Bedürftig, alles über den Hadoop-Cluster zu erfahren?
Hadoop ist ein Software-Framework zum Analysieren und Speichern großer Datenmengen über Cluster von handelsüblicher Hardware hinweg. In diesem Artikel untersuchen wir einen Hadoop-Cluster.
Beginnen wir zunächst mit einer Einführung in Cluster.
Was ist ein Cluster?
Ein Cluster ist eine Sammlung von Knoten. Knoten sind nichts anderes als ein Verbindungs-/Schnittpunkt innerhalb eines Netzwerks.
Ein Computercluster ist eine Ansammlung von Computern, die mit einem Netzwerk verbunden sind, miteinander kommunizieren können und als ein einziges System funktionieren.
Was ist ein Hadoop-Cluster?
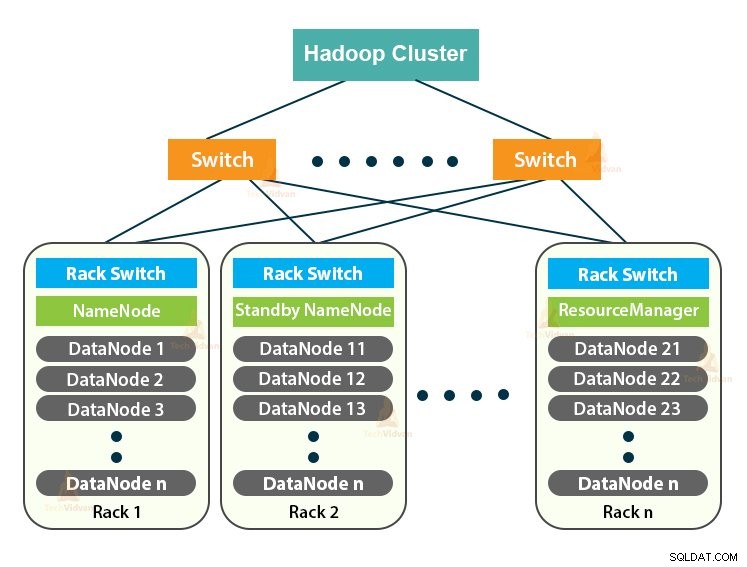
Hadoop-Cluster ist nur ein Computer-Cluster, der für die verteilte Verarbeitung einer großen Datenmenge verwendet wird.
Es ist ein Rechencluster, der zum Speichern und Analysieren großer Mengen unstrukturierter oder strukturierter Daten in einer verteilten Computerumgebung entwickelt wurde.
Hadoop-Cluster werden auch als Shared-Nothing-Systeme bezeichnet da außer der Netzwerkbandbreite nichts zwischen den Knoten im Cluster geteilt wird. Dies verringert die Verarbeitungslatenz.
Daher wird die Cluster-weite Latenzzeit minimiert, wenn es erforderlich ist, Abfragen für große Datenmengen zu verarbeiten.
Lassen Sie uns nun die Architektur des Hadoop-Clusters untersuchen.
Architektur des Hadoop-Clusters
Der Hadoop-Cluster folgt einer Master-Slave-Architektur. Es besteht aus dem Master-Knoten, den Slave-Knoten und dem Client-Knoten.
1. Master im Hadoop-Cluster
Der Master im Hadoop-Cluster ist eine Hochleistungsmaschine mit einer hohen Konfiguration von Speicher und CPU. Die beiden Daemons NameNode und ResourceManager werden auf dem Master-Knoten ausgeführt.
a. Funktionen von NameNode
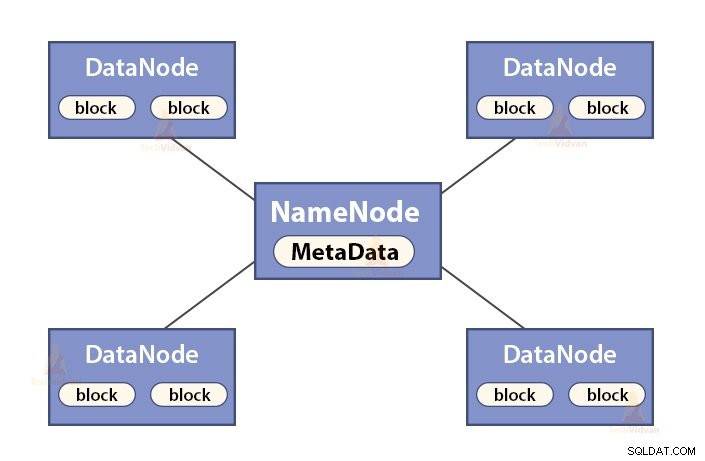
NameNode ist ein Masterknoten im Hadoop HDFS . NameNode verwaltet den Namespace des Dateisystems. Es speichert Dateisystem-Metadaten im Speicher für einen schnellen Abruf. Daher sollte es auf High-End-Rechnern konfiguriert werden.
