Einführung
Schon jetzt sind Ihre Übereinstimmungsbedingungen möglicherweise zu weit gefasst. Sie können jedoch die Levenshtein-Distanz verwenden, um Ihre Wörter zu überprüfen. Es ist vielleicht gar nicht so einfach, alle gewünschten Ziele damit zu erfüllen, wie zum Beispiel Klangähnlichkeit. Daher schlage ich vor, Ihr Problem in einige andere Probleme aufzuteilen.
Beispielsweise können Sie einen benutzerdefinierten Prüfer erstellen, der übergebene aufrufbare Eingaben verwendet, die zwei Zeichenfolgen annehmen und dann die Frage beantworten, ob sie gleich sind (für levenshtein das wird für similar_text eine Distanz sein, die kleiner als ein bestimmter Wert ist - einige Prozent Ähnlichkeit e t.c. - Es liegt an Ihnen, Regeln zu definieren).
Ähnlichkeit, basierend auf Wörtern
Nun, alle integrierten Funktionen schlagen fehl, wenn wir über Fälle sprechen, in denen Sie nach teilweisen Übereinstimmungen suchen - insbesondere wenn es sich um nicht geordnete Übereinstimmungen handelt. Daher müssen Sie ein komplexeres Vergleichstool erstellen. Sie haben:
- Daten-String (der zum Beispiel in DB sein wird). Es sieht aus wie D =D0 D1 D2 ... Dn
- Suchzeichenfolge (das ist die Benutzereingabe). Es sieht aus wie S =S0 S1 ... Sm
Hier bedeutet Leerzeichen einfach irgendein Leerzeichen (ich gehe davon aus, dass Leerzeichen die Ähnlichkeit nicht beeinflussen). Auch n > m . Mit dieser Definition geht es bei Ihrem Problem darum, eine Menge von m zu finden Wörter in D was S ähnlich sein wird . Durch set Ich meine jede ungeordnete Sequenz. Wenn wir also eine solche Sequenz finden in D , dann S ist ähnlich wie D .
Offensichtlich, wenn n < m dann enthält die Eingabe mehr Wörter als eine Datenzeichenfolge. In diesem Fall können Sie entweder denken, dass sie nicht ähnlich sind, oder sich wie oben verhalten, aber Daten und Eingaben vertauschen (das sieht zwar etwas seltsam aus, ist aber in gewissem Sinne zutreffend)
Implementierung
Dazu müssen Sie in der Lage sein, eine Reihe von Zeichenfolgen zu erstellen, die Teile von m sind Wörter aus D . Basierend auf meiner dieser Frage
Sie können dies tun mit:
protected function nextAssoc($assoc)
{
if(false !== ($pos = strrpos($assoc, '01')))
{
$assoc[$pos] = '1';
$assoc[$pos+1] = '0';
return substr($assoc, 0, $pos+2).
str_repeat('0', substr_count(substr($assoc, $pos+2), '0')).
str_repeat('1', substr_count(substr($assoc, $pos+2), '1'));
}
return false;
}
protected function getAssoc(array $data, $count=2)
{
if(count($data)<$count)
{
return null;
}
$assoc = str_repeat('0', count($data)-$count).str_repeat('1', $count);
$result = [];
do
{
$result[]=array_intersect_key($data, array_filter(str_split($assoc)));
}
while($assoc=$this->nextAssoc($assoc));
return $result;
}
-so für jedes Array getAssoc() gibt ein Array ungeordneter Auswahlen zurück, die aus m bestehen Artikel jeweils.
