Wenn es eine Möglichkeit gibt, Lebensmittel online zu bestellen, warum nicht? Dieser Artikel untersucht das Datenmodell hinter dem Liefersystem eines Lebensmittelgeschäfts.
Etwas aus dem Garten zu pflücken und dann gleich zuzubereiten, ist für uns immer noch ein besonderes Gefühl – aber das können wir nicht oft. Die heutige Schnelllebigkeit lässt das nicht zu. Tatsächlich erlaubt es uns manchmal nicht einmal, in den Laden zu gehen, um unsere Lebensmittel „auszusuchen“. Da macht es Sinn, sich etwas Zeit zu sparen und per App zu bestellen, was man braucht. Unsere Bestellung wird einfach bei uns zu Hause auftauchen. Vielleicht bekommen wir nicht das besondere Frischgepflückt-Gefühl, aber es wird Essen auf unserem Tisch geben.
Das Datenmodell hinter einer solchen Anwendung ist Thema des heutigen Artikels.
Was brauchen wir für ein Datenmodell für Lebensmittellieferungen?
Die Idee dieses Modells ist, dass eine Anwendung (Web, Handy oder beides) es registrierten Kunden ermöglicht, eine Bestellung (bestehend aus Produkten aus unserem Shop) zu erstellen. Dann wird diese Bestellung an den Kunden ausgeliefert. Wir werden selbstverständlich Kundendaten und eine Liste aller verfügbaren Produkte speichern, um dies zu unterstützen.
Kunden können mehrere Bestellungen aufgeben, die verschiedene Artikel in unterschiedlichen Mengen enthalten. Wenn eine Kundenbestellung eingeht, sollten die Filialmitarbeiter benachrichtigt werden, damit sie die benötigten Artikel finden und verpacken können. (Dies kann einen oder mehrere Container erfordern.) Schließlich werden die Container entweder zusammen oder getrennt geliefert.
In der App selbst sollen Kunden und Mitarbeiter nach erfolgter Lieferung Notizen einfügen und das Gegenüber bewerten können.
Das Datenmodell
Das Datenmodell besteht aus drei Themenbereichen:
Items & unitsCustomers & employeesOrders
Wir präsentieren jeden Themenbereich in der Reihenfolge, in der er aufgeführt ist.
Abschnitt 1:Gegenstände und Einheiten
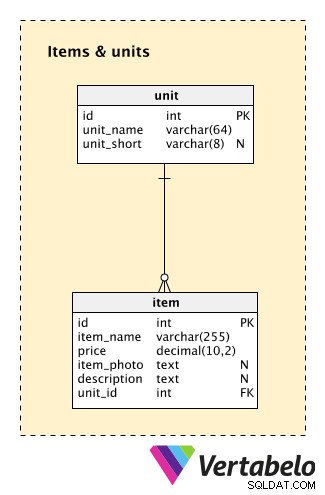
Wir beginnen mit den Items & units Fachbereich. Obwohl es sich um einen kleinen Teil unseres Modells handelt, enthält es zwei sehr wichtige Tabellen.
Die unit Tabelle speichert Informationen über die Einheiten, die wir jedem Artikel in unserem Inventar zuweisen. Für jeden Wert in dieser Tabelle speichern wir zwei UNIQUE-Werte:unit_name (zB „Kilogramm“) und unit_short (zB „kg“). Beachten Sie, dass unit_short ist die Abkürzung für unit_name .
Die zweite Tabelle in diesem Themenbereich ist item . Es listet alle Artikel auf, die wir auf Lager haben. Für jeden Artikel speichern wir:
item_name– Der EINZIGARTIGE Name, den wir für diesen Artikel verwenden werden.price– Der aktuelle Preis dieses Artikels.item_photo– Ein Link zu einem Foto dieses Artikels.description– Zusätzliche Textbeschreibung des Artikels.unit_id– Referenziert dieunitWörterbuch und bezeichnet die Einheit, die zum Messen dieses Elements verwendet wird.
Bitte beachten Sie, dass ich hier einige Dinge weggelassen habe. Das wichtigste ist ein Flag, das angibt, ob ein Inventarartikel derzeit zum Verkauf angeboten wird. Warum haben wir das nicht? Es würde mindestens ein zusätzliches Feld (das Flag) sowie eine weitere Tabelle (um historische Änderungen für jedes Element zu speichern) erfordern. Der Einfachheit halber bin ich davon ausgegangen, dass alle Artikel, die wir auf Lager haben, auch zum Verkauf angeboten werden.
