Erkunden Sie die Architektur von Hadoop, dem am weitesten verbreiteten Framework zum Speichern und Verarbeiten riesiger Datenmengen.
In diesem Artikel werden wir die Hadoop-Architektur untersuchen. Der Artikel erläutert die Hadoop-Architektur und die Komponenten der Hadoop-Architektur, nämlich HDFS, MapReduce und YARN. In diesem Artikel werden wir die Hadoop-Architektur zusammen mit dem Diagramm der Hadoop-Architektur im Detail untersuchen.
Beginnen wir nun mit der Hadoop-Architektur.
Hadoop-Architektur
Das Ziel des Designs von Hadoop ist die Entwicklung eines kostengünstigen, zuverlässigen und skalierbaren Frameworks, das die wachsende Zahl von Big Data speichert und analysiert.
Apache Hadoop ist ein Software-Framework, das von der Apache Software Foundation zum Speichern und Verarbeiten großer Datensätze unterschiedlicher Größe und Formate entwickelt wurde.
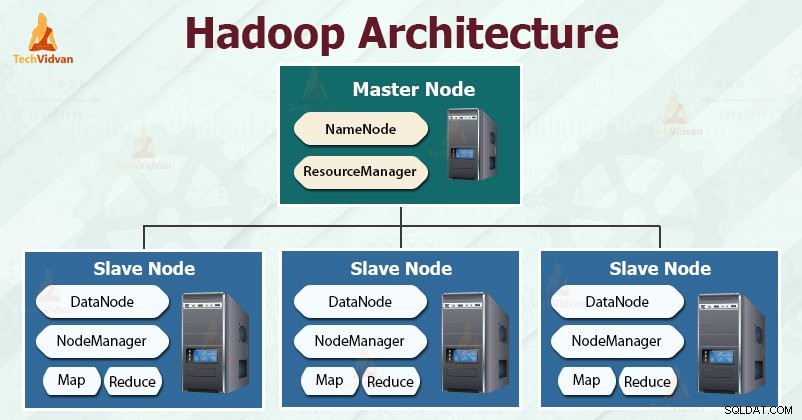
Hadoop folgt dem Master-Slave Architektur zur effektiven Speicherung und Verarbeitung großer Datenmengen. Die Master-Knoten weisen den Slave-Knoten Aufgaben zu.
Die Slave-Knoten sind für das Speichern der eigentlichen Daten und das Ausführen der eigentlichen Berechnung/Verarbeitung verantwortlich. Die Master-Knoten sind für das Speichern der Metadaten und das Verwalten der Ressourcen im gesamten Cluster verantwortlich.
Slave-Knoten speichern die eigentlichen Geschäftsdaten, während der Master die Metadaten speichert.
Die Hadoop-Architektur besteht aus drei Schichten. Sie sind:
- Speicherschicht (HDFS)
- Ressourcenverwaltungsebene (YARN)
- Verarbeitungsebene (MapReduce)
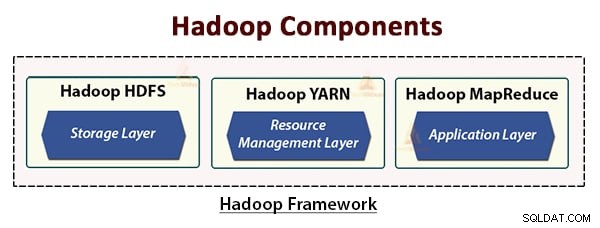
HDFS, YARN und MapReduce sind die Kernkomponenten des Hadoop-Frameworks.
Lassen Sie uns nun diese drei Kernkomponenten im Detail untersuchen.
