Welche Probleme werden wir berücksichtigen?
Wenn der Server meldet „Auf dem E-Laufwerk ist kein Platz mehr“ – ist keine tiefgreifende Analyse erforderlich. Fehler, deren Lösung aus dem Text der Nachricht ersichtlich ist und für die Google sofort einen Link zu MSDN mit der Lösung wirft, werden von uns nicht berücksichtigt.
Betrachten wir die für Google nicht offensichtlichen Probleme, wie zum Beispiel ein plötzlicher Leistungsabfall oder die fehlende Verbindung. Betrachten Sie die wichtigsten Tools für die Anpassung und Analyse. Mal sehen, wo sich die Protokolle und andere nützliche Informationen befinden. Tatsächlich werde ich versuchen, alle notwendigen Informationen für einen schnellen Start in einem Artikel zu sammeln.
Zuallererst
Wir beginnen mit den häufigsten Fragen und betrachten sie separat.
Wenn Ihre Datenbank plötzlich ohne ersichtlichen Grund langsam zu arbeiten begann, Sie aber nichts geändert hatten, aktualisieren Sie zunächst die Statistiken und bauen Sie die Indizes neu auf.
Im Internet gibt es viele solcher Methoden, Beispiele für Skripte werden bereitgestellt. Ich gehe davon aus, dass all diese Methoden für Profis sind. Nun, ich beschreibe den einfachsten Weg:Sie brauchen nur eine Maus, um es umzusetzen.
Abkürzungen
- SSMS ist eine Anwendung von Microsoft SQL Server Management Studio. Ab der Version 2016 ist es kostenlos auf der MS-Website als eigenständige Anwendung verfügbar. docs.microsoft.com/en-us/sql/ssms/download-sql-server-management-studio-ssms
- Profiler ist eine Anwendung von „SQL Server Profiler“, die mit SSMS installiert wird.
- Performance Monitor ist ein Snap-In des Control Panels, mit dem Sie die Leistungszähler überwachen, den Verlauf von Messungen protokollieren und anzeigen können.
Statistikaktualisierung mit einem „Dienstplan“:
- SSMS ausführen;
- mit einem erforderlichen Server verbinden;
- erweitern Sie den Baum im Objektinspektor:Verwaltung\Wartungspläne (Servicepläne);
- Klicken Sie mit der rechten Maustaste auf den Knoten und wählen Sie „Wartungsplan-Assistent“;
- Markieren Sie im Assistenten die erforderlichen Aufgaben:Index neu erstellen und Statistiken aktualisieren
- Sie können beide Aufgaben gleichzeitig markieren oder zwei Wartungspläne mit jeweils einer Aufgabe erstellen (siehe „Wichtige Hinweise“ weiter unten);
- weiter prüfen wir eine benötigte DB (oder mehrere Datenbanken). Wir tun dies für jede Aufgabe (wenn zwei Aufgaben ausgewählt werden, gibt es zwei Dialoge mit der Auswahl einer Datenbank);
- Weiter, Weiter, Fertig.
Nach diesen Aktionen wird ein „Wartungsplan“ erstellt (nicht ausgeführt). Sie können es manuell ausführen, indem Sie mit der rechten Maustaste darauf klicken und „Ausführen“ auswählen. Alternativ konfigurieren Sie den Start per SQL Agent.
Wichtige Hinweise:
- Das Aktualisieren von Statistiken ist ein nicht blockierender Vorgang. Sie können es in einem Arbeitsmodus ausführen.
- Der Indexneuaufbau ist ein Blockiervorgang. Sie können es nur außerhalb der Arbeitszeiten ausführen. Es gibt eine Ausnahme – die Enterprise-Edition des Servers erlaubt die Ausführung eines „Online-Neuaufbaus“. Diese Option kann in den Aufgabeneinstellungen aktiviert werden. Bitte beachten Sie, dass in allen Editionen ein Häkchen vorhanden ist, aber es funktioniert nur in Enterprise.
- Natürlich müssen diese Aufgaben regelmäßig durchgeführt werden. Ich schlage eine einfache Methode vor, um festzustellen, wie oft Sie dies tun:
– Bei den ersten Problemen den Wartungsplan ausführen;
– Wenn es geholfen hat, warten Sie, bis die Probleme wieder auftreten (in der Regel bis zum nächsten Monatsabschluss/Gehaltsabrechnung/ etc. bei Massengeschäften);
– Der resultierende Zeitraum eines normalen Betriebs ist Ihr Bezugspunkt;
– Konfigurieren Sie beispielsweise die Ausführung des Wartungsplans doppelt so oft.
Der Server ist langsam – was sollten Sie tun?
Die vom Server verwendeten Ressourcen
Wie jedes andere Programm benötigt der Server Prozessorzeit, Daten auf der Festplatte, RAM und Netzwerkbandbreite.
Der Task-Manager hilft Ihnen, den Mangel an einer bestimmten Ressource in erster Näherung einzuschätzen, egal wie schrecklich es klingen mag.
Prozessor Laden
Auch ein Schüler kann die Auslastung im Manager überprüfen. Wir müssen nur sicherstellen, dass, wenn der Prozessor geladen ist, es der Prozess sqlserver.exe ist.
Wenn dies der Fall ist, müssen Sie zur Analyse der Benutzeraktivität gehen, um zu verstehen, was genau die Last verursacht hat (siehe unten).
Disc Loa d
Viele Leute schauen nur auf die CPU-Last, vergessen aber, dass das DBMS ein Datenspeicher ist. Die Datenmengen wachsen, die Prozessorleistung steigt, während die HDD-Geschwindigkeit in etwa gleich bleibt. Bei SSDs ist die Situation besser, aber das Speichern von Terabytes darauf ist teuer.
Es stellt sich heraus, dass ich oft auf Situationen stoße, in denen das Festplattensystem zum Engpass wird und nicht die CPU.
