ClusterControl 1.6 verfügt über eine engere Integration mit AWS, Azure und Google Cloud, sodass es jetzt möglich ist, neue Instanzen zu starten und MySQL, MariaDB, MongoDB und PostgreSQL direkt über die ClusterControl-Benutzeroberfläche bereitzustellen. In diesem Blog zeigen wir Ihnen, wie Sie einen Cluster auf Amazon Web Services bereitstellen.
Beachten Sie, dass diese neue Funktion zwei Module namens clustercontrol-cloud erfordert und clustercontrol-clud . Ersteres ist ein Hilfsdämon, der die CMON-Fähigkeit der Cloud-Kommunikation erweitert, während letzteres ein Dateimanager-Client zum Hochladen und Herunterladen von Dateien auf Cloud-Instanzen ist. Beide Pakete sind Abhängigkeiten des Clustercontrol-UI-Pakets, das automatisch installiert wird, wenn sie nicht vorhanden sind. Einzelheiten finden Sie auf der Dokumentationsseite der Komponenten.
Cloud-Anmeldedaten
Mit ClusterControl können Sie Ihre Cloud-Anmeldeinformationen unter Integrationen (Seitenmenü) -> Cloud-Anbieter:
speichern und verwalten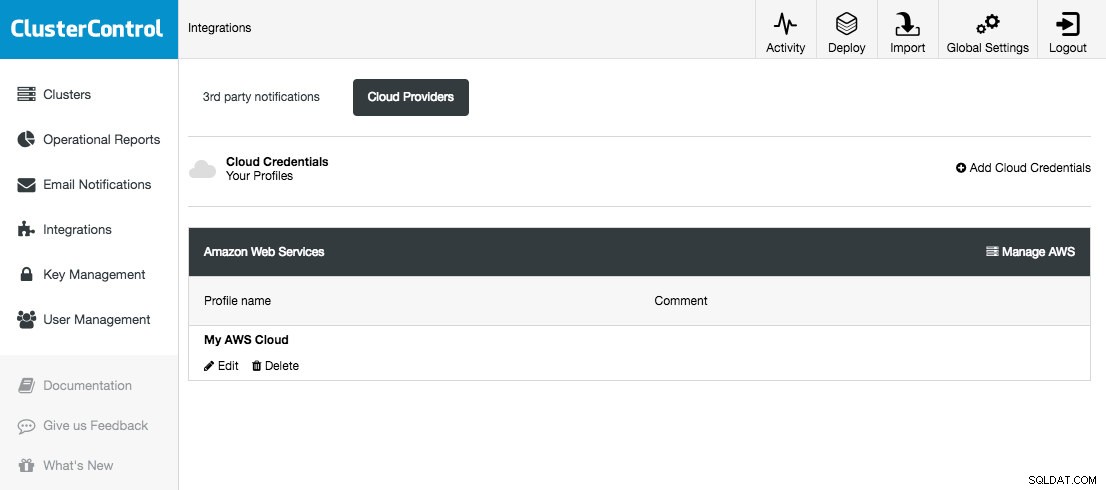
Die unterstützten Cloud-Plattformen in dieser Version sind Amazon Web Services, Google Cloud Platform und Microsoft Azure. Auf dieser Seite können Sie neue Cloud-Anmeldeinformationen hinzufügen, vorhandene verwalten und auch eine Verbindung zu Ihrer Cloud-Plattform herstellen, um Ressourcen zu verwalten.