Die Funktionen von NameNode sind:
- Verwaltet den Namensraum des Dateisystems
- Speichert Metadaten über Blöcke einer Datei, blockiert den Speicherort, Berechtigungen usw.
- Es führt die Namensraumoperationen des Dateisystems aus, wie das Öffnen, Schließen, Umbenennen von Dateien und Verzeichnissen usw.
- Es pflegt und verwaltet den DataNode.
b. Funktionen des Ressourcenmanagers
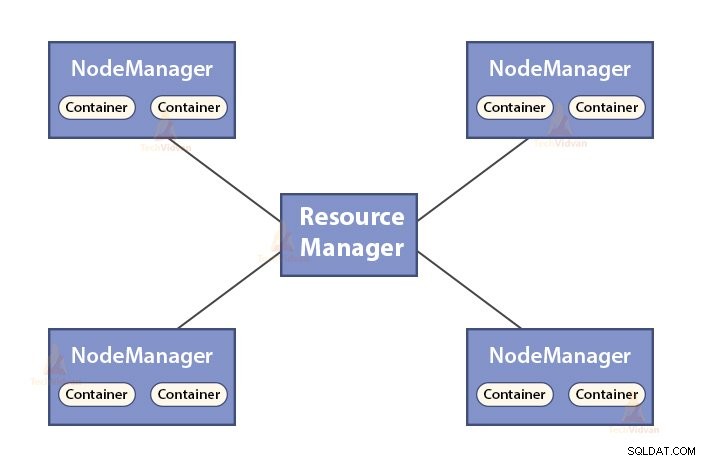
- ResourceManager ist der Master-Daemon von YARN.
- Der ResourceManager verteilt die Ressourcen zwischen allen Anwendungen im System.
- Es verfolgt aktive und tote Knoten im Cluster.
2. Slaves im Hadoop-Cluster
Slaves im Hadoop-Cluster sind kostengünstige Standardhardware. Die beiden Daemons, die DataNodes und die YARN NodeManagers sind, laufen auf den Slave-Knoten.
a. Funktionen von DataNodes
- DataNodes speichert die eigentlichen Geschäftsdaten. Es speichert die Blöcke einer Datei.
- Es führt die Erstellung, Löschung und Replikation von Blöcken basierend auf den Anweisungen von NameNode durch.
- DataNode ist für die Bereitstellung von Lese-/Schreiboperationen des Clients verantwortlich.
b. Funktionen des NodeManagers
- NodeManager ist der Slave-Daemon von YARN.
- Es ist für Container verantwortlich, überwacht deren Ressourcennutzung (wie CPU, Festplatte, Arbeitsspeicher, Netzwerk) und meldet dasselbe an den ResourceManager.
- Der NodeManager überprüft auch den Zustand des Knotens, auf dem er ausgeführt wird.
3. Client-Knoten im Hadoop-Cluster
Client-Knoten in Hadoop sind weder Master-Knoten noch Slave-Knoten. Auf ihnen ist Hadoop mit allen Cluster-Einstellungen installiert.
Funktionen von Client-Knoten
- Client-Knoten laden Daten in den Hadoop-Cluster.
- Es sendet MapReduce-Jobs, die beschreiben, wie diese Daten verarbeitet werden sollen.
- Ergebnisse des Auftrags nach Abschluss der Verarbeitung abrufen.
Wir können den Hadoop-Cluster skalieren, indem wir weitere Knoten hinzufügen. Dadurch wird Hadoop linear skalierbar . Mit jedem hinzugefügten Knoten erhalten wir eine entsprechende Steigerung des Durchsatzes. Wenn wir „n“ Knoten haben, ergibt das Hinzufügen von 1 Knoten (1/n) zusätzliche Rechenleistung.
