Manchmal ist es schwierig, eine große Datenmenge in einem Unternehmen zu verwalten, insbesondere bei der exponentiellen Zunahme von Datenanalyse und IoT-Nutzung. Je nach Größe kann diese Datenmenge die Leistung Ihrer Systeme beeinträchtigen, und Sie müssen wahrscheinlich Ihre Datenbanken skalieren oder einen Weg finden, dies zu beheben. Es gibt verschiedene Möglichkeiten, Ihre PostgreSQL-Datenbanken zu skalieren, und eine davon ist Sharding. In diesem Blog werden wir sehen, was Sharding ist und wie man es in PostgreSQL mit ClusterControl konfiguriert, um die Aufgabe zu vereinfachen.
Was ist Sharding?
Sharding ist die Aktion zur Optimierung einer Datenbank durch Aufteilen von Daten aus einer großen Tabelle in mehrere kleine. Kleinere Tabellen sind Shards (oder Partitionen). Partitionierung und Sharding sind ähnliche Konzepte. Der Hauptunterschied besteht darin, dass beim Sharding die Daten auf mehrere Computer verteilt werden, während es beim Partitionieren um das Gruppieren von Teilmengen von Daten innerhalb einer einzelnen Datenbankinstanz geht.
Es gibt zwei Arten von Sharding:
-
Horizontal Sharding:Jede neue Tabelle hat dasselbe Schema wie die große Tabelle, aber eindeutige Zeilen. Dies ist nützlich, wenn Abfragen dazu neigen, eine Teilmenge von Zeilen zurückzugeben, die oft zusammen gruppiert sind.
-
Vertical Sharding:Jede neue Tabelle hat ein Schema, das eine Teilmenge des Schemas der ursprünglichen Tabelle ist. Dies ist nützlich, wenn Abfragen dazu neigen, nur eine Teilmenge der Datenspalten zurückzugeben.
Sehen wir uns ein Beispiel an:
Originaltabelle
| ID | Name | Alter | Land |
|---|---|---|---|
| 1 | James Smith | 26 | USA |
| 2 | Mary Johnson | 31 | Deutschland |
| 3 | Robert Williams | 54 | Kanada |
| 4 | Jennifer Brown | 47 | Frankreich |
Vertikales Sharding
| Shard1 | Shard2 | |||
|---|---|---|---|---|
| ID | Name | Alter | ID | Land |
| 1 | James Smith | 26 | 1 | USA |
| 2 | Mary Johnson | 31 | 2 | Deutschland |
| 3 | Robert Williams | 54 | 3 | Kanada |
| 4 | Jennifer Brown | 47 | 4 | Frankreich |
Horizontales Sharding
| Shard1 | Shard2 | ||||||
|---|---|---|---|---|---|---|---|
| ID | Name | Alter | Land | ID | Name | Alter | Land |
| 1 | James Smith | 26 | USA | 3 | Robert Williams | 54 | Kanada |
| 2 | Mary Johnson | 31 | Deutschland | 4 | Jennifer Brown | 47 | Frankreich |
Nachdem wir nun einige Sharding-Konzepte besprochen haben, fahren wir mit dem nächsten Schritt fort.
Wie stelle ich einen PostgreSQL-Cluster bereit?
Wir werden ClusterControl für diese Aufgabe verwenden. Wenn Sie ClusterControl noch nicht verwenden, können Sie es installieren und Ihre aktuelle PostgreSQL-Datenbank bereitstellen oder importieren, indem Sie die Option „Importieren“ auswählen und den Schritten folgen, um alle ClusterControl-Funktionen wie Backups, automatisches Failover, Warnungen, Überwachung und mehr zu nutzen .
Um eine Bereitstellung über ClusterControl durchzuführen, wählen Sie einfach die Option „Bereitstellen“ und folgen Sie den angezeigten Anweisungen.
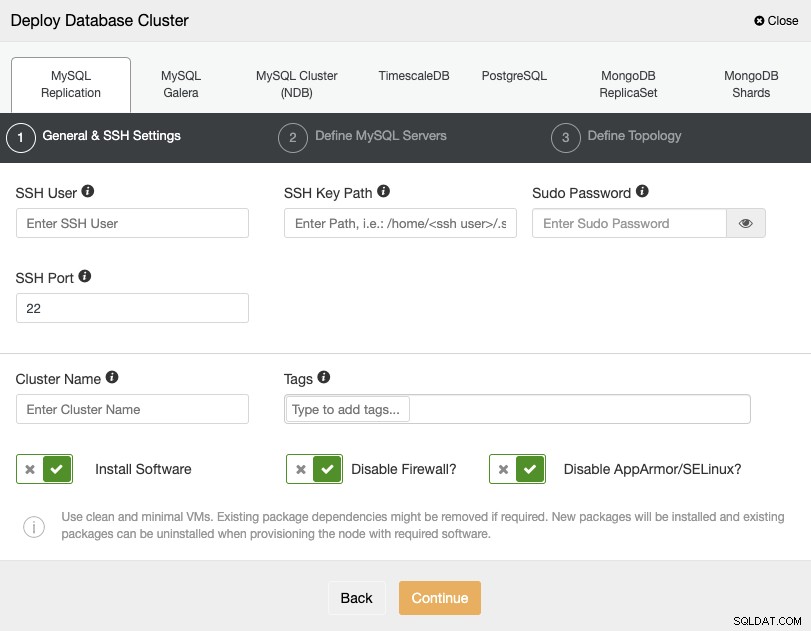
Bei der Auswahl von PostgreSQL müssen Sie Ihren Benutzer, Schlüssel oder Ihr Passwort angeben und Port für die Verbindung per SSH mit Ihren Servern. Sie können Ihrem neuen Cluster auch einen Namen geben und wenn Sie möchten, können Sie auch ClusterControl verwenden, um die entsprechende Software und Konfigurationen für Sie zu installieren.