Die hier eingerichteten Anmeldeinformationen können verwendet werden für:
- Cloud-Ressourcen verwalten
- Bereitstellen von Datenbanken in der Cloud
- Backup in den Cloud-Speicher hochladen
Folgendes würden Sie sehen, wenn Sie auf die Schaltfläche „AWS verwalten“ klicken:
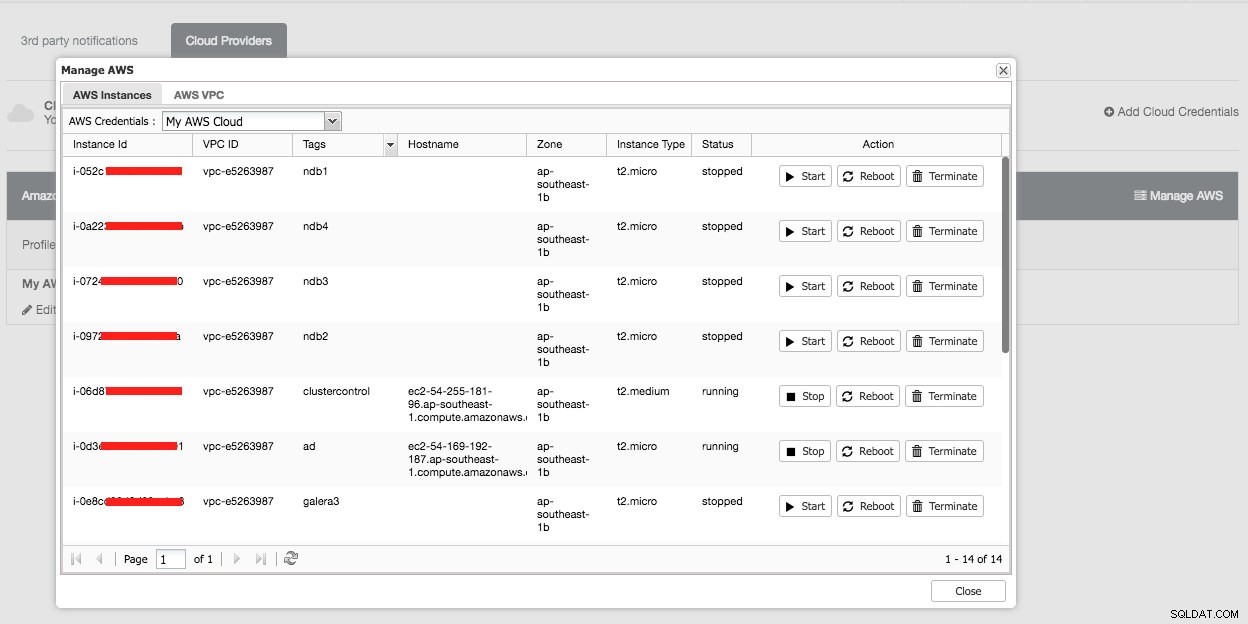
Sie können einfache Verwaltungsaufgaben auf Ihren Cloud-Instanzen ausführen. Sie können die VPC-Einstellungen auch auf der Registerkarte „AWS VPC“ überprüfen, wie im folgenden Screenshot gezeigt:
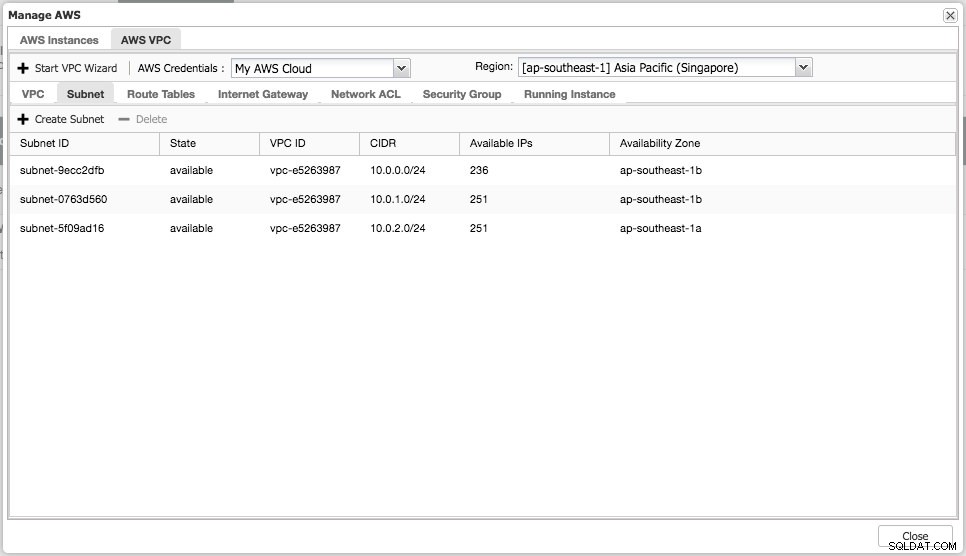
Die oben genannten Funktionen sind als Referenz nützlich, insbesondere wenn Sie Ihre Cloud-Instanzen vorbereiten, bevor Sie mit der Datenbankbereitstellung beginnen.
