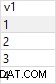
Ja, es sollte anders sein - (1) wird voraussichtlich schneller sein.
Having stellt sicher, dass zuerst die Hauptabfrage ausgeführt wird und dann der Having-Filter angewendet wird - es funktioniert also im Grunde genommen mit dem Datensatz, der von der (Abfrage minus Have) zurückgegeben wird.
Die erste Abfrage sollte vorgezogen werden, da sie diese Datensätze überhaupt nicht auswählt.