SCUMM (Severalnines ClusterControl Unified Monitoring &Management) ist eine agentenbasierte Lösung, bei der Agenten auf den Datenbankknoten installiert sind. Es bietet eine Reihe von Überwachungs-Dashboards, die Prometheus als Datenspeicher mit seiner elastischen Abfragesprache und seinem mehrdimensionalen Datenmodell haben. Prometheus kratzt Metrikdaten von Exportern, die auf den Datenbankhosts ausgeführt werden.
Die ClusterControl SCUMM-Architektur wurde mit Version 1.7.0 eingeführt und erweitert die Überwachungsfunktionalität für MySQL, Galera Cluster, PostgreSQL und ProxySQL.
Das neue ClusterControl 1.7.1 fügt hochauflösendes Monitoring für MongoDB-Systeme hinzu.
 ClusterControl MongoDB-Dashboard-Liste
ClusterControl MongoDB-Dashboard-Liste In diesem Artikel beschreiben wir die beiden Haupt-Dashboards für MongoDB-Umgebungen. MongoDB Server und MongoDB Replicaset.
Dashboard und Metrikliste
Die Liste der Dashboards und ihrer Metriken:
| MongoDB-Server | |
|---|---|
| Name ReplSet-Name Serverbetriebszeit OpsCounters Verbindungen WT – Gleichzeitige Tickets (Lesen) WT – Gleichzeitige Tickets (Schreiben) WT – Gleichzeitige Tickets (Schreiben) /> WT - Cache Global Lock Asserts |
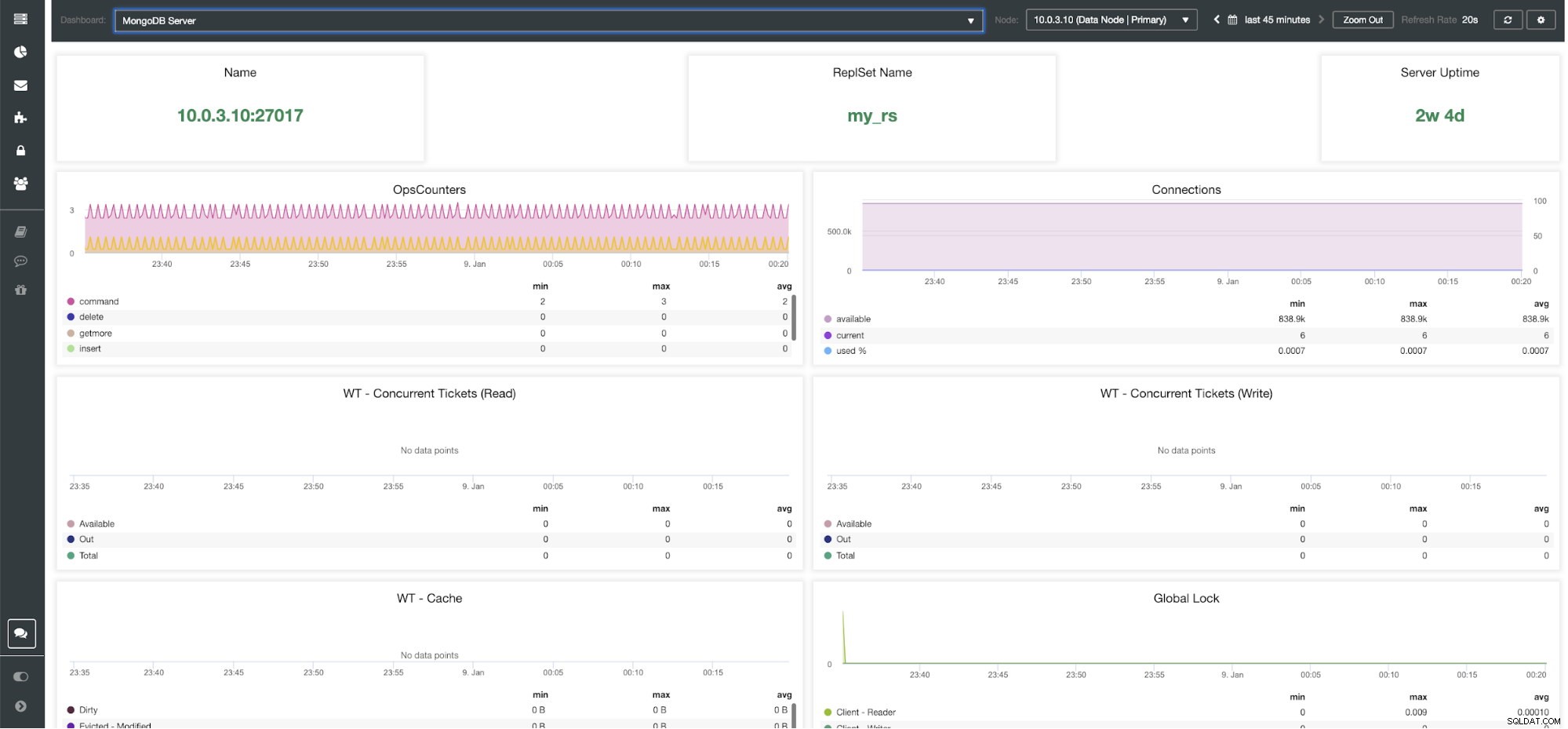 ClusterControl MongoDB Server Dashboard
ClusterControl MongoDB Server Dashboard| MongoDB ReplicaSet | |
|---|---|
