MongoDB ist ein Dokumentendatenspeicher, den es seit über einem Jahrzehnt gibt. In den letzten Jahren hat sich MongoDB zu einem ausgereiften Produkt entwickelt, das Optionen der Enterprise-Klasse wie Skalierbarkeit, Sicherheit und Belastbarkeit bietet. Bei der anspruchsvollen Wolkenbewegung war das jedoch nicht gut genug.
Cloud-Ressourcen wie virtuelle Maschinen, Container, serverlose Rechenressourcen und Datenbanken sind derzeit sehr gefragt. Heutzutage können viele Softwarelösungen in einem Bruchteil der Zeit erstellt werden, die früher für die Bereitstellung auf der eigenen Hardware benötigt wurde. Es hat einen Trend ausgelöst und gleichzeitig die Markterwartungen verändert.
Aber die Qualität eines Onlinedienstes beschränkt sich nicht nur auf die Bereitstellung. Häufig benötigen Benutzer zusätzliche Dienste, Integrationen oder zusätzliche Funktionen, die ihnen bei ihrer Arbeit helfen. Cloud-Angebote können immer noch sehr begrenzt sein und mehr Probleme verursachen, als Sie durch die Automatisierung und Remote-Infrastruktur erreichen können.
Wie geht MongoDB Inc. also mit diesem allgemeinen Problem um?
Die Antwort war MongoDB Atlas, das interne Erweiterungen als Teil einer größeren Cloud-/Automatisierungsplattform bringt. Durch das Hinzufügen von Komponenten von Drittanbietern ist MongoDB floriert. Im heutigen Blog werden wir sehen, welche Entwickler sie haben und wie sie Ihnen helfen können, Ihre Datenverarbeitungsanforderungen zu erfüllen.
Die Gegenstände, die wir heute erkunden werden, sind...