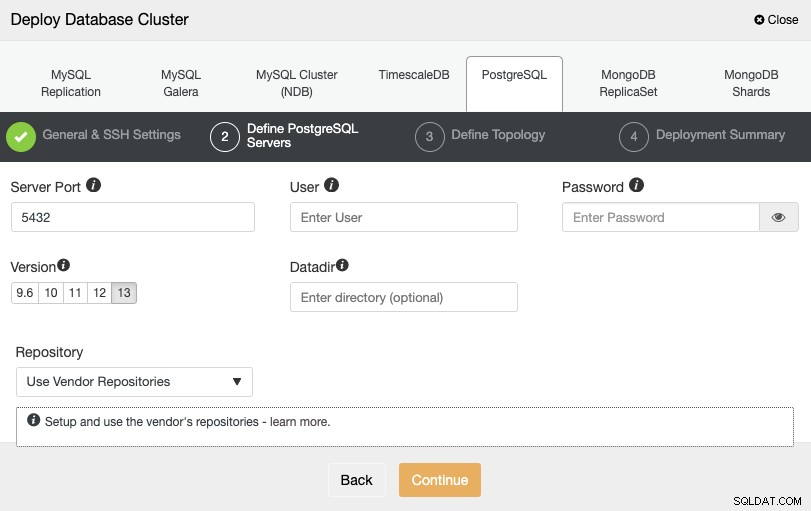
Nachdem Sie die SSH-Zugriffsinformationen eingerichtet haben, müssen Sie die Datenbankanmeldeinformationen definieren , Version und Datenverzeichnis (optional). Sie können auch angeben, welches Repository verwendet werden soll.
Im nächsten Schritt müssen Sie Ihre Server mithilfe der IP-Adresse oder des Hostnamens zu dem Cluster hinzufügen, den Sie erstellen werden.
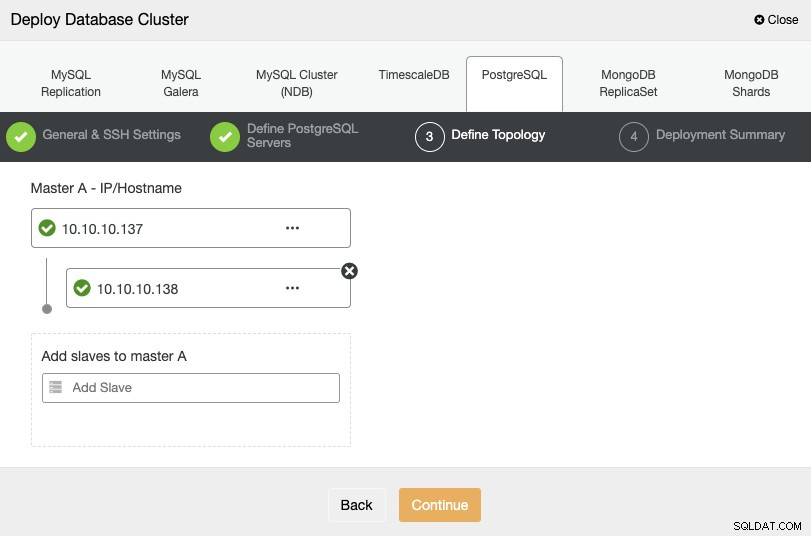
Im letzten Schritt können Sie wählen, ob Ihre Replikation synchron oder Asynchron, und drücken Sie dann einfach auf „Bereitstellen“.
Sobald die Aufgabe abgeschlossen ist, sehen Sie Ihren neuen PostgreSQL-Cluster in der Hauptbildschirm von ClusterControl.

Nachdem Sie Ihren Cluster erstellt haben, können Sie mehrere Aufgaben darauf ausführen wie das Hinzufügen eines Load Balancers (HAProxy), eines Connection Poolers (pgBouncer) oder eines neuen Replikats.
Wiederholen Sie den Vorgang, um mindestens zwei separate PostgreSQL-Cluster zum Konfigurieren von Sharding zu haben, was der nächste Schritt ist.
Wie konfiguriere ich PostgreSQL-Sharding?