Einzelknoten-Hadoop-Cluster vs. Mehrknoten-Hadoop-Cluster
1. Hadoop-Cluster mit einem Knoten
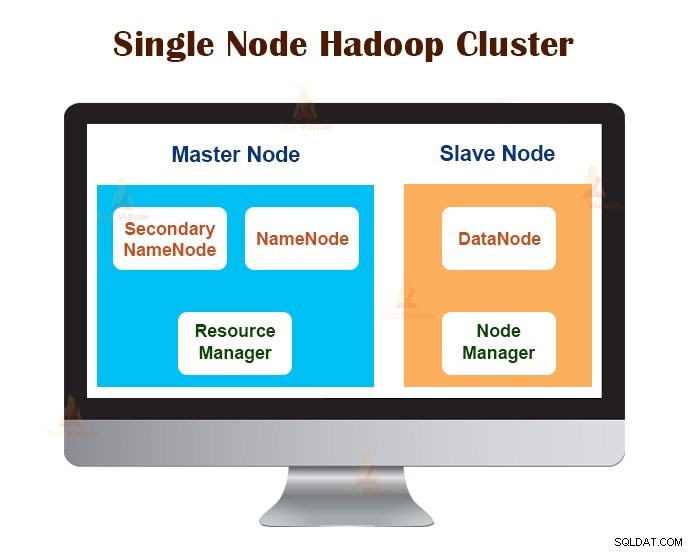
Single Node Hadoop Cluster wird auf einem einzelnen Computer bereitgestellt. Alle Daemons wie NameNode, DataNode, ResourceManager, NodeManager laufen auf demselben Rechner/Host.
In einem Single-Node-Cluster-Setup läuft alles auf einer einzigen JVM-Instanz. Der Hadoop-Benutzer musste keine Konfigurationseinstellungen vornehmen, außer der Variable JAVA_HOME.
Der standardmäßige Replikationsfaktor für einen Hadoop-Cluster mit einem Knoten ist immer 1.
2. Hadoop-Cluster mit mehreren Knoten
Multi-Node-Hadoop-Cluster wird auf mehreren Computern bereitgestellt. Alle Daemons im Hadoop-Cluster mit mehreren Knoten sind aktiv und werden auf verschiedenen Maschinen/Hosts ausgeführt.
Ein Hadoop-Cluster mit mehreren Knoten folgt einer Master-Slave-Architektur. Die Daemons Namenode und ResourceManager laufen auf den Masterknoten, die High-End-Computermaschinen sind.
Die Daemons DataNodes und NodeManagers laufen auf den Slave-Knoten (Worker-Knoten), bei denen es sich um kostengünstige Standardhardware handelt.
Im Multi-Node-Hadoop-Cluster können Slave-Rechner an jedem Ort vorhanden sein, unabhängig vom Standort des physischen Standorts des Master-Servers.
Im Hadoop-Cluster verwendete Kommunikationsprotokolle
Die HDFS-Kommunikationsprotokolle sind auf dem TCP/IP-Protokoll geschichtet. Ein Client baut eine Verbindung mit dem NameNode über den konfigurierbaren TCP-Port auf der NameNode-Maschine auf.
Der Hadoop-Cluster stellt über das ClientProtocol eine Verbindung zum Client her. Darüber hinaus kommuniziert der DataNode mit dem NameNode unter Verwendung des DataNode-Protokolls.
Die RPC-Abstraktion (Remote Procedure Call) umschließt das Client-Protokoll und das DataNode-Protokoll. NameNode initiiert standardmäßig keine RPCs. Es antwortet nur auf RPC-Anfragen, die von Clients oder DataNodes ausgegeben werden.
Best Practices für die Erstellung von Hadoop-Clustern
Die Leistung eines Hadoop-Clusters hängt von verschiedenen Faktoren ab, die auf den gut dimensionierten Hardwareressourcen basieren, die CPU, Arbeitsspeicher, Netzwerkbandbreite, Festplatte und andere gut konfigurierte Softwareschichten verwenden.
Der Aufbau eines Hadoop-Clusters ist keine triviale Aufgabe. Dabei müssen verschiedene Faktoren wie die Auswahl der richtigen Hardware, die Dimensionierung der Hadoop-Cluster und die Konfiguration des Hadoop-Clusters berücksichtigt werden.
Sehen wir uns nun jeden einzelnen im Detail an.
