In diesem Artikel bauen wir einen Schaber für einen tatsächlichen freiberuflicher Gig, bei dem der Kunde möchte, dass ein Python-Programm Daten aus Stack Overflow kratzt, um neue Fragen (Fragetitel und URL) zu erhalten. Gescrapte Daten sollten dann in MongoDB gespeichert werden. Es ist erwähnenswert, dass Stack Overflow eine API hat, die verwendet werden kann, um auf das exakte zuzugreifen gleichen Daten. Der Kunde wollte jedoch einen Schaber, also bekam er einen Schaber.
Kostenloser Bonus: Klicken Sie hier, um ein Python + MongoDB-Projektskelett mit vollständigem Quellcode herunterzuladen, der Ihnen zeigt, wie Sie von Python aus auf MongoDB zugreifen.
Aktualisierungen:
- 03.01.2014 - Überarbeitung der Spinne. Danke, @kissgyorgy.
- 18.02.2015 – Teil 2 hinzugefügt.
- 06.09.2015 - Aktualisiert auf die neueste Version von Scrapy und PyMongo - Prost!
Lesen Sie wie immer die Nutzungsbedingungen/Servicebedingungen der Website und respektieren Sie die robots.txt Datei, bevor Sie einen Scraping-Job starten. Stellen Sie sicher, dass Sie sich an ethische Scraping-Praktiken halten, indem Sie die Website nicht über einen kurzen Zeitraum mit zahlreichen Anfragen überfluten. Behandle jede Website, die du kratzt, als wäre es deine eigene .
Installation
Wir benötigen die Scrapy-Bibliothek (v1.0.3) zusammen mit PyMongo (v3.0.3) zum Speichern der Daten in MongoDB. Sie müssen auch MongoDB installieren (nicht abgedeckt).
Scheiße
Wenn Sie OSX oder eine Linux-Variante ausführen, installieren Sie Scrapy mit pip (mit aktivierter virtueller Umgebung):
$ pip install Scrapy==1.0.3
$ pip freeze > requirements.txt
Wenn Sie sich auf einem Windows-Computer befinden, müssen Sie eine Reihe von Abhängigkeiten manuell installieren. Detaillierte Anweisungen finden Sie in der offiziellen Dokumentation sowie in diesem von mir erstellten Youtube-Video.
Sobald Scrapy eingerichtet ist, überprüfen Sie Ihre Installation, indem Sie diesen Befehl in der Python-Shell ausführen:
>>>>>> import scrapy
>>>
Wenn Sie keine Fehlermeldung erhalten, können Sie loslegen!
PyMongo
Als nächstes installieren Sie PyMongo mit pip:
$ pip install pymongo
$ pip freeze > requirements.txt
Jetzt können wir mit dem Bau des Crawlers beginnen.
Scrapy-Projekt
Starten wir ein neues Scrapy-Projekt:
$ scrapy startproject stack
2015-09-05 20:56:40 [scrapy] INFO: Scrapy 1.0.3 started (bot: scrapybot)
2015-09-05 20:56:40 [scrapy] INFO: Optional features available: ssl, http11
2015-09-05 20:56:40 [scrapy] INFO: Overridden settings: {}
New Scrapy project 'stack' created in:
/stack-spider/stack
You can start your first spider with:
cd stack
scrapy genspider example example.com
Dadurch werden eine Reihe von Dateien und Ordnern erstellt, die eine grundlegende Boilerplate enthalten, damit Sie schnell loslegen können:
├── scrapy.cfg
└── stack
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
Daten angeben
Die items.py Datei wird verwendet, um Speicher-„Container“ für die Daten zu definieren, die wir zu scrapen planen.