1. HDFS
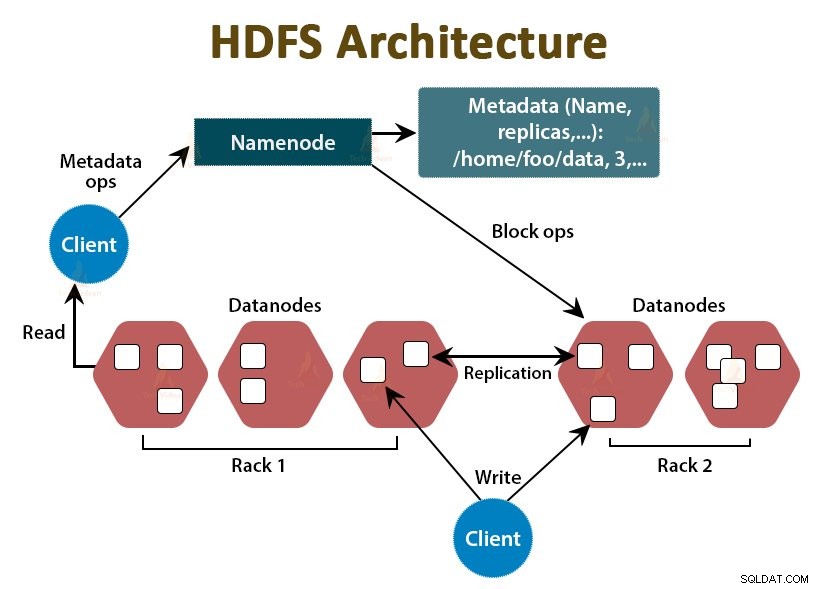
HDFS ist das Hadoop Distributed File System , das auf preiswerter handelsüblicher Hardware läuft. Es ist die Speicherschicht für Hadoop. Die Dateien in HDFS sind in Blöcke von Blockgröße unterteilt, die als Datenblöcke bezeichnet werden.
Diese Blöcke werden dann auf den Slave-Knoten im Cluster gespeichert. Die Blockgröße beträgt standardmäßig 128 MB, die wir nach unseren Anforderungen konfigurieren können.
Wie Hadoop folgt auch HDFS der Master-Slave-Architektur. Es besteht aus zwei Daemons – NameNode und DataNode. Der NameNode ist der Master-Daemon, der auf dem Master-Knoten läuft. Die DataNodes sind der Slave-Daemon, der auf den Slave-Knoten läuft.
NameNode
NameNode speichert die Metadaten des Dateisystems, dh Dateinamen, Informationen über Blöcke einer Datei, Speicherorte, Berechtigungen usw. Er verwaltet die Datanodes.
Datenknoten
DataNodes sind die Slave-Knoten, die die eigentlichen Geschäftsdaten speichern. Es bedient die Lese-/Schreibanforderungen des Clients basierend auf den NameNode-Anweisungen.
DataNodes speichert die Blöcke der Dateien und NameNode speichert die Metadaten wie Blockorte, Berechtigungen usw.
2. MapReduce
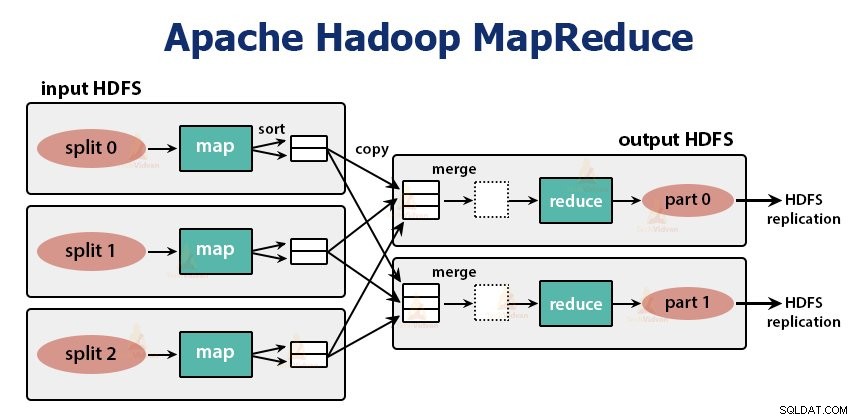
Es ist die Datenverarbeitungsschicht von Hadoop. Es handelt sich um ein Software-Framework zum Schreiben von Anwendungen, die riesige Datenmengen (im Bereich von Terabyte bis Petabyte) parallel auf dem Cluster von handelsüblicher Hardware verarbeiten.