1. Auswahl der richtigen Hardware für Hadoop-Cluster
Viele Unternehmen befinden sich beim Einrichten einer Hadoop-Infrastruktur in einer schwierigen Lage, da sie nicht wissen, welche Art von Maschinen sie zum Einrichten einer optimierten Hadoop-Umgebung kaufen müssen und welche ideale Konfiguration sie verwenden müssen.
Bei der Auswahl der richtigen Hardware für den Hadoop-Cluster sind folgende Punkte zu beachten:
- Das Datenvolumen, das der Cluster verarbeiten wird.
- Die Art der Workloads, mit denen der Cluster umgehen wird (CPU-gebunden, E/A-gebunden).
- Methodik der Datenspeicherung wie Datencontainer, verwendete Datenkomprimierungstechniken, falls vorhanden.
- Eine Datenaufbewahrungsrichtlinie, d. h. wie lange wir die Daten aufbewahren wollen, bevor sie gelöscht werden.
2. Dimensionierung des Hadoop-Clusters
Bei der Bestimmung der Größe des Hadoop-Clusters sollte das Datenvolumen, das die Hadoop-Benutzer auf dem Hadoop-Cluster verarbeiten werden, eine wichtige Überlegung sein.
Die Kenntnis des zu verarbeitenden Datenvolumens hilft bei der Entscheidung, wie viele Knoten zur effizienten Verarbeitung der Daten und der für jeden Knoten erforderlichen Speicherkapazität erforderlich sind. Es sollte ein Gleichgewicht zwischen der Leistung und den Kosten der genehmigten Hardware bestehen.
3. Hadoop-Cluster konfigurieren
Die ideale Konfiguration für den Hadoop-Cluster zu finden, ist keine leichte Aufgabe. Das Hadoop-Framework muss an den verwendeten Cluster und auch an den Job angepasst werden.
Der beste Weg, um die ideale Konfiguration für den Hadoop-Cluster zu bestimmen, besteht darin, die Hadoop-Jobs mit der verfügbaren Standardkonfiguration auszuführen, um eine Basislinie zu erhalten. Danach können wir die Protokolldateien des Jobverlaufs analysieren, um festzustellen, ob es Ressourcenschwächen gibt oder ob die Ausführung der Jobs länger dauert als erwartet.
Wenn ja, dann ändern Sie die Konfiguration. Durch Wiederholen des gleichen Vorgangs kann die Konfiguration des Hadoop-Clusters so optimiert werden, dass sie den Geschäftsanforderungen am besten entspricht.
Die Leistung des Hadoop-Clusters hängt stark von den den Daemons zugewiesenen Ressourcen ab. Für kleine bis mittlere Datenkontexte reserviert Hadoop einen CPU-Kern auf jedem DataNode, während es für lange Datasets 2 CPU-Kerne auf jedem DataNode für HDFS- und MapReduce-Daemons zuweist.
Hadoop-Clusterverwaltung
Bei der Bereitstellung des Hadoop-Clusters in der Produktion ist es offensichtlich, dass es entlang aller Dimensionen wie Volumen, Vielfalt und Geschwindigkeit skaliert werden sollte.
Verschiedene Merkmale, die es besitzen sollte, um produktionsreif zu werden, sind – Verfügbarkeit rund um die Uhr, Robustheit, Verwaltbarkeit und Leistung. Das Hadoop-Cluster-Management ist der Hauptaspekt der Big-Data-Initiative.
Das beste Tool für die Verwaltung von Hadoop-Clustern sollte die folgenden Funktionen aufweisen:-
- Es muss rund um die Uhr Hochverfügbarkeit, Ressourcenbereitstellung, vielfältige Sicherheit, Workload-Management, Zustandsüberwachung und Leistungsoptimierung gewährleisten. Außerdem muss es Jobplanung, Richtlinienverwaltung, Sicherung und Wiederherstellung über einen oder mehrere Knoten bereitstellen.
- Implementieren Sie redundante HDFS-NameNode-Hochverfügbarkeit mit Lastenausgleich, Hot-Standbys, Neusynchronisierung und automatischem Failover.
- Durchsetzung richtlinienbasierter Kontrollen, die verhindern, dass eine Anwendung einen unverhältnismäßigen Anteil an Ressourcen in einem bereits ausgelasteten Hadoop-Cluster beansprucht.
- Durchführen von Regressionstests zur Verwaltung der Bereitstellung beliebiger Softwareschichten über Hadoop-Cluster. Dadurch soll sichergestellt werden, dass keine Jobs oder Daten abstürzen oder im täglichen Betrieb auf Engpässe stoßen.