Das StackItem() Klasse erbt von Item (docs), das im Grunde eine Reihe vordefinierter Objekte enthält, die Scrapy bereits für uns erstellt hat:
import scrapy
class StackItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
Lassen Sie uns einige Gegenstände hinzufügen, die wir tatsächlich sammeln möchten. Für jede Frage benötigt der Kunde den Titel und die URL. Aktualisieren Sie also items.py so:
from scrapy.item import Item, Field
class StackItem(Item):
title = Field()
url = Field()
Erstelle die Spinne
Erstellen Sie eine Datei namens stack_spider.py im Verzeichnis „spiders“. Hier passiert die Magie – z. B. wo wir Scrapy sagen, wie man das genaue findet Daten, nach denen wir suchen. Wie Sie sich vorstellen können, ist dies spezifisch zu jeder einzelnen Webseite, die Sie scrapen möchten.
Beginnen Sie mit der Definition einer Klasse, die von Scrapys Spider erbt und dann nach Bedarf Attribute hinzufügen:
from scrapy import Spider
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
Die ersten paar Variablen sind selbsterklärend (docs):
namedefiniert den Namen der Spinne.allowed_domainsenthält die Basis-URLs für die erlaubten Domains, die der Spider crawlen kann.start_urlsist eine Liste von URLs, von denen aus der Spider mit dem Crawlen beginnen kann. Alle nachfolgenden URLs beginnen mit den Daten, die der Spider von den URLs instart_urlsherunterlädt .
XPath-Selektoren
Als nächstes verwendet Scrapy XPath-Selektoren, um Daten von einer Website zu extrahieren. Mit anderen Worten, wir können bestimmte Teile der HTML-Daten basierend auf einem gegebenen XPath auswählen. Wie in Scrapys Dokumentation angegeben, „ist XPath eine Sprache zur Auswahl von Knoten in XML-Dokumenten, die auch mit HTML verwendet werden kann.“
Mit den Entwicklertools von Chrome können Sie ganz einfach einen bestimmten Xpath finden. Untersuchen Sie einfach ein bestimmtes HTML-Element, kopieren Sie den XPath und optimieren Sie ihn (nach Bedarf):
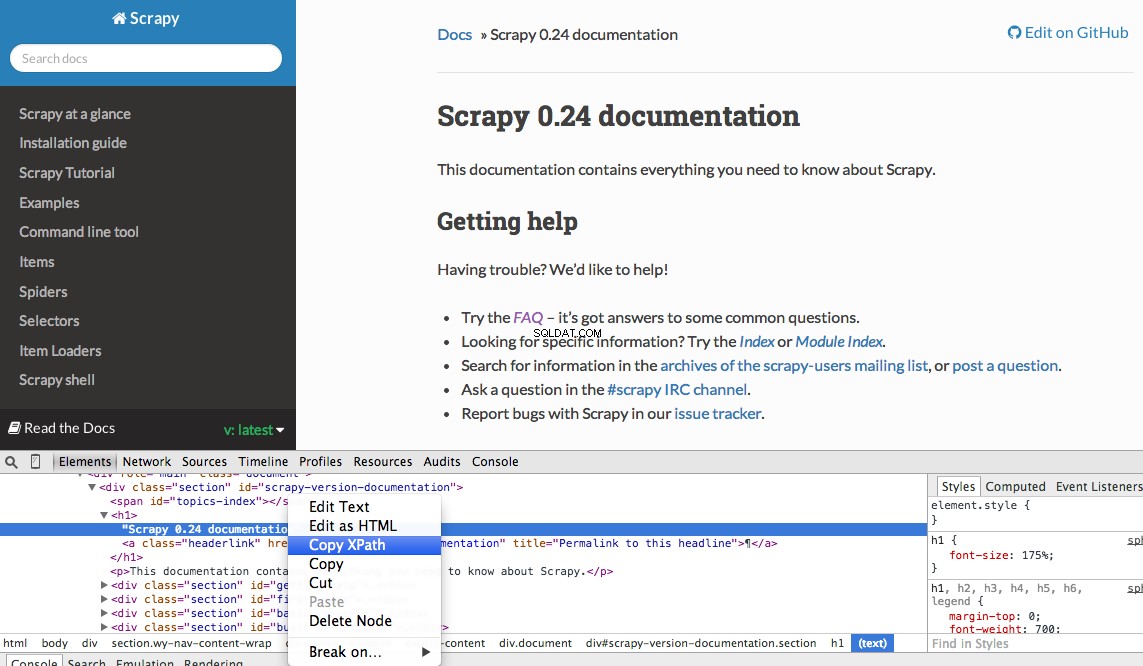
Developer Tools gibt Ihnen auch die Möglichkeit, XPath-Selektoren in der JavaScript-Konsole zu testen, indem Sie $x verwenden - also $x("//img") :
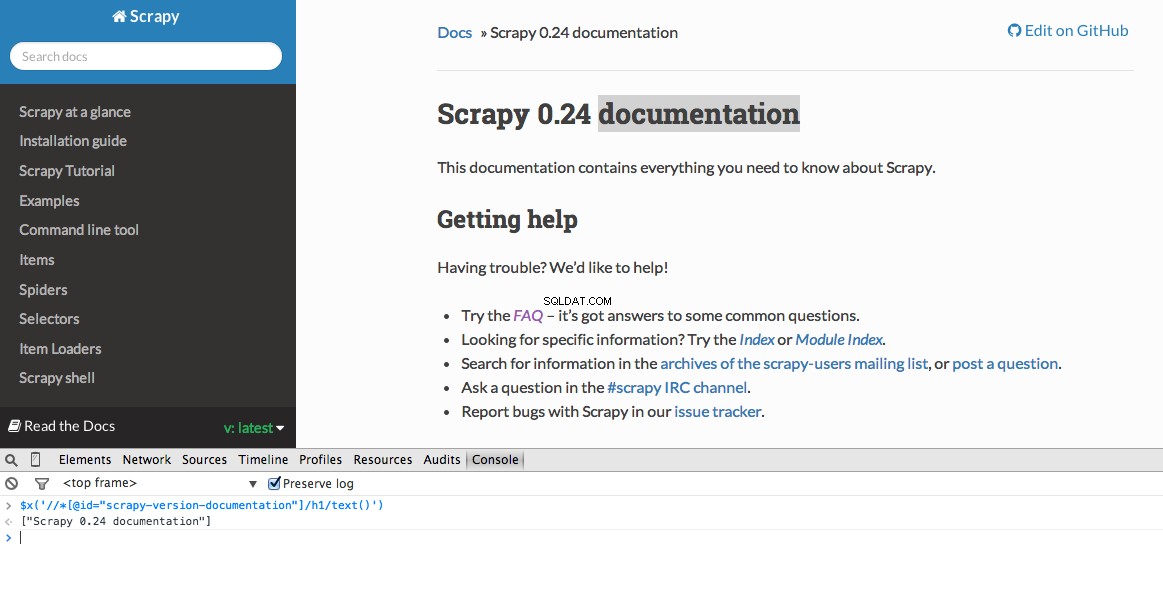
Auch hier teilen wir Scrapy grundsätzlich mit, wo es mit der Suche nach Informationen basierend auf einem definierten XPath beginnen soll. Navigieren wir zur Stack Overflow-Site in Chrome und suchen Sie die XPath-Selektoren.
