den Wartetypen und -kategorien des Abfragespeichers gesprochen, und er sagte, dass dies durchaus möglich sei … also müssen wir ein Auge darauf haben es.
Analyseergebnisse TL;DR
Nach ausführlicher Analyse habe ich bestätigt, dass die auf dem Kundensystem beobachteten Ergebnisse nicht anomal, sondern eher alltäglich sind. Wenn Sie also auf ein auf Wartezeiten ausgerichtetes Tool zum Überwachen und Optimieren Ihrer Workloads angewiesen sind, ist es sehr wahrscheinlich, dass Sie sich auf die falschen Abfragen konzentrieren und diejenigen übersehen, die für die meisten verantwortlich sind der Abfragedauer und des Ressourcenverbrauchs auf einem System. Da sich CPU- und IO-Verbrauch direkt in Ausgaben für Serverhardware und Cloud umwandeln, ist dies erheblich.
Die meisten Abfragen warten nicht
Eine interessante und wichtige Erkenntnis, auf die ich zuerst eingehen werde, ist, dass die meisten Abfragen überhaupt keine Wartezeiten erzeugen. Von insgesamt 56.438 Abfragen auf allen Servern hatten nur 9.781 (17 %) Wartezeiten und nur 8.092 (14 %) Wartezeiten von signifikanten Typen. Wenn Sie nur Wartezeiten verwenden, um zu bestimmen, welche Abfragen optimiert werden sollen, werden Ihnen die meisten Abfragen in der Arbeitslast entgehen.
Korrelieren von Wartezeiten und Ressourcen
Ich habe analysiert, wie Wartezeiten mit dem Ressourcenverbrauch zusammenhängen, indem ich alle Abfragen auf jedem System nach Wartezeiten und Ressourcen eingestuft und die Ränge verwendet habe, um eine Spearman-Korrelation zu berechnen. Letztendlich versuchen wir festzustellen, ob die Top-Kellner auch die Top-Konsumenten sind. Wie sich herausstellt, tun sie das nicht.
Tabelle 1 zeigt die farbskalierten Korrelationskoeffizienten für durchschnittliche Abfragewartezeit Zeit zu anderen Maßen – ein Wert von 1,00 (dunkelblau) steht für Daten, die perfekt korreliert sind. Wie Sie sehen können, ist die Korrelation mit Wartezeiten und anderen Messwerten auf den meisten Servern nicht stark, und für einen Server gibt es eine negative Korrelation mit den meisten Messwerten.
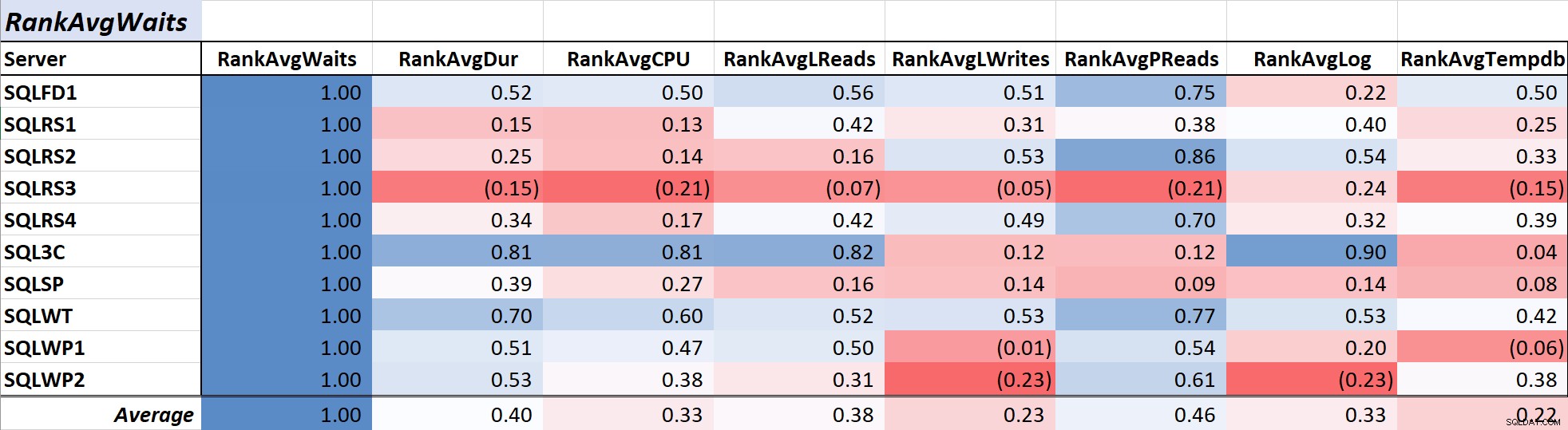 Tabelle 1:Korrelation mit der durchschnittlichen Wartezeit für Abfragen (ms)
Tabelle 1:Korrelation mit der durchschnittlichen Wartezeit für Abfragen (ms)
Die Abfragedauer ist oft ein Hauptanliegen von DBAs und Entwicklern, da sie sich direkt auf die Benutzererfahrung auswirkt, und Tabelle 2 zeigt die Korrelation zwischen der durchschnittlichen Abfragedauer und die anderen Maßnahmen. Die Korrelation mit der Dauer und den beiden primären Ressourcenmesswerten, CPU und logische Lesevorgänge, ist mit 0,97 bzw. 0,75 ziemlich stark.