Für Festplatten sind die folgenden Metriken wichtig:
- durchschnittliche Warteschlangenlänge (ausstehende E/A-Operationen, Anzahl);
- Lese-/Schreibgeschwindigkeit (in MB/s).
Die Server-Version des Task-Managers zeigt in der Regel (je nach Systemversion) beides an. Führen Sie andernfalls das Systemmonitor-Snap-In (Systemmonitor) aus. Wir interessieren uns für folgende Zähler:
- Physischer (logischer) Datenträger/durchschnittliche Lese- (Schreib-)Zeit
- Physischer (logischer) Datenträger/durchschnittliche Warteschlangenlänge des Datenträgers
- Physische (logische) Festplatte/Festplattengeschwindigkeit
Für weitere Details können Sie die Handbücher der Hersteller beispielsweise hier nachlesen:social.technet.microsoft.com/wiki/contents/articles/3214.monitoring-disk-usage.aspx.
Kurz:
- Die Warteschlange sollte 1 nicht überschreiten. Kurze Bursts sind zulässig, wenn sie schnell abklingen. Die Bursts können je nach System unterschiedlich sein. Für eine einfache RAID-Spiegelung von zwei Festplatten – die Warteschlange von mehr als 10-20 ist ein Problem. Bei einer coolen Bibliothek mit Super-Caching habe ich Bursts von bis zu 600–800 gesehen, die sofort ohne Verzögerungen aufgelöst wurden.
- Der normale Wechselkurs hängt auch von der Art eines Plattensystems ab. Die übliche (Desktop-)HDD überträgt mit 50-100 MB/s. Eine gute Disk Library – mit 500 MB/s und mehr. Bei kleinen Zufallsoperationen ist die Geschwindigkeit geringer. Dies kann Ihr Bezugspunkt sein.
- Diese Parameter müssen als Ganzes betrachtet werden. Wenn Ihre Bibliothek 50 MB/s überträgt und eine Warteschlange von 50 Operationen ansteht, stimmt offensichtlich etwas mit der Hardware nicht. Wenn sich die Warteschlange staut, wenn die Übertragung nahe an einem Maximum ist – wahrscheinlich ist dies nicht den Platten anzulasten – sie können einfach nicht mehr – müssen wir nach einer Möglichkeit suchen, die Last zu reduzieren.
- Die Auslastung sollte auf Platten (falls es mehrere gibt) separat geprüft und mit dem Speicherort von Serverdateien verglichen werden. Der Task-Manager kann die am aktivsten verwendeten Dateien anzeigen. Damit kann sichergestellt werden, dass die Last durch DBMS verursacht wird.
Was kann Probleme mit dem Festplattensystem verursachen:
- Probleme mit der Hardware
- Cache ausgebrannt, Leistung drastisch gesunken;
- das Plattensystem wird von etwas anderem verwendet;
- RAM-Mangel. Austauschen. Caching verfallen, Leistung gesunken (siehe Abschnitt über RAM unten).
- Benutzerlast erhöht. Es ist notwendig, die Arbeit der Benutzer zu evaluieren (problematische Abfrage/neue Funktionalität/Anstieg der Benutzeranzahl/Anstieg der Datenmenge/etc).
- Datenbankdatenfragmentierung (siehe Indexneuaufbau oben), Systemdateifragmentierung.
- Das Festplattensystem hat seine maximale Leistungsfähigkeit erreicht.
Im Fall der letzten Option – werfen Sie die Hardware nicht sofort weg. Manchmal können Sie etwas mehr aus dem System herausholen, wenn Sie das Problem mit Bedacht angehen. Überprüfen Sie den Speicherort der Systemdateien auf Übereinstimmung mit den empfohlenen Anforderungen:
- Vermischen Sie Betriebssystemdateien nicht mit Datenbankdatendateien. Speichern Sie sie auf verschiedenen physischen Medien, damit das System nicht mit DBMS um I/O konkurriert.
- Die Datenbank besteht aus zwei Dateitypen:Daten (*.mdf, *.ndf) und Protokolle (*.ldf).
Datendateien werden in der Regel hauptsächlich zum Lesen verwendet. Protokolle dienen zum Schreiben (wobei das Schreiben fortlaufend ist). Es wird daher empfohlen, Protokolle und Daten auf verschiedenen physikalischen Medien zu speichern, damit das Protokollieren das Lesen der Daten nicht unterbricht (in der Regel hat der Schreibvorgang Vorrang vor dem Lesen). - MS SQL kann „temporäre Tabellen“ für die Abfrageverarbeitung verwenden. Sie werden in der Systemdatenbank tempdb gespeichert. Wenn Sie eine hohe Last auf Dateien dieser Datenbank haben, können Sie versuchen, sie auf physisch getrennten Medien zu rendern.
Fassen Sie das Problem mit dem Dateispeicherort zusammen und verwenden Sie das Prinzip „Teile und herrsche“. Werten Sie aus, auf welche Dateien zugegriffen wird, und versuchen Sie, diese auf verschiedene Medien zu verteilen. Nutzen Sie auch die Funktionen von RAID-Systemen. Beispielsweise sind RAID-5-Lesevorgänge schneller als Schreibvorgänge – was gut für Datendateien ist.
Sehen wir uns an, wie Sie Informationen zur Benutzerleistung abrufen:Wer macht was und wie viele Ressourcen werden verbraucht
Ich habe die Aufgaben zur Überwachung der Benutzeraktivität in die folgenden Gruppen eingeteilt:
- Aufgaben zur Analyse bestimmter Anfragen.
- Aufgaben zur Analyse der Belastung durch die Anwendung unter bestimmten Bedingungen (z. B. wenn ein Benutzer auf eine Schaltfläche in einer mit der Datenbank kompatiblen Drittanbieteranwendung klickt).
- Aufgaben zur Analyse der Ist-Situation.