Nun konfigurieren wir Sharding mit PostgreSQL-Partitionen und Foreign Data Wrapper (FDW). Diese Funktionalität ermöglicht PostgreSQL den Zugriff auf Daten, die auf anderen Servern gespeichert sind. Es ist eine Erweiterung, die standardmäßig in der allgemeinen PostgreSQL-Installation verfügbar ist.
Wir werden die folgende Umgebung verwenden:
Servers: Shard1 - 10.10.10.137, Shard2 - 10.10.10.138
Database User: admindb
Table: customersUm die FDW-Erweiterung zu aktivieren, müssen Sie nur den folgenden Befehl auf Ihrem Hauptserver ausführen, in diesem Fall Shard1:
postgres=# CREATE EXTENSION postgres_fdw;
CREATE EXTENSIONNun erstellen wir die Tabelle Kunden unterteilt nach Registrierungsdatum:
postgres=# CREATE TABLE customers (
id INT NOT NULL,
name VARCHAR(30) NOT NULL,
registered DATE NOT NULL
)
PARTITION BY RANGE (registered);Und die folgenden Partitionen:
postgres=# CREATE TABLE customers_2021
PARTITION OF customers
FOR VALUES FROM ('2021-01-01') TO ('2022-01-01');
postgres=# CREATE TABLE customers_2020
PARTITION OF customers
FOR VALUES FROM ('2020-01-01') TO ('2021-01-01');Diese Partitionen sind lokal. Lassen Sie uns nun einige Testwerte einfügen und überprüfen:
postgres=# INSERT INTO customers (id, name, registered) VALUES (1, 'James', '2020-05-01');
postgres=# INSERT INTO customers (id, name, registered) VALUES (2, 'Mary', '2021-03-01');Hier können Sie die Hauptpartition abfragen, um alle Daten zu sehen:
postgres=# SELECT * FROM customers;
id | name | registered
----+-------+------------
1 | James | 2020-05-01
2 | Mary | 2021-03-01
(2 rows)Oder auch die entsprechende Partition abfragen:
postgres=# SELECT * FROM customers_2021;
id | name | registered
----+------+------------
2 | Mary | 2021-03-01
(1 row)
postgres=# SELECT * FROM customers_2020;
id | name | registered
----+-------+------------
1 | James | 2020-05-01
(1 row)
Wie Sie sehen können, wurden Daten je nach Registrierungsdatum in verschiedene Partitionen eingefügt. Lassen Sie uns nun im Remote-Knoten, in diesem Fall Shard2, eine weitere Tabelle erstellen:
postgres=# CREATE TABLE customers_2019 (
id INT NOT NULL,
name VARCHAR(30) NOT NULL,
registered DATE NOT NULL);Sie müssen diesen Shard2-Server auf folgende Weise in Shard1 erstellen:
postgres=# CREATE SERVER shard2 FOREIGN DATA WRAPPER postgres_fdw OPTIONS (host '10.10.10.138', dbname 'postgres');Und der Benutzer, der darauf zugreift:
postgres=# CREATE USER MAPPING FOR admindb SERVER shard2 OPTIONS (user 'admindb', password 'Passw0rd');Erstellen Sie nun die FOREIGN TABLE in Shard1:
postgres=# CREATE FOREIGN TABLE customers_2019
PARTITION OF customers
FOR VALUES FROM ('2019-01-01') TO ('2020-01-01')
SERVER shard2;Und fügen wir Daten in diese neue entfernte Tabelle von Shard1 ein:
postgres=# INSERT INTO customers (id, name, registered) VALUES (3, 'Robert', '2019-07-01');
INSERT 0 1
postgres=# INSERT INTO customers (id, name, registered) VALUES (4, 'Jennifer', '2019-11-01');
INSERT 0 1Wenn alles geklappt hat, sollten Sie auf die Daten von Shard1 und Shard2 zugreifen können:
Shard1:
postgres=# SELECT * FROM customers;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
1 | James | 2020-05-01
2 | Mary | 2021-03-01
(4 rows)
postgres=# SELECT * FROM customers_2019;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
(2 rows)Shard2:
postgres=# SELECT * FROM customers_2019;
id | name | registered
----+----------+------------
3 | Robert | 2019-07-01
4 | Jennifer | 2019-11-01
(2 rows)Das ist es. Jetzt verwenden Sie Sharding in Ihrem PostgreSQL-Cluster.
Fazit
Partitionierung und Sharding in PostgreSQL sind gute Funktionen. Es hilft Ihnen, wenn Sie unter anderem Daten in einer großen Tabelle trennen müssen, um die Leistung zu verbessern oder Daten auf einfache Weise zu löschen. Ein wichtiger Punkt bei der Verwendung von Sharding ist die Wahl eines guten Shard Keys, der die Daten optimal zwischen den Nodes verteilt. Außerdem können Sie ClusterControl verwenden, um die PostgreSQL-Bereitstellung zu vereinfachen und einige Funktionen wie Überwachung, Warnungen, automatisches Failover, Sicherung, Point-in-Time-Wiederherstellung und mehr zu nutzen.