In Teil 1 dieser Reihe über Apache HBase-Snapshots haben Sie gelernt, wie Sie die neue Snapshots-Funktion verwenden, und ein wenig Theorie hinter der Implementierung. Jetzt ist es an der Zeit, etwas tiefer in die technischen Details einzutauchen.
Was ist eine Tabelle?
Eine HBase-Tabelle besteht aus einer Reihe von Metadateninformationen und einer Reihe von Schlüssel/Wert-Paaren:
- Tabelleninfo :Eine Manifestdatei, die die „Einstellungen“ der Tabelle beschreibt, wie z. B. Spaltenfamilien, Komprimierungs- und Codierungscodecs, Bloomfiltertypen usw.
- Regionen :Die „Partitionen“ der Tabelle werden Regionen genannt. Jede Region ist für die Handhabung eines zusammenhängenden Satzes von Schlüsseln/Werten verantwortlich, und sie werden durch einen Startschlüssel und einen Endschlüssel definiert.
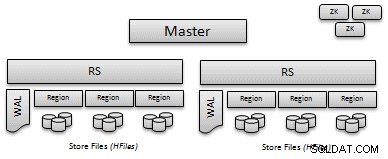
- WALs/MemStore Hinweis:Bevor Daten auf die Festplatte geschrieben werden, werden Puts in das Write Ahead Log (WAL) geschrieben und dann im Speicher gespeichert, bis der Speicherdruck ein Flush auf die Festplatte auslöst. Die WAL bietet eine einfache Möglichkeit, Puts wiederherzustellen, die bei einem Fehler nicht auf die Festplatte geschrieben wurden.
- HFiles :Irgendwann werden alle Daten auf die Festplatte gespült; Ein HFile ist das HBase-Format, das die gespeicherten Schlüssel/Werte enthält. HDateien sind unveränderlich, können aber beim Komprimieren oder Löschen von Regionen gelöscht werden.
(Hinweis:Um mehr über den HBase-Schreibpfad zu erfahren, werfen Sie einen Blick auf den Blogbeitrag zum HBase-Schreibpfad.)
Was ist ein Snapshot?
Ein Snapshot ist eine Reihe von Metadateninformationen, die es dem Administrator ermöglichen, zu einem früheren Zustand der Tabelle zurückzukehren, auf der er aufgenommen wurde. Ein Snapshot ist keine Kopie der Tabelle; Am einfachsten kann man es sich als eine Reihe von Operationen vorstellen, um Metadaten (Tabelleninformationen und Regionen) und die Daten (HFiles, Memstore, WALs) zu verfolgen. Während des Snapshot-Vorgangs sind keine Kopien der Daten beteiligt.
- Offline-Schnappschüsse :Der einfachste Fall für die Erstellung eines Snapshots ist, wenn eine Tabelle deaktiviert ist. Das Deaktivieren einer Tabelle bedeutet, dass alle Daten auf die Festplatte geleert werden und keine Schreib- oder Lesevorgänge akzeptiert werden. In diesem Fall besteht das Erstellen eines Schnappschusses lediglich darin, die Tabellenmetadaten und die HFiles auf der Festplatte durchzugehen und einen Verweis darauf zu behalten. Der Master führt diese Operation durch, und die erforderliche Zeit wird hauptsächlich durch die Zeit bestimmt, die der HDFS-Namenode benötigt, um die Liste der Dateien bereitzustellen.
- Online-Schnappschüsse :In den meisten Situationen sind Tabellen jedoch aktiviert und jeder Regionsserver verarbeitet Put- und Get-Anforderungen. In diesem Fall erhält der Master die Snapshot-Anforderung und bittet jeden Regionsserver, einen Snapshot der Regionen zu erstellen, für die er verantwortlich ist.