Datenbankbereitstellung in der Cloud
In früheren Versionen von ClusterControl wurde die Datenbankbereitstellung in der Cloud ähnlich behandelt wie die Bereitstellung auf Standardhosts, bei denen Sie die Cloudinstanzen zuvor erstellen und dann die Instanzdetails und Anmeldeinformationen im Assistenten „Datenbankcluster bereitstellen“ angeben mussten. Das Bereitstellungsverfahren war sich keiner zusätzlichen Funktionalität und Flexibilität in der Cloud-Umgebung bewusst, wie z. B. dynamische IP- und Hostnamenzuweisung, NAT-ed öffentliche IP-Adresse, Speicherelastizität, virtuelle private Cloud-Netzwerkkonfiguration und so weiter.
Mit Version 1.6 müssen Sie nur die Cloud-Anmeldeinformationen angeben, die über die Schnittstelle „Cloud-Anbieter“ verwaltet werden können, und dem Bereitstellungsassistenten „In der Cloud bereitstellen“ folgen. Klicken Sie in der ClusterControl-Benutzeroberfläche auf Bereitstellen und Ihnen werden die folgenden Optionen angezeigt:
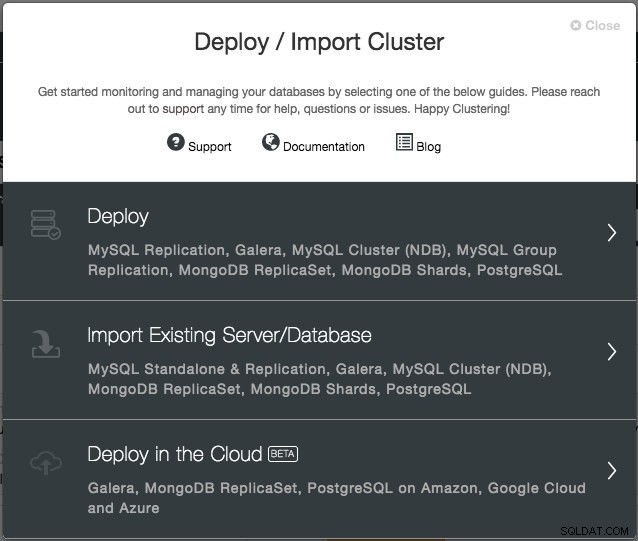
Die derzeit unterstützten Cloud-Anbieter sind die drei Big Player Amazon Web Service (AWS), Google Cloud und Microsoft Azure. Wir werden in der zukünftigen Version weitere Anbieter integrieren.
