Nun, die Analyse der Ausbreitung des SARS-CoV-2-Coronavirus war nicht mein Traumanwendungsfall . Aber aufgrund der Reaktionen auf den Artikel Tracking Coronavirus COVID-19 Near Real Time with SAP HANA XSA von Ferry Djaja habe ich mich entschieden, meine beiden Groszy ebenfalls hinzuzufügen.
[Aktualisiert am 30.03.20 mit den geänderten Links zu den Quelldaten; und die neue Kartenausgabe basierend auf der neuen Datengranularität. Danke Douglas Maltby für deinen Kommentar!]
In seinem Blogbeitrag verwendete Ferry JavaScript in SAP HANA XSA, um die Daten aus CSV-Dateien abzurufen, die täglich von der Johns Hopkins University aktualisiert werden.
Ich möchte Ihnen zeigen, wie Sie mit nur wenigen Codezeilen diese Dateien in SAP HANA ziehen und laden können dank SAP HANA Python Client API for Machine Learning (hana_ml Paket).
Einige Leute waren mit der Visualisierung auf der Karte am Ende verwirrt – bitte beachten Sie, dass sich dieser Artikel auf technische Anwendungsfälle konzentriert, die verschiedene Komponenten verbinden, und nicht auf eine tiefgreifende Analyse von Coronavirus-Daten.
Python-Umgebung abrufen, z. Jupyter