Das MapReduce-Framework arbeitet mit den
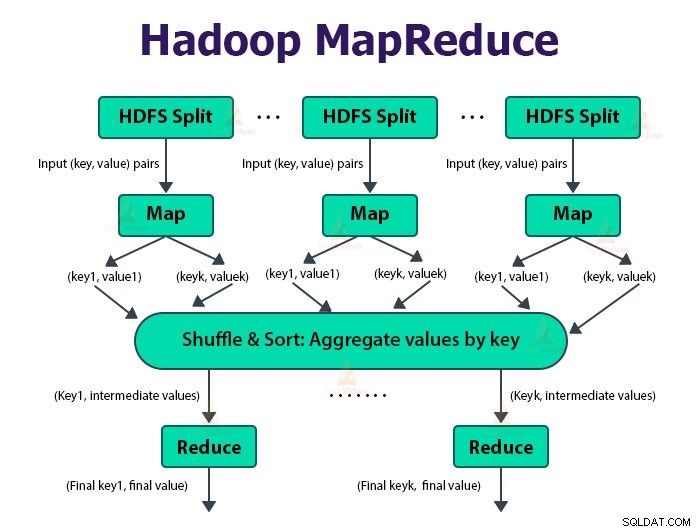
Der MapReduce-Job ist die Arbeitseinheit, die der Client ausführen möchte. Der MapReduce-Job besteht hauptsächlich aus den Eingabedaten, dem MapReduce-Programm und den Konfigurationsinformationen. Hadoop führt die MapReduce-Jobs aus, indem es sie in zwei Arten von Aufgaben unterteilt, die Zuordnungsaufgaben sind und Aufgaben reduzieren . Das Hadoop YARN hat diese Aufgaben geplant und wird auf den Knoten im Cluster ausgeführt.
Aufgrund einiger ungünstiger Bedingungen werden die Aufgaben, wenn sie fehlschlagen, automatisch auf einem anderen Knoten neu geplant.
Der Benutzer definiert die Kartenfunktion und die Reduce-Funktion zum Ausführen des MapReduce-Jobs.
Die Eingabe für die Map-Funktion und die Ausgabe der Reduce-Funktion ist das Schlüssel-Wert-Paar.
Die Funktion der Zuordnungsaufgaben besteht darin, die Daten zu laden, zu analysieren, zu filtern und umzuwandeln. Die Ausgabe der Map-Aufgabe ist die Eingabe für die Reduce-Aufgabe. Aufgabe reduzieren führt dann eine Gruppierung und Aggregation der Ausgabe der Kartenaufgabe durch.
Die MapReduce-Aufgabe wird in zwei Phasen durchgeführt-
1. Kartenphase
a. RecordReader
Hadoop teilt die Eingaben für den MapReduce-Job in Aufteilungen fester Größe auf, die als Eingabeaufteilungen bezeichnet werden oder Splits. Der RecordReader wandelt diese Aufteilungen in Datensätze um und parst die Daten in Datensätze, parst jedoch nicht die Datensätze selbst. RecordReader stellt der Mapper-Funktion die Daten in Schlüssel-Wert-Paaren bereit.
b. Karte
In der Zuordnungsphase erstellt Hadoop eine Zuordnungsaufgabe, die eine benutzerdefinierte Funktion namens Zuordnungsfunktion für jeden Datensatz in der Eingabeaufteilung ausführt. Es generiert null oder mehrere zwischenzeitliche Schlüssel-Wert-Paare als Map-Task-Ausgabe.