Lassen Sie uns jeden von ihnen im Detail betrachten.
Warnung
Die Leistungsanalyse erfordert ein tiefes Verständnis der Struktur und der Funktionsprinzipien des Datenbankservers und des Betriebssystems. Deshalb wird das Lesen nur dieser Artikel Sie nicht zum Profi machen.
Die betrachteten Kriterien und Zähler in realen Systemen hängen stark voneinander ab. So wird beispielsweise eine hohe HDD-Last häufig durch fehlenden Arbeitsspeicher verursacht. Selbst wenn Sie einige Messungen durchführen, reicht dies nicht aus, um die Probleme vernünftig einzuschätzen.
Der Zweck der Artikel ist es, das Wesentliche an einfachen Beispielen vorzustellen. Sie sollten meine Empfehlungen nicht als Leitfaden betrachten. Ich empfehle Ihnen, sie als Trainingsaufgaben zu verwenden, die den Gedankenfluss erklären können.
Ich hoffe, dass Sie lernen, Ihre Schlussfolgerungen zur Serverleistung in Zahlen zu begründen.
Anstatt zu sagen „Server wird langsamer“, geben Sie bestimmte Werte bestimmter Indikatoren an.
Analysiere ein P Artikulation R Anfrage
Der erste Punkt ist ganz einfach, lassen Sie uns kurz darauf eingehen. Wir werden einige weniger offensichtliche Probleme berücksichtigen.
Zusätzlich zu den Abfrageergebnissen ermöglicht SSMS das Abrufen zusätzlicher Informationen über die Abfrageausführung:
- Sie können den Abfrageplan abrufen, indem Sie auf die Schaltflächen „Geschätzten Ausführungsplan anzeigen“ und „Tatsächlichen Ausführungsplan einschließen“ klicken. Der Unterschied zwischen ihnen besteht darin, dass der Schätzungsplan ohne Abfrageausführung erstellt wird. Somit wird die Information über die Anzahl der verarbeiteten Zeilen geschätzt. Im tatsächlichen Plan gibt es sowohl geschätzte als auch tatsächliche Daten. Starke Abweichungen dieser Werte weisen darauf hin, dass die Statistik nicht relevant ist. Die Analyse des Plans ist jedoch ein Thema für einen anderen Artikel – bis jetzt gehen wir nicht tiefer darauf ein.
- Wir können Messungen der Prozessorkosten und Festplattenoperationen des Servers erhalten. Dazu ist es notwendig, die Option SET zu aktivieren. Sie können dies entweder im Dialogfeld "Abfrageoptionen" wie folgt tun:
Oder mit den direkten SET-Befehlen in der Abfrage:
SET STATISTICS IO ON
SET STATISTICS TIME ON
SELECT * FROM Production.Product p
JOIN Production.ProductDocument pd ON p.ProductID = pd.ProductID
JOIN Production.ProductProductPhoto ppp ON p.ProductID = ppp.ProductIDAls Ergebnis erhalten wir Daten über die für die Kompilierung und Ausführung aufgewendete Zeit sowie die Anzahl der Festplattenoperationen.
Time of SQL Server parsing and compilation:
CPU time = 16 ms, elapsed time = 89 ms.
SQL Server performance time:
CPU time = 0 ms, time spent = 0 ms.
SQL Server performance time:
CPU time = 0 ms, time spent = 0 ms.
(32 row(s) affected)
The «ProductProductPhoto» table. The number of views is 32, logic reads – 96, physical reads 5, read-ahead reads 0, lob of logical reads 0, lob of physical reads 0, lob of read-ahead reads 0.
The ‘Product’ table. The number of views is 0, logic reads – 64, physical reads – 0, read-ahead reads – 0, lob of logical reads – 0, lob of physical reads – 0, lob of readahead reads – 0.
The «ProductDocument» table. The number of views is 1, logical reads – 3, physical reads – 1, read-ahead reads -, lob of logical reads – 0, lob of physical reads – 0, lob of readahead reads – 0.
Time of SQL activity:
CPU time = 15 ms, spent time = 35 ms.Ich möchte Ihre Aufmerksamkeit auf die Kompilierungszeit, die logischen Lesevorgänge 96 und die physischen Lesevorgänge 5 lenken. Wenn dieselbe Abfrage zum zweiten Mal und später ausgeführt wird, können die physischen Lesevorgänge abnehmen und eine erneute Kompilierung ist möglicherweise nicht erforderlich. Aufgrund dieser Tatsache kommt es häufig vor, dass die Abfrage beim zweiten und den folgenden Malen schneller ausgeführt wird als beim ersten Mal. Wie Sie verstehen, liegt der Grund im Zwischenspeichern der Daten und kompilierten Abfragepläne.
- Die Schaltfläche «Client-Statistiken einbeziehen» zeigt die Informationen zum Netzwerkaustausch, die Anzahl der ausgeführten Operationen und die Gesamtausführungszeit, einschließlich der Kosten für den Netzwerkaustausch und die Verarbeitung durch einen Client. Das Beispiel zeigt, dass die erstmalige Ausführung der Abfrage länger dauert:
- In SSMS 2016 gibt es die Schaltfläche «Live-Abfragestatistiken einbeziehen». Es zeigt das Bild wie im Fall des Abfrageplans an, enthält jedoch die nicht zufälligen Ziffern der verarbeiteten Zeilen, die sich während der Ausführung der Abfrage auf dem Bildschirm ändern. Das Bild ist sehr klar – blinkende Pfeile und laufende Zahlen, man sieht sofort, wo die Zeit verschwendet wird. Die Schaltfläche funktioniert auch für SQL Server 2014 und höher.
Zusammenfassend:
- Prüfen Sie die CPU-Kosten mit SET STATISTICS TIME ON.
