In unserem vorherigen Hadoop-Tutorial o Rial haben wir Ihnen eine ausführliche Beschreibung von InputFormat. bereitgestellt In diesem Blog werden wir uns jetzt mit dem Hadoop-Ausgabeformat befassen.
Wir werden diskutieren, was OutputFormat in Hadoop ist, was RecordWritter in MapReduce OutputFormat ist. Wir werden auch die Typen von OutputFormat in MapReduce behandeln.
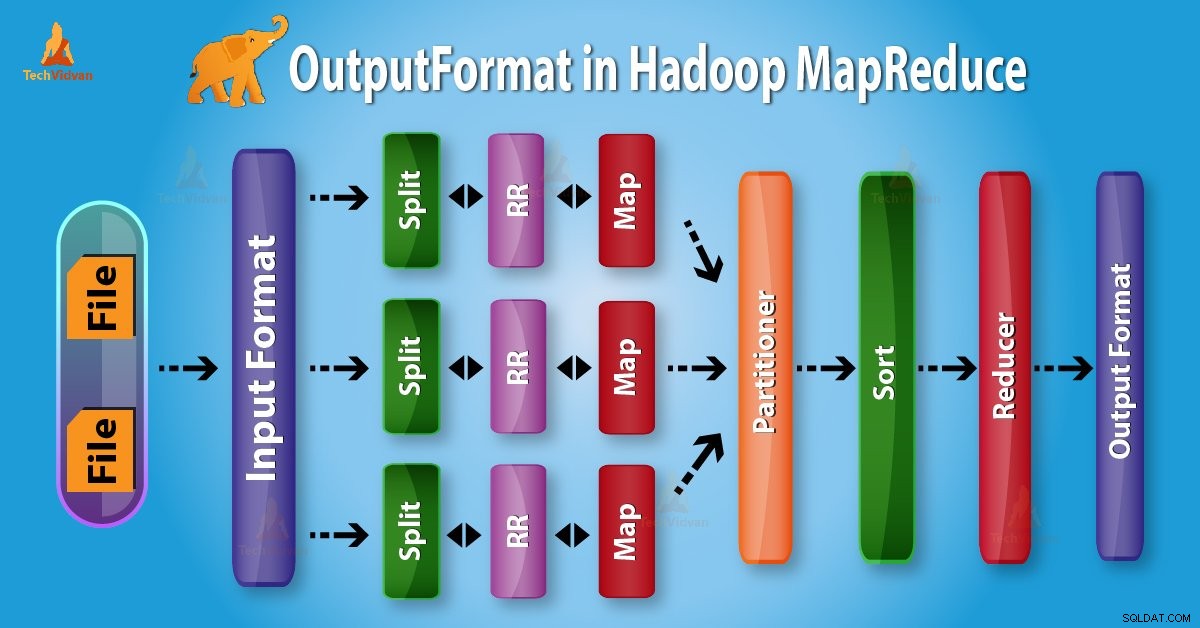
Einführung in das Hadoop-Ausgabeformat
Ausgabeformat Überprüfen Sie die Ausgabespezifikation für die Ausführung des Map-Reduce-Jobs. Es beschreibt, wie die RecordWriter-Implementierung verwendet wird, um Ausgaben in Ausgabedateien zu schreiben.
Bevor wir mit OutputFormat beginnen, wollen wir zuerst lernen, was RecordWriter ist und was die Arbeit von RecordWriter in MapReduce ist?
1. RecordWriter in Hadoop MapReduce
Wie wir wissen, Reduzierer nimmt Mapper Zwischenausgabe als Eingabe. Dann führt es eine Reducer-Funktion auf ihnen aus, um eine Ausgabe zu generieren, die wiederum null oder mehr Schlüssel-Wert-Paare ist.
Daher schreibt RecordWriter bei der Ausführung des MapReduce-Jobs diese ausgegebenen Schlüssel-Wert-Paare aus der Reducer-Phase in die Ausgabedateien.