| ReplSet-Größe ReplSet-Name PRIMARY Serverversion Replikatsätze und Mitglieder Oplog-Fenster pro ReplSet Replikations-Headroom Insgesamt PRIMÄR/SEKUNDÄR online pro ReplSet Offene Cursor pro ReplSet ReplSet - Timeout-Cursor pro Set Max. Replikationsverzögerung pro ReplSet Oplog-Größe OpsCounters Ping-Zeit zum Replizieren von Set-Mitgliedern von PRIMARY(s) |
 ClusterControl MongoDB ReplicaSet-Dashboard
ClusterControl MongoDB ReplicaSet-Dashboard Da Datenbanksysteme stark von Betriebssystemressourcen abhängen, finden Sie auch zwei zusätzliche Dashboards für die Systemübersicht und die Clusterübersicht Ihrer MongoDB-Umgebung.
| Systemübersicht | |
|---|---|
| Server-Betriebszeit CPU-Kerne Gesamt-RAM Durchschnittliche Auslastung CPU-Nutzung RAM-Nutzung Festplattenspeichernutzung Netzwerknutzung /> Disk IOPS Disk IO Util % Disk Throughput |
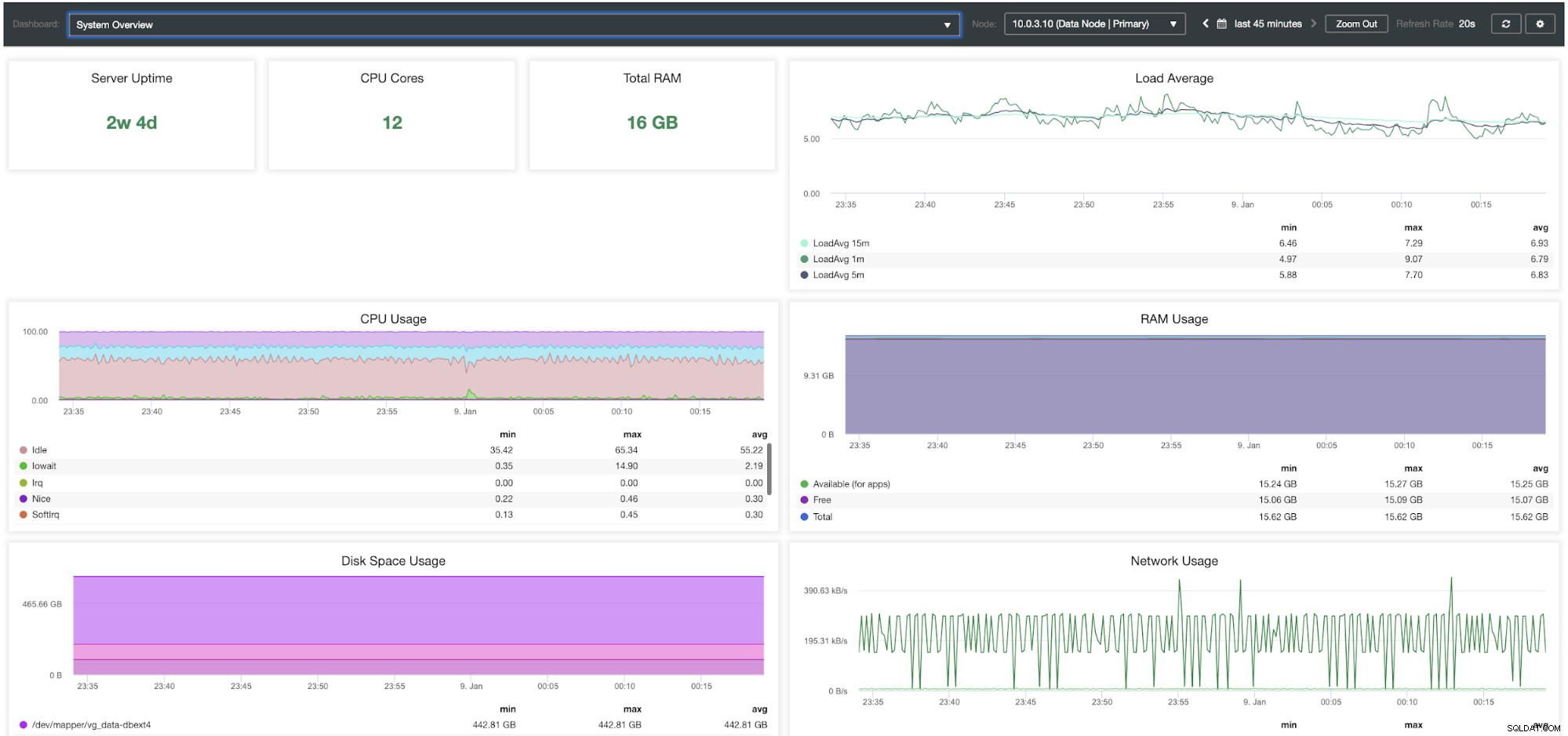 ClusterControl-Systemübersichts-Dashboard
ClusterControl-Systemübersichts-Dashboard| Cluster-Übersicht | |
|---|---|
| Durchschnittliche Belastung 1 m Durchschnittliche Belastung 5 m Durchschnittliche Belastung 15 m Verfügbarer Arbeitsspeicher für Anwendungen Netzwerk-TX Netzwerk-RX Festplatte lesen IOPS Disk Write IOPS Disk Write + Read IOPS |
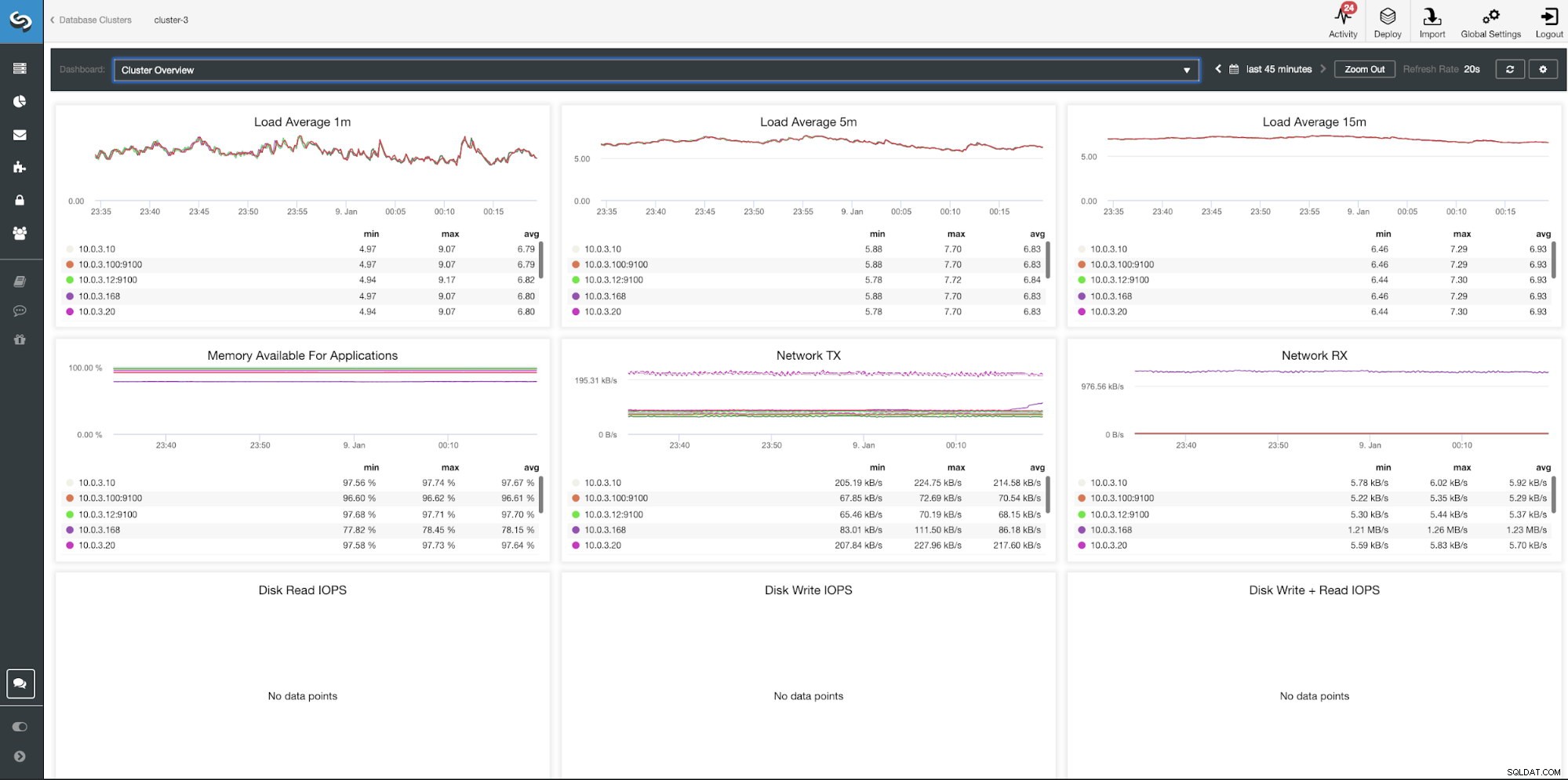 ClusterControl-Clusterübersichts-Dashboard
ClusterControl-Clusterübersichts-Dashboard MongoDB-Server-Dashboard
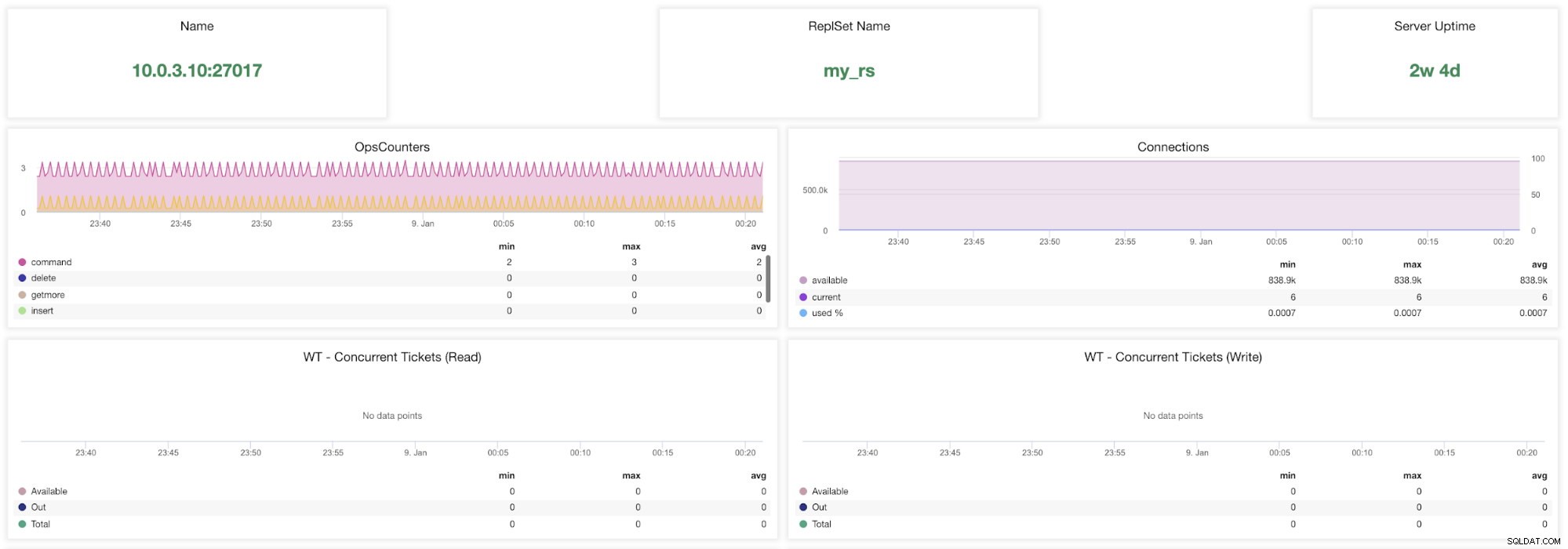 ClusterControl MongoDB-Metriken
ClusterControl MongoDB-Metriken Name - Serveradresse und Port.