- Festplattenoperationen:SET STATISTICS IO ON. Vergessen Sie nicht, dass das logische Lesen eine Leseoperation ist, die im Plattencache ausgeführt wird, ohne physisch auf das Plattensystem zuzugreifen. „Physical Read“ nimmt viel mehr Zeit in Anspruch.
- Bewerten Sie das Volumen des Netzwerkverkehrs mit «Client-Statistiken einbeziehen».
- Analysieren Sie den Algorithmus zur Ausführung der Abfrage anhand des Ausführungsplans mit „Aktuellen Ausführungsplan einbeziehen“ und „Live-Abfragestatistik einbeziehen“.
Analysieren Sie die Anwendungslast
Hier verwenden wir den SQL Server Profiler. Nach dem Starten und Verbinden mit dem Server müssen Protokollereignisse ausgewählt werden. Führen Sie dazu die Profilerstellung mit einer standardmäßigen Ablaufverfolgungsvorlage aus. Auf dem Allgemein Registerkarte Vorlage verwenden Wählen Sie im Feld Standard (Standard) aus und klicken Sie auf Ausführen .
Der kompliziertere Weg ist das Hinzufügen/Löschen von Filtern oder Ereignissen zu/von der ausgewählten Vorlage. Diese Optionen finden Sie auf der zweiten Registerkarte des Dialogmenüs. Wählen Sie Alle Ereignisse anzeigen aus, um die gesamte Bandbreite möglicher Ereignisse und auszuwählender Spalten anzuzeigen und Alle Spalten anzeigen Kontrollkästchen.

Wir benötigen die folgenden Ereignisse:
- Gespeicherte Prozeduren \ RPC:Abgeschlossen
- TSQL \ SQL:BatchCompleted
Diese Ereignisse überwachen alle externen SQL-Aufrufe an den Server. Sie erscheinen nach Abschluss der Abfrageverarbeitung. Es gibt ähnliche Ereignisse, die den Start von SQL Server verfolgen:
- Gespeicherte Prozeduren \ RPC:Starten
- TSQL \ SQL:BatchStarting
Wir benötigen diese Prozeduren jedoch nicht, da sie keine Informationen über die für die Abfrageausführung aufgewendeten Serverressourcen enthalten. Es ist offensichtlich, dass solche Informationen erst nach Abschluss des Ausführungsprozesses verfügbar sind. Daher sind Spalten mit Daten zu CPU, Lesevorgängen und Schreibvorgängen in den *Startereignissen leer.
Folgende Events könnten uns ebenfalls interessieren, wir werden sie aber noch nicht freischalten:
- Gespeicherte Prozeduren \ SP:Starting (*Completed) überwacht den internen Aufruf der gespeicherten Prozedur nicht vom Client, sondern innerhalb der aktuellen Anfrage oder einer anderen Prozedur.
- Gespeicherte Prozeduren \ SP:StmtStarting (*Completed) verfolgt den Beginn jeder Anweisung innerhalb der gespeicherten Prozedur. Wenn die Prozedur einen Zyklus enthält, entspricht die Anzahl der Ereignisse für die Befehle im Zyklus der Anzahl der Iterationen im Zyklus.
- TSQL \ SQL:StmtStarting (*Completed) überwacht den Beginn jeder Anweisung innerhalb des SQL-Stapels. Wenn Ihre Abfrage mehrere Befehle enthält, enthält jeder von ihnen ein Ereignis. Somit funktioniert es für die in der Abfrage befindlichen Befehle.
Diese Ereignisse sind praktisch, um den Ausführungsprozess zu überwachen.
Von C Spalten
Welche Spalten ausgewählt werden müssen, ist aus dem Schaltflächennamen ersichtlich. Wir benötigen die folgenden:
- TextData, BinaryData enthalten den Abfragetext.
- CPU, Lesevorgänge, Schreibvorgänge, Dauer zeigen Ressourcenverbrauchsdaten an.
- StartTime, EndTime ist die Zeit zum Starten und Beenden des Ausführungsprozesses. Sie sind praktisch zum Sortieren.
Fügen Sie andere Spalten basierend auf Ihren Einstellungen hinzu.
Die Spaltenfilter… Schaltfläche öffnet das Dialogfeld zum Konfigurieren von Ereignisfiltern. Wenn Sie an der Aktivität des jeweiligen Benutzers interessiert sind, können Sie den Filter nach der SID-Nummer oder dem Benutzernamen setzen. Leider wird die Überwachung des jeweiligen Benutzers komplizierter, wenn die App über den App-Server mit dem Pull von Verbindungen verbunden wird.
Sie können Filter für die Auswahl nur komplizierter Abfragen (Dauer>X), Abfragen, die intensive Schreibvorgänge verursachen (Schreibvorgänge>Y), sowie Abfrageinhaltsauswahlen usw. verwenden.
Was benötigen wir noch vom Profiler? Natürlich der Ausführungsplan!