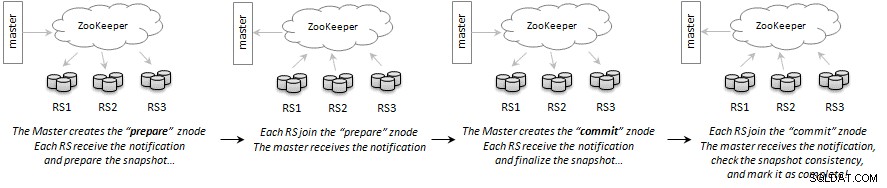
Die Kommunikation zwischen den Master- und Region-Servern erfolgt über Apache ZooKeeper unter Verwendung einer zweiphasigen Commit-ähnlichen Transaktion. Der Master erstellt einen Znode, der „den Snapshot vorbereiten“ bedeutet. Jeder Regionsserver verarbeitet die Anfrage und bereitet den Snapshot für die Regionen aus der Tabelle vor, für die er verantwortlich ist. Sobald sie fertig sind, fügen sie dem Z-Knoten für die Vorbereitungsanfrage einen Unterknoten mit der Bedeutung „Ich bin fertig“ hinzu.
Sobald alle Server der Region ihren Status zurückgemeldet haben, erstellt der Master einen weiteren Znode, der „Commit Snapshot“ bedeutet; Jeder Regionsserver stellt den Snapshot fertig und meldet den Status wie vor dem Beitritt zum Knoten. Sobald alle Regionsserver zurückgemeldet haben, schließt der Master den Snapshot ab und markiert den Vorgang als abgeschlossen. Falls ein Regionsserver einen Fehler meldet, erstellt der Master einen neuen Znode, der verwendet wird, um die Abbruchnachricht zu senden.
Da der Regionsserver kontinuierlich neue Anforderungen verarbeitet, können unterschiedliche Anwendungsfälle unterschiedliche Konsistenzmodelle erfordern. Beispielsweise könnte jemand an einem schlampigen Snapshot ohne die neuen Daten im MemStore interessiert sein, jemand anderes möchte vielleicht einen vollständig konsistenten Snapshot, der Schreibvorgänge für eine Weile sperren muss, und so weiter.
Aus diesem Grund ist das Verfahren zum Erstellen eines Snapshots auf dem Regionsserver austauschbar. Derzeit ist die einzige vorhandene Implementierung „Flush Snapshot“, die vor dem Erstellen eines Snapshots einen Flush durchführt und nur Zeilenkonsistenz garantiert. Andere Verfahren mit anderen Konsistenzrichtlinien können in Zukunft implementiert werden.
Im Online-Fall ist die zum Erstellen eines Snapshots erforderliche Zeit durch die Zeit begrenzt, die der langsamste Server der Region benötigt, um den Snapshot-Vorgang durchzuführen und den Erfolg an den Master zurückzumelden. Dieser Vorgang dauert normalerweise einige Sekunden.
Archivieren
Wie wir bereits gesehen haben, sind HFiles unveränderlich. Dadurch können wir vermeiden, dass die Daten während der Snapshot- oder Klonvorgänge kopiert werden, aber während der Komprimierung werden sie entfernt und durch eine komprimierte Version ersetzt. Wenn Sie in diesem Fall einen Snapshot oder eine geklonte Tabelle haben, die auf eine dieser Dateien verweist, werden sie nicht gelöscht, sondern an einen „Archiv“-Speicherort verschoben. Wenn Sie einen Snapshot löschen und niemand sonst auf die Dateien verweist, auf die der Snapshot verweist, werden diese Dateien gelöscht.
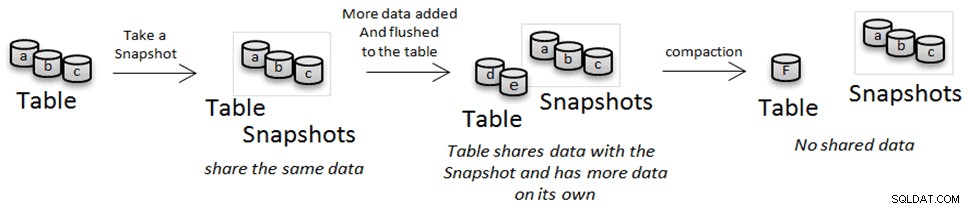
Klonen und Wiederherstellen von Tabellen
Snapshots können als Sicherungslösung angesehen werden, bei der sie zum Wiederherstellen/Wiederherstellen einer Tabelle nach einem Benutzer- oder Anwendungsfehler verwendet werden können, aber die Snapshot-Funktion kann viel mehr als ein einfaches Sichern und Wiederherstellen ermöglichen. Nachdem Sie eine Tabelle aus einem Snapshot geklont haben, können Sie einen MapReduce-Job oder eine einfache Anwendung schreiben, um die Unterschiede oder das, was Sie für wichtig halten, selektiv in der Produktion zusammenzuführen. Ein weiterer Anwendungsfall ist, dass Sie Schemaänderungen oder Aktualisierungen der Daten testen können, ohne stundenlang auf eine Tabellenkopie warten zu müssen und ohne am Ende viele Daten auf der Festplatte duplizieren zu müssen.
