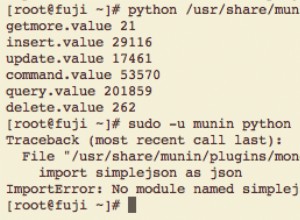
Ihre Herausforderung ergibt sich aus der Tatsache, dass Prop_Info muss von beiden Abfragen abgerufen werden. Das macht es schwierig herauszufinden, in welcher Mongo-Sammlung es leben sollte.
In MongoDB erstellen Sie Ihr Dokumentschema mit dem idealen Ziel, dass ein einzelnes Dokument alle Informationen enthält, die Sie für Ihre Abfragemuster benötigen. Falls Sie die gleichen Daten benötigen D (z. B. Prop_Info in Ihrem Fall) von zwei separaten Abfragen für zwei separate Sammlungen A zurückgegeben und B , müssen Sie zwischen den folgenden drei Strategien wählen:
-
Dduplizieren in den Dokumenten der beidenAundB, und erzwingen Sie die Konsistenz mit Ihrem Code. Dies ist in der Regel die Entwurfswahl von Hochleistungssystemen, die die Notwendigkeit einer zweiten Abfrage eliminieren möchten, auch wenn dies auf Kosten zusätzlicher Codekomplexität auf der Einfüge-/Aktualisierungsseite und mit einigen potenziellen Konsistenzproblemen geht, da Mongo nicht ACID ist. -
Setzen Sie
DinAund speichern Sie eine Referenz (DBRef oder eine andere Kombination von identifizierenden Feldern) inBdamit Sie mit einer zweiten Abfrage dorthin gelangen. Dies ist in der Regel die Designentscheidung, wenn die Anzahl der AbfragenAist die Anzahl der Anfragen anBüberschreitet . Es behältDlokal für die häufiger abgefragte Sammlung. In diesem Schemaentwurfsmuster müssen Sie nur eine zweite Abfrage durchführen, wenn SieBabfragen . -
Setzen Sie
Din einer neuen SammlungCund machen Sie eine zweite Abfrage von beidenAundB. Dies ist in der Regel die Designwahl angesichts sehr ungewisser zukünftiger Anforderungen, bei denen nicht klar ist, was die Kompromisse wären, wenn Sie sich für (1) oder (2) oben entscheiden. Es ist das "relational-ähnlichste" Schema und dasjenige, das Sie dazu zwingt, eine zweite Abfrage zu machen, wenn Sie beideAabfragen undB.
Welche Strategie Sie wählen, hängt von Ihrer Domäne, den Abfragemustern, der Unterstützung durch Ihr Object-Relational-Mapping-Framework (ORM) (falls Sie eines verwenden) und nicht zuletzt von Ihren Vorlieben ab.
In den Situationen, denen ich begegnet bin, habe ich nie (3) gewählt. Ich habe (1) in Hochleistungssituationen (Analysesysteme) verwendet. Ich habe (2) überall sonst verwendet, da die Abfragezugriffsmuster deutlich gemacht haben, wo sich die "geteilten" Daten befinden sollten.
Wenn Sie nach Auswahl Ihrer Strategie noch Unterstützung benötigen, posten Sie eine weitere SO-Frage, die sich speziell auf das Schemaentwurfsproblem angesichts der gewählten Strategie konzentriert.
Drei abschließende Tipps:
-
Wenn die gemeinsam genutzten Daten
Deine Beziehungsmultiplizität größer als 1 hat, verwenden Sie ein Array. Sie können ganze Arrays indizieren und mit$elemMatch . -
Um
Dzu aktualisieren Verwenden Sie in Strategie (1) oder (2) den atomaren Modifikator von MongoDB Operationen , von denen viele für den Betrieb mit Arrays ausgelegt sind. -
Diese SO-Frage deckt das DBRef-Zwei-Abfragemuster in der Antwort von @Stennie ab. (@Stennie arbeitet für 10gen, die Marker von MongoDB.)
Viel Glück!