Ich werde dafür Jupyter im Docker-Container verwenden. Bitte schauen Sie sich meinen vorherigen Beitrag Container verstehen (Teil 05):Gemeinsame Dateien zwischen Host und Containern an, wenn Sie nicht wissen, wie man ihn startet. Außerdem können Sie die gleichen Schritte unten in jeder anderen Python-Umgebung ausführen.
Ich habe also meinen Container myjupyter01 Betrieb. Ich bin wie im vorherigen Blog beschrieben mit der Jupyter-Benutzeroberfläche verbunden.
Installieren Sie hana_ml
Das Jupyter-Image, das ich aus der Docker-Hub-Registrierung verwendet habe, war jupyter/minimal-notebook . Es enthält bereits einige beliebte Datenverarbeitungspakete, wie pandas .
Aber zusätzlich muss ich hana_ml installieren , das – in seiner aktuellen Version 1.0.8 – im PyPI-Repository verfügbar ist:https://pypi.org/project/hana-ml/.
Der Befehl zum Ausführen der Installation lautet python -m pip install hana_ml , aber da ich es vom Jupyter-Notebook mit Python3-Kernel ausführe, muss ich es mit ! ausführen am Anfang:
!python -m pip install hana_ml
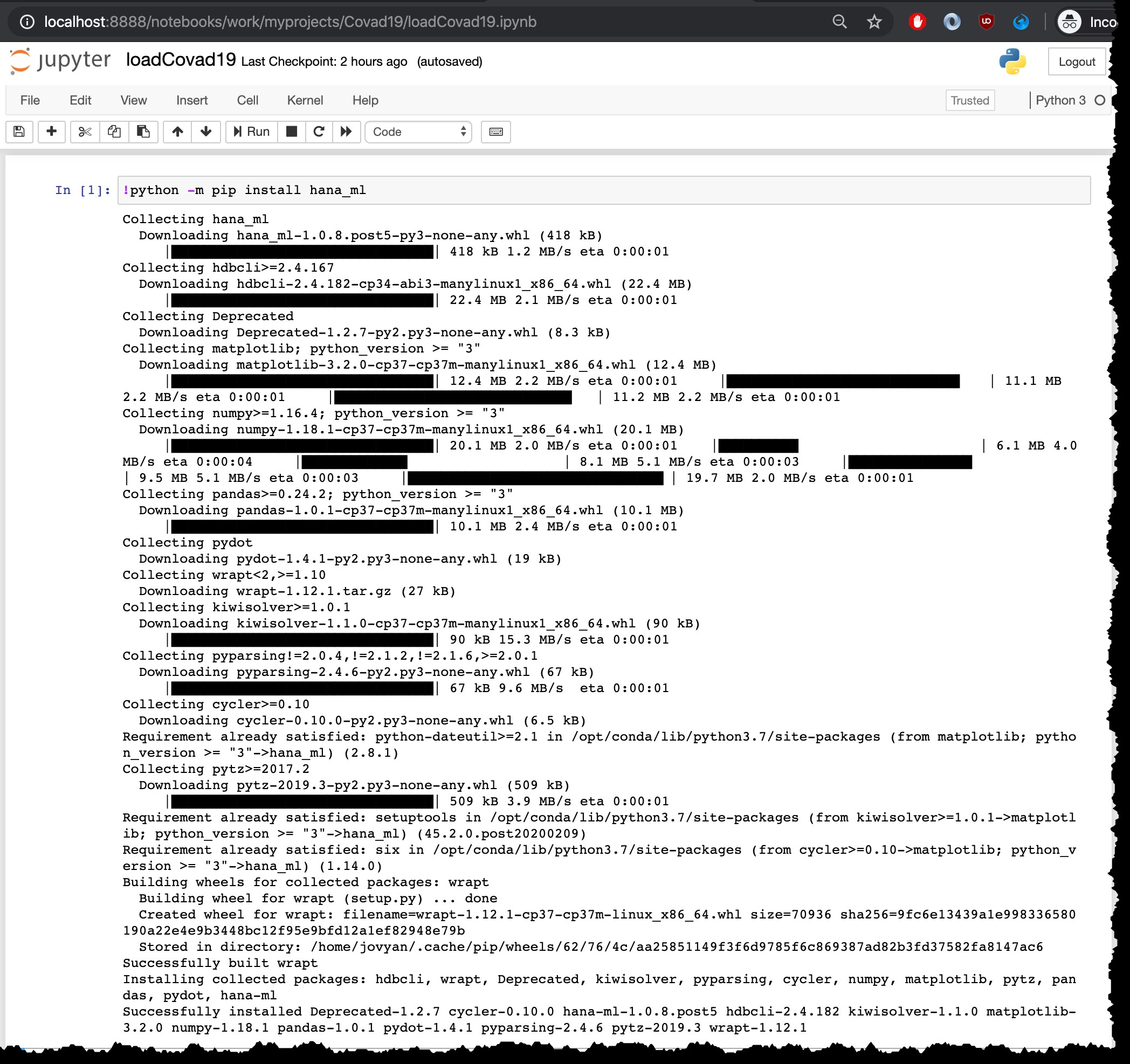
Natürlich muss dieser Installationsschritt nur einmal durchgeführt werden. Keine Notwendigkeit, es im selben Container erneut auszuführen, z. beim Nachladen der neusten Dateien.
Verwenden Sie pandas um Dateien mit Daten zu importieren
Importieren wir dieselben drei Dateien (confirmed , deaths , recovered ) von https://github.com/CSSEGISandData/COVID-19/tree/master/csse_covid_19_data/csse_covid_19_time_series wie Ferry in seinem Beispiel verwendet.