Es ist notwendig, das Ereignis «Performance \ Showplan XML Statistics Profile» zum Tracing hinzuzufügen. Während wir unsere Abfrage ausführen, erhalten wir das folgende Bild:
Der Abfragetext:
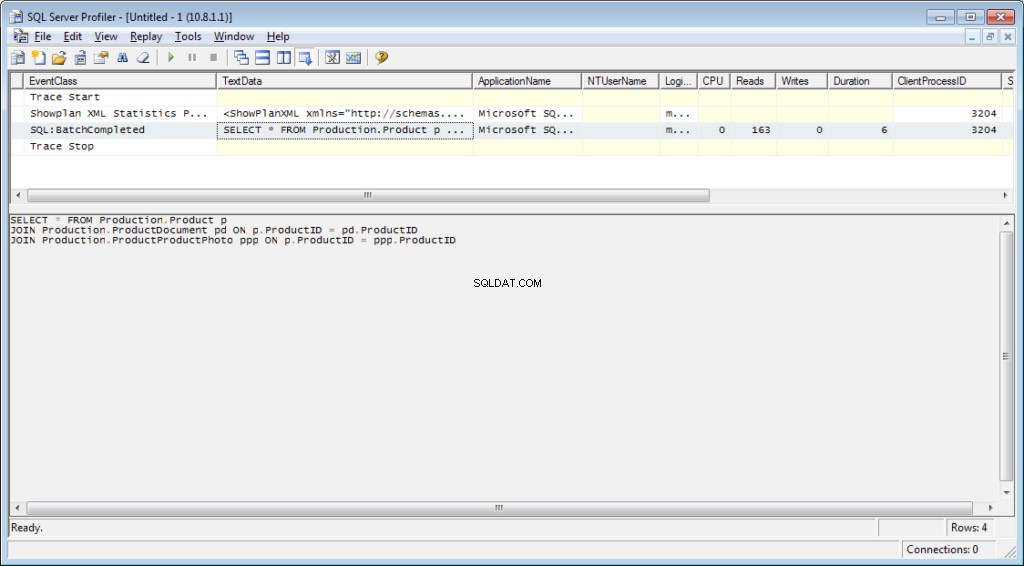
Der Ausführungsplan:
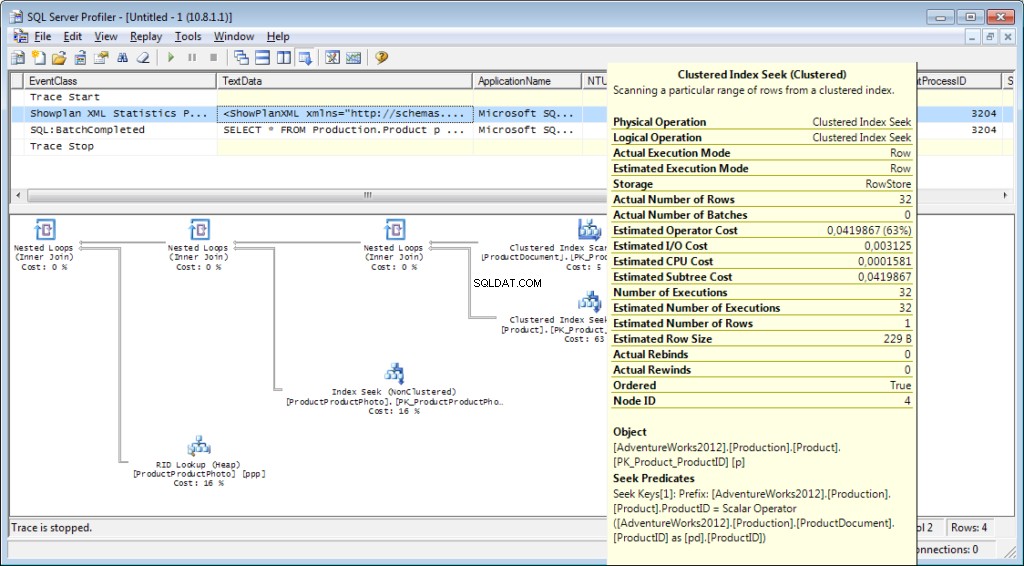
Und das ist noch nicht alles
Es ist möglich, einen Trace in einer Datei oder einer Datenbanktabelle zu speichern. Tracing-Einstellungen können als persönliche Vorlage für einen schnellen Durchlauf gespeichert werden. Sie können die Ablaufverfolgung ohne Profiler ausführen, indem Sie einfach einen T-SQL-Code und die Prozeduren sp_trace_create, sp_trace_setevent, sp_trace_setstatus und sp_trace_getdata verwenden. Ein Beispiel finden Sie hier. Dieser Ansatz kann beispielsweise nützlich sein, um automatisch nach einem Zeitplan mit dem Speichern einer Ablaufverfolgung in einer Datei zu beginnen. Sie können einen kurzen Blick auf den Profiler werfen, um zu sehen, wie diese Befehle verwendet werden. Sie können zwei Ablaufverfolgungen ausführen und in einer verfolgen, was passiert, wenn die zweite beginnt. Stellen Sie sicher, dass im Profiler selbst kein Filter nach der Spalte „ApplicationName“ vorhanden ist.
Die Liste der vom Profiler überwachten Ereignisse ist sehr umfangreich und beschränkt sich nicht nur auf den Empfang von Abfragetexten. Es gibt Ereignisse, die Fullscan, Neukompilierung, Autogrow, Deadlock und vieles mehr verfolgen.
Benutzeraktivität auf dem Server analysieren
Es gibt verschiedene Situationen. Eine Abfrage kann lange auf „Ausführung“ hängen und es ist unklar, ob sie abgeschlossen wird oder nicht. Ich möchte die problematische Abfrage separat analysieren; Allerdings müssen wir zuerst bestimmen, was die Abfrage ist. Es ist sinnlos, es mit einem Profiler abzufangen – wir haben das Startereignis bereits verpasst, und es ist nicht klar, wie lange wir warten müssen, bis der Prozess abgeschlossen ist.
Lass es uns herausfinden
Vielleicht haben Sie schon von „Aktivitätsmonitor“ gehört. Die höheren Editionen haben wirklich umfangreiche Funktionen. Wie kann es uns helfen? Activity Monitor enthält viele nützliche und interessante Funktionen. Wir erhalten alles, was wir brauchen, aus Systemansichten und -funktionen. Monitor selbst ist nützlich, da Sie den Profiler darauf einstellen und sehen können, welche Abfragen er durchführt.
Wir brauchen:
- dm_exec_sessions liefert Informationen über Sitzungen verbundener Benutzer. In unserem Artikel sind die nützlichen Felder diejenigen, die einen Benutzer identifizieren (login_name, login_time, host_name, program_name, …) und Felder mit Informationen zu verbrauchten Ressourcen (cpu_time, reads, writes, memory_usage, …)
- dm_exec_requests liefert Informationen über die gerade ausgeführten Abfragen.