Die Map-Aufgabe schreibt ihre Ausgabe auf die lokale Festplatte. Diese Zwischenausgabe wird dann von den Reduziertasks verarbeitet, die eine benutzerdefinierte Reduzierfunktion ausführen, um die endgültige Ausgabe zu erzeugen. Sobald der Job abgeschlossen ist, wird die Kartenausgabe geleert.
c. Combiner
Die Eingabe für die einzelne Reduktionsaufgabe ist die Ausgabe von allen Mappern, die von allen Abbildungsaufgaben ausgegeben wird. Mit Hadoop kann der Benutzer eine Combiner-Funktion definieren, die auf der Kartenausgabe ausgeführt wird.
Kombinierer gruppiert die Daten in der Map-Phase, bevor sie an Reducer übergeben werden. Es kombiniert die Ausgabe der Map-Funktion, die dann als Eingabe an die Reduce-Funktion übergeben wird.
d. Partitionierer
Wenn es mehrere Reducer gibt, teilen die Map-Tasks ihre Ausgabe auf, wobei jeder eine Partition für jeden Reduce-Task erstellt. In jeder Partition kann es viele Schlüssel und ihre zugeordneten Werte geben, aber die Datensätze für jeden gegebenen Schlüssel befinden sich alle in einer einzigen Partition.
Mit Hadoop können Benutzer die Partitionierung steuern, indem sie eine benutzerdefinierte Partitionierungsfunktion angeben. Im Allgemeinen gibt es einen Standard-Partitionierer, der die Schlüssel mithilfe der Hash-Funktion bündelt.
2. Reduzierphase:
Die verschiedenen Phasen der Reduzierungsaufgabe sind wie folgt:
a. Sortieren und Mischen:
Die Reducer-Aufgabe beginnt mit einem Shuffle-and-Sort-Schritt. Der Hauptzweck dieser Phase besteht darin, die äquivalenten Schlüssel zusammen zu sammeln. Die Sort-and-Shuffle-Phase lädt die vom Partitionierer geschriebenen Daten auf den Knoten herunter, auf dem Reducer läuft.
Es sortiert jedes Datenstück in eine große Datenliste. Das MapReduce-Framework führt dieses Sortieren und Mischen durch, sodass wir es in der Reduce-Aufgabe leicht iterieren können.
Das Sortieren und Mischen werden vom Framework automatisch durchgeführt. Der Entwickler kann über das Comparator-Objekt steuern, wie die Schlüssel sortiert und gruppiert werden.
b. Reduzieren:
Der Reducer, bei dem es sich um die benutzerdefinierte Reduzierungsfunktion handelt, wird einmal pro Tastengruppierung ausgeführt. Der Reducer filtert, aggregiert und kombiniert Daten auf verschiedene Weise. Sobald die Reduzierungsaufgabe abgeschlossen ist, gibt sie dem OutputFormat null oder mehr Schlüssel-Wert-Paare. Die Ausgabe des Reduzieren-Tasks wird in Hadoop HDFS gespeichert.
c. Ausgabeformat
Es nimmt die Ausgabe des Reducers und schreibt sie von RecordWriter in die HDFS-Datei. Standardmäßig trennt es Schlüssel, Wert durch einen Tabulator und jeden Datensatz durch ein Zeilenumbruchzeichen.
3. GARN
YARN steht für Yet Another Resource Negotiator . Es ist die Ressourcenverwaltungsschicht von Hadoop. Es wurde in Hadoop 2 eingeführt.
YARN wurde mit der Idee entwickelt, die Funktionen der Jobplanung und des Ressourcenmanagements in separate Daemons aufzuteilen. Die Grundidee besteht darin, einen globalen ResourceManager und Anwendungsmaster pro Anwendung zu haben, wobei die Anwendung ein einzelner Job oder DAG von Jobs sein kann.
YARN besteht aus ResourceManager, NodeManager und ApplicationMaster pro Anwendung.
