Mehrere JOINS in einer einzigen Abfrage
Mehrere JOINS sind normalerweise mehreren Sammlungen zugeordnet, aber Sie müssen ein grundlegendes Verständnis dafür haben, wie der INNER JOIN funktioniert (siehe meine vorherigen Posts zu diesem Thema). Zusätzlich zu unseren beiden Kollektionen hatten wir vorher; Einheiten und Studenten, fügen wir eine dritte Sammlung hinzu und nennen sie Sport. Füllen Sie die Sportsammlung mit den folgenden Daten:
{
"_id" : 1,"tournamentsPlayed" : 6,
"gamesParticipated" : [{"hockey" : "midfielder","football" : "stricker","handball" : "goalkeeper"}],
"sportPlaces" : ["Stafford Bridge","South Africa", "Rio Brazil"]
}
{
"_id" : 2,"tournamentsPlayed" : 3,
"gamesParticipated" : [{"hockey" : "goalkeeper","football" : "stricker", "handball" : "midfielder"}],
"sportPlaces" : ["Ukraine","India", "Argentina"]
}
{
"_id" : 3,"tournamentsPlayed" : 10,
"gamesParticipated" : [{"hockey" : "stricker","football" : "goalkeeper","tabletennis" : "doublePlayer"}],
"sportPlaces" : ["China","Korea","France"]
}Wir möchten beispielsweise alle Daten für einen Schüler mit einem _id-Feldwert gleich 1 zurückgeben. Normalerweise schreiben wir eine Abfrage, um den _id-Feldwert aus der Schülersammlung abzurufen, und verwenden dann den zurückgegebenen Wert für die Abfrage Daten in den anderen beiden Sammlungen. Folglich ist dies nicht die beste Option, insbesondere wenn es sich um eine große Menge von Dokumenten handelt. Ein besserer Ansatz wäre die Verwendung der SQL-Funktion des Studio3T-Programms. Wir können unsere MongoDB mit dem normalen SQL-Konzept abfragen und dann versuchen, den resultierenden Mongo-Shell-Code grob an unsere Spezifikation anzupassen. Lassen Sie uns zum Beispiel alle Daten mit _id gleich 1 aus allen Sammlungen abrufen:
SELECT *
FROM students
INNER JOIN units
ON students._id = units._id
INNER JOIN sports
ON students._id = sports._id
WHERE students._id = 1;Das resultierende Dokument wird sein:
{
"students" : {"_id" : NumberInt(1),"name" : "James Washington","age" : 15.0,"grade" : "A","score" : 10.5},
"units" : {"_id" : NumberInt(1),"grades" : {Maths" : "A","English" : "A","Science" : "A","History" : "B"}
},
"sports" : {
"_id" : NumberInt(1),"tournamentsPlayed" : NumberInt(6),
"gamesParticipated" : [{"hockey" : "midfielder", "football" : "striker","handball" : "goalkeeper"}],
"sportPlaces" : ["Stafford Bridge","South Africa","Rio Brazil"]
}
}Auf der Registerkarte Abfragecode lautet der entsprechende MongoDB-Code:
db.getCollection("students").aggregate(
[{ "$project" : {"_id" : NumberInt(0),"students" : "$$ROOT"}},
{ "$lookup" : {"localField" : "students._id","from" : "units","foreignField" : "_id", "as" : "units"}},
{ "$unwind" : {"path" : "$units","preserveNullAndEmptyArrays" : false}},
{ "$lookup" : {"localField" : "students._id","from" : "sports", "foreignField" : "_id","as" : "sports"}},
{ "$unwind" : {"path" : "$sports", "preserveNullAndEmptyArrays" : false}},
{ "$match" : {"students._id" : NumberLong(1)}}
]
);Wenn ich mir das zurückgegebene Dokument ansehe, bin ich persönlich mit der Datenstruktur nicht allzu zufrieden, insbesondere bei eingebetteten Dokumenten. Wie Sie sehen können, werden _id-Felder zurückgegeben, und für die Einheiten müssen wir das Notenfeld möglicherweise nicht in die Einheiten einbetten.
