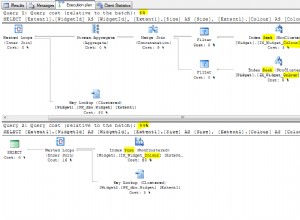
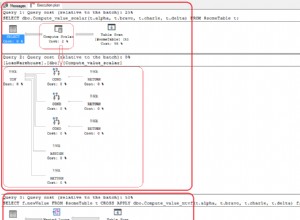
Um die Zeile aus dem Ergebnis wegzulassen falls einer der Quelle Zeilen für die gleiche id hat value IS NULL , eine Lösung in Postgres wäre die Verwendung der Aggregatfunktion every()
oder (Synonym aus historischen Gründen) bool_and()
im HAVING Klausel:
SELECT id
, max(case when colID = 1 then value else '' end) AS fn
, max(case when colID = 2 then value else '' end) AS ln
, max(case when colID = 3 then value else '' end) AS jt
FROM tbl
GROUP BY id
HAVING every(value IS NOT NULL);Erklären
Ihr Versuch mit einem WHERE -Klausel würde nur eine eliminieren Quellzeile für id = 3 in Ihrem Beispiel (das mit colID = 1 ), sodass zwei weitere für dieselbe id übrig bleiben . Wir erhalten also immer noch eine Zeile für id = 3 im Ergebnis nach der Aggregation.
Da wir aber keine Zeile mit colID = 1 haben , erhalten wir einen leeren String (Achtung:kein NULL Wert!) für fn im Ergebnis für id = 3 .
Eine schnellere Lösung in Postgres wäre die Verwendung von crosstab() . Einzelheiten:
Andere RDBMS
Während EVERY im SQL:2008-Standard definiert ist, wird es von vielen RDBMS nicht unterstützt, vermutlich weil einige von ihnen zwielichtige Implementierungen des booleschen Typs haben. (Keine Namen wie "MySQL" oder "Oracle" fallen lassen ...). Sie können wahrscheinlich überall (einschließlich Postgres) ersetzen mit:
SELECT id
, max(case when colID = 1 then value else '' end) AS fn
, max(case when colID = 2 then value else '' end) AS ln
, max(case when colID = 3 then value else '' end) AS jt
FROM tbl
GROUP BY id
HAVING count(*) = count(value);
Weil count() zählt keine NULL-Werte. In MySQL gibt es auch bit_and()
.Mehr unter dieser verwandten Frage: