
Was ist Couchbase
Couchbase Server ist eine verteilte Open-Source-JSON-Dokumentendatenbank. Es stellt einen Schlüssel-Wert-Speicher mit horizontaler Skalierung und verwaltetem Cache für Datenoperationen unter einer Millisekunde, speziell entwickelte Indexer für effiziente Abfragen und eine leistungsstarke Abfrage-Engine zur Ausführung von SQL-ähnlichen Abfragen bereit. Für mobile und Internet-of-Things-Umgebungen läuft Couchbase auch nativ auf dem Gerät und verwaltet die Synchronisation mit dem Server.
Warum Couchbase?
Couchbase Server ist eine verteilte Open-Source-JSON-Dokumentendatenbank. Es stellt einen Schlüssel-Wert-Speicher mit horizontaler Skalierung und verwaltetem Cache für Datenoperationen unter einer Millisekunde, speziell entwickelte Indexer für effiziente Abfragen und eine leistungsstarke Abfrage-Engine zur Ausführung von SQL-ähnlichen Abfragen bereit. Für mobile und Internet-of-Things-Umgebungen läuft Couchbase auch nativ auf dem Gerät und verwaltet die Synchronisation mit dem Server.
Couchbase Server ist darauf spezialisiert, Datenmanagement mit geringer Latenz für umfangreiche interaktive Web-, Mobil- und IoT-Anwendungen bereitzustellen. Zu den allgemeinen Anforderungen, die Couchbase Server erfüllen sollte, gehören:
- Einheitliche Programmierschnittstelle
- Abfrage
- Suchen
- Mobil und IoT
- Analytics
- Core-Datenbank-Engine
- Scale-out-Architektur
- Memory-First-Architektur
- Big Data- und SQL-Integrationen
- Umfassende Sicherheit
- Container- und Cloud-Bereitstellungen
- Hohe Verfügbarkeit
Viele Datenbanken sind in der Lage, eine oder mehrere dieser Anforderungen zu erfüllen, erfordern jedoch Kompromisse, wenn sie in der Produktion mit unternehmenskritischen Anwendungen im Internetmaßstab laufen. Beispielsweise könnte eine Lösung Datenmodellflexibilität bieten, aber möglicherweise nicht in der Lage sein, Knoten hinzuzufügen oder zu entfernen, ohne die Betriebszeit oder Leistung zu beeinträchtigen. Eine andere Lösung könnte eine gute Skalierbarkeit beim Schreiben aufweisen, ohne das Datenmodell spontan indizieren oder ändern zu können. Couchbase Server wurde entwickelt, um eine produktive Entwickler- und Administrationserfahrung zu bieten und gleichzeitig eine skalierbare Leistung zu bieten, ob in der Cloud, in einem Container, vor Ort oder auf einem Edge-Gerät.
Nosql-Leistungsbenchmark
Neuer Benchmark zum Vergleich von MongoDB, DataStax und Couchbase Server demonstriert Couchbase als die skalierbarste NoSQL-Datenbank mit der besten Leistung.
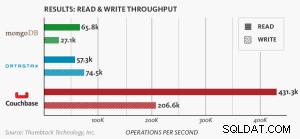
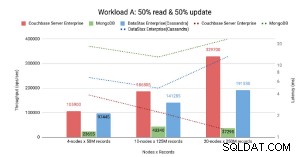
Knotenbasierter Benchmark .
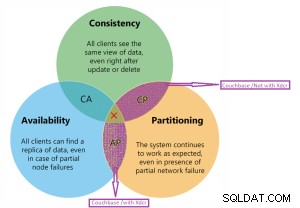
Gemäß CAP-Theorem Couchbase .
Cap-Theorem