Wir möchten ein Einheitenfeld mit eingebetteten Einheiten und keine anderen Felder haben. Dies führt uns zum Teil der groben Melodie. Kopieren Sie wie in den vorherigen Beiträgen den Code mit dem bereitgestellten Kopiersymbol und gehen Sie zum Aggregationsbereich, fügen Sie den Inhalt mit dem Einfügen-Symbol ein.
Das Wichtigste zuerst, der $match-Operator sollte die erste Stufe sein, also verschieben Sie ihn an die erste Position und haben Sie so etwas:
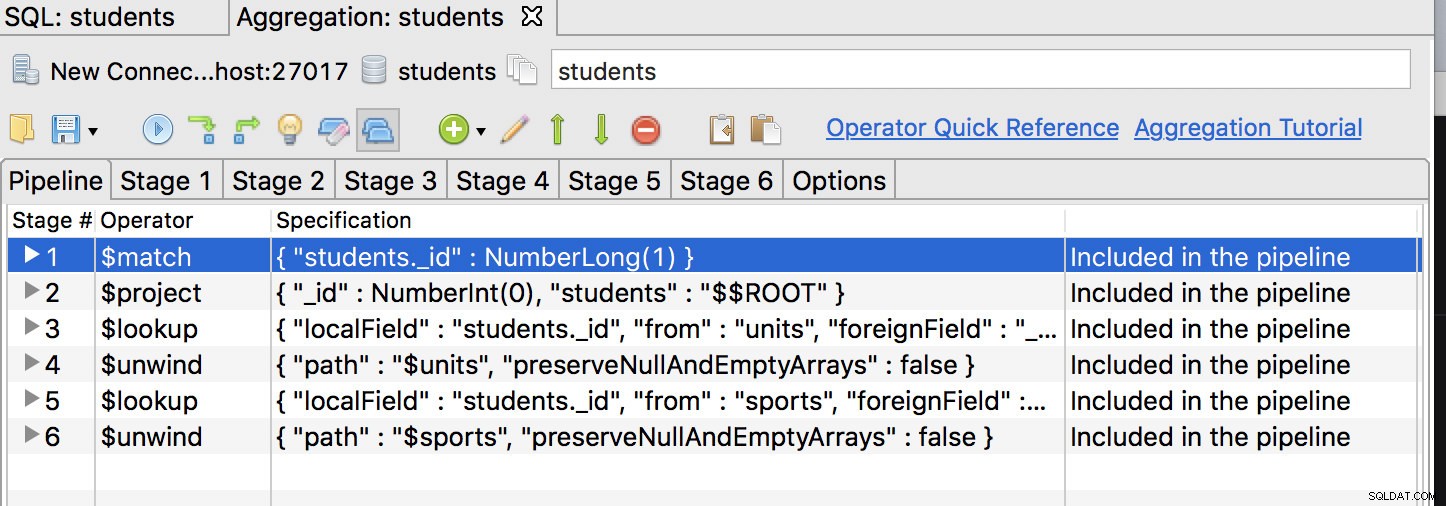
Klicken Sie auf die Registerkarte der ersten Stufe und ändern Sie die Abfrage in:
{
"_id" : NumberLong(1)
}Anschließend müssen wir die Abfrage weiter modifizieren, um viele Einbettungsstufen unserer Daten zu entfernen. Dazu fügen wir neue Felder hinzu, um Daten für die Felder zu erfassen, die wir entfernen möchten, z. B.:
db.getCollection("students").aggregate(
[
{ "$project" : { "_id" : NumberInt(0), "students" : "$$ROOT"}},
{ "$match" : {"students._id" : NumberLong(1)}},
{ "$lookup" : { "localField" : "students._id", "from" : "units","foreignField" : "_id", "as" : "units"}},
{ "$addFields" : { "_id": "$students._id","units" : "$units.grades"}},
{ "$unwind" : { "path" : "$units", "preserveNullAndEmptyArrays" : false}},
{ "$lookup" : {"localField" : "students._id", "from" : "sports", "foreignField" : "_id", "as" : "sports"}},
{ "$unwind" : { "path" : "$sports","preserveNullAndEmptyArrays" : false}},
{ "$project" : {"sports._id" : 0.0}}
]
);Wie Sie sehen können, haben wir im Feinabstimmungsprozess neue Feldeinheiten eingeführt, die den Inhalt der vorherigen Aggregationspipeline mit Noten als eingebettetes Feld überschreiben. Außerdem haben wir ein _id-Feld erstellt, um anzuzeigen, dass sich die Daten auf alle Dokumente in den Sammlungen mit demselben Wert beziehen. Die letzte Phase des $Projekts besteht darin, das _id-Feld im Sportdokument zu entfernen, sodass wir ordentlich präsentierte Daten wie unten haben.