Klicken Sie mit der rechten Maustaste auf die erste Frage und wählen Sie „Inspect Element“:
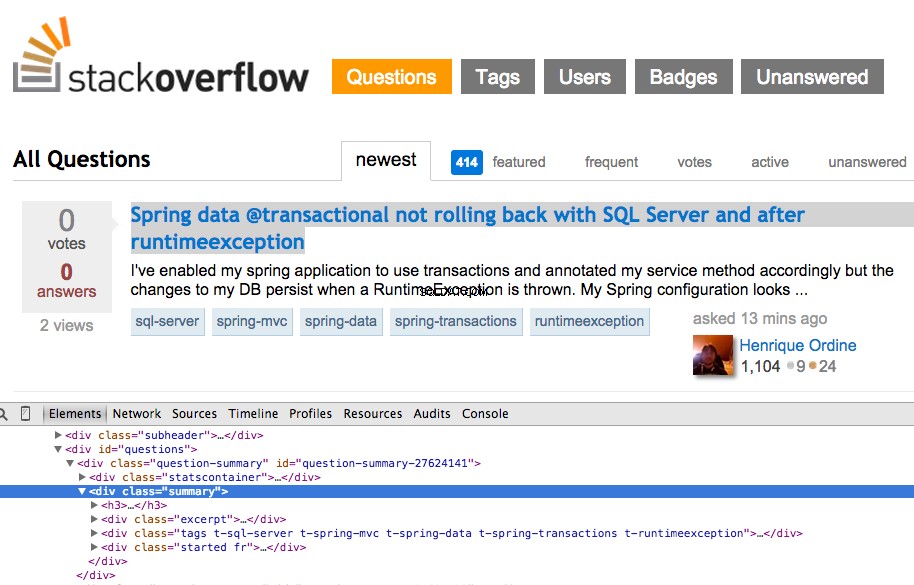
Holen Sie sich jetzt den XPath für <div class="summary"> , //*[@id="question-summary-27624141"]/div[2] , und testen Sie es dann in der JavaScript-Konsole:
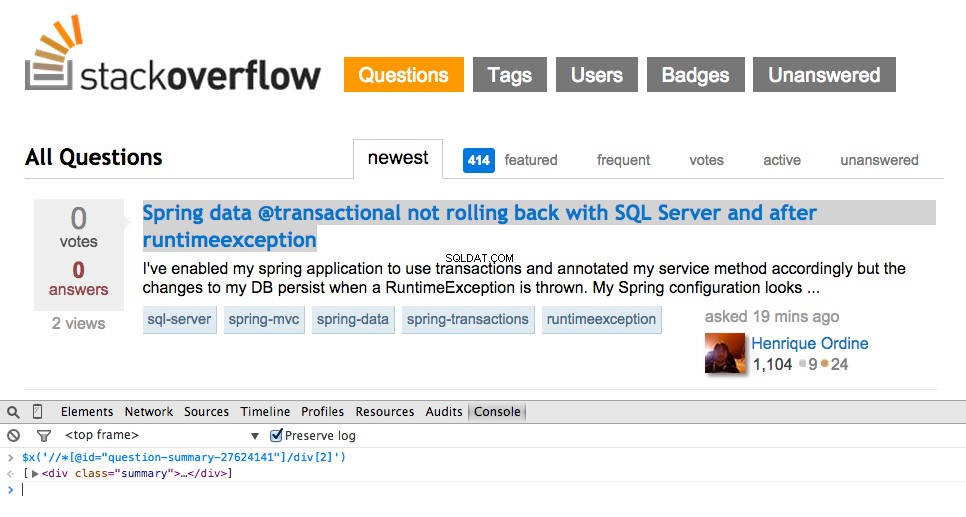
Wie Sie sehen können, wird nur eine ausgewählt Frage. Also müssen wir den XPath ändern, um alle zu erfassen Fragen. Irgendwelche Ideen? Ganz einfach://div[@class="summary"]/h3 . Was bedeutet das? Im Wesentlichen besagt dieser XPath:Greife alle <h3> Elemente, die untergeordnete Elemente von <div> sind die eine Klasse von summary hat . Testen Sie diesen XPath in der JavaScript-Konsole.
Beachten Sie, dass wir nicht die tatsächliche XPath-Ausgabe von Chrome Developer Tools verwenden. In den meisten Fällen ist die Ausgabe nur eine hilfreiche Beilage, die Sie im Allgemeinen in die richtige Richtung weist, um den funktionierenden XPath zu finden.