Couchbase befindet sich auf dem CP- und AP-Diagramm.
Couchbase CP- und AP-Diagrammdetail.
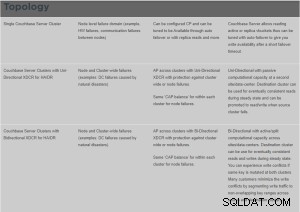
Was ist XDCR?
Cross Data Center Replication (XDCR) repliziert Daten zwischen Clustern:Dies bietet Schutz vor Rechenzentrumsausfällen und bietet außerdem einen leistungsstarken Datenzugriff für global verteilte, unternehmenskritische Anwendungen.
XDCR repliziert Daten aus einem bestimmten Bucket im Quellcluster in einen bestimmten Bucket im Zielcluster. Daten aus dem Quell-Bucket werden mithilfe eines XDCR-Agenten, der auf dem Quell-Cluster ausgeführt wird, unter Verwendung des Datenbankänderungsprotokolls in den Ziel-Bucket übertragen. Jeder Bucket (Couchbase oder Ephemeral) auf jedem Cluster kann als Quelle oder Ziel für eine oder mehrere XDCR-Definitionen angegeben werden.
Eine vollständige Beschreibung der Architektur von XDCR finden Sie unter Rechenzentrumsübergreifende Replikation (XDCR). Vielleicht möchten Sie sich mit den dort bereitgestellten Informationen vertraut machen, bevor Sie die in diesem Abschnitt beschriebenen Routinen durchführen.
Xdcr-Grundstruktur;
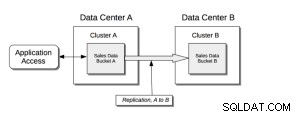
Voraussetzungen;
- Bestätigen Sie, dass Ihr Cluster die richtige Größe hat und neue XDCR-Streams verarbeiten kann. Beispielsweise benötigt XDCR 1-2 zusätzliche CPU-Kerne pro Stream und in einigen Fällen werden auch mehr RAM und Netzwerkressourcen benötigt. Wenn ein Cluster nicht die richtige Größe für die vorhandene Arbeitslast und die neuen XDCR-Streams hat, kann XDCR um Serverressourcen konkurrieren und sich negativ auf die Gesamtleistung auswirken.
- Couchbase Server verwendet den TCP/IP-Port 8091, um Informationen zur Clusterkonfiguration auszutauschen. Wenn Sie über eine dedizierte Verbindung oder das Internet mit einem Zielcluster kommunizieren, sollten Sie sicherstellen, dass alle Knoten im Ziel- und Quellcluster über die Ports 8091 und 8092 kommunizieren können.
Ports aufgelistet nach Kommunikationspfad
| XDCR (Cluster-zu-Cluster) |
|
Couchbase speichert Daten sowohl auf der Festplatte als auch im RAM. Das Standardverhalten besteht darin, das Dokument zu einem beliebigen Zeitpunkt (normalerweise schnell) nach dem Speichern im RAM auf die Festplatte zu schreiben. Dadurch bleibt ein kurzes Fenster, in dem ein Knotenausfall zu Datenverlust führen kann.
In jedem Fall wird das Dokument nach dem Schreiben in den RAM schließlich auf die Festplatte geschrieben. Couchbase führt eine Festplatten-Schreibwarteschlange, die Sie auf der Seite mit den Metrikberichten in der Verwaltungskonsole überprüfen können. Jetzt synchronisiert CB Schreibvorgänge über den Cluster, und ich glaube, dass ein Schreibvorgang über einen Cluster synchronisiert wird, bevor Couchbase bestätigt, dass der Schreibvorgang stattgefunden hat (z. B. bevor die Schreibmethode an den Aufrufer zurückkehrt).
Wenn Sie mehr Dokumente als verfügbaren Arbeitsspeicher haben, werden nur die Dokumente, auf die am häufigsten zugegriffen wird, zum schnellen Abrufen im Arbeitsspeicher gespeichert, während alle anderen auf die Festplatte „ausgelagert“ werden.
Hinweis;
Als die Bucket-Größe in der Quelle von 200 GB auf 10 GB reduziert wurde, wurde die Replikation schneller genug. Mit anderen Worten, wenn die Bucket-Größe hoch ist und sich alle Daten im RAM befinden, habe ich gesehen, dass die Replikation eine Lücke von 10 Sekunden hatte.
Quelle und Ziel müssen dieselbe Linux-Einstellung und dieselben Ressourcen haben. Dies ist nur ein Ratschlag.
Prod-Bucket-Resident muss %100 sein. Weil die Replikationsgeschwindigkeit wichtig ist.
Bucket replication best settings ; XDCR Source Nozzles per Node: 2 --> 8 XDCR Target Nozzles per Node: 2 --> 24 (Nozzles=Channel=parallel , as cpu core) XDCR Checkpoint Interval (sn): 1800 --> 60 Control frequency is low, but not as much as waiting in the queue. The higher this value, the longer it takes for XDCR queues to grow. XDCR Batch Count: 500 --> 2000 It is beneficial to increase by 2.3 times. It also sends so many data groups at the same time. XDCR Batch Size (kB): 2048 --> 8192 It is beneficial to increase by 2.3 times. At the same time, it sends such a large amount of data. XDCR Failure Retry Interval: 10 --> 10 It is used for retry attempts in network errors. XDCR Optimistic Replication Threshold: 256 --> 1024 --> 256 --> 128 Increasing or decreasing this value appropriately can speed up replication, collect data above 1 mb and send it in bulk. But collection can be a waste of time and waiting in the queue. This is the compressed document size in bytes. 0 - 2097152 Bytes (20MB). Default is 256 Bytes. XDCR retrieves metadata for documents larger than this size at once before copying the uncompressed document to a destination set. This option improves XDCR latency. XDCR Statistics Collection Interval (ms): 1000 --> 1000 XDCR Logging Level: info --> info
Hinweis;
Ich empfehle, dass Quelle und Ziel dieselbe Einstellung haben und dieselben Ressourcen haben.
Dies sind Bucket-Einstellung , Cluster-Einstellung , CPU , Arbeitsspeicher , Festplattenqualität usw.
Xdcr-Replikation ist nur Datenreplikation. Vor der Replikation müssen Sie Bucket-Metadaten erstellen.
Wenn Sie möchten, erstellen Sie Benutzer, Index, Ansicht, Ereignis usw.
Als zusätzliche Informationen;
Sie können eine xdcr-Replikation in der Community-Version durchführen.
Sie können die xdcr-Replikation in der Enterprise-Version durchführen. Dies erfordert eine zusätzliche Lizenz. Wenn Sie Standby nicht als Prod verwenden, ist es keine hohe Gebühr.
Die anderen Konnektoren von Couchbase für XDCR; Elasticsearch, Hadoop, Kafka, Spark, Talend, SQL (ODBC / JDBC)
Die Couchbase-Verwaltung kann über WEB UI, REST API und CLI erfolgen. Insbesondere die Web-Benutzeroberfläche ist sehr einfach und unkompliziert zu bedienen. Über die Benutzeroberfläche können Sie viele operative Transaktionen und Abfragen durchführen.
Replication Summary; Stby=Xdcr=Target=Remote same term. A different name xdcr cluster is established with the same features. The buckets with the same name with the same features are created in the xdcr cluster. In Prod, add remote server and xdcr information are entered in the xdcr tab. Prod in xdcr tab with add remote cluster; Cluster Name= Xdcr couchbase name IP/Hostname= Xdcr ip / hostname Username=Xdcr Admin username Password=Xdcr Admin user password Prod in xdcr tab with add bucket replication; Replicate From Bucket = Bucket name in the prod Remote Cluster = Added Xdcr name Remote Bucket = Bucket name added in Xdcr
Speichereinstellungen für Xdcr-Clustereinstellungen werden entsprechend dem Serverspeicherwert angegeben.
Sollte freie Größe für Serverspeicher haben.
Xdcr benötigt zusätzlichen Speicher im Produktionscluster.
Mehrere Couchbase-Bucket-Replikation ist möglich.
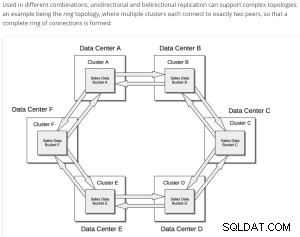
Beispiel einer einfachen XDCR-Replikation;
Xdcr-Tab auf Couchbase-Homepage ausgewählt.