Im nächsten Schritt geht es um die Reihenfolge in der produzierten Auswahl. Wir sollten beide Niels Andersen durchsuchen und Andersen Niels in unserem D Schnur. Daher müssen Sie in der Lage sein, Permutationen für Arrays zu erstellen. Es ist ein sehr häufiges Problem, aber ich werde meine Version auch hier einfügen:
protected function getPermutations(array $input)
{
if(count($input)==1)
{
return [$input];
}
$result = [];
foreach($input as $key=>$element)
{
foreach($this->getPermutations(array_diff_key($input, [$key=>0])) as $subarray)
{
$result[] = array_merge([$element], $subarray);
}
}
return $result;
}
Danach können Sie eine Auswahl von m erstellen Wörter und dann, indem Sie jedes von ihnen permutieren, erhalten Sie alle Varianten zum Vergleichen mit der Suchzeichenfolge S . Dieser Vergleich erfolgt jedes Mal über einen Rückruf, wie z. B. levenshtein . Hier ist ein Beispiel:
public function checkMatch($search, callable $checker=null, array $args=[], $return=false)
{
$data = preg_split('/\s+/', strtolower($this->data), -1, PREG_SPLIT_NO_EMPTY);
$search = trim(preg_replace('/\s+/', ' ', strtolower($search)));
foreach($this->getAssoc($data, substr_count($search, ' ')+1) as $assoc)
{
foreach($this->getPermutations($assoc) as $ordered)
{
$ordered = join(' ', $ordered);
$result = call_user_func_array($checker, array_merge([$ordered, $search], $args));
if($result<=$this->distance)
{
return $return?$ordered:true;
}
}
}
return $return?null:false;
}
Dies überprüft die Ähnlichkeit basierend auf einem Benutzerrückruf, der mindestens zwei Parameter (d. h. verglichene Zeichenfolgen) akzeptieren muss. Möglicherweise möchten Sie auch eine Zeichenfolge zurückgeben, die eine positive Callback-Rückgabe ausgelöst hat. Bitte beachten Sie, dass dieser Code nicht zwischen Groß- und Kleinschreibung unterscheidet - aber vielleicht möchten Sie ein solches Verhalten nicht (dann ersetzen Sie einfach strtolower() ).
Ein Beispiel für den vollständigen Code ist in dieser Auflistung verfügbar (Ich habe keine Sandbox verwendet, da ich nicht sicher bin, wie lange die Code-Auflistung dort verfügbar sein wird). Mit diesem Anwendungsbeispiel:
$data = 'Niels Faurskov Andersen';
$search = [
'Niels Andersen',
'Niels Faurskov',
'Niels Faurskov Andersen',
'Nils Faurskov Andersen',
'Nils Andersen',
'niels faurskov',
'niels Faurskov',
'niffddels Faurskovffre'//I've added this crap
];
$checker = new Similarity($data, 2);
echo(sprintf('Testing "%s"'.PHP_EOL.PHP_EOL, $data));
foreach($search as $name)
{
echo(sprintf(
'Name "%s" has %s'.PHP_EOL,
$name,
($result=$checker->checkMatch($name, 'levenshtein', [], 1))
?sprintf('matched with "%s"', $result)
:'mismatched'
)
);
}
Sie erhalten ein Ergebnis wie:
Testing "Niels Faurskov Andersen" Name "Niels Andersen" has matched with "niels andersen" Name "Niels Faurskov" has matched with "niels faurskov" Name "Niels Faurskov Andersen" has matched with "niels faurskov andersen" Name "Nils Faurskov Andersen" has matched with "niels faurskov andersen" Name "Nils Andersen" has matched with "niels andersen" Name "niels faurskov" has matched with "niels faurskov" Name "niels Faurskov" has matched with "niels faurskov" Name "niffddels Faurskovffre" has mismatched
- hier ist Demo für diesen Code, nur für den Fall.
Komplexität
Da Sie sich nicht nur um irgendwelche Methoden kümmern, sondern auch um - wie gut ist es, werden Sie vielleicht feststellen, dass solcher Code ziemlich exzessive Operationen produziert. Ich meine zumindest die Generierung von Saitenparts. Komplexität besteht hier aus zwei Teilen:
- Generierungsteil für Strings. Wenn Sie alle Saitenteile generieren möchten, müssen Sie dies so tun, wie ich es oben beschrieben habe. Möglicher Verbesserungspunkt - Generierung von ungeordneten Zeichenfolgensätzen (das kommt vor der Permutation). Ich bezweifle jedoch, dass dies möglich ist, da die Methode im bereitgestellten Code sie nicht mit "Brute-Force" generiert, sondern mathematisch berechnet (mit einer Kardinalität von
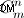 )
) - Ähnlichkeitsprüfungsteil. Hier hängt Ihre Komplexität vom gegebenen Ähnlichkeitsprüfer ab. Beispiel:
similar_text()hat O(N)-Komplexität, daher wird es bei großen Vergleichsmengen extrem langsam sein.
Sie können die aktuelle Lösung jedoch immer noch verbessern, indem Sie sie im laufenden Betrieb überprüfen. Jetzt generiert dieser Code zuerst alle String-Untersequenzen und beginnt dann, sie nacheinander zu überprüfen. In der Regel müssen Sie das nicht tun, also möchten Sie es vielleicht durch Verhalten ersetzen, wenn es nach dem Generieren der nächsten Sequenz sofort überprüft wird. Dann erhöhen Sie die Leistung für Zeichenfolgen mit positiver Antwort (aber nicht für Zeichenfolgen ohne Übereinstimmung).