{ "_id" : NumberInt(1),
"students" : {"name" : "James Washington", "age" : 15.0, "grade" : "A", "score" : 10.5},
"units" : {"Maths" : "A","English" : "A", "Science" : "A","History" : "B"},
"sports" : {
"tournamentsPlayed" : NumberInt(6),
"gamesParticipated" : [{"hockey" : "midfielder","football" : "striker","handball" : "goalkeeper"}],
"sportPlaces" : ["Stafford Bridge", "South Africa", "Rio Brazil"]
}
}Wir können auch einschränken, welche Felder aus SQL-Sicht zurückgegeben werden sollen. Zum Beispiel können wir den Namen des Schülers, die Einheiten, die dieser Schüler absolviert, und die Anzahl der gespielten Turniere mit mehreren JOINS mit dem folgenden Code zurückgeben:
SELECT students.name, units.grades, sports.tournamentsPlayed
FROM students
INNER JOIN units
ON students._id = units._id
INNER JOIN sports
ON students._id = sports._id
WHERE students._id = 1;Dies gibt uns nicht das angemessenste Ergebnis. Kopieren Sie es also wie gewohnt und fügen Sie es in den Aggregationsbereich ein. Wir optimieren mit dem Code unten, um das passende Ergebnis zu erhalten.
db.getCollection("students").aggregate(
[
{ "$project" : { "_id" : NumberInt(0), "students" : "$$ROOT"}},
{ "$match" : {"students._id" : NumberLong(1)}},
{ "$lookup" : { "localField" : "students._id", "from" : "units","foreignField" : "_id", "as" : "units"}},
{ "$addFields" : {"units" : "$units.grades"}},
{ "$unwind" : { "path" : "$units", "preserveNullAndEmptyArrays" : false}},
{ "$lookup" : {"localField" : "students._id", "from" : "sports", "foreignField" : "_id", "as" : "sports"}},
{ "$unwind" : { "path" : "$sports","preserveNullAndEmptyArrays" : false}},
{ "$project" : {"name" : "$students.name", "grades" : "$units.grades", "tournamentsPlayed" : "$sports.tournamentsPlayed"}
}}
]
);Dieses Aggregationsergebnis des SQL JOIN-Konzepts gibt uns eine ordentliche und präsentable Datenstruktur, die unten gezeigt wird.
{
"name" : "James Washington",
"grades" : {"Maths" : "A", "English" : "A", "Science" : "A", "History" : "B"},
"tournamentsPlayed" : NumberInt(6)
}Ziemlich einfach, oder? Die Daten sind recht gut darstellbar, als ob sie in einer einzelnen Sammlung als einzelnes Dokument gespeichert wären.
LEFT OUTER JOIN
Der LEFT OUTER JOIN wird normalerweise verwendet, um Dokumente anzuzeigen, die nicht der am häufigsten dargestellten Beziehung entsprechen. Die Ergebnismenge einer LEFT OUTER-Verknüpfung enthält alle Zeilen aus beiden Sammlungen, die die Kriterien der WHERE-Klausel erfüllen, genau wie eine INNER JOIN-Ergebnismenge. Außerdem werden alle Dokumente aus der linken Sammlung, die keine übereinstimmenden Dokumente in der rechten Sammlung haben, ebenfalls in die Ergebnismenge aufgenommen. Die aus der Tabelle auf der rechten Seite ausgewählten Felder geben NULL-Werte zurück. Alle Dokumente in der rechten Sammlung, die keine übereinstimmenden Kriterien aus der linken Sammlung haben, werden jedoch nicht zurückgegeben.