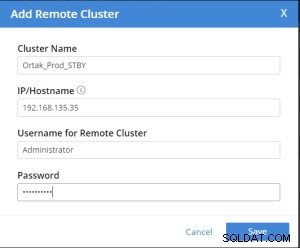
Remote-Cluster-Registerkarte hinzufügen ist auf der ausgewählten xdcr-Registerkarte ausgewählt.

Der Vorgang zum Hinzufügen eines Remote-Clusters erfolgt nach .
Replikationsregisterkarte hinzufügen ist auf der ausgewählten xdcr-Registerkarte ausgewählt.
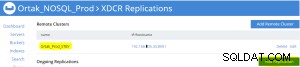
Der Vorgang zum Hinzufügen der Bucket-Replikation erfolgt nach .
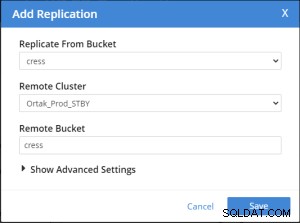
Beste Parameter für xdcr-Leistung . Aber es kann für Ihr System neu eingestellt werden.

Replikationsstatus auf der xdcr-Registerkarte der Quelle (prod)
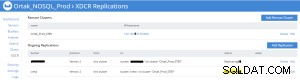
Bucket-Replikationsstatistik
Replikationsleistung auf Ziel;

Replikationsleistung an der Quelle;

Referenzen;
1-) https://resources.couchbase.com/nosql_comparison_web/altoros-nosql-performance-benchmark
2-) https://docs.couchbase.com/
3-) https://www.businesswire.com/news/home/20140625005778/en/Couchbase-Blows-Past-Competition-in-NoSQL-Performance-Benchmark
4-) https://www.quora.com/What-is-the-relation-between-SQL-NoSQL-the-CAP-theorem-and-ACID
Fatih Gençali – Couchbase-Zertifizierungen