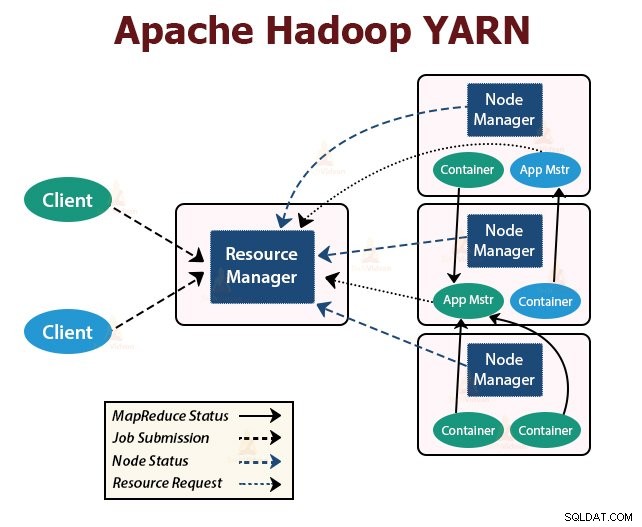
1. Ressourcenmanager
Es verteilt Ressourcen zwischen allen Anwendungen im Cluster.
Es besteht aus zwei Hauptkomponenten, dem Scheduler und dem ApplicationManager.
a. Planer
- Der Scheduler weist den verschiedenen Anwendungen, die im Cluster ausgeführt werden, unter Berücksichtigung der Kapazitäten, Warteschlangen usw. Ressourcen zu.
- Es ist ein reiner Scheduler. Der Status der Anwendung wird nicht überwacht oder nachverfolgt.
- Scheduler garantiert nicht den Neustart der fehlgeschlagenen Aufgaben, die entweder aufgrund eines Anwendungsfehlers oder eines Hardwarefehlers fehlgeschlagen sind.
- Es führt die Planung basierend auf den Ressourcenanforderungen der Anwendungen durch.
b. Anwendungsmanager
- Sie sind für die Annahme der Stellenangebote verantwortlich.
- ApplicationManager verhandelt den ersten Container zum Ausführen des anwendungsspezifischen ApplicationMaster.
- Sie bieten einen Dienst zum Neustarten des ApplicationMaster-Containers bei einem Fehler.
- Der ApplicationMaster pro Anwendung ist für die Aushandlung von Containern vom Scheduler verantwortlich. Es verfolgt und überwacht ihren Status und Fortschritt.
2. NodeManager:
NodeManager läuft auf den Slave-Knoten. Es ist für Container verantwortlich, überwacht die Nutzung der Maschinenressourcen, dh CPU, Speicher, Festplatte, Netzwerknutzung, und meldet diese an den ResourceManager oder Scheduler.
3. Bewerbungsmaster:
Der ApplicationMaster pro Anwendung ist eine Framework-spezifische Bibliothek. Es ist für das Aushandeln von Ressourcen vom ResourceManager verantwortlich. Es arbeitet mit dem/den NodeManager(n) zusammen, um die Aufgaben auszuführen und zu überwachen.
Zusammenfassung
In diesem Artikel haben wir die Hadoop-Architektur untersucht. Der Hadoop folgt der Master-Slave-Topologie. Die Master-Knoten weisen den Slave-Knoten Aufgaben zu. Die Architektur umfasst drei Schichten:HDFS, YARN und MapReduce.
HDFS ist das verteilte Dateisystem in Hadoop zum Speichern von Big Data. MapReduce ist das Verarbeitungsframework für die verteilte Verarbeitung großer Datenmengen im Hadoop-Cluster. YARN ist für die Verwaltung der Ressourcen zwischen den Anwendungen im Cluster verantwortlich.
Der HDFS-Daemon NameNode und der YARN-Daemon ResourceManager werden auf dem Master-Knoten im Hadoop-Cluster ausgeführt. Auf den Slave-Knoten laufen der HDFS-Daemon DataNode und der YARN NodeManager.
HDFS und das MapReduce-Framework werden auf denselben Knoten ausgeführt, was zu einer sehr hohen aggregierten Bandbreite im gesamten Cluster führt.
Lernen Sie weiter!!