Auf der ersten Seite werden Ihnen die Optionen für die Clusterdetails angezeigt:
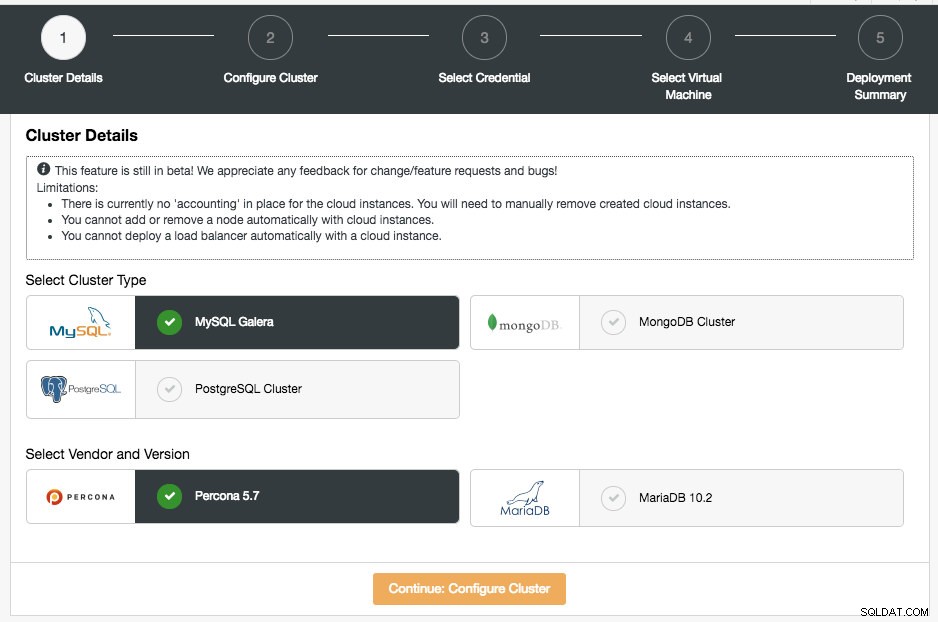
In diesem Abschnitt müssen Sie den unterstützten Clustertyp auswählen, MySQL Galera Cluster, MongoDB Replica Set oder PostgreSQL Streaming Replication. Im nächsten Schritt wählen Sie den unterstützten Anbieter für den ausgewählten Clustertyp aus. Derzeit werden folgende Anbieter und Versionen unterstützt:
- MySQL Galera-Cluster – Percona XtraDB-Cluster 5.7, MariaDB 10.2
- MongoDB-Cluster – MongoDB 3.4 von MongoDB, Inc und Percona Server für MongoDB 3.4 von Percona (nur Replikatsatz).
- PostgreSQL-Cluster – PostgreSQL 10.0 (nur Streaming-Replikation).
Im nächsten Schritt wird Ihnen folgender Dialog angezeigt:
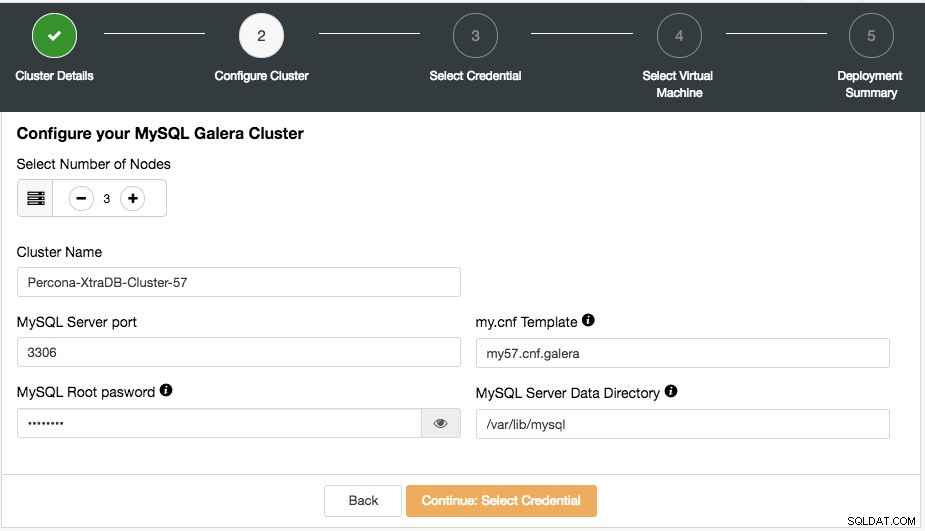
Hier können Sie den ausgewählten Clustertyp entsprechend konfigurieren. Wählen Sie die Anzahl der Knoten. Der Clustername wird als Instanz-Tag verwendet, sodass Sie diese Bereitstellung in Ihrem Cloud-Anbieter-Dashboard leicht erkennen können. Im Clusternamen ist kein Leerzeichen zulässig. My.cnf Template ist die Vorlagenkonfigurationsdatei, die ClusterControl zum Bereitstellen des Clusters verwendet. Es muss sich unter /usr/share/cmon/templates auf dem ClusterControl-Host befinden. Die restlichen Felder sind ziemlich selbsterklärend.