import hana_ml, pandas
# Links updated on 2020-03-22
df_confd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_global.csv')
df_death = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_deaths_global.csv')
df_recvd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_recovered_global.csv')
#Links from before March 22nd
#df_confd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Confirmed.csv')
#df_death = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Deaths.csv')
#df_recvd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Recovered.csv')
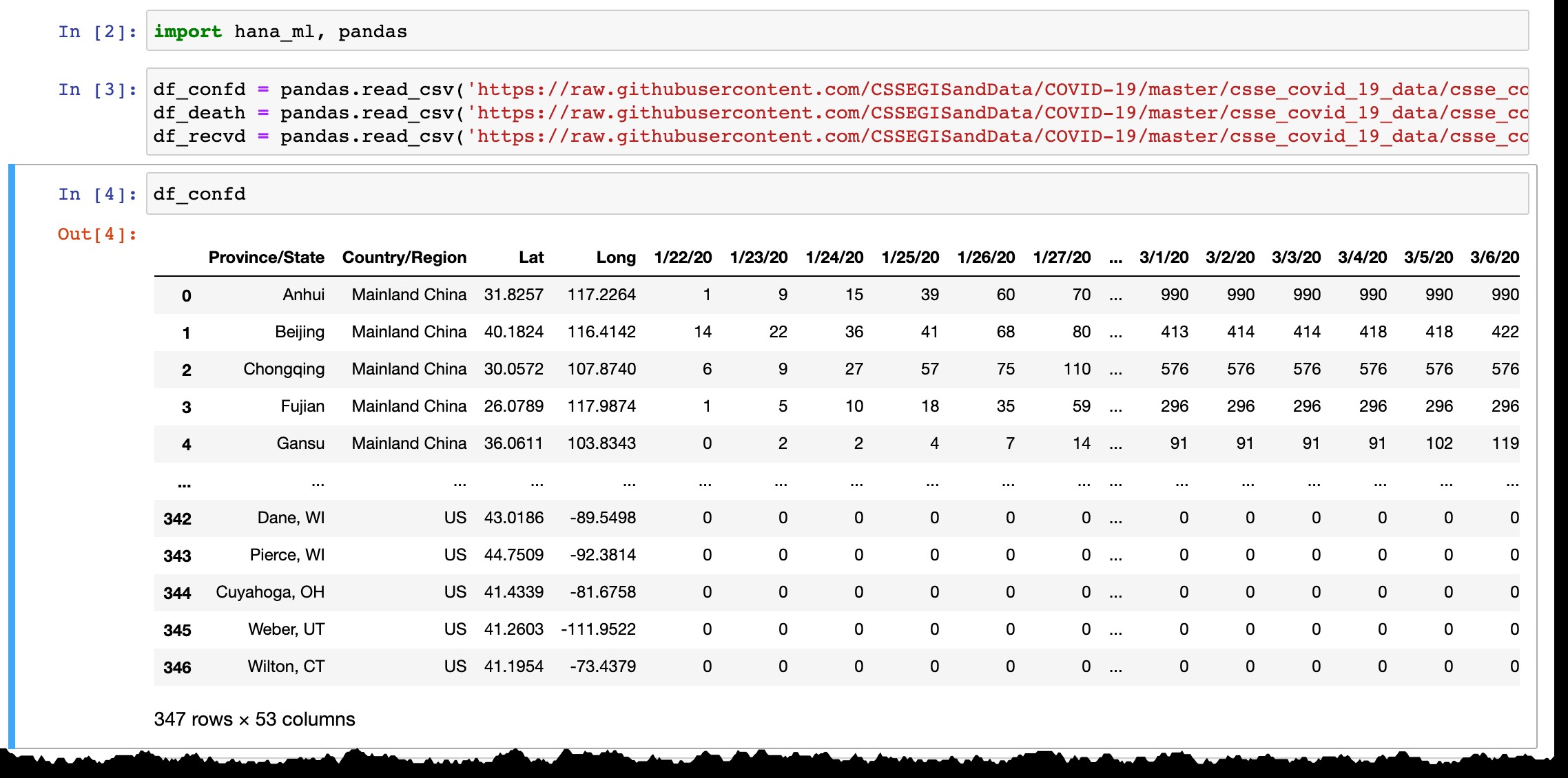
Wie Sie in der Vorschau des Pandas-Datenrahmens sehen können, listet er nur Länder oder Provinzen mit bestätigten Fällen auf, und jeden Tag wird die neue Spalte mit den neuesten Daten vom Vortag hinzugefügt. Zeilen werden hinzugefügt, wenn der/die erste(n) Fall(e) in der neuen Region bestätigt wird.
Verwenden Sie pandas um den Datenrahmen neu zu formatieren
Bevor wir die Daten in SAP HANA beibehalten, gehen wir wie folgt vor:
- Entfernen Sie alle Datumsspalten außer der letzten,
- Benennen Sie die letzte Spalte aus dem tatsächlichen Datum um (z. B. den heutigen
3/10/20aufConfirmed).