ReplsSet-Name - Zeigt den Namen des Replikatsatzes an, zu dem der Server gehört.
Server-Betriebszeit - Zeit seit dem letzten Serverneustart.
Operationszähler - Anzahl der während des ausgewählten Zeitraums eingegangenen Anfragen, aufgeschlüsselt nach Art der Operation. Diese Zählungen umfassen alle empfangenen Vorgänge, einschließlich derjenigen, die nicht erfolgreich waren.
Verbindungen - Dieses Diagramm zeigt eine der wichtigsten zu beobachtenden Metriken - die Anzahl der Verbindungen, die während des ausgewählten Zeitraums empfangen wurden, einschließlich erfolgloser Anfragen. Abnormale Verkehrslasten können zu Leistungsproblemen führen. Wenn MongoDB wenig Verbindungen hat, kann es eingehende Anfragen möglicherweise nicht rechtzeitig bearbeiten.
WT – gleichzeitige Tickets (Lesen) / WT – gleichzeitige Tickets (Schreiben) Diese beiden Diagramme zeigen Lese- und Schreibtickets, die die Parallelität in WiredTiger (WT) steuern. WT-Tickets steuern, wie viele Lese- und Schreibvorgänge gleichzeitig auf der Speicher-Engine ausgeführt werden können. Wenn die verfügbaren Lese- und Schreibtickets auf Null fallen, entspricht die Anzahl der gleichzeitig ausgeführten Vorgänge den konfigurierten Lese-/Schreibwerten. Das bedeutet, dass alle anderen Operationen warten müssen, bis einer der laufenden Threads seine Arbeit an der Speicher-Engine beendet hat, bevor sie ausgeführt werden.
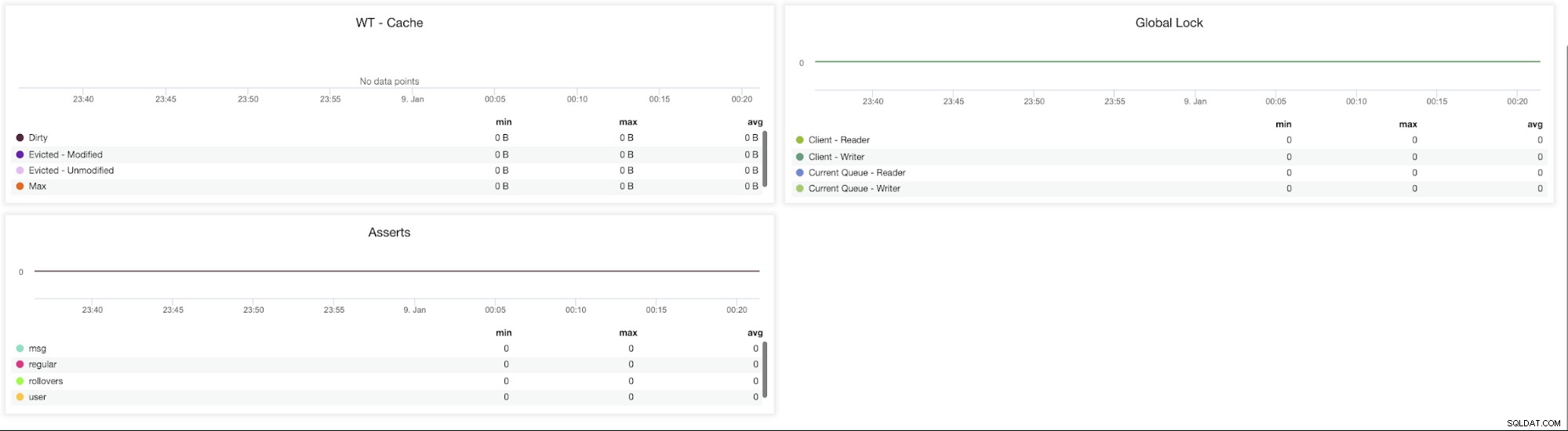 ClusterControl MongoDB-Metriken
ClusterControl MongoDB-Metriken WT - Cache (Dirty, Evicted - Modified, Evicted - Unmodified, Max) - Die Größe des Caches ist der wichtigste Knopf für WiredTiger. Standardmäßig reserviert MongoDB 3.x 50 % (60 % in 3.2) des verfügbaren Arbeitsspeichers für seinen Datencache.