Im nächsten Dialog wählen Sie die Cloud-Anmeldeinformationen aus:
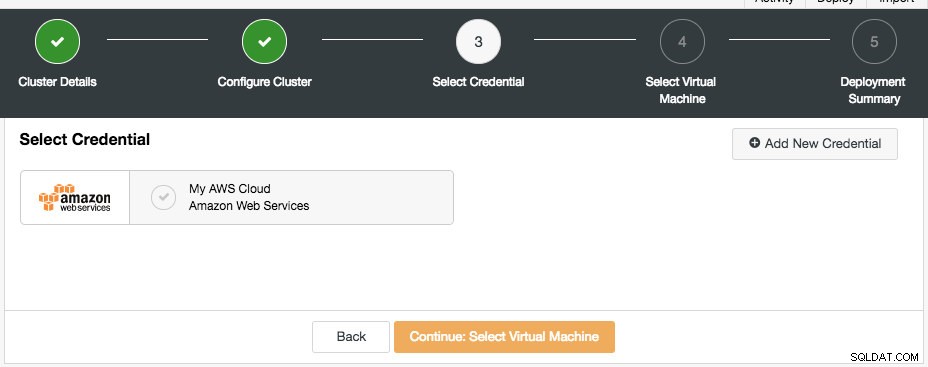
Sie können die vorhandenen Cloud-Anmeldeinformationen auswählen oder eine neue erstellen, indem Sie auf die Schaltfläche „Neue Anmeldeinformationen hinzufügen“ klicken. Der nächste Schritt besteht darin, die Konfiguration der virtuellen Maschine auszuwählen:
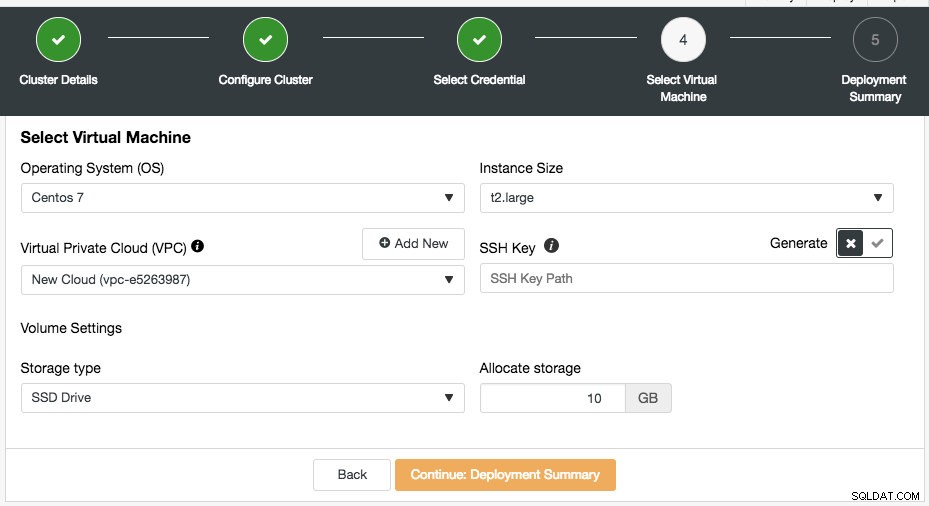
Die meisten Einstellungen in diesem Schritt werden dynamisch vom Cloud-Anbieter mit den ausgewählten Anmeldeinformationen ausgefüllt. Sie können das Betriebssystem, die Instanzgröße, die VPC-Einstellung, den Speichertyp und die Speichergröße konfigurieren und auch den Speicherort des SSH-Schlüssels auf dem ClusterControl-Host angeben. Sie können ClusterControl auch speziell für diese Instanzen einen neuen Schlüssel generieren lassen. Wenn Sie auf die Schaltfläche „Neu hinzufügen“ neben Virtual Private Cloud klicken, wird Ihnen ein Formular zum Erstellen einer neuen VPC angezeigt:
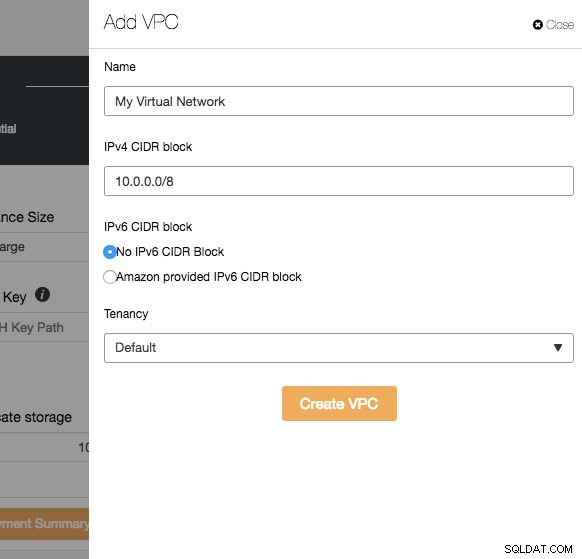