- session_id ist eine Kennung der Sitzung, die mit der vorherigen Ansicht verknüpft werden soll.
- start_time ist die Zeit für die Ausführung der Ansicht.
- command ist ein Feld, das einen Typ des ausgeführten Befehls enthält. Für Benutzerabfragen ist es select/update/delete/
- sql_handle, statement_start_offset, statement_end_offset liefern Informationen zum Abrufen des Abfragetextes:Handle sowie die Start- und Endposition im Text der Abfrage, also den Teil, der gerade ausgeführt wird (für den Fall, dass Ihre Abfrage mehrere enthält Befehle).
- plan_handle ist ein Handle des generierten Plans.
- blocking_session_id gibt die Nummer der Sitzung an, die die Blockierung verursacht hat, wenn es Blockaden gibt, die die Ausführung der Abfrage verhindern
- wait_type, wait_time, wait_resource sind Felder mit Informationen über den Grund und die Dauer der Wartezeit. Bei einigen Wartearten, zB Datensperre, muss zusätzlich ein Code für die gesperrte Ressource angegeben werden.
- percent_complete ist der Prozentsatz der Fertigstellung. Leider ist es nur für Befehle mit einem klar vorhersehbaren Fortschritt (z. B. Sicherung oder Wiederherstellung) verfügbar.
- CPU-Zeit, Lesevorgänge, Schreibvorgänge, logische_Lesevorgänge, gewährter_Abfrage_Speicher sind Ressourcenkosten.
- dm_exec_sql_text(sql_handle | plan_handle), sys.dm_exec_query_plan(plan_handle) sind Funktionen zum Abrufen des Texts und des Ausführungsplans. Nachfolgend betrachten wir ein Beispiel für seine Verwendung.
- dm_exec_query_stats ist eine zusammenfassende Statistik der Ausführung von Abfragen. Es zeigt die Abfrage, die Anzahl ihrer Ausführungen und das Volumen der verbrauchten Ressourcen an.
Wichtige Hinweise
Die obige Liste ist nur ein kleiner Teil. Eine vollständige Liste aller Systemansichten und -funktionen ist in der Dokumentation beschrieben. Außerdem gibt es ein schönes Bild, das ein Diagramm der Verbindungen zwischen den Hauptobjekten zeigt.
Der Abfragetext, sein Plan und Ausführungsstatistiken sind Daten, die im Prozedurcache gespeichert werden. Sie sind während der Ausführung verfügbar. Dann ist die Verfügbarkeit nicht garantiert und hängt von der Cache-Auslastung ab. Ja, der Cache kann manuell bereinigt werden. Manchmal wird es empfohlen, wenn die Ausführungspläne „durchgeknallt“ sind. Dennoch gibt es viele Nuancen.
Das Feld „Befehl“ ist für Benutzeranfragen bedeutungslos, da wir den vollständigen Text erhalten können. Es ist jedoch sehr wichtig, um Informationen über Systemprozesse zu erhalten. In der Regel führen sie einige interne Aufgaben aus und haben keinen SQL-Text. Für solche Prozesse ist die Information über den Befehl der einzige Hinweis auf den Aktivitätstyp.
In den Kommentaren zum vorherigen Artikel wurde gefragt, woran der Server beteiligt ist, wenn er nicht funktionieren sollte. Die Antwort wird wahrscheinlich in der Bedeutung dieses Feldes liegen. In meiner Praxis lieferte das „command“-Feld immer etwas ganz Verständliches für aktive Systemprozesse:autoshrink / autogrow / checkpoint / logwriter / etc.
Verwendung
Wir gehen zum praktischen Teil. Ich werde einige Beispiele für seine Verwendung geben. Die Servermöglichkeiten sind nicht begrenzt – Sie können sich Ihre eigenen Beispiele ausdenken.
Beispiel 1. Welcher Prozess verbraucht CPU/Lesevorgänge/Schreibvorgänge/Speicher
Sehen Sie sich zunächst die Sitzungen an, die mehr Ressourcen verbrauchen, z. B. CPU. Sie finden diese Informationen möglicherweise in sys.dm_exec_sessions. Daten auf der CPU, einschließlich Lese- und Schreibvorgänge, sind jedoch kumulativ. Dies bedeutet, dass die Nummer die Gesamtzahl für die gesamte Verbindungszeit enthält. Es ist klar, dass der Benutzer, der sich vor einem Monat verbunden hat und nicht getrennt wurde, einen höheren Wert hat. Das bedeutet nicht, dass sie das System überlasten.
Ein Code mit dem folgenden Algorithmus kann dieses Problem lösen:
- Triff eine Auswahl und speichere sie in einer temporären Tabelle
- Warten Sie einige Zeit
- Triff zum zweiten Mal eine Auswahl
- Vergleichen Sie diese Ergebnisse. Ihre Differenz zeigt die in Schritt 2 aufgewendeten Kosten an.
- Der Einfachheit halber kann die Differenz durch die Dauer von Schritt 2 dividiert werden, um die durchschnittlichen „Kosten pro Sekunde“ zu erhalten.