Globale Sperre (Client-Lesen, Client – Schreiben, Aktuelle Warteschlange – Leser, Aktuelle Warteschlange – Verfasser) – Schlechte Schemaentwurfsmuster oder umfangreiche Lese- und Schreibanforderungen von vielen Clients können umfangreiche Sperren verursachen. In diesem Fall muss die Konsistenz gewahrt und Schreibkonflikte vermieden werden.
Um dies zu erreichen, verwendet MongoDB Multi-Granularity-Locking, das Sperrvorgänge auf verschiedenen Ebenen ermöglicht, z. B. auf globaler, Datenbank- oder Sammlungsebene .
Behauptungen (msg, regular, rollovers, user) – Dieses Diagramm zeigt die Anzahl der Assertionen, die jede Sekunde ausgelöst werden. Hohe Werte und Abweichungen von Trends sollten überprüft werden.
MongoDB ReplicaSet-Dashboard
Die in diesem Dashboard angezeigten Metriken sind nur von Bedeutung, wenn Sie einen Replikatsatz verwenden.
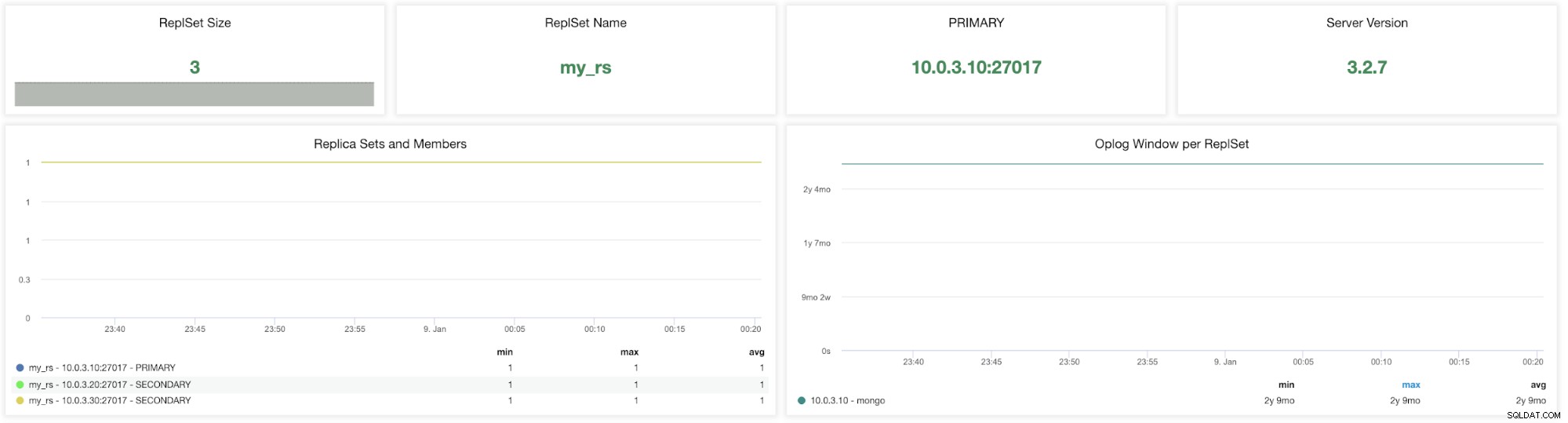 ClusterControl MongoDB ReplicaSet-Metriken
ClusterControl MongoDB ReplicaSet-Metriken ReplicaSet-Größe - Die Anzahl der Mitglieder im Replikatsatz. Die standardmäßige Replikatsatzbereitstellung für das Produktionssystem ist ein Replikatsatz mit drei Mitgliedern. Im Allgemeinen wird empfohlen, dass ein Replikat-Set eine ungerade Anzahl stimmberechtigter Mitglieder hat. Die Fehlertoleranz für eine Replikatgruppe ist die Anzahl der Mitglieder, die nicht mehr verfügbar sein können und immer noch genügend Mitglieder in der Gruppe verbleiben, um eine primäre Gruppe zu wählen. Die Fehlertoleranz für drei Mitglieder ist eins, für fünf zwei usw.