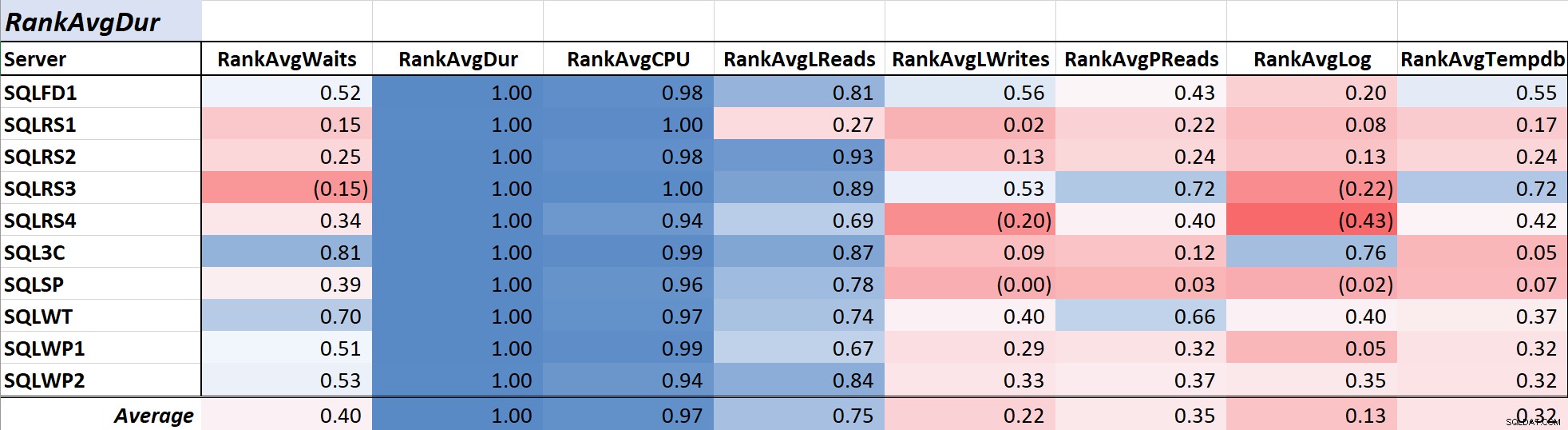 Tabelle 2:Korrelation mit der durchschnittlichen Abfragedauer (ms)
Tabelle 2:Korrelation mit der durchschnittlichen Abfragedauer (ms)
Da logische Lesevorgänge immer CPU verwenden und wie die Dauer die CPU in Millisekunden gemessen wird, ist diese Beziehung nicht überraschend. Die Ergebnisse stimmen mit der Idee überein, dass, wenn Sie möchten, dass Ihre Datenbankanwendungen so schnell wie möglich ausgeführt werden, die Konzentration auf die Reduzierung der Abfrage-CPU und der logischen Lesevorgänge effektiver ist, um die Dauer zu reduzieren, als die Verwendung von Wartezeiten allein. Glücklicherweise ist dies über ein besseres Abfragedesign, eine bessere Indizierung usw. in der Regel einfacher, als die Wartezeit für Abfragen direkt zu reduzieren. Kollege Aaron Bertrand präsentiert hier effektiv einige der Vorbehalte beim Tuning mit Waits.
% der Gesamtwartezeit
Als Nächstes habe ich untersucht, ob die Abfragen mit der höchsten Wartezeit tendenziell den größten Ressourcenverbrauch ausmachen. Wir möchten feststellen, ob das, was wir auf dem Kundensystem gesehen haben, atypisch ist, wo die zwei am häufigsten wartenden Abfragen einen relativ kleinen Prozentsatz des gesamten Ressourcenverbrauchs darstellten.