- MongoDB-Diagramme
- MongoDB-Stich
- MongoDB Kubernetes-Integrationen mit Ops Manager
- MongoDB Cloud-Migration
- Volltextsuche
- MongoDB Data Lake (Beta)
MongoDB-Diagramme
MongoDB Charts ist einer der Dienste, auf die über die MongoDB Atlas-Plattform zugegriffen werden kann. Es bietet einfach eine einfache Möglichkeit, Ihre Daten in MongoDB zu visualisieren. Sie müssen Ihre Daten nicht in ein anderes Repository verschieben oder Ihren eigenen Code schreiben, da MongoDB Charts für die Arbeit mit Datendokumenten entwickelt wurde und die Visualisierung Ihrer Daten vereinfacht.
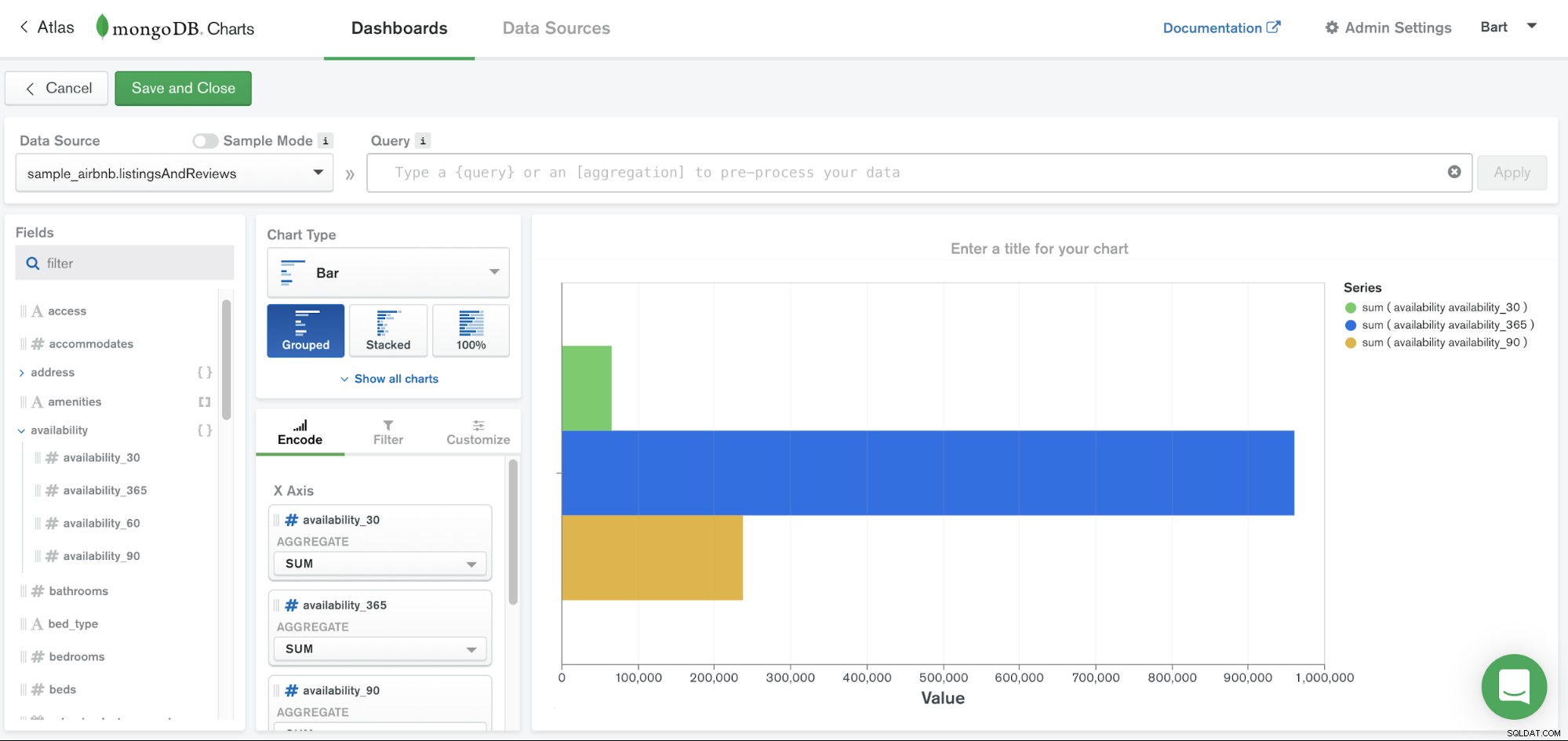
MongoDB Charts macht die Übermittlung Ihrer Daten durch die Bereitstellung integrierter Tools zu einem unkomplizierten Prozess um Visualisierungen einfach zu teilen und zusammenzuarbeiten. Die Datenvisualisierung ist eine Schlüsselkomponente, um ein klares Verständnis Ihrer Daten zu vermitteln, Korrelationen zwischen Variablen hervorzuheben und das Erkennen von Mustern und Trends in Ihrem Datensatz zu erleichtern.
Hier sind einige Schlüsselfunktionen, die Sie in den Diagrammen verwenden können.
Aggregation
Aggregation Framework ist ein operativer Prozess, der Dokumente in verschiedenen Phasen manipuliert, sie gemäß den bereitgestellten Kriterien verarbeitet und dann die berechneten Ergebnisse zurückgibt. Werte aus mehreren Dokumenten werden zusammen gruppiert, auf denen mehr Operationen durchgeführt werden können, um übereinstimmende Ergebnisse zurückzugeben.