ReplSet-Name - Es ist der in der MongoDB-Konfigurationsdatei zugewiesene Name. Der Name bezieht sich auf /etc/mongod.conf replSet value.
PRIMÄR - Der primäre Knoten empfängt alle Schreiboperationen und zeichnet alle anderen Änderungen an seinem Datensatz in seinem Operationsprotokoll auf. Der Wert dient zum Identifizieren der IP und des Ports Ihres primären Knotens im MongoDB-Replikatsatz-Cluster.
Serverversion - Identifizieren Sie die Serverversion. ClusterControl Version 1.7.1 unterstützt die MongoDB-Versionen 3.2/3.4/3.6/4.0.
Replik-Sets und -Mitglieder (Min., Max., Durchschnitt) – Dieses Diagramm kann Ihnen helfen, aktive Mitglieder über den Zeitraum zu identifizieren. Sie können die minimale, maximale und durchschnittliche Anzahl von primären und sekundären Knoten verfolgen und wie sich diese Zahlen im Laufe der Zeit verändert haben. Jede Abweichung kann die Fehlertoleranz und Cluster-Verfügbarkeit beeinträchtigen.
Oplog-Fenster pro ReplSet - Das Replikationsfenster ist eine wichtige Metrik, die es zu beobachten gilt. Das MongoDB-Oplog ist eine einzelne Sammlung, die auf eine (voreingestellte) Größe begrenzt wurde. Er kann als Unterschied zwischen dem ersten und dem letzten Zeitstempel in oplog.rs beschrieben werden. Dies ist die Zeitspanne, die eine sekundäre Instanz offline sein kann, bevor eine anfängliche Synchronisierung erforderlich ist, um die Instanz zu synchronisieren. Diese Metriken informieren Sie darüber, wie viel Zeit Sie noch haben, bevor unsere nächste Transaktion aus dem Oplog gelöscht wird.
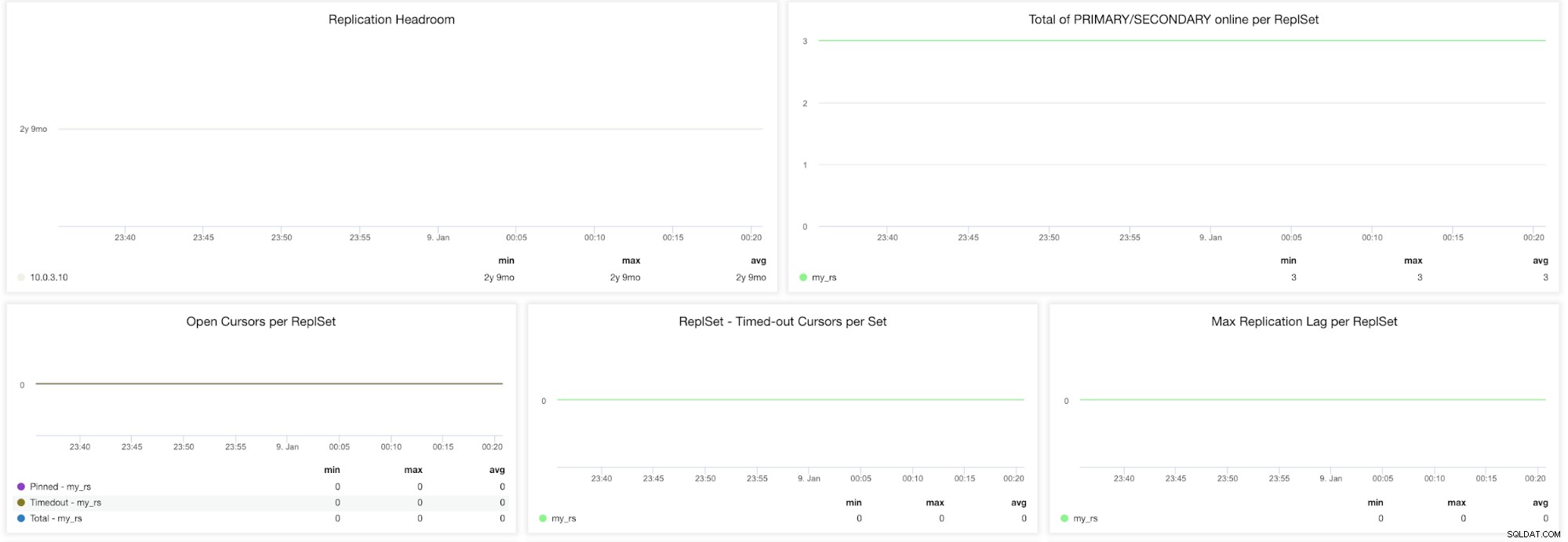 ClusterControl MongoDB ReplicaSet-Metriken
ClusterControl MongoDB ReplicaSet-Metriken Replikationsspielraum - Dieses Diagramm zeigt den Unterschied zwischen dem Oplog-Fenster des primären Knotens und der Replikationsverzögerung der sekundären Knoten. Das MongoDB-Oplog ist in der Größe begrenzt und wenn der Knoten zu weit zurückliegt, kann er nicht aufholen. In diesem Fall wird eine vollständige Synchronisierung ausgegeben, und dies ist ein teurer Vorgang, der jederzeit vermieden werden muss.
Summe PRIMARY/SECONDARY online pro ReplSet - Gesamtzahl der Cluster-Knoten über den Zeitraum.