df_confd_latest=df_confd.drop(df_confd.columns[4:len(df_confd.columns)-1], axis='columns')
df_confd_latest.columns = [*df_confd_latest.columns[:-1],'Confirmed']
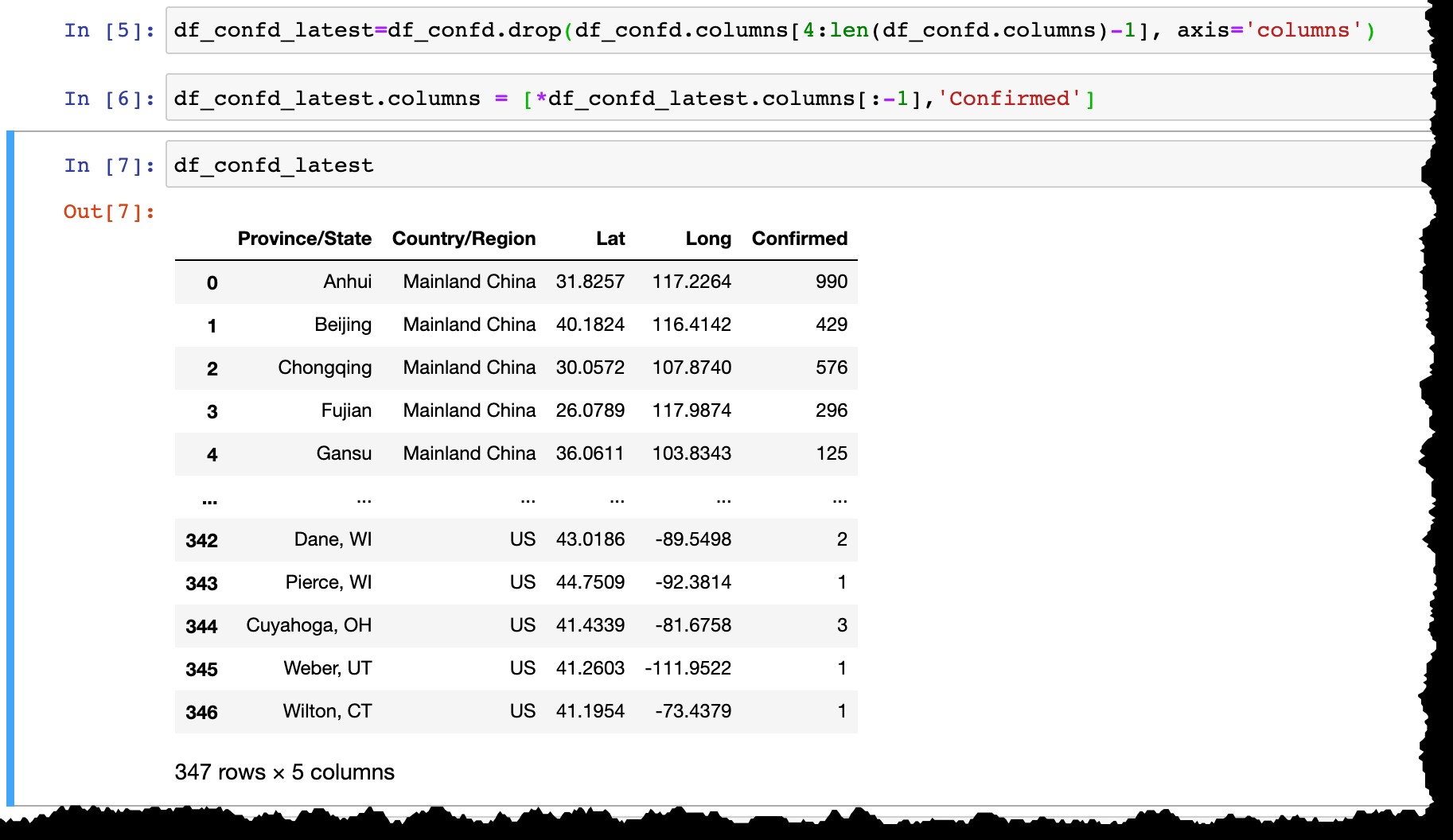
Verwenden Sie hana_ml um Daten in der SAP-HANA-Tabelle zu speichern
Lassen Sie mich nun mit dem Benutzer hanaml eine Verbindung zu meiner Instanz von SAP HANA Express herstellen das gibt es dort schon…
cc=hana_ml.dataframe.ConnectionContext('12.34.567.890', 39015, 'hanaml', 'MyPasswordReusedEverywhere')
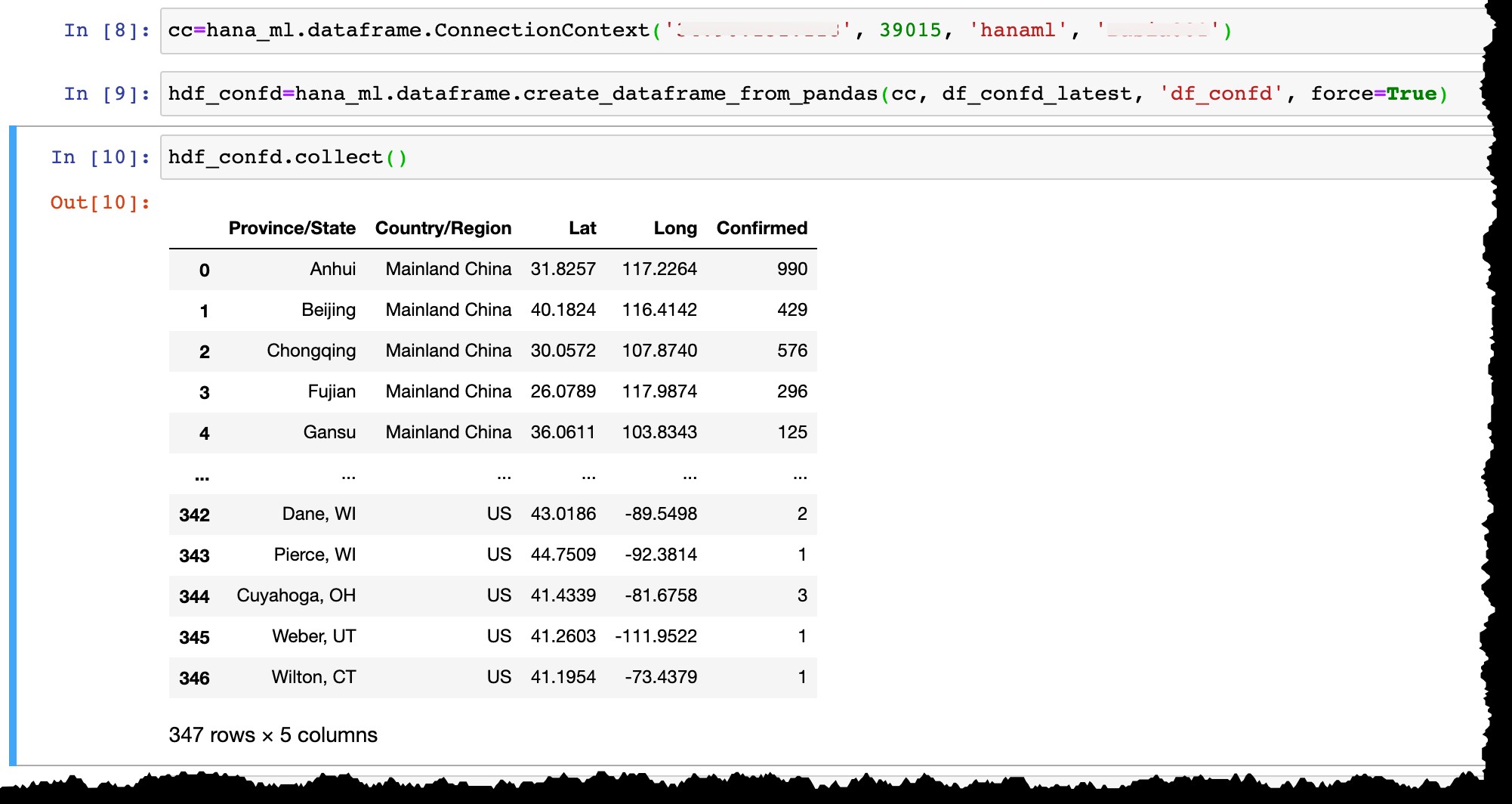
…und konvertieren Sie den Pandas-Datenrahmen df_confd_latest in einen HANA-Datenrahmen hdf_confd .
hdf_confd=hana_ml.dataframe.create_dataframe_from_pandas(cc, df_confd_latest, 'df_confd', force=True)
Sobald der HANA-Datenrahmen erstellt ist:
- Eine physische Spaltentabelle wird in HANA erstellt und Daten aus Pandas Datenrahmen werden dort eingefügt,
- HANA-Datenrahmen
hdf_confdin Python speichert keine Daten auf Ihrem Laptop, sondern zeigt nur auf eine TabelleHANAML.df_confdim SAP-HANA-Serverspeicher, und alle Python-Operationen auf dem HANA-Datenrahmen werden physisch in der HANA-Datenbank ausgeführt, ohne dass Daten zwischen dem Server und einem Client verschoben werden, - Um das Ergebnis von Operationen anzuzeigen, müssen wir
collect()anwenden Methode, um den HANA-Datenrahmen in Pandas zu konvertieren (und als Ergebnis Daten vom HANA-Datenbankserver auf den lokalen Client zu bringen).