VPC ist eine logische Netzwerkinfrastruktur, die Sie innerhalb Ihrer Cloud-Plattform haben. Sie können Ihre VPC konfigurieren, indem Sie ihren IP-Adressbereich ändern, Subnetze erstellen, Routing-Tabellen, Netzwerk-Gateways und Sicherheitseinstellungen konfigurieren. Es wird empfohlen, Ihre Datenbankinfrastruktur zur Isolierung, Sicherheit und Routing-Steuerung in diesem Netzwerk bereitzustellen.
Geben Sie beim Erstellen einer neuen VPC den VPC-Namen und den IPv4-Adressblock mit Subnetz an. Wählen Sie dann, ob IPv6 Teil des Netzwerks sein soll, und die Tenancy-Option. Sie können dieses virtuelle Netzwerk dann für Ihre Datenbankinfrastruktur verwenden.
Der letzte Schritt ist die Bereitstellungszusammenfassung:
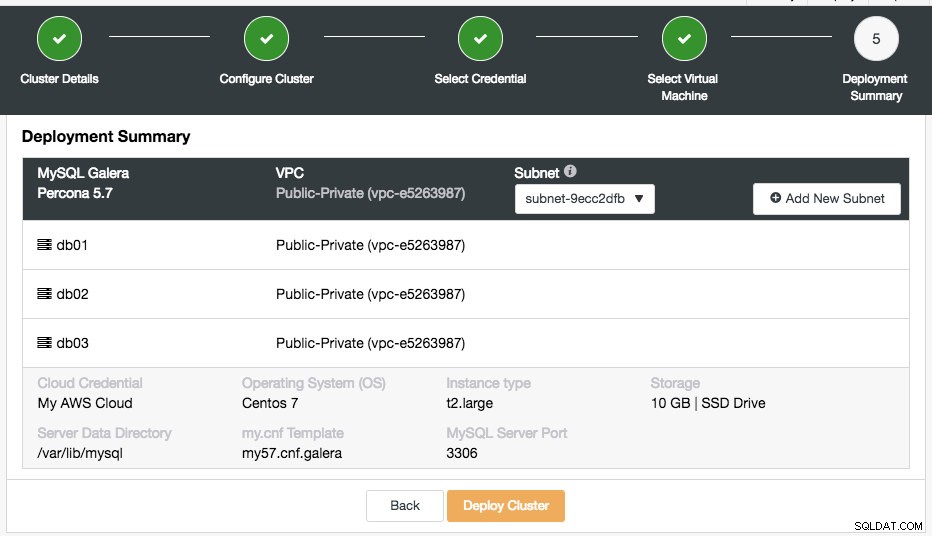
In dieser Phase müssen Sie auswählen, in welchem Subnetz unter dem ausgewählten virtuellen Netzwerk die Datenbank ausgeführt werden soll. Beachten Sie, dass für das ausgewählte Subnetz die automatische Zuweisung öffentlicher IPv4-Adressen aktiviert sein MUSS. Sie können auch ein neues Subnetz unter dieser VPC erstellen, indem Sie auf die Schaltfläche „Neues Subnetz hinzufügen“ klicken. Überprüfen Sie, ob alles korrekt ist, und klicken Sie auf die Schaltfläche „Cluster bereitstellen“, um die Bereitstellung zu starten.