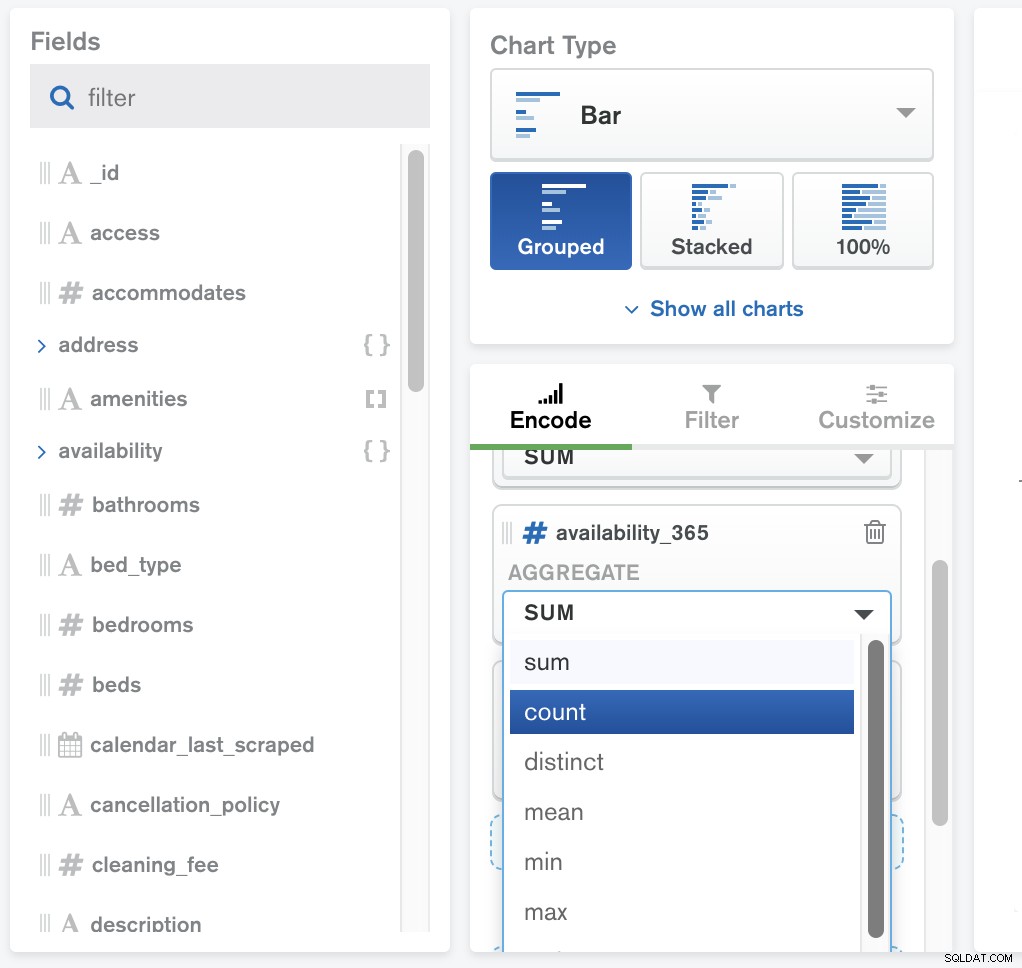
MongoDB Charts bietet integrierte Aggregationsfunktionen. Mit der Aggregation können Sie Ihre Erfassungsdaten nach einer Vielzahl von Metriken verarbeiten und Berechnungen wie Mittelwert und Standardabweichung durchführen.
Charts bieten eine nahtlose Integration mit MongoDB Atlas. Sie können MongoDB-Diagramme mit Atlas-Projekten verknüpfen und schnell mit der Visualisierung Ihrer Atlas-Clusterdaten beginnen.
Umgang mit Dokumentendaten
MongoDB Charts versteht die Vorteile des Dokumentdatenmodells von Haus aus. Es verwaltet dokumentbasierte Daten, einschließlich fester Objekte und Arrays. Die Verwendung einer verschachtelten Datenstruktur bietet die Flexibilität, Ihre Daten so zu strukturieren, wie sie für Ihre Anwendung geeignet sind, und behält gleichzeitig die Visualisierungsmöglichkeiten bei.
MongoDB Charts bietet eine integrierte Aggregationsfunktion, mit der Sie Ihre Erfassungsdaten anhand einer Vielzahl von Metriken verarbeiten können. Es ist intuitiv genug für Nicht-Entwickler zu verwenden und ermöglicht eine Self-Service-Datenanalyse, was es zu einem großartigen Tool für Datenanalyseteams macht.
MongoDB-Stitch
Haben Sie schon von serverloser Architektur gehört?