Diagramm 1 Unten sehen Sie den Prozentsatz der gesamten CPU und logischen Lesevorgänge für jeden Server, die durch die Abfragen entfallen, die 75 % der gesamten Wartezeit darstellen. Nur ein Server hatte eine Ressource von mehr als 75 % – liest auf SQLRS3. Im Übrigen verbrauchten die Abfragen, die für 75 % der Wartezeit verantwortlich sind, weniger als 75 % der Ressourcen – oft weit weniger. Dies spiegelt das wider, was wir auf dem Kundensystem gesehen haben, und stimmt mit der Korrelationsanalyse überein.
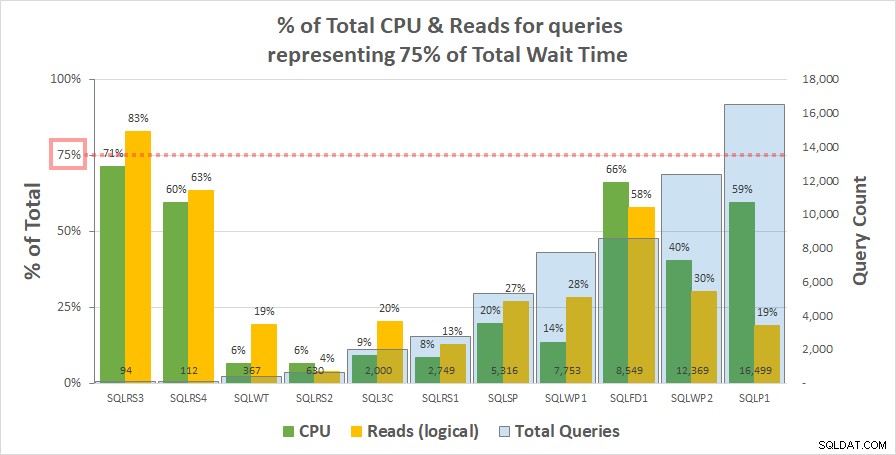 Diagramm 1
Diagramm 1
Beachten Sie, dass eine Beziehung zur Gesamtzahl der Abfragen in der Workload zu bestehen scheint. Dies wird durch die hellblaue Säulenreihe auf der sekundären y-Achse dargestellt und das Diagramm wird nach dieser Reihe aufsteigend sortiert. Die beiden Server mit den höchsten Ressourcenmaßen bei 75 % der Wartezeiten hatten auch die wenigsten Abfragen (SQLRS3 und SQLRS4). Je kleiner die Arbeitslast eingestellt ist, desto größer ist der potenzielle Einfluss einer kleinen Anzahl von Abfragen, und tatsächlich machten auf beiden Servern nur zwei Abfragen die meisten Wartezeiten und Ressourcen aus. Eine Möglichkeit, dies zu betrachten, ist, dass Wartezeiten am besten dazu beitragen, Ihre schwersten Abfragen zu identifizieren, wenn Sie sie am wenigsten benötigen.
Wartezeit und Abfragedauer
Schließlich habe ich den Prozentsatz der Gesamtwartezeit zur Gesamtabfragedauer auf jedem System ausgewertet. Tabelle 3 hat Spalten für:
- Gesamtabfragedauer in ms
- Gesamtwartezeit ms – roh
- Gesamtwartezeit ms – ohne Parallelität, Leerlauf und Benutzerwartezeiten (Rev1)
- Gesamtwartezeit ms – ohne Parallelität, Leerlauf, Benutzerwartezeiten und CPU (Rev2)
- Der Prozentsatz der Dauer für die 3 Wartezeitspalten mit Datenbalken
- Gesamtanzahl eindeutiger Suchanfragen, mit Datenbalken
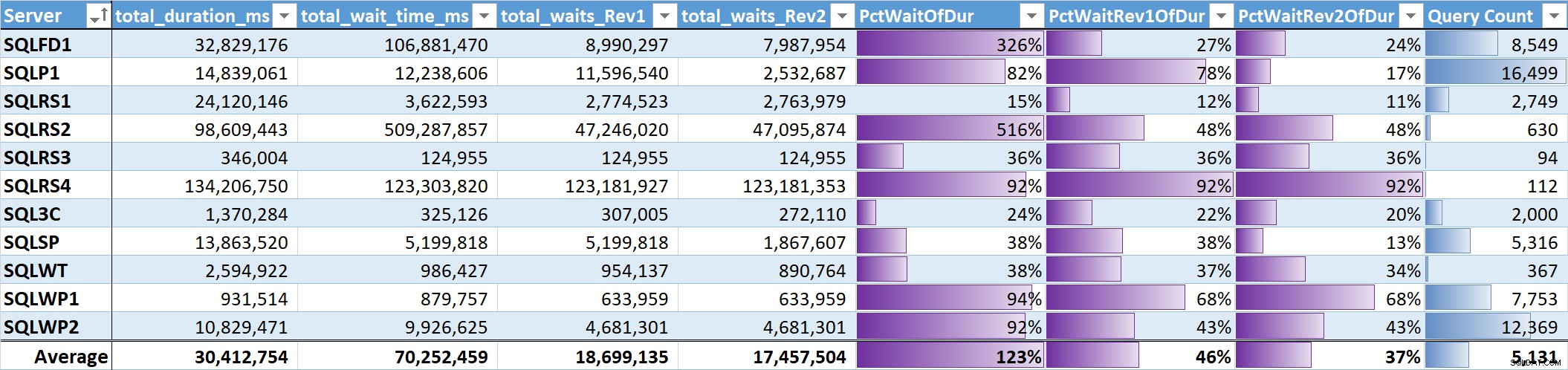 Tabelle 3
Tabelle 3