Vorteile des Hadoop-Clusters
Die verschiedenen Vorteile des Hadoop-Clusters sind:
1. Skalierbar
Hadoop-Cluster sind skalierbar. Wir können dem Hadoop-Cluster beliebig viele Knoten ohne Ausfallzeiten und ohne zusätzlichen Aufwand hinzufügen. Mit jedem hinzugefügten Knoten erhalten wir eine entsprechende Steigerung des Durchsatzes.
2. Robustheit
Der Hadoop-Cluster ist vor allem für seinen zuverlässigen Speicher bekannt. Es kann Daten zuverlässig speichern, selbst in Fällen wie DataNode-Ausfall, NameNode-Ausfall und Netzwerkpartitionierung. Der DataNode sendet periodisch ein Heartbeat-Signal an den NameNode.
In der Netzwerkpartition wird eine Reihe von DataNodes vom NameNode getrennt, wodurch NameNode keinen Heartbeat von diesen DataNodes empfängt. NameNode betrachtet diese DataNodes dann als tot und leitet keine I/O-Anfrage an sie weiter.
Außerdem unterschreitet der Replikationsfaktor der in diesen DataNodes gespeicherten Blöcke ihren angegebenen Wert. Als Ergebnis initiiert NameNode dann die Replikation dieser Blöcke und erholt sich von dem Fehler.
3. Cluster-Neuausgleich
Die Hadoop HDFS-Architektur führt automatisch einen Cluster-Neuausgleich durch. Wenn der freie Speicherplatz im DataNode unter den Schwellenwert fällt, verschiebt die HDFS-Architektur automatisch einige Daten auf einen anderen DataNode, wo genügend Speicherplatz verfügbar ist.
4. Kostengünstig
Die Einrichtung des Hadoop-Clusters ist kostengünstig, da es sich um kostengünstige Standardhardware handelt. Jedes Unternehmen kann problemlos einen leistungsstarken Hadoop-Cluster einrichten, ohne viel für teure Serverhardware auszugeben.
Außerdem überwinden Hadoop-Cluster mit ihrer verteilten Speichertopologie die Einschränkungen des traditionellen Systems. Der begrenzte Speicherplatz kann einfach erweitert werden, indem dem System zusätzliche kostengünstige Speichereinheiten hinzugefügt werden.
5. Flexibel
Hadoop-Cluster sind äußerst flexibel, da sie Daten jeder Art verarbeiten können, entweder strukturiert, halbstrukturiert oder unstrukturiert, und in jeder Größe von Gigabyte bis Petabyte.
6. Schnelle Bearbeitung
In Hadoop Cluster können Daten in einer verteilten Umgebung parallel verarbeitet werden. Dies bietet Hadoop schnelle Datenverarbeitungsfunktionen. Hadoop-Cluster können Terabytes oder Petabytes an Daten innerhalb von Sekundenbruchteilen verarbeiten.
7. Datenintegrität
Um Datenblöcke auf Beschädigungen durch fehlerhafte Software, Fehler in einem Speichergerät usw. zu prüfen, implementiert der Hadoop-Cluster eine Prüfsumme für jeden Block der Datei. Wenn es einen beschädigten Block findet, sucht es ihn von einem anderen DataNode, der die Kopie desselben Blocks enthält. Somit bewahrt der Hadoop-Cluster die Datenintegrität.
Zusammenfassung
Nachdem wir diesen Artikel gelesen haben, können wir sagen, dass der Hadoop-Cluster ein spezieller Rechencluster ist, der für die Analyse und Speicherung von Big Data entwickelt wurde. Hadoop Cluster folgt einer Master-Slave-Architektur.
Der Master-Knoten ist die High-End-Computermaschine, und die Slave-Knoten sind Maschinen mit normaler CPU- und Speicherkonfiguration. Wir haben auch gesehen, dass der Hadoop-Cluster auf einem einzelnen Computer namens Single-Node-Hadoop-Cluster oder auf mehreren Computern namens Multi-Node-Hadoop-Cluster eingerichtet werden kann.
In diesem Artikel haben wir auch die Best Practices behandelt, die beim Erstellen eines Hadoop-Clusters zu befolgen sind. Wir haben auch viele Vorteile des Hadoop-Clusters gesehen, darunter Skalierbarkeit, Flexibilität, Kosteneffizienz usw.