Sie können dann den Fortschritt überwachen, indem Sie auf Aktivität -> Jobs -> Cluster erstellen -> Vollständige Jobdetails klicken:
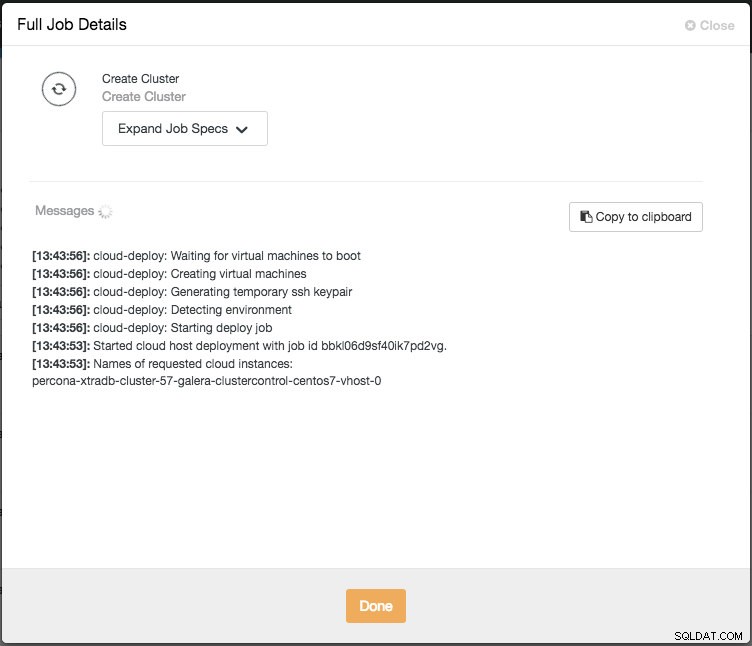
Abhängig von den Verbindungen kann es 10 bis 20 Minuten dauern, bis der Vorgang abgeschlossen ist. Sobald Sie fertig sind, sehen Sie einen neuen Datenbank-Cluster, der unter dem ClusterControl-Dashboard aufgelistet ist. Für PostgreSQL-Streaming-Replikationscluster müssen Sie nach Abschluss der Bereitstellung möglicherweise die Master- und Slave-IP-Adressen kennen. Gehen Sie einfach zur Registerkarte Knoten und Sie sehen die öffentlichen und privaten IP-Adressen auf der Knotenliste auf der linken Seite:
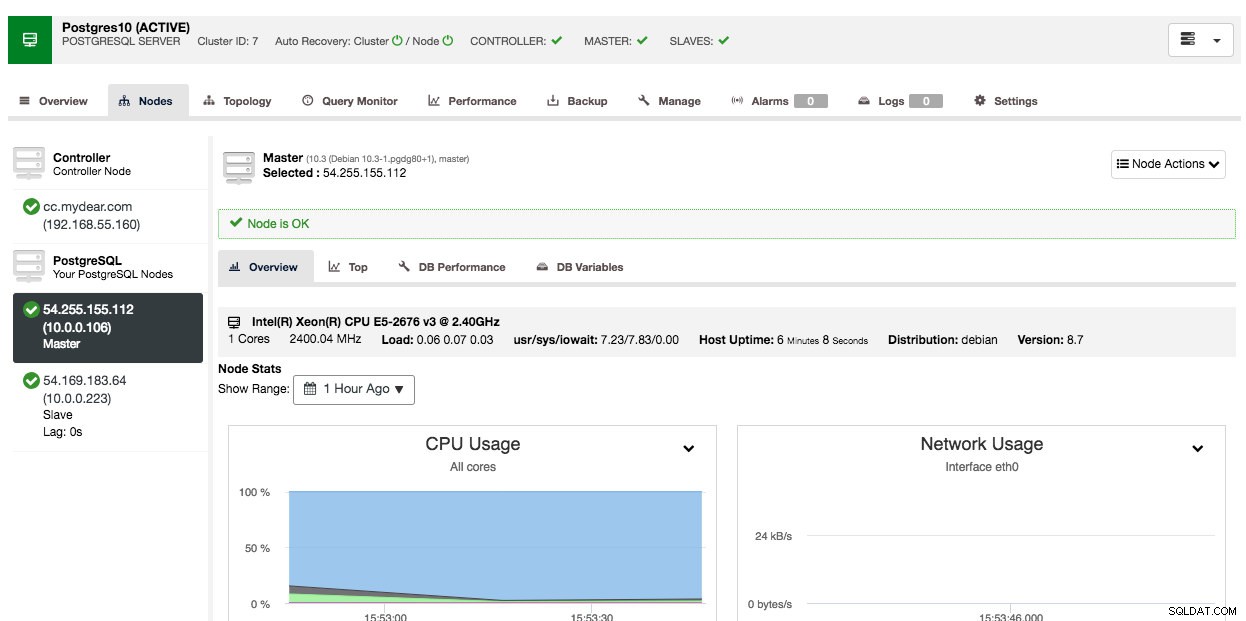
Ihr Datenbank-Cluster ist jetzt bereitgestellt und wird auf AWS ausgeführt.
Momentan funktioniert das Hochskalieren ähnlich wie beim Standard-Host, wo man vorher manuell eine Cloud-Instanz anlegen und unter ClusterControl -> Cluster auswählen -> Node hinzufügen den Host angeben muss.
Unter der Haube macht der Bereitstellungsprozess Folgendes:
- Cloud-Instanzen erstellen
- Sicherheitsgruppen und Netzwerke konfigurieren
- Überprüfen Sie die SSH-Konnektivität von ClusterControl zu allen erstellten Instanzen
- Datenbank auf jeder Instanz bereitstellen
- Konfigurieren Sie die Clustering- oder Replikationslinks
- Registrieren Sie die Bereitstellung in ClusterControl
Beachten Sie, dass sich diese Funktion noch in der Beta-Phase befindet. Dennoch können Sie diese Funktion verwenden, um Ihre Entwicklungs- und Testumgebung zu beschleunigen, indem Sie den Datenbankcluster bei verschiedenen Cloud-Anbietern von einer einzigen Benutzeroberfläche aus steuern und verwalten.