Mit Serverless komponieren Sie Ihre Anwendung in einzelne, autonome Funktionen. Jede Funktion wird vom serverlosen Anbieter gehostet und kann automatisch skaliert werden, wenn die Häufigkeit der Funktionsaufrufe zunimmt oder abnimmt. Dies erweist sich als eine sehr kostengünstige Art, Rechenressourcen zu bezahlen. Sie zahlen nur für die Zeiten, in denen Ihre Funktionen aufgerufen werden, anstatt dafür zu bezahlen, dass Ihre Anwendung immer aktiv ist und auf Anfragen in so vielen verschiedenen Instanzen wartet.
MongoDB Stitch ist eine andere Art von MongoDB-Dienst, der nur das Nützlichste verwendet die Cloud-Infrastrukturumgebungen. Es ist eine serverlose Plattform, die es Entwicklern ermöglicht, Anwendungen zu erstellen, ohne eine Serverinfrastruktur einrichten zu müssen. Stitch wird auf MongoDB Atlas erstellt und integriert automatisch die Verbindung zu Ihrer Datenbank. Sie können eine Verbindung zu Stitch über die Stitch Client SDKs herstellen, die für viele der von Ihnen entwickelten Plattformen offen sind.
MongoDB Kubernetes-Integrationen mit Ops Manager
Ops Manager ist eine Verwaltungsplattform für MongoDB-Cluster, die Sie auf Ihrer eigenen Infrastruktur ausführen. Die Funktionen von Ops Manager umfassen Überwachung, Alarmierung, Disaster Recovery, Skalierung, Bereitstellung und Upgrade von Replikatsätzen und Sharding-Clustern sowie anderen MongoDB-Produkten. Im Jahr 2018 führte MongoDB die Beta-Integration mit Kubernetes ein.
Der MongoDB Enterprise Operator ist mit Kubernetes v1.11 und höher kompatibel. Es wurde gegen Openshift 3.11 getestet. Dieser Operator erfordert Ops Manager oder Cloud Manager. Wenn wir in diesem Dokument auf „Ops Manager“ verweisen, können Sie „Cloud Manager“ ersetzen. Die Funktionalität ist die gleiche.
Die Installation ist ziemlich einfach und erfordert
- MongoDB Enterprise Operator installieren. Dies kann über die Helm- oder YAML-Datei erfolgen.
- Ops Manager-Eigenschaften sammeln.
- Erstellen Sie eine Kubernetes-ConfigMap-Datei und wenden Sie sie an
- Erstellen Sie das geheime Kubernetes-Objekt, das den Ops Manager-API-Schlüssel speichert
In diesem einfachen Beispiel verwenden wir die YAML-Datei:
kubectl apply -f crds.yaml
kubectl apply -f https://raw.githubusercontent.com/mongodb/mongodb-enterprise-kubernetes/master/mongodb-enterprise.yamlDer nächste Schritt besteht darin, die folgenden Informationen zu erhalten, die wir in der ConfigMap-Datei verwenden werden. All das finden Sie im Ops Manager.
- Basis-URL. Basis-URL ist die URL Ihres Ops Managers oder Cloud Managers.
- Projekt-ID. Die ID eines Ops Manager-Projekts, in dem der Kubernetes-Operator bereitgestellt wird.
- Benutzer. Ein vorhandener Ops Manager-Benutzername
- Öffentlicher API-Schlüssel. Wird vom Kubernetes-Operator verwendet, um eine Verbindung zum Ops Manager-REST-API-Endpunkt herzustellen
Da wir nun die erforderlichen Ops Manager-Konfigurationsinformationen erhalten haben, müssen wir eine Kubernetes-ConfigMap-Datei für Kubernetes erstellen. Zu Übungszwecken können wir diese Datei project.yaml nennen.
apiVersion: v1
kind: ConfigMap
metadata:
name:<<Name>>
namespace: mongodb
data:
projectId:<<Project ID>>
baseUrl: <<OpsManager URL>>Der nächste Schritt besteht darin, eine ConfigMap für Kubernetes und eine geheime Datei zu erstellen
kubectl apply -f my-project.yaml
kubectl -n mongodb create secret generic <<Name of credentials>> --from-literal="user=<<User>>" --from-literal="publicApiKey=<<public-api-key>>"Sobald wir das haben, können wir unseren ersten Cluster bereitstellen
apiVersion: mongodb.com/v1
kind: MongoDbReplicaSet
metadata:
name: <<Replica set name>>
namespace: mongodb
spec:
members: 3
version: 4.2.0
persistent: false
project: <<Name value specified in metadata.name of ConfigMap file>>
credentials: <<Name of credentials secret>>Ausführlichere Anweisungen finden Sie in der MongoDB-Dokumentation.