Der ungewichtete Durchschnitt für die sinnvollen Wartezeiten (Rev2) über alle Systeme hinweg beträgt 37 % der gesamten Abfragedauer. Auf fünf der Systeme lag sie unter 25 % und nur auf zwei Systemen über 50 %. Auf dem System mit 92 % Wartezeit (SQLRS4), einem mit den wenigsten Abfragen, machten zwei Abfragen 99 % der Wartezeiten, 97 % der Dauer, 84 % der CPU und 86 % der Lesevorgänge aus.
Obwohl die Wartezeit auf bestimmten Systemen einen erheblichen Teil der Abfragelaufzeit ausmachen kann und es intuitiv erscheint, dass sich die Abfragedauer verringert, wenn Sie die Wartezeit verkürzen, haben wir gesehen, dass Wartezeit und Dauer nur schwach korreliert sind. Es ist unwahrscheinlich, dass es so einfach ist, und meine eigene Erfahrung bestätigt dies. Hier ist weitere Forschung erforderlich.
Umfassendes Tuning mit Plan Explorer und SQL Sentry
Wie dieses ausgezeichnete SQLskills-Whitepaper häufig andeutet, sind die Ursache für lange Wartezeiten oft nicht optimierte Abfragen und Indizes. Der kostenlose SentryOne Plan Explorer wurde speziell entwickelt, um den Ressourcenverbrauch durch effizientes Abfragetuning mit seinem Indexanalysemodul und vielen anderen innovativen Funktionen zu reduzieren. SQL Sentry integriert Plan Explorer direkt in die Top SQL-, Blocking- und Deadlocks-Module, sodass Sie problematische Abfragen automatisch an einem Ort erfassen und optimieren können. Sie können ganz einfach einen Bereich von Interesse in den historischen Warte-, CPU- oder IO-Diagrammen des SQL Sentry-Dashboards auswählen und zur Top-SQL-Ansicht springen, um die ressourcenintensivsten Abfragen während dieser Zeit zu finden. Dann können Sie mit einem einzigen Klick eine Abfrage im Plan-Explorer öffnen und detaillierte Wartezeiten auf Abfrageebene abrufen und Ressourcen nach Bedarf. Ich glaube nicht, dass es eine bessere Verkörperung der vollständigen Waits- und Queues-Tuning-Methodik als diese gibt.
 Diagramm „Wartezeiten“ des SQL Sentry-Dashboards
Diagramm „Wartezeiten“ des SQL Sentry-Dashboards
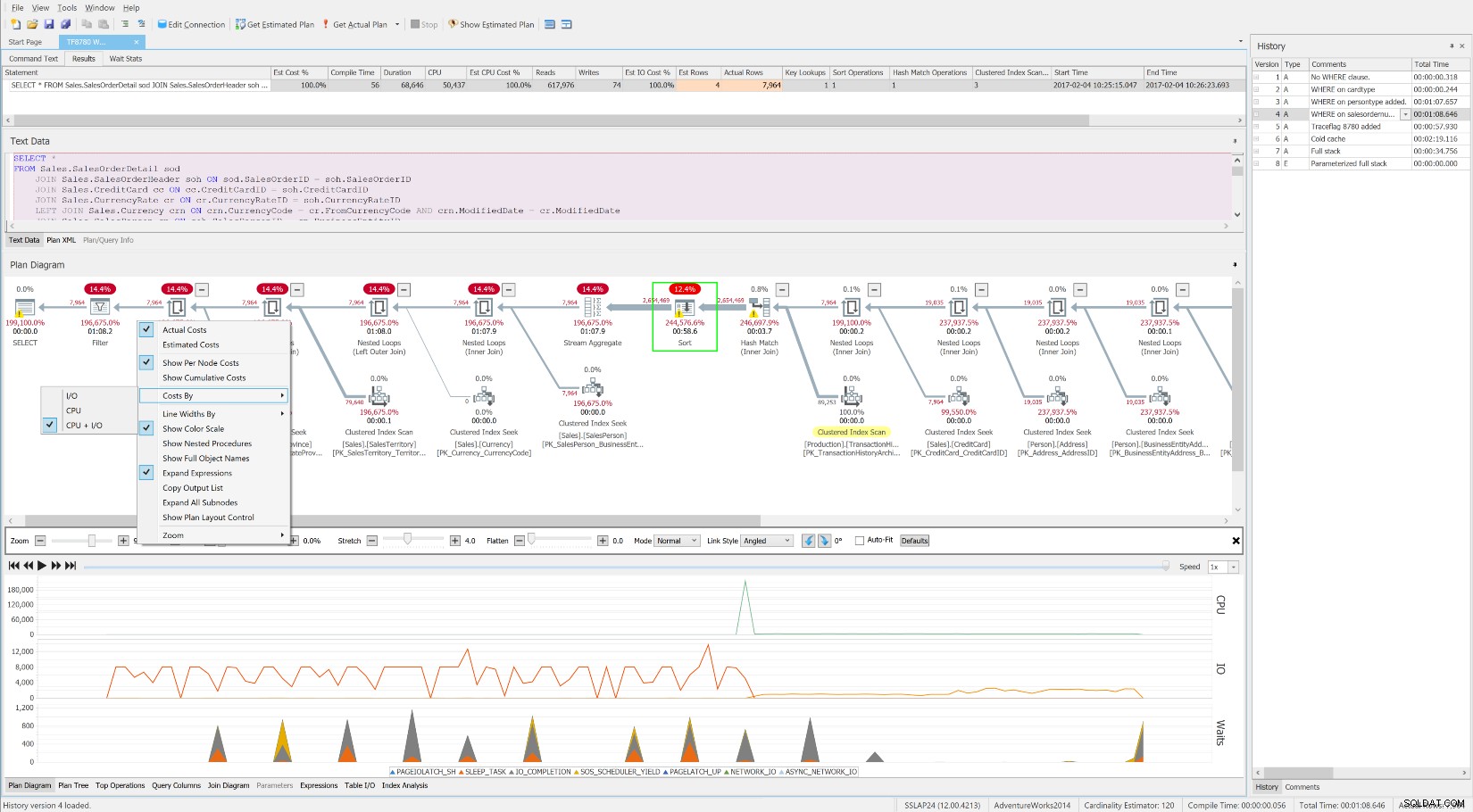 Der kostenlose SentryOne-Plan-Explorer zeigt die Wartezeiten im Laufe der Zeit zusammen mit der Betriebsebene an Kosten und Ressourcen
Der kostenlose SentryOne-Plan-Explorer zeigt die Wartezeiten im Laufe der Zeit zusammen mit der Betriebsebene an Kosten und Ressourcen
Schlussfolgerung
Das Optimieren mit Wartezeiten und Warteschlangen ist für die Leistung von SQL Server heute genauso anwendbar wie damals im Jahr 2006. Die Konzentration auf Wartezeiten bis zum Ausschluss von Ressourcen ist jedoch gefährlich, da aus den Daten klar hervorgeht, dass dies zu allgemein nicht optimierten und kostenineffiziente Systeme. Wenn es um Hardwareressourcen und Cloud-Ausgaben geht, zahlen Sie letztendlich für Rechen- und E/A-Ressourcen und nicht für Wartezeiten, daher ist es sinnvoll, direkt für den Verbrauch zu optimieren. Wenn der Ressourcenverbrauch und die damit verbundenen Konflikte verringert werden, ergibt sich meiner Erfahrung nach automatisch eine kürzere Wartezeit.
Bestätigung
Ich möchte Fred Frost, Lead Data Scientist bei SentryOne, für seinen wertvollen Beitrag und seine kritische Überprüfung dieser Analyse danken.