Jetzt aktualisieren wir die stack_spider.py Skript:
from scrapy import Spider
from scrapy.selector import Selector
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')
Extrahieren Sie die Daten
Wir müssen die gewünschten Daten noch parsen und kratzen, was in <div class="summary"><h3> fällt . Aktualisieren Sie erneut stack_spider.py so:
from scrapy import Spider
from scrapy.selector import Selector
from stack.items import StackItem
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')
for question in questions:
item = StackItem()
item['title'] = question.xpath(
'a[@class="question-hyperlink"]/text()').extract()[0]
item['url'] = question.xpath(
'a[@class="question-hyperlink"]/@href').extract()[0]
yield item
````
We are iterating through the `questions` and assigning the `title` and `url` values from the scraped data. Be sure to test out the XPath selectors in the JavaScript Console within Chrome Developer Tools - e.g., `$x('//div[@class="summary"]/h3/a[@class="question-hyperlink"]/text()')` and `$x('//div[@class="summary"]/h3/a[@class="question-hyperlink"]/@href')`.
## Test
Ready for the first test? Simply run the following command within the "stack" directory:
```console
$ scrapy crawl stack
Zusammen mit dem Scrapy-Stack-Trace sollten 50 Fragetitel und URLs ausgegeben werden. Mit diesem kleinen Befehl können Sie die Ausgabe in eine JSON-Datei rendern:
$ scrapy crawl stack -o items.json -t json
Wir haben jetzt unseren Spider basierend auf unseren gesuchten Daten implementiert. Jetzt müssen wir die gekratzten Daten in MongoDB speichern.
Speichern Sie die Daten in MongoDB
Jedes Mal, wenn ein Artikel zurückgegeben wird, möchten wir die Daten validieren und ihn dann zu einer Mongo-Sammlung hinzufügen.
Der erste Schritt besteht darin, die Datenbank zu erstellen, die wir verwenden möchten, um alle unsere gecrawlten Daten zu speichern. Öffnen Sie settings.py und spezifizieren Sie die Pipeline und fügen Sie die Datenbankeinstellungen hinzu:
ITEM_PIPELINES = ['stack.pipelines.MongoDBPipeline', ]
MONGODB_SERVER = "localhost"
MONGODB_PORT = 27017
MONGODB_DB = "stackoverflow"
MONGODB_COLLECTION = "questions"
Pipeline-Management
Wir haben unsere Spinne so eingerichtet, dass sie den HTML-Code durchsucht und analysiert, und wir haben unsere Datenbankeinstellungen eingerichtet. Jetzt müssen wir die beiden durch eine Pipeline in pipelines.py miteinander verbinden .
Mit Datenbank verbinden
Lassen Sie uns zunächst eine Methode definieren, um tatsächlich eine Verbindung zur Datenbank herzustellen:
import pymongo
from scrapy.conf import settings
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
Hier erstellen wir eine Klasse, MongoDBPipeline() , und wir haben eine Konstruktorfunktion, um die Klasse zu initialisieren, indem wir die Mongo-Einstellungen definieren und dann eine Verbindung zur Datenbank herstellen.
Daten verarbeiten
Als nächstes müssen wir eine Methode definieren, um die geparsten Daten zu verarbeiten:
import pymongo
from scrapy.conf import settings
from scrapy.exceptions import DropItem
from scrapy import log
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
def process_item(self, item, spider):
valid = True
for data in item:
if not data:
valid = False
raise DropItem("Missing {0}!".format(data))
if valid:
self.collection.insert(dict(item))
log.msg("Question added to MongoDB database!",
level=log.DEBUG, spider=spider)
return item
Wir stellen eine Verbindung zur Datenbank her, entpacken die Daten und speichern sie anschließend in der Datenbank. Jetzt können wir wieder testen!
Test
Führen Sie erneut den folgenden Befehl im „stack“-Verzeichnis aus:
$ scrapy crawl stack
HINWEIS :Stellen Sie sicher, dass Sie den Mongo-Daemon haben - mongod - läuft in einem anderen Terminalfenster.
