Wollte mit der Option einsteigen, Ihre Aufgabe mit reinem BigQuery (Standard-SQL) zu lösen
Voraussetzungen/Annahmen :Quelldaten befinden sich in sandbox.temp.id1_id2_pairs
Sie sollten dies durch Ihre eigene ersetzen oder wenn Sie mit Dummy-Daten aus Ihrer Frage testen möchten - Sie können diese Tabelle wie folgt erstellen (natürlich ersetzen Sie sandbox.temp mit Ihrem eigenen project.dataset )
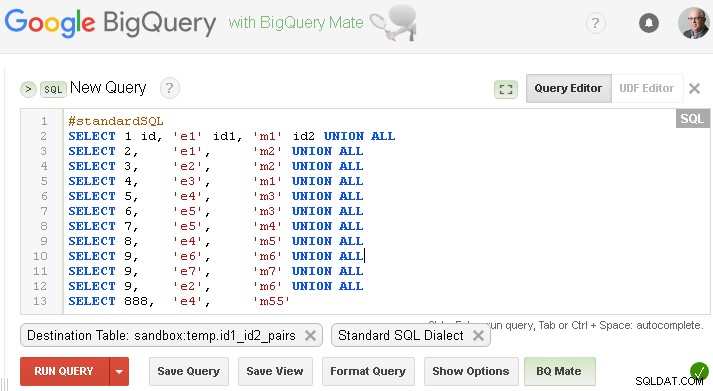
Stellen Sie sicher, dass Sie die entsprechende Zieltabelle eingestellt haben
Hinweis :Sie finden alle entsprechenden Abfragen (als Text) am Ende dieser Antwort, aber im Moment veranschauliche ich meine Antwort mit Screenshots - damit alles dargestellt wird - Abfrage, Ergebnis und verwendete Optionen
Es gibt also drei Schritte:
Schritt 1 – Initialisierung
Hier führen wir nur eine anfängliche Gruppierung von id1 basierend auf Verbindungen mit id2 durch:
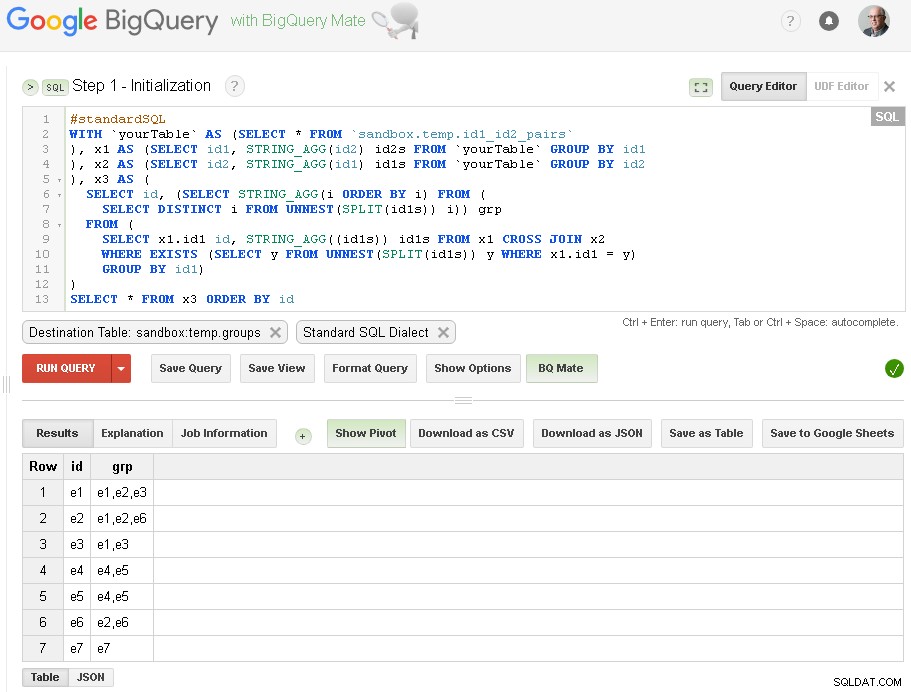
Wie Sie hier sehen können, haben wir eine Liste aller id1-Werte mit entsprechenden Verbindungen basierend auf einer einfachen einstufigen Verbindung über id2
erstellt
Ausgabetabelle ist sandbox.temp.groups
Schritt 2 – Gruppieren von Iterationen
In jeder Iteration werden wir die Gruppierung basierend auf bereits eingerichteten Gruppen anreichern.