Datenbanksicherung in der Cloud
Diese Funktion gibt es seit ClusterControl 1.5.0, und jetzt haben wir die Unterstützung für Azure Cloud Storage hinzugefügt. Das bedeutet, dass Sie das erstellte Backup nun auf allen drei großen Cloud-Anbietern (AWS, GCP und Azure) hoch- und herunterladen können. Der Upload-Vorgang erfolgt direkt nach erfolgreicher Erstellung des Backups (wenn Sie „Backup in die Cloud hochladen“ umschalten) oder Sie können manuell auf die Cloud-Symbol-Schaltfläche der Backup-Liste klicken:
Sie können dann Backups aus der Cloud herunterladen und wiederherstellen, falls Sie Ihren lokalen Backup-Speicher verloren haben oder wenn Sie die lokale Speicherplatznutzung für Ihre Backups reduzieren müssen.
Aktuelle Einschränkungen
Es gibt einige bekannte Einschränkungen für die Cloud-Bereitstellungsfunktion, wie unten angegeben:
- Es gibt derzeit keine „Abrechnung“ für die Cloud-Instanzen. Sie müssen die Cloud-Instanzen manuell entfernen, wenn Sie einen Datenbank-Cluster entfernen.
- Mit Cloud-Instanzen können Sie Knoten nicht automatisch hinzufügen oder entfernen.
- Sie können einen Load Balancer nicht automatisch mit einer Cloud-Instanz bereitstellen.
Wir haben die Funktion in vielen Umgebungen und Setups ausgiebig getestet, aber es gibt immer wieder Ausnahmefälle, die wir möglicherweise übersehen haben. Weitere Informationen finden Sie im Änderungsprotokoll.
Viel Spaß beim Clustering in der Cloud!