Sehen Sie sich diese beiden Sammlungen an:
Schüler
{"_id" : 1,"name" : "James Washington","age" : 15.0,"grade" : "A","score" : 10.5}
{"_id" : 2,"name" : "Clinton Ariango","age" : 14.0,"grade" : "B","score" : 7.5}
{"_id" : 4,"name" : "Mary Muthoni","age" : 16.0,"grade" : "A","score" : 11.5}Einheiten
{"_id" : 1,"Maths" : "A","English" : "A","Science" : "A","History" : "B"}
{"_id" : 2,"Maths" : "B","English" : "B","Science" : "A","History" : "B"}
{"_id" : 3,"Maths" : "A","English" : "A","Science" : "A","History" : "A"}In der Studentensammlung haben wir den _id-Feldwert nicht auf 3 gesetzt, aber in der Einheitensammlung haben wir. Ebenso gibt es keinen _id-Feldwert 4 in der Einheitensammlung. Wenn wir die Schülersammlung als linke Option im JOIN-Ansatz mit der folgenden Abfrage verwenden:
SELECT *
FROM students
LEFT OUTER JOIN units
ON students._id = units._idMit diesem Code erhalten wir folgendes Ergebnis:
{
"students" : {"_id" : 1,"name" : "James Washington","age" : 15,"grade" : "A","score" : 10.5},
"units" : {"_id" : 1,"grades" : {"Maths" : "A","English" : "A", "Science" : "A","History" : "B"}}
}
{
"students" : {"_id" : 2,"name" : "Clinton Ariango", "age" : 14,"grade" : "B", "score" : 7.5 }
}
{
"students" : {"_id" : 3,"name" : "Mary Muthoni","age" : 16,"grade" : "A","score" : 11.5},
"units" : {"_id" : 3,"grades" : {"Maths" : "A","English" : "A","Science" : "A","History" : "A"}}
}Das zweite Dokument enthält kein Einheitenfeld, da es kein übereinstimmendes Dokument in der Einheitensammlung gab. Für diese SQL-Abfrage lautet der entsprechende Mongo-Code
db.getCollection("students").aggregate(
[
{
"$project" : {"_id" : NumberInt(0), "students" : "$$ROOT"}},
{
"$lookup" : {"localField" : "students._id", "from" : "units", "foreignField" : "_id", "as" : "units"}
},
{
"$unwind" : { "path" : "$units", "preserveNullAndEmptyArrays" : true}
}
]
);Natürlich haben wir etwas über die Feinabstimmung gelernt, sodass Sie fortfahren und die Aggregationspipeline neu strukturieren können, um das gewünschte Endergebnis zu erzielen. SQL ist ein sehr mächtiges Werkzeug, was die Datenbankverwaltung betrifft. Es ist ein weites Thema für sich, Sie können auch versuchen, die IN- und GROUP BY-Klauseln zu verwenden, um den entsprechenden Code für MongoDB zu erhalten und zu sehen, wie es funktioniert.
Schlussfolgerung
Die Gewöhnung an eine neue (Datenbank-)Technologie zusätzlich zu der gewohnten kann viel Zeit in Anspruch nehmen. Relationale Datenbanken sind immer noch weiter verbreitet als die nicht-relationalen. Mit der Einführung von MongoDB haben sich die Dinge jedoch geändert und die Leute möchten es aufgrund der damit verbundenen starken Leistung so schnell wie möglich lernen.
Das Erlernen von MongoDB von Grund auf kann etwas mühsam sein, aber wir können das SQL-Wissen nutzen, um Daten in MongoDB zu manipulieren, den entsprechenden MongoDB-Code zu erhalten und ihn zu optimieren, um die am besten geeigneten Ergebnisse zu erzielen. Eines der verfügbaren Tools, um dies zu verbessern, ist Studio 3T. Es bietet zwei wichtige Funktionen, die den Umgang mit komplexen Daten erleichtern, nämlich:SQL-Abfragefunktion und den Aggregationseditor. Die Feinabstimmung von Abfragen stellt nicht nur sicher, dass Sie das beste Ergebnis erzielen, sondern verbessert auch die Leistung in Bezug auf die Zeitersparnis.