Quelle der Abfrage ist die Ausgabetabelle des vorherigen Schritts (sandbox.temp.groups). ) und Ziel ist dieselbe Tabelle (sandbox.temp.groups ) mit Überschreiben
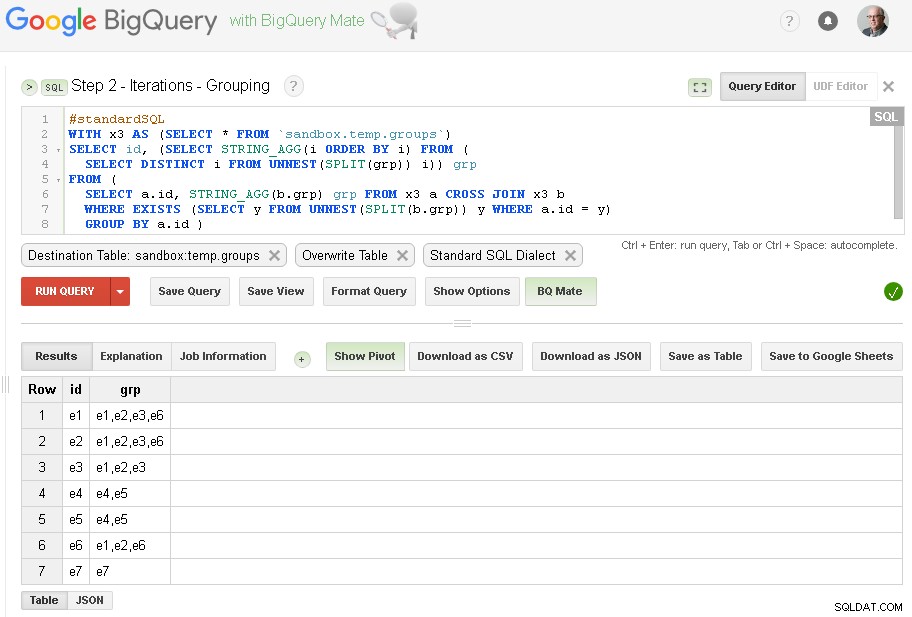
Wir werden die Iterationen fortsetzen, bis die Anzahl der gefundenen Gruppen dieselbe ist wie in der vorherigen Iteration
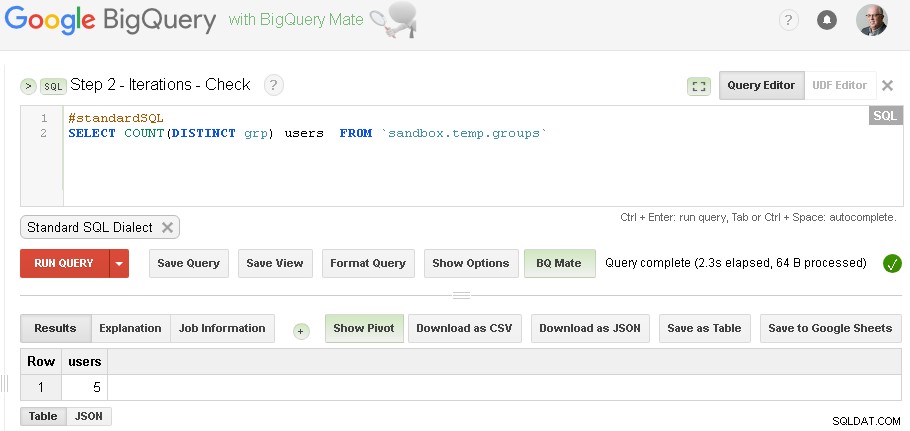
Hinweis :Sie können einfach zwei BigQuery-Web-UI-Tabs geöffnet haben (wie oben gezeigt) und ohne Codeänderungen einfach Gruppierung ausführen und dann immer wieder prüfen, bis die Iterationen zusammenlaufen
(Für spezifische Daten, die ich im Abschnitt „Voraussetzungen“ verwendet habe – ich hatte drei Iterationen – die erste Iteration hat 5 Benutzer hervorgebracht, die zweite Iteration hat 3 Benutzer hervorgebracht und die dritte Iteration hat wiederum 3 Benutzer hervorgebracht – was darauf hindeutet, dass wir mit den Iterationen fertig sind.
Im realen Fall kann die Anzahl der Iterationen natürlich mehr als nur drei betragen, daher benötigen wir eine Art Automatisierung (siehe entsprechenden Abschnitt am Ende der Antwort).