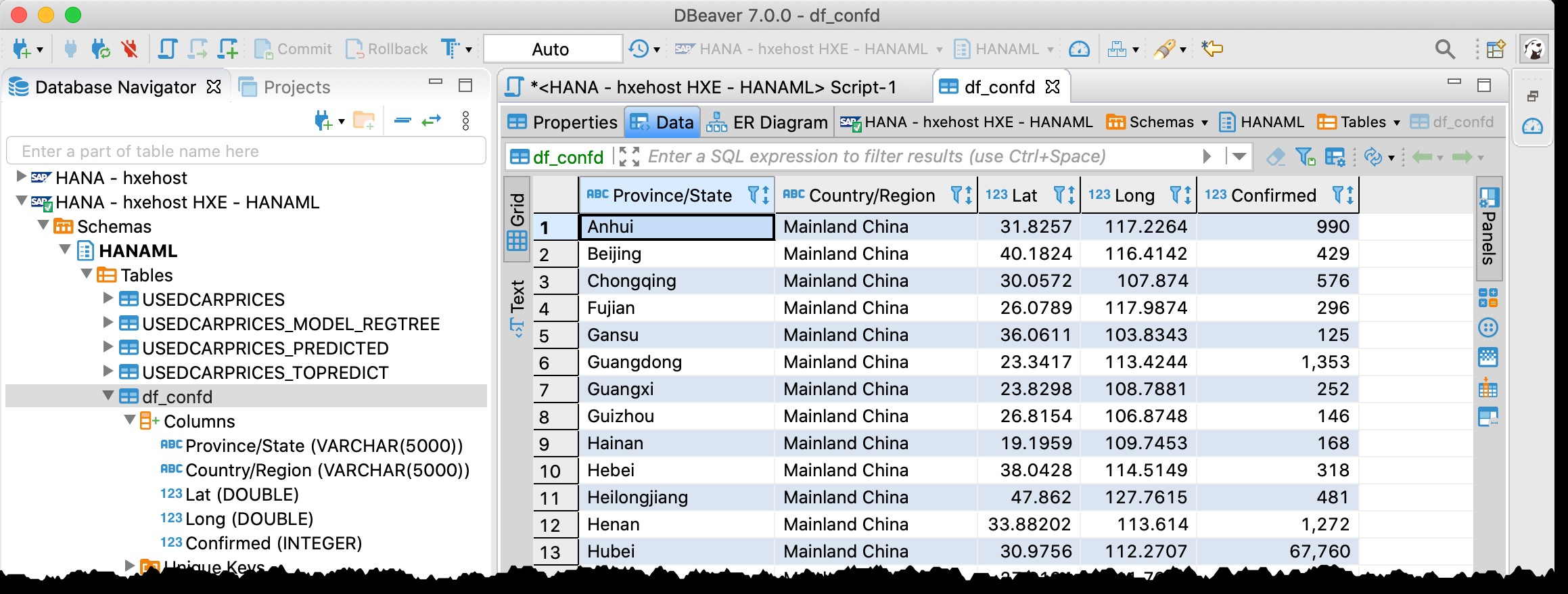
Verwenden Sie DBeaver, um Daten in SAP HANA zu überprüfen…
Sie erinnern sich vielleicht, dass ich bereits DBeaver – das kostenlose Datenbanktool zur Unterstützung von SAP HANA – in meinem vorherigen Beitrag „GeoArt mit SAP HANA und DBeaver“ verwendet habe.
Ich benutze es jetzt wieder und finde tatsächlich die Tabelle df_confd im Schema HANAML mit allen Daten aus dem Pandas-Quelldatenrahmen.
