Es ist immer eine gute Idee, sich der Speicherressourcen bewusst zu sein, wenn $unwind
aufgrund der auftretenden Replikation von Daten.
Verwenden von $match
Das Eingrenzen der Ergebnisse auf die spezifischen Dokumente, nach denen Sie suchen, ist natürlich eine Möglichkeit, den Speicherplatz zu reduzieren, der zum Speichern der zurückgegebenen Daten erforderlich ist.
Eine andere Möglichkeit, den Speicherbedarf zu reduzieren, ist $project
. $project ermöglicht es Ihnen, die Dokumente in der Pipeline neu zu organisieren, sodass Sie nur die Elemente zurückgeben, an denen Sie interessiert sind.
Um Ihr Beispiel zu verwenden,
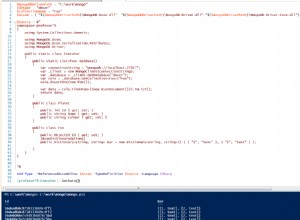
{
someInfo: "blah blah blah",
answers: [
{
email: "example@sqldat.com",
values: [
{value: 1, label: "test1"},
{value: 2, label: "test2"}
]
},
{
email: "example@sqldat.com",
values: [
{value: 6, label: "test1"},
{value: 1, label: "test2"}
]
}
]
}
Mit
db.collection.aggregate([{ $match: { <element>: <value> }}, { $project: { _id: 0, answers: 1}}])
entfernt die someInfo und andere Attribute, an denen Sie vielleicht nicht interessiert sind. Dann könnten Sie $project wieder nach dem Abwickeln...
db.collection.aggregate([
{ $match: { <element>: <value> }},
{ $project: { _id: 0, answers: 1}},
{ $unwind: "$answers"},
{ $unwind: "$answers.tags"},
{ $project: { e: "$answers.email", v: "$answers.values"}}
])
liefert ziemlich kompakte Ergebnisse wie:
{ e: "example@sqldat.com", v: { value: 1, label: "test1" } }
{ e: "example@sqldat.com", v: { value: 2, label: "test2" } }
{ e: "example@sqldat.com", v: { value: 6, label: "test1" } }
{ e: "example@sqldat.com", v: { value: 1, label: "test2" } }
Obwohl die Attributnamen aus einem Buchstaben die Lesbarkeit für Menschen verringern, wird die Größe der Daten verringert, die durch lange, wiederholte Attributnamen aufgeblasen werden.