Die zweite wichtige Sache, die ich ausgelassen habe, ist die Verfolgung des Lagerstatus. Ich gehe davon aus, dass wir alles aus einem zentralen Lager versenden und immer verfügbare Artikel haben. Wenn wir einen Artikel nicht haben, benachrichtigen wir den Kunden einfach und bieten ihm einen ähnlichen Artikel als Ersatz an.
Abschnitt 2:Kunden und Mitarbeiter

Die Customers & employees Der Themenbereich enthält alle Tabellen, die zum Speichern von Kunden- und Mitarbeiterdaten erforderlich sind. Wir verwenden diese Informationen im zentralen Teil unseres Modells.
Der employee Tabelle enthält eine Liste aller relevanten Mitarbeiter (z. B. die Lebensmittelpacker und die Zusteller). Für jeden Mitarbeiter speichern wir seinen first_name und last_name und einen EINZIGARTIGEN employee_code Wert. Obwohl die ID-Spalte ebenfalls EINZIGARTIG ist (und der Primärschlüssel dieser Tabelle), ist es besser, einen anderen, realen Wert (z. B. eine Umsatzsteuer-Identifikationsnummer) als Mitarbeiterkennung zu verwenden. Somit haben wir den employee_code Feld.
Beachten Sie, dass ich keine Mitarbeiter-Anmeldedaten, Mitarbeiterrollen und eine Möglichkeit zum Verfolgen des Rollenverlaufs eingefügt habe. Diese können einfach hinzugefügt werden, wie in diesem Artikel beschrieben.
Jetzt fügen wir Kunden zu unserem Modell hinzu. Dies erfordert zwei weitere Tabellen.
Die Kunden werden geografisch segmentiert, daher benötigen wir eine city Wörterbuch. Für jede Stadt, in der wir Lebensmittellieferungen anbieten, speichern wir den city_name und die postal_code . Zusammen bilden diese den alternativen Schlüssel dieser Tabelle.
Kunden sind definitiv der wichtigste Teil dieses Modells; Sie sind diejenigen, die den gesamten Prozess initiieren. Wir speichern eine vollständige Liste unserer Kunden im customer Tisch. Für jeden Kunden speichern wir Folgendes:
first_name– Der Vorname des Kunden.last_name– Der Nachname des Kunden.user_name– Der Benutzername, den der Kunde bei der Einrichtung seines Kontos gewählt hat.password– Das Passwort, das der Kunde bei der Einrichtung seines Kontos gewählt hat.time_inserted– Der Moment, in dem dieser Datensatz in die Datenbank eingefügt wurde.confirmation_code– Ein Code, der während des Registrierungscodes generiert wurde. Dieser Code wird verwendet, um ihre E-Mail-Adresse zu bestätigen.time_confirmed– Wann die E-Mail-Bestätigung stattgefunden hat.contact_email– Die E-Mail-Adresse des Kunden, die auch als Bestätigungs-E-Mail verwendet wird.contact_phone– Die Telefonnummer des Kunden.city_id– Die ID dercitywo der Kunde wohnt.address– Die Privatadresse des Kunden.delivery_city_id– Die ID dercitywohin die Bestellung des Kunden geliefert werden soll.delivery_address– Die bevorzugte Lieferadresse. Beachten Sie, dass dies mit der Privatadresse des Kunden übereinstimmen kann (aber nicht sein muss).
