Ich weiß nichts über die Interna von Microsoft SQL Server, aber ich kann für MySQL antworten, das Sie für Ihre Frage markiert haben. Die Details können für andere Implementierungen abweichen.
F1. Richtig, für den Clustered-Index wird kein zusätzlicher Speicherplatz benötigt.
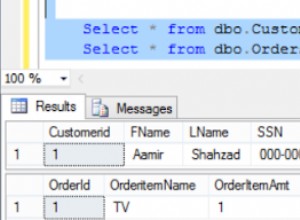
Was passiert, wenn Sie den gruppierten Index löschen? Die InnoDB-Engine von MySQL verwendet immer den Primärschlüssel (oder den ersten eindeutigen Nicht-Null-Schlüssel) als Clustered-Index. Wenn Sie eine Tabelle ohne Primärschlüssel definieren oder den Primärschlüssel einer vorhandenen Tabelle löschen, InnoDB generiert einen internen künstlichen Schlüssel für den Clustered-Index . Dieser interne Schlüssel hat keine logische Spalte, um darauf zu verweisen.
Q2. Die Reihenfolge der Zeilen, die von einer Abfrage zurückgegeben werden, die einen nicht gruppierten Index verwendet, ist nicht garantiert. In der Praxis ist dies die Reihenfolge, in der auf die Zeilen zugegriffen wurde. Wenn Zeilen in einer bestimmten Reihenfolge zurückgegeben werden müssen, sollten Sie ORDER BY verwenden in Ihrer Anfrage. Wenn der Optimierer daraus schließen kann, dass Ihre gewünschte Reihenfolge mit der Reihenfolge übereinstimmt, in der er auf Zeilen zugreift (Indexreihenfolge, ob nach geclustertem oder nicht geclustertem Index), kann er den Sortierschritt überspringen.
Q3. Der nicht gruppierte InnoDB-Index hat keinen Zeiger auf die entsprechende Zeile in einem Blatt des Indexes, er hat den Wert des Primärschlüssels. Eine Suche in einem nicht gruppierten Index besteht also in Wirklichkeit aus zwei B-Tree-Suchvorgängen, von denen die erste das Blatt des nicht gruppierten Index findet, und dann eine zweite Suche im gruppierten Index.
Dies ist doppelt so teuer wie eine einzelne B-Tree-Suche (mehr oder weniger), daher verfügt InnoDB über eine zusätzliche Funktion namens Adaptiver Hash-Index . Häufig gesuchte Werte werden im AHI zwischengespeichert, und wenn eine Abfrage das nächste Mal nach einem zwischengespeicherten Wert sucht, kann sie eine O(1)-Suche durchführen. Im AHI-Cache findet es einen Zeiger direkt auf das Blatt des Clustered-Index, also eliminiert es beide B-Tree-Suchen, teilweise.
Wie stark dies die Gesamtleistung verbessert, hängt davon ab, wie häufig Sie nach denselben Werten suchen, die zuvor gesucht wurden. Meiner Erfahrung nach ist es typisch, dass das Verhältnis von Hash-Suchen zu Nicht-Hash-Suchen etwa 1:2 beträgt.
Q4. Erstellen Sie die Indizes, um die Abfragen zu bedienen, die Sie optimieren müssen. Typischerweise ist ein Clustered-Index ein primärer oder eindeutiger Schlüssel, und zumindest im Fall von InnoDB ist dies erforderlich. Weder age noch salary dürfte einmalig sein.
Vielleicht gefällt Ihnen meine Präsentation, How to Design Indexes, Really .
F5. InnoDB erstellt automatisch einen Index, wenn Sie eine eindeutige Einschränkung deklarieren. Sie können die Einschränkung nicht haben, ohne dass ein Index dafür vorhanden ist. Wenn Sie keinen Index hätten, wie würde die Engine die Eindeutigkeit sicherstellen, wenn Sie einen Wert einfügen? Es müsste die gesamte Tabelle nach einem doppelten Wert in dieser Spalte durchsucht werden. Der Index hilft, eindeutige Prüfungen viel effizienter zu machen.