if object_id('tempdb..#tmp') is NULL
BEGIN
SELECT * into #tmp from sys.dm_exec_sessions s
PRINT 'wait for a second to collect statistics at the first run '
-- we do not wait for the next launches, because we compare with the result of the previous launch
WAITFOR DELAY '00:00:01';
END
if object_id('tempdb..#tmp1') is not null drop table #tmp1
declare @d datetime
declare @dd float
select @d = crdate from tempdb.dbo.sysobjects where id=object_id('tempdb..#tmp')
select * into #tmp1 from sys.dm_exec_sessions s
select @dd=datediff(ms,@d,getdate())
select @dd AS [time interval, ms]
SELECT TOP 30 s.session_id, s.host_name, db_name(s.database_id) as db, s.login_name,s.login_time,s.program_name,
s.cpu_time-isnull(t.cpu_time,0) as cpu_Diff, convert(numeric(16,2),(s.cpu_time-isnull(t.cpu_time,0))/@dd*1000) as cpu_sec,
s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0) as totIO_Diff, convert(numeric(16,2),(s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0))/@dd*1000) as totIO_sec,
s.reads-isnull(t.reads,0) as reads_Diff, convert(numeric(16,2),(s.reads-isnull(t.reads,0))/@dd*1000) as reads_sec,
s.writes-isnull(t.writes,0) as writes_Diff, convert(numeric(16,2),(s.writes-isnull(t.writes,0))/@dd*1000) as writes_sec,
s.logical_reads-isnull(t.logical_reads,0) as logical_reads_Diff, convert(numeric(16,2),(s.logical_reads-isnull(t.logical_reads,0))/@dd*1000) as logical_reads_sec,
s.memory_usage, s.memory_usage-isnull(t.memory_usage,0) as [mem_D],
s.nt_user_name,s.nt_domain
from #tmp1 s
LEFT join #tmp t on s.session_id=t.session_id
order BY
cpu_Diff desc
--totIO_Diff desc
--logical_reads_Diff desc
drop table #tmp
GO
select * into #tmp from #tmp1
drop table #tmp1 Ich verwende zwei Tabellen im Code:#tmp – für die erste Auswahl und #tmp1 – für die zweite. Während der ersten Ausführung erstellt und füllt das Skript #tmp und #tmp1 in einem Sekundenintervall und führt dann andere Aufgaben aus. Bei den nächsten Durchläufen verwendet das Skript die Ergebnisse der vorherigen Ausführung als Vergleichsbasis. Daher entspricht die Dauer von Schritt 2 der Wartezeit zwischen den Skriptausführungen.
Versuchen Sie es auszuführen, sogar auf dem Produktionsserver. Das Skript erstellt nur „temporäre Tabellen“ (verfügbar in der aktuellen Sitzung und gelöscht, wenn deaktiviert) und hat keinen Thread.
Wer eine Abfrage nicht in MS SSMS ausführen möchte, kann sie in eine Anwendung einpacken, die in seiner bevorzugten Programmiersprache geschrieben ist. Ich zeige Ihnen, wie Sie dies in MS Excel ohne eine einzige Codezeile tun können.
Stellen Sie im Menü Daten eine Verbindung zum Server her. Wenn Sie aufgefordert werden, eine Tabelle auszuwählen, wählen Sie eine zufällige aus. Klicken Sie auf „Weiter“ und „Fertig stellen“, bis das Dialogfeld „Datenimport“ angezeigt wird. In diesem Fenster müssen Sie auf Eigenschaften klicken. In den Eigenschaften ist es notwendig, einen Befehlstyp durch den SQL-Wert zu ersetzen und unsere modifizierte Abfrage in das Befehlstextfeld einzufügen.
Sie müssen die Abfrage ein wenig modifizieren:
- Fügen Sie «SET NOCOUNT ON» hinzu
- Temporäre Tabellen durch variable Tabellen ersetzen
- Die Verzögerung dauert höchstens 1 Sekunde. Felder mit gemittelten Werten sind nicht erforderlich
Die modifizierte Abfrage für Excel
SET NOCOUNT ON;
declare @tmp table(session_id smallint primary key,login_time datetime,host_name nvarchar(256),program_name nvarchar(256),login_name nvarchar(256),nt_user_name nvarchar(256),cpu_time int,memory_usage int,reads bigint,writes bigint,logical_reads bigint,database_id smallint)
declare @d datetime;
select @d=GETDATE()
INSERT INTO @tmp(session_id,login_time,host_name,program_name,login_name,nt_user_name,cpu_time,memory_usage,reads,writes,logical_reads,database_id)
SELECT session_id,login_time,host_name,program_name,login_name,nt_user_name,cpu_time,memory_usage,reads,writes,logical_reads,database_id
from sys.dm_exec_sessions s;
WAITFOR DELAY '00:00:01';
declare @dd float;
select @dd=datediff(ms,@d,getdate());
SELECT
s.session_id, s.host_name, db_name(s.database_id) as db, s.login_name,s.login_time,s.program_name,
s.cpu_time-isnull(t.cpu_time,0) as cpu_Diff,
s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0) as totIO_Diff,
s.reads-isnull(t.reads,0) as reads_Diff,
s.writes-isnull(t.writes,0) as writes_Diff,
s.logical_reads-isnull(t.logical_reads,0) as logical_reads_Diff,
s.memory_usage, s.memory_usage-isnull(t.memory_usage,0) as [mem_Diff],
s.nt_user_name,s.nt_domain
from sys.dm_exec_sessions s
left join @tmp t on s.session_id=t.session_id Ergebnis:
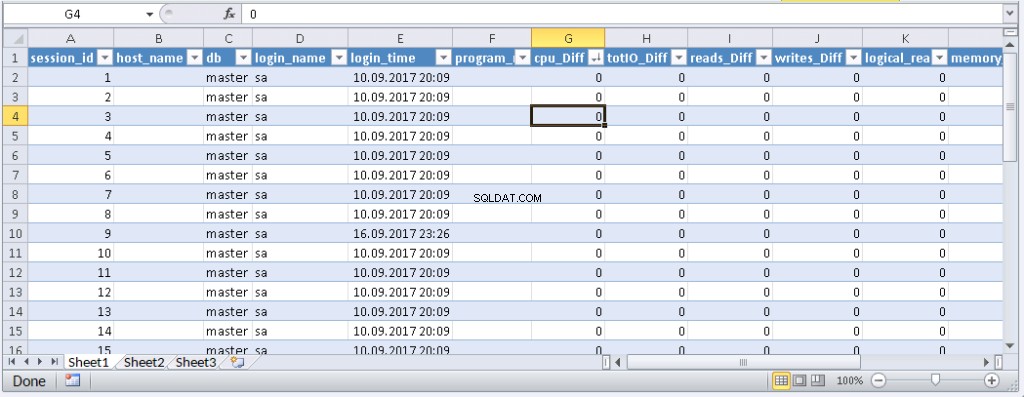
Wenn Daten in Excel angezeigt werden, können Sie sie nach Bedarf sortieren. Um die Informationen zu aktualisieren, klicken Sie auf „Aktualisieren“. In den Arbeitsmappeneinstellungen können Sie „automatische Aktualisierung“ in einem bestimmten Zeitraum und „beim Start aktualisieren“ festlegen. Sie können die Datei speichern und an Ihre Kollegen weitergeben. Daher haben wir ein praktisches und einfaches Tool geschaffen.