2. Hadoop-Ausgabeformat
Oben wird deutlich, dass RecordWriter Ausgabedaten von Reducer übernimmt. Dann schreibt es diese Daten in Ausgabedateien. OutputFormat bestimmt, wie diese Ausgabe-Schlüssel-Wert-Paare von RecordWriter in Ausgabedateien geschrieben werden.
Die Funktionen OutputFormat und InputFormat sind ähnlich. OutputFormat-Instanzen werden verwendet, um in Dateien auf der lokalen Festplatte oder in HDFS. zu schreiben In MapReduce Jobausführung auf Basis der Ausgabespezifikation;
- Hadoop MapReduce-Job prüft, ob das Ausgabeverzeichnis nicht bereits vorhanden ist.
- OutputFormat im MapReduce-Job stellt die RecordWriter-Implementierung bereit, die verwendet wird, um die Ausgabedateien des Jobs zu schreiben. Dann werden die Ausgabedateien in einem FileSystem gespeichert.
Das Framework verwendet FileOutputFormat.setOutputPath() Methode zum Festlegen des Ausgabeverzeichnisses.
Arten von Ausgabeformaten in MapReduce
Es gibt verschiedene Arten von Ausgabeformaten, die wie folgt sind:
1. Textausgabeformat
Das Standardausgabeformat ist TextOutputFormat. Es schreibt (Schlüssel, Wert)-Paare in einzelne Zeilen von Textdateien. Seine Schlüssel und Werte können von beliebigem Typ sein. Der Grund dafür ist, dass TextOutputFormat sie durch den Aufruf von toString() in Strings umwandelt auf ihnen.
Es trennt das Schlüssel-Wert-Paar durch ein Tabulatorzeichen. Durch die Verwendung von MapReduce.output.textoutputformat.separator Eigenschaft können wir auch ändern.
KeyValueTextOutputFormat wird auch zum Lesen dieser Ausgabetextdateien verwendet.
2. SequenceFileOutputFormat
Dieses OutputFormat schreibt Sequenzdateien für seine Ausgabe. SequenceFileInputFormat ist auch eine Zwischenformatverwendung zwischen MapReduce-Jobs. Es serialisiert beliebige Datentypen in die Datei.
Und das entsprechende SequenceFileInputFormat deserialisiert die Datei in dieselben Typen. Es präsentiert die Daten dem nächstenMapper in der gleichen Weise, wie es vom vorherigen Reduzierer emittiert wurde. Statische Methoden steuern auch die Komprimierung.
3. SequenceFileAsBinaryOutputFormat
Es ist eine andere Variante von SequenceFileInputFormat. Es schreibt auch Schlüssel und Werte im Binärformat in die Sequenzdatei.
4. MapFileOutputFormat
Es ist eine andere Form von FileOutputFormat. Es schreibt auch die Ausgabe als Zuordnungsdateien. Das Framework fügt einen Schlüssel in einer MapFile der Reihe nach hinzu. Wir müssen also sicherstellen, dass der Reducer die Schlüssel in sortierter Reihenfolge ausgibt.
5. Mehrere Ausgaben
Dieses Format ermöglicht das Schreiben von Daten in Dateien, deren Namen von den ausgegebenen Schlüsseln und Werten abgeleitet werden.
6. LazyOutputFormat
Bei der Auftragsausführung von MapReduce erstellt FileOutputFormat manchmal Ausgabedateien, auch wenn sie leer sind. LazyOutputFormat ist auch ein Wrapper OutputFormat.
7. DBOutputFormat
Es ist das Ausgabeformat zum Schreiben in relationale Datenbanken und HBase. Dieses Format sendet auch die Reduce-Ausgabe an eine SQL-Tabelle. Es akzeptiert auch Schlüssel-Wert-Paare. Dabei hat der Schlüssel einen DBwritable erweiternden Typ.
Schlussfolgerung
Daher werden je nach Bedarf unterschiedliche Ausgabeformate verwendet. Ich hoffe, Sie finden diesen Blog hilfreich. Wenn Sie Fragen zu Hadoop OutputFormat haben, hinterlassen Sie bitte einen Kommentar in einem Kommentarfeld. Wir lösen sie gerne.