Cursor öffnen pro ReplSet (angeheftet, Timeout, Gesamt) - Eine Leseanforderung kommt mit einem Cursor, der ein Zeiger auf den Datensatz des Ergebnisses ist. Es bleibt auf dem Server geöffnet und verbraucht daher Speicher, es sei denn, es wird durch die Standardeinstellung von MongoDB beendet. Sie sollten nicht aktive Cursor identifizieren und abschneiden, um Speicherplatz zu sparen.
ReplSet – Timeout-Cursor pro SetsMax. Replikationsverzögerung pro ReplSet – Die Replikationsverzögerung ist sehr wichtig, um ein Auge darauf zu haben, wenn Sie Lesevorgänge skalieren, indem Sie mehr Sekundäre hinzufügen. MongoDB verwendet diese Secondaries nur, wenn sie nicht zu weit hinterherhinken. Wenn der sekundäre Server eine Replikationsverzögerung aufweist, riskieren Sie, veraltete Daten bereitzustellen, die bereits auf dem primären Server überschrieben wurden.
OplogSize – Bestimmte Workloads erfordern möglicherweise eine größere Oplog-Größe. Aktualisierungen an mehreren Dokumenten gleichzeitig, Löschungen entsprechen der gleichen Datenmenge wie eine Einfügung oder die beträchtliche Anzahl von In-Place-Aktualisierungen.
OpsConters - Dieses Diagramm zeigt die Anzahl der Abfrageausführungen.
Ping-Zeit zum Replica-Set-Mitglied vom Primären - Auf diese Weise können Sie Replikatsatzmitglieder erkennen, die ausgefallen oder vom primären Knoten aus nicht erreichbar sind.
Schlussbemerkungen
Die neue Dashboard-Funktion ClusterControl 1.7.1 MongoDB ist in der Community Edition kostenlos verfügbar. Datenbankbetriebsteams können davon profitieren, indem sie die hochauflösenden Grafiken verwenden, insbesondere bei der Durchführung ihrer täglichen Routinen wie Ursachenanalysen und Kapazitätsplanung.
Mit nur einem Klick können neue Monitoring-Agents bereitgestellt werden. ClusterControl installiert Prometheus-Agenten, konfiguriert Metriken und verwaltet den Zugriff auf die Prometheus-Exporterkonfiguration über seine GUI, sodass Sie die Parameterkonfiguration wie Collector-Flags für die Exporter (Prometheus) besser verwalten können.
Indem Sie die Anzahl der Lese- und Schreibanforderungen angemessen überwachen, können Sie eine Ressourcenüberlastung verhindern, den Ursprung potenzieller Überlastungen schnell finden und wissen, wann eine Skalierung erforderlich ist.