Klonen Sie eine Tabelle aus einem Snapshot
Wenn ein Administrator einen Klonvorgang durchführt, wird eine neue Tabelle mit dem im Snapshot vorhandenen Tabellenschema erstellt, das mit den Start-/Endschlüsseln in den Informationen zu den Snapshot-Regionen vorab aufgeteilt ist. Sobald die Tabellenmetadaten erstellt sind, wird der gleiche Trick wie beim Snapshot verwendet, anstatt die Daten hineinzukopieren. Da die HFiles unveränderlich sind, wird nur ein Verweis auf die Quelldatei erstellt; Dadurch kann der Vorgang Datenkopien vermeiden und der Klon bearbeitet werden, ohne dass dies Auswirkungen auf die Quelltabelle oder den Snapshot hat. Der Klonvorgang wird vom Master durchgeführt.
Eine Tabelle aus einem Snapshot wiederherstellen
Der Wiederherstellungsvorgang ähnelt dem Klonvorgang; Sie können sich das so vorstellen, als würden Sie die Tabelle löschen und aus dem Snapshot klonen. Die Wiederherstellungsoperation bringt die alten Daten zurück, die im Snapshot vorhanden sind, wobei alle Daten aus der Tabelle entfernt werden, die nicht auch im Snapshot enthalten sind, und auch das Schema der Tabelle wird auf das des Snapshots zurückgesetzt. Unter der Haube wird die Wiederherstellung implementiert, indem ein Unterschied zwischen dem Tabellenstatus und dem Snapshot gemacht wird, Dateien entfernt werden, die nicht im Snapshot vorhanden sind, und Verweise auf diejenigen im Snapshot hinzugefügt werden, die im aktuellen Status nicht vorhanden sind. Auch der Tabellendeskriptor wird modifiziert, um das „Schema“ der Tabelle zum Zeitpunkt des Schnappschusses widerzuspiegeln. Der Wiederherstellungsvorgang wird vom Master durchgeführt und die Tabelle muss deaktiviert werden.
Futures
Derzeit enthält die Snapshot-Implementierung alle grundlegenden erforderlichen Funktionen. Wie wir gesehen haben, können neue Snapshot-Konsistenzrichtlinien für die Online-Snapshots mehr Flexibilität, Konsistenz oder Leistungsverbesserungen bieten. Eine bessere Dateiverwaltung kann die Belastung des HDFS-Namensknotens verringern und die Speicherplatzverwaltung verbessern. Darüber hinaus stehen Metriken, Web-UI (Hue) und mehr auf der To-Do-Liste.
Schlussfolgerung
HBase-Snapshots fügen neue Funktionen hinzu, wie die „Prozedurkoordination“, die vom Online-Snapshot verwendet wird, oder Copy-on-Write-Snapshot, Wiederherstellung und Klone.
Snapshots bieten eine schnellere und bessere Alternative zu handgemachten „Backup“- und „Klon“-Lösungen auf Basis von distcp oder CopyTable. Alle Snapshot-Vorgänge (Snapshot, Wiederherstellung, Klonen) beinhalten keine Datenkopien, was zu schnelleren Snapshots der Tabelle und Einsparungen an Speicherplatz führt.
Weitere Informationen zum Aktivieren und Verwenden von Snapshots finden Sie im Dokument zur Betriebsverwaltung von HBase.
Matteo Bertozzi ist Software Engineer im Platform-Team und HBase-Committer.