MongoDB Cloud-Migration
Der Atlas Live Migration Service kann Ihre Daten aus Ihrer bestehenden Umgebung migrieren, egal ob auf AWS, Azure, GCP oder On-Prem zu MongoDB Atlas, der globalen Cloud-Datenbank für MongoDB.
Die Migration erfolgt über einen dedizierten Replikationsdienst. Der Atlas Live-Migrationsprozess streamt Daten über einen MongoDB-gesteuerten Anwendungsserver.
Live-Migration funktioniert, indem ein Cluster in MongoDB Atlas mit Ihrer Quelldatenbank synchronisiert wird. Während dieses Vorgangs kann Ihre Anwendung weiterhin aus Ihrer Quelldatenbank lesen und schreiben. Da der Prozess bevorstehende Änderungen überwacht, werden alle repliziert, und die Migration kann online durchgeführt werden. Sie entscheiden, wann die Anwendungsverbindungseinstellung geändert und die Umstellung durchgeführt wird. Um den Prozess weniger anfällig zu machen, bietet Atlas eine Validate-Option, die den IP-Zugriff auf die Whitelist, die SSL-Konfiguration, CA usw. prüft.
Volltextsuche
Die Volltextsuche ist ein weiterer Service-Cloud-Service, der von MongoDB bereitgestellt wird und nur in MongoDB Atlas verfügbar ist. Nicht-Atlas-MongoDB-Bereitstellungen können die Textindizierung verwenden. Die Atlas-Volltextsuche basiert auf Open Source Apache Lucene. Lucene ist eine leistungsstarke Textsuchbibliothek. Lucene verfügt über eine benutzerdefinierte Abfragesyntax zum Abfragen seiner Indizes. Es ist eine Grundlage beliebter Systeme wie Elasticsearch und Apache Solr. Es ermöglicht das Erstellen eines Indexes für die Volltextsuche, das Suchen, Speichern und Lesen. Es ist vollständig in Atlas MongoDB integriert, sodass keine zusätzlichen Systeme oder Infrastrukturen bereitgestellt oder verwaltet werden müssen.
MongoDB Data Lake (Beta)
Die letzte MongoDB-Cloud-Funktion, die wir in MongoDB Data Lake erwähnen möchten. Es ist ein ziemlich neuer Dienst, der sich mit dem beliebten Konzept der Data Lakes befasst. Ein Data Lake ist ein riesiger Pool von Rohdaten, dessen Zweck noch nicht definiert ist. Anstatt Daten in einem speziell entwickelten Datenspeicher abzulegen, verschieben Sie sie in ihrem ursprünglichen Format in einen Data Lake. Dadurch entfallen die Vorabkosten für die Datenaufnahme, wie z. B. die Transformation. Sobald Daten in die platziert werden.
Die Verwendung von Atlas Data Lake zur Aufnahme Ihrer S3-Daten in Atlas-Cluster ermöglicht es Ihnen, Daten, die in Ihren AWS S3-Buckets gespeichert sind, mit Mongo Shell, MongoDB Compass und jedem MongoDB-Treiber abzufragen.
Es gibt jedoch einige Einschränkungen. Die folgenden Funktionen funktionieren noch nicht, z. B. Überwachung von Data Lakes mit Atlas-Überwachungstools, Unterstützung einzelner S3-AWS-Konten, IP-Whitelist und Beschränkungen von AWS-Konten und AWS-Sicherheitsgruppen oder keine Möglichkeit, Indizes hinzuzufügen.