Schritt 3 – Endgültige Gruppierung
Wenn die id1-Gruppierung abgeschlossen ist, können wir die endgültige Gruppierung für id2 hinzufügen
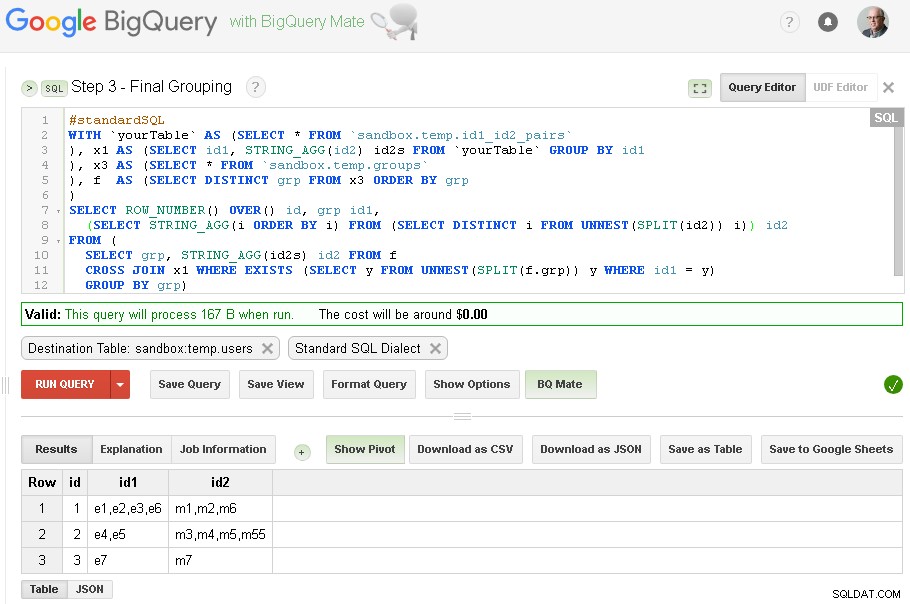
Das Endergebnis befindet sich jetzt in sandbox.temp.users Tabelle
Verwendete Suchanfragen (Vergessen Sie nicht, die entsprechenden Zieltabellen festzulegen und bei Bedarf zu überschreiben, wie in der oben beschriebenen Logik und den Screenshots):
Voraussetzungen:
#standardSQL
SELECT 1 id, 'e1' id1, 'm1' id2 UNION ALL
SELECT 2, 'e1', 'm2' UNION ALL
SELECT 3, 'e2', 'm2' UNION ALL
SELECT 4, 'e3', 'm1' UNION ALL
SELECT 5, 'e4', 'm3' UNION ALL
SELECT 6, 'e5', 'm3' UNION ALL
SELECT 7, 'e5', 'm4' UNION ALL
SELECT 8, 'e4', 'm5' UNION ALL
SELECT 9, 'e6', 'm6' UNION ALL
SELECT 9, 'e7', 'm7' UNION ALL
SELECT 9, 'e2', 'm6' UNION ALL
SELECT 888, 'e4', 'm55'
Schritt 1
#standardSQL
WITH `yourTable` AS (select * from `sandbox.temp.id1_id2_pairs`
), x1 AS (SELECT id1, STRING_AGG(id2) id2s FROM `yourTable` GROUP BY id1
), x2 AS (SELECT id2, STRING_AGG(id1) id1s FROM `yourTable` GROUP BY id2
), x3 AS (
SELECT id, (SELECT STRING_AGG(i ORDER BY i) FROM (
SELECT DISTINCT i FROM UNNEST(SPLIT(id1s)) i)) grp
FROM (
SELECT x1.id1 id, STRING_AGG((id1s)) id1s FROM x1 CROSS JOIN x2
WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(id1s)) y WHERE x1.id1 = y)
GROUP BY id1)
)
SELECT * FROM x3
Schritt 2 – Gruppieren
#standardSQL
WITH x3 AS (select * from `sandbox.temp.groups`)
SELECT id, (SELECT STRING_AGG(i ORDER BY i) FROM (
SELECT DISTINCT i FROM UNNEST(SPLIT(grp)) i)) grp
FROM (
SELECT a.id, STRING_AGG(b.grp) grp FROM x3 a CROSS JOIN x3 b
WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(b.grp)) y WHERE a.id = y)
GROUP BY a.id )
Schritt 2 - Aktivieren Sie
#standardSQL
SELECT COUNT(DISTINCT grp) users FROM `sandbox.temp.groups`
Schritt 3
#standardSQL
WITH `yourTable` AS (select * from `sandbox.temp.id1_id2_pairs`
), x1 AS (SELECT id1, STRING_AGG(id2) id2s FROM `yourTable` GROUP BY id1
), x3 as (select * from `sandbox.temp.groups`
), f AS (SELECT DISTINCT grp FROM x3 ORDER BY grp
)
SELECT ROW_NUMBER() OVER() id, grp id1,
(SELECT STRING_AGG(i ORDER BY i) FROM (SELECT DISTINCT i FROM UNNEST(SPLIT(id2)) i)) id2
FROM (
SELECT grp, STRING_AGG(id2s) id2 FROM f
CROSS JOIN x1 WHERE EXISTS (SELECT y FROM UNNEST(SPLIT(f.grp)) y WHERE id1 = y)
GROUP BY grp)
Automatisierung :
Natürlich kann der obige "Prozess" manuell ausgeführt werden, falls die Iterationen schnell konvergieren - so werden Sie am Ende 10-20 Läufe haben. Aber in realeren Fällen können Sie dies einfach mit jedem Client
automatisieren Ihrer Wahl