Beispiel 2. Wofür verbraucht eine Sitzung Ressourcen?
Jetzt werden wir feststellen, was die Problemsitzungen tatsächlich bewirken. Verwenden Sie dazu sys.dm_exec_requests und Funktionen, um Abfragetext und Abfrageplan zu erhalten.
Der Abfrage- und Ausführungsplan nach Sitzungsnummer
DECLARE @sql_handle varbinary(64) DECLARE @plan_handle varbinary(64) DECLARE @sid INT Declare @statement_start_offset int, @statement_end_offset INT, @session_id SMALLINT -- for the information by a particular user – indicate a session number SELECT @sid=182 -- receive state variables for further processing IF @sid IS NOT NULL SELECT @sql_handle=der.sql_handle, @plan_handle=der.plan_handle, @statement_start_offset=der.statement_start_offset, @statement_end_offset=der.statement_end_offset, @session_id = der.session_id FROM sys.dm_exec_requests der WHERE example@sqldat.com -- print the text of the query being executed DECLARE @txt VARCHAR(max) IF @sql_handle IS NOT NULL SELECT @txt=[text] FROM sys.dm_exec_sql_text(@sql_handle) PRINT @txt -- output the plan of the batch/procedure being executed IF @plan_handle IS NOT NULL select * from sys.dm_exec_query_plan(@plan_handle) -- and the plan of the query being executed within the batch/procedure IF @plan_handle IS NOT NULL SELECT dbid, objectid, number, encrypted, CAST(query_plan AS XML) AS planxml from sys.dm_exec_text_query_plan(@plan_handle, @statement_start_offset, @statement_end_offset)
Fügen Sie die Sitzungsnummer in die Abfrage ein und führen Sie sie aus. After execution, there will be plans on the Results tab (the first one is for the whole query, and the second one is for the current step if there are several steps in the query) and the query text on the Messages tab. To view the plan, you need to click the text that looks like the URL in the row. The plan will be opened in a separate tab. Sometimes, it happens that the plan is opened not in a graphical form, but in the form of XML-text. This may happen because the MS SSMS version is lower than the server. Delete the “Version” and “Build” from the first row and then save the result XML to a file with the .sqlplan extension. After that, open it separately. If this does not help, I remind you that the 2016 studio is officially available for free on the MS website.
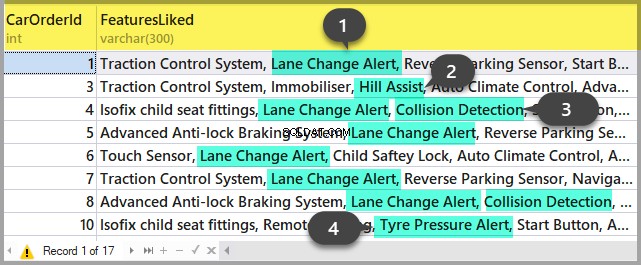
It is obvious that the result plan will be an estimated one, as the query is being executed. Still, it is possible to receive some execution statistics. To do this, use the sys.dm_exec_query_stats view with the filter by our handles.
Add this information at the end of the previous query
-- plan statistics IF @sql_handle IS NOT NULL SELECT * FROM sys.dm_exec_query_stats QS WHERE example@sqldat.com_handle
As a result, we will get the information about the steps of the executed query:how many times they were executed and what resources were spent. This information is added to the statistics only after the execution process is completed. The statistics are not tied to the user but are maintained within the whole server. If different users execute the same query, the statistics will be total for all users.
Example 3. Can I see all of them?
Let’s combine the system views we considered with the functions in one query. It can be useful for evaluating the whole situation.
-- receive a list of all current queries SELECT LEFT((SELECT [text] FROM sys.dm_exec_sql_text(der.sql_handle)),500) AS txt --,(select top 1 1 from sys.dm_exec_query_profiles where session_id=der.session_id) as HasLiveStat ,der.blocking_session_id as blocker, DB_NAME(der.database_id) AS База, s.login_name, * from sys.dm_exec_requests der left join sys.dm_exec_sessions s ON s.session_id = der.session_id WHERE der.session_id<>@@SPID -- AND der.session_id>50
The query outputs a list of active sessions and texts of their queries. For system processes, usually, there is no query; however, the command field is filled up. You can see the information about blocks and waits, and mix this query with example 1 in order to sort by the load. Still, be careful, query texts may be large. Their massive selection can be resource-intensive and lead to a huge traffic increase. In the example, I limited the result query to the first 500 characters but did not execute the plan.
Schlussfolgerung
It would be great to get Live Query Statistics for an arbitrary session. According to the manufacturer, now, monitoring statistics requires many resources and therefore, it is disabled by default. Its enabling is not a problem, but additional manipulations complicate the process and reduce the practical benefit.
In this article, we analyzed user activity in the following ways:using possibilities MS SSMS, profiler, direct calls to system views. All these methods allow estimating costs on executing a query and getting the execution plan. Each method is suitable for a particular situation. Thus, the best solution is to combine them.