Abschnitt 3:Bestellungen
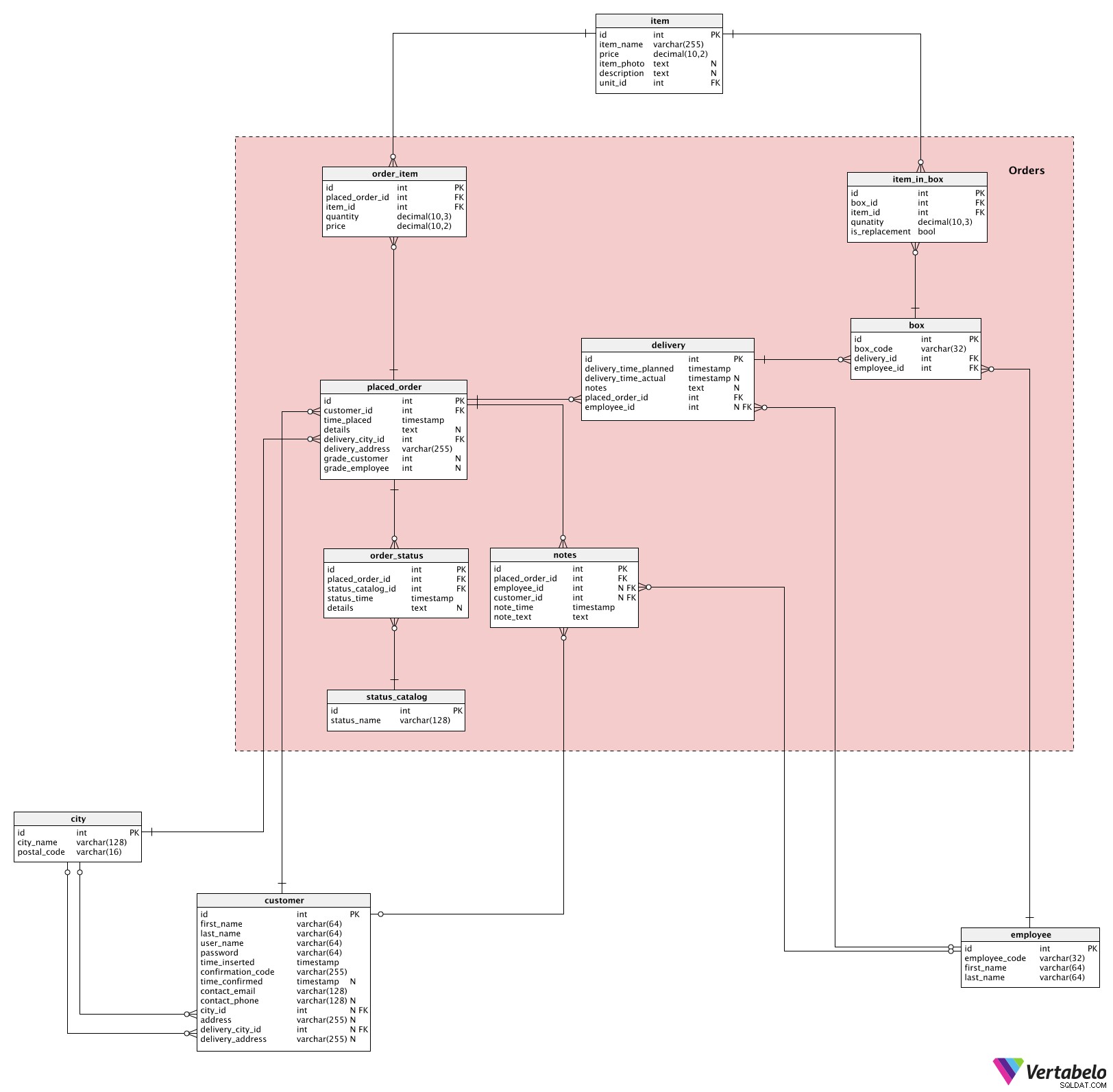
Der zentrale und wichtigste Teil dieses Modells sind die Orders Fachbereich. Hier finden wir alle Tabellen, die benötigt werden, um eine Bestellung aufzugeben und Artikel zu verfolgen, bis sie an Kunden geliefert werden.
Der gesamte Prozess beginnt, wenn ein Kunde eine Bestellung aufgibt. Eine Liste aller jemals aufgegebenen Bestellungen befindet sich im placed_order Tisch. Ich habe absichtlich diesen Namen und nicht „order“ verwendet, da order ein von SQL reserviertes Schlüsselwort ist. Für jede Bestellung speichern wir:
customer_id– Die ID descustomerdie diese Bestellung aufgegeben haben.time_placed– Der Zeitstempel, zu dem diese Bestellung aufgegeben wurde.details– Alle Details zu dieser Bestellung in unstrukturiertem Textformat.delivery_city_id– Ein Verweis auf diecitywohin diese Bestellung geliefert werden soll.delivery_address– Die Adresse, an die diese Bestellung geliefert werden soll.grade_customer&grade_employee– Noten, die der Mitarbeiter und der Kunde nach Abschluss eines Auftrags vergeben. Bis zu diesem Moment enthält dieses Attribut einen NULL-Wert. Die Note eines Kunden zeigt an, wie zufrieden er mit unserem Service war; Die Note eines Mitarbeiters gibt uns Aufschluss darüber, was uns erwartet, wenn dieser Kunde das nächste Mal eine Bestellung aufgibt.