Hurra! Wir haben unsere gecrawlten Daten erfolgreich in der Datenbank gespeichert:
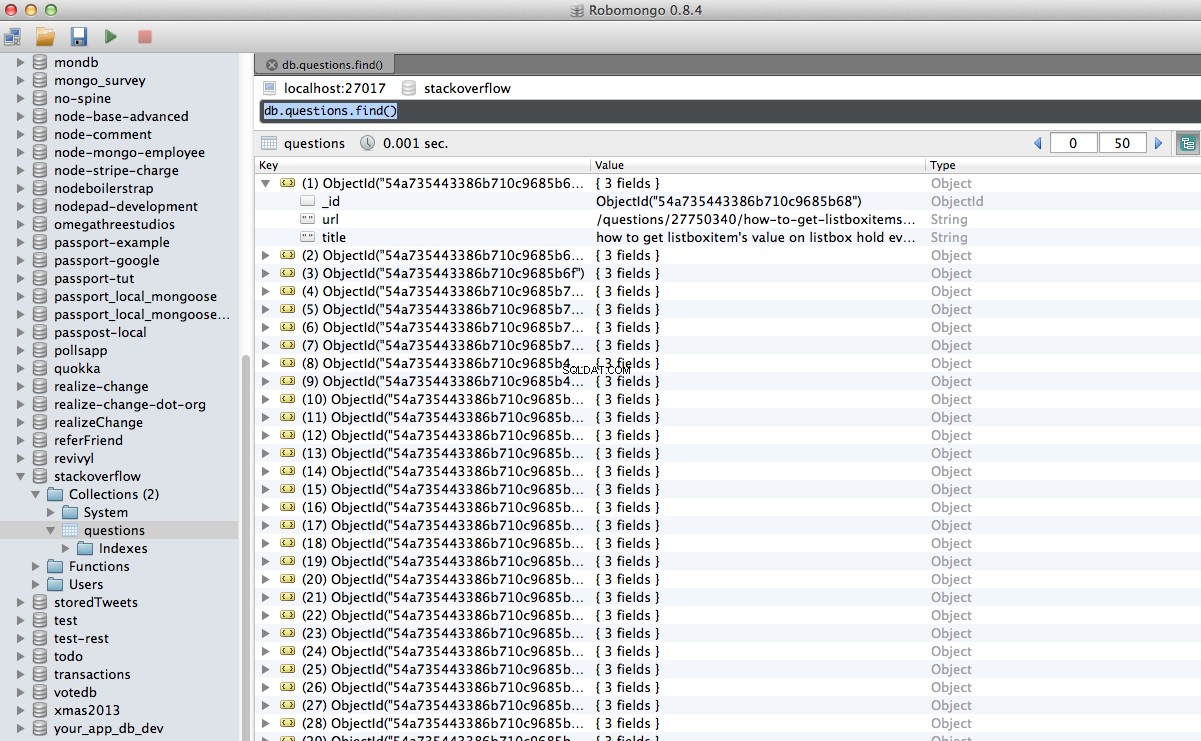
Schlussfolgerung
Dies ist ein ziemlich einfaches Beispiel für die Verwendung von Scrapy zum Crawlen und Scrapen einer Webseite. Das eigentliche freiberufliche Projekt erforderte, dass das Skript den Paginierungslinks folgte und jede Seite mit dem CrawlSpider scrapte (docs), die super einfach zu implementieren ist. Versuchen Sie, dies selbst zu implementieren, und hinterlassen Sie unten einen Kommentar mit dem Link zum Github-Repository für eine schnelle Codeüberprüfung.
Brauchen Sie Hilfe? Beginnen Sie mit diesem fast vollständigen Skript. Dann sehen Sie sich Teil 2 für die vollständige Lösung an!
Kostenloser Bonus: Klicken Sie hier, um ein Python + MongoDB-Projektskelett mit vollständigem Quellcode herunterzuladen, der Ihnen zeigt, wie Sie von Python aus auf MongoDB zugreifen.
Sie können den gesamten Quellcode aus dem Github-Repository herunterladen. Kommentieren Sie unten mit Fragen. Danke fürs Lesen!