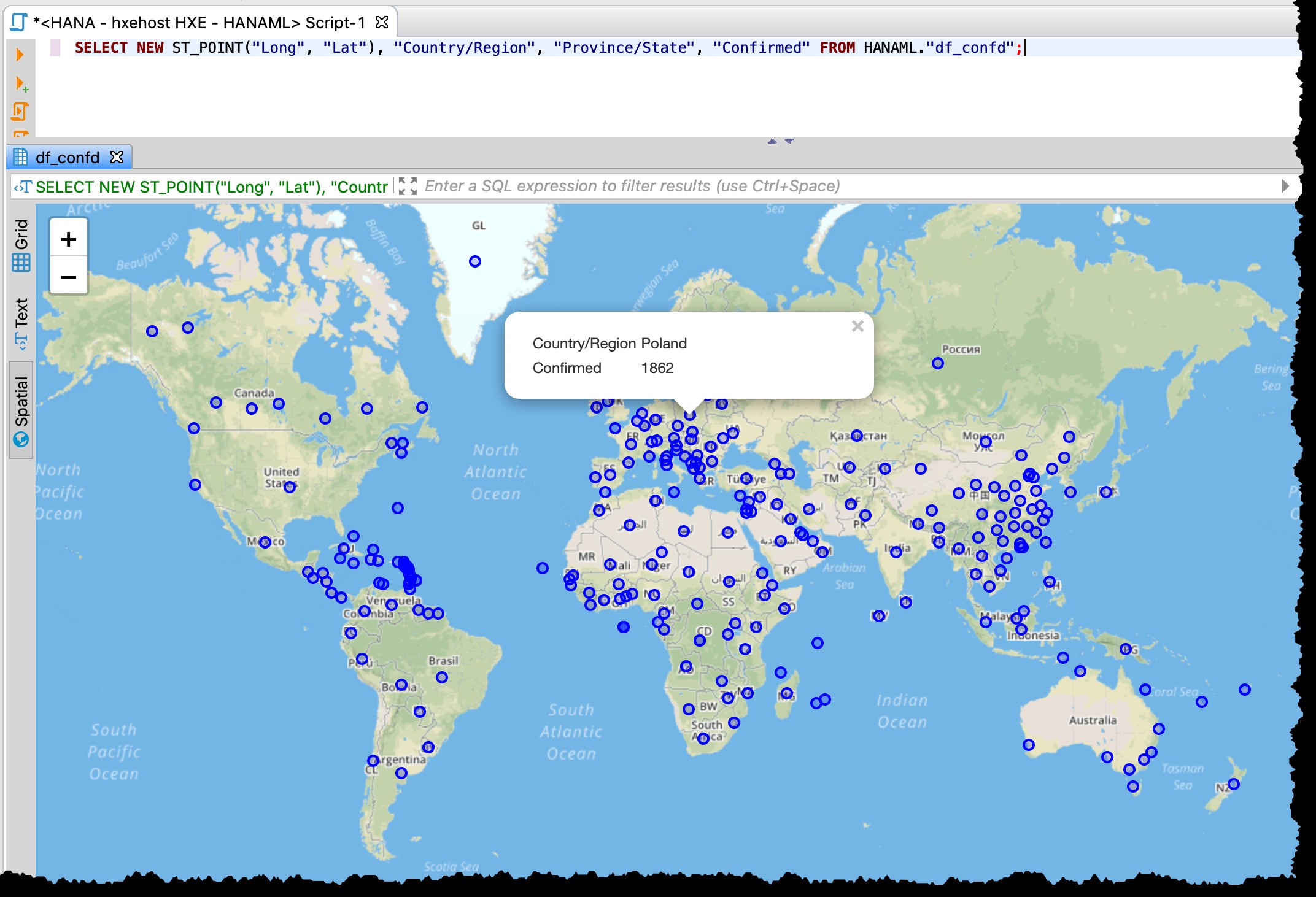
…und machen Sie eine räumliche Vorschau
Da die Tabelle Breiten- und Längengradspalten enthält, kann ich betroffene Länder/Staaten direkt aus DBeaver mit dem folgenden SQL mithilfe der räumlichen Datenvorschau visualisieren.
SELECT NEW ST_POINT("Long", "Lat"), "Country/Region", "Province/State", "Confirmed" FROM HANAML."df_confd";
Ich musste die Kartenprojektion auf EPSG:4326 ändern um diese Punkte auf der Karte zu bekommen. Und DBeaver zeigt mir den Rest der Aufzeichnungsdaten, wenn ich auf einen beliebigen Punkt klicke.