Während des Bestellvorgangs wählt ein Kunde einen oder mehrere Artikel aus. Für jeden Artikel definieren sie eine gewünschte Menge. Eine Liste aller Artikel zu jeder Bestellung wird im order_item Tisch. Für jeden Datensatz in dieser Tabelle speichern wir IDs für die zugehörige Bestellung (placed_order_id ), Artikel (item_id ), die gewünschte Menge und den price wann diese Bestellung aufgegeben wurde.
Zusätzlich zu was sie geliefert haben möchten, definieren die Kunden auch ihre gewünschte Lieferzeit . Für jede Bestellung erstellen wir einen Datensatz im delivery Tisch. Dadurch wird die delivery_time_planned aufgezeichnet und fügen Sie zusätzliche Textnotizen ein. Die placed_order_id Attribut wird ebenfalls definiert, wenn dieser Datensatz eingefügt wird. Die verbleibenden zwei Attribute werden definiert, wenn wir diese Lieferung einem Mitarbeiter zuweisen (employee_id ) und wann die Bestellung geliefert wurde (delivery_time_actual ).
Auch wenn es so aussieht, als hätten wir nur eine Lieferung pro Bestellung, ist dies möglicherweise nicht immer der Fall. Wir müssen möglicherweise zwei oder mehr Lieferungen pro Bestellung ausführen, und das ist der Hauptgrund, warum ich mich dafür entschieden habe, die Lieferdaten in eine neue Tabelle aufzunehmen.
Wenn wir mit der Bearbeitung einer Bestellung beginnen, packen die Mitarbeiter die Artikel in einen oder mehrere Kartons. Jedes box wird EINZIGARTIG durch seinen box_code definiert und wird einer Lieferung zugeordnet (delivery_id ). Wir speichern auch die ID des Mitarbeiters, der diese Box vorbereitet hat.
Jede Box enthält einen oder mehrere Artikel. Daher im item_in_box Tabelle müssen wir Verweise auf box Tabelle (box_id ) und das item Tabelle (item_id ) sowie die Menge, die in dieses Feld gelegt wird. Das letzte Attribut, is_replacement , gibt an, ob ein Artikel ein Ersatz für einen anderen Artikel ist. Wir können davon ausgehen, dass ein Mitarbeiter einen Kunden kontaktiert, bevor er einen Ersatzartikel in eine Kiste legt. Ein Ergebnis dieser Aktion könnte sein, dass ein Kunde mit dem Ersatzartikel einverstanden ist; eine andere könnte die Stornierung der gesamten Bestellung sein.
Die verbleibenden drei Tabellen im Modell sind eng mit Status und Kommentaren verknüpft.
Zunächst speichern wir alle möglichen Status im status_catalog . Jeder Status wird EINZIGARTIG durch seinen status_name definiert . Wir können Status wie „Bestellung erstellt“, „Bestellung aufgegeben“, „Artikel verpackt“, „im Transport“ und „geliefert“ erwarten.
Status werden Bestellungen entweder automatisch (nachdem einige Teile des Prozesses abgeschlossen sind) oder in einigen Fällen manuell zugewiesen (z. B. wenn es ein Problem mit der Bestellung gibt). Alle verfügbaren Bestellstatus werden im order_status Tisch. Neben Fremdschlüsseln aus zwei Tabellen (status_catalog und placed_order ), speichern wir den tatsächlichen Zeitstempel, als dieser Status zugewiesen wurde (status_time ) und weitere details im Textformat.
Die letzte Tabelle in diesem Modell sind die notes Tisch. Die Idee hinter dieser Tabelle ist, alle zusätzlichen Kommentare zu einer bestimmten Bestellung einzufügen (placed_order_id ). Kommentare können von Mitarbeitern oder Kunden eingefügt werden. Für jeden Datensatz nur eine der employee_id oder customer_id Felder enthalten einen Wert; der andere wird NULL sein. Wir speichern den Zeitpunkt, an dem diese Notiz in das System eingefügt wurde (note_time ) und den note_text .
Welche Änderungen würden Sie am Datenmodell für Lebensmittellieferungen vornehmen?
Heute haben wir ein Datenmodell besprochen, das Web- und mobile Lebensmittelliefer-Apps unterstützen könnte – sowohl aus Kunden- als auch aus Mitarbeitersicht. Wie bereits in diesem Artikel erwähnt, gibt es viele Möglichkeiten, dieses Modell zu verbessern. Fühlen Sie sich frei, Ihre Vorschläge hinzuzufügen. Sagen Sie uns, was Sie zu diesem Modell hinzufügen oder daraus entfernen würden. Oder vielleicht würden Sie diese Struktur ganz anders organisieren. Lass es uns im Kommentarbereich wissen!