[unten ist der alte Screenshot vom 11.03.2020, der auch die unterschiedliche Granularität von z.B. Damals verwendete US-Daten]
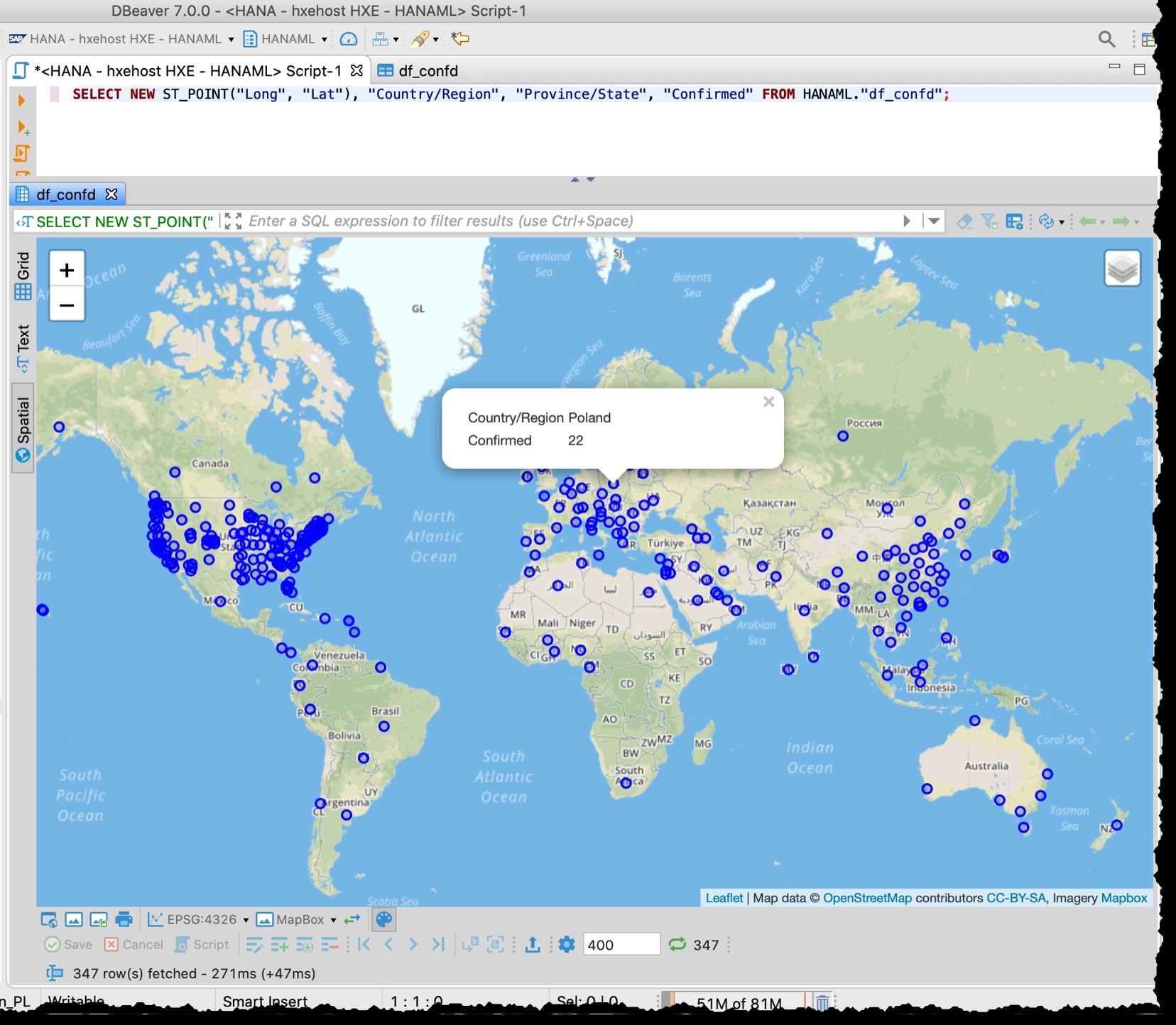
Die räumliche Vorschau von DBeaver ist kein vollwertiges Tool zur visuellen Erkundung von Geodaten. Dennoch reicht es aus, betroffene Länder/Regionen zu sehen (abhängig von der Granularität in den Quelldateien).
Falls Sie daran interessiert sind, mehr über hana_ml zu erfahren …
… dann würde ich auf jeden Fall empfehlen, das Hands-On Tutorial:Machine Learning push-down to SAP HANA with Python von Andreas Forster zu lesen.
HANA ML ist Teil des neuen Themas „Advanced Analytics with SAP HANA“ für CodeJam-Events. Leider mussten wir aufgrund der Coronavirus-Situation die erste von Jakob Flaman in Bern diesen Monat absagen. Eine weitere wird von Ewelina Pękała am 27. Mai in Katowice organisiert:https://www.eventbrite.com/e/sap-codejam-katowice-registration-99016299417. Hoffentlich normalisiert sich die Situation bis dahin und wir müssen diese nicht ebenfalls absagen.