Zuvor haben wir einen Blog über das Erzielen von MySQL-Failover und -Failback auf der Google Cloud Platform (GCP) veröffentlicht, und in diesem Blog werden wir uns ansehen, wie der Rivale Amazon Relational Database Service (RDS) Failover handhabt. Wir werden uns auch ansehen, wie Sie ein Failback Ihres ehemaligen Master-Knotens durchführen können, um ihn wieder in seine ursprüngliche Reihenfolge als Master zu bringen.
Beim Vergleich der Tech-Giganten Public Clouds, die verwaltete relationale Datenbankdienste unterstützen, ist Amazon der einzige, der eine alternative Option (zusammen mit MySQL/MariaDB, PostgreSQL, Oracle und SQL Server) anbietet seine eigene Art der Datenbankverwaltung namens Amazon Aurora. Für diejenigen, die mit Aurora nicht vertraut sind:Es handelt sich um eine vollständig verwaltete relationale Datenbank-Engine, die mit MySQL und PostgreSQL kompatibel ist. Aurora ist Teil des verwalteten Datenbankdienstes Amazon RDS, einem Webdienst, der das Einrichten, Betreiben und Skalieren einer relationalen Datenbank in der Cloud vereinfacht.
Warum sollten Sie Failover oder Failback durchführen?
Der Entwurf eines großen Systems, das fehlertolerant, hochverfügbar und ohne Single-Point-Of-Failure (SPOF) ist, erfordert angemessene Tests, um festzustellen, wie es reagieren würde, wenn etwas schief geht.
Wenn Sie sich Sorgen darüber machen, wie Ihr System reagieren würde, wenn es auf FDIR (Fault Detection, Isolation, and Recovery) Ihres Systems reagiert, sollten Failover und Failback von großer Bedeutung sein.
Datenbank-Failover in Amazon RDS
Failover erfolgt automatisch (manuelles Failover wird Switchover genannt). Wie in einem früheren Blog besprochen, tritt ein Failover auf, sobald Ihr aktueller Datenbankmaster einen Netzwerkausfall oder eine abnormale Beendigung des Hostsystems erfährt. Failover schaltet es in einen stabilen Redundanzzustand oder auf einen Standby-Computerserver, ein System, eine Hardwarekomponente oder ein Netzwerk.
In Amazon RDS müssen Sie dies nicht tun, noch müssen Sie es selbst überwachen, da RDS ein verwalteter Datenbankdienst ist (was bedeutet, dass Amazon die Arbeit für Sie erledigt). Dieser Dienst verwaltet Dinge wie Hardwareprobleme, Sicherung und Wiederherstellung, Software-Updates, Speicher-Upgrades und sogar Software-Patches. Darüber sprechen wir später in diesem Blog.
Datenbank-Failback in Amazon RDS
Im vorherigen Blog haben wir auch behandelt, warum Sie ein Failback durchführen müssen. In einer typischen replizierten Umgebung muss der Master leistungsfähig genug sein, um eine enorme Last zu tragen, insbesondere wenn die Workload-Anforderung hoch ist. Ihr Master-Setup erfordert angemessene Hardwarespezifikationen, um sicherzustellen, dass es Schreibvorgänge verarbeiten, Replikationsereignisse generieren, kritische Lesevorgänge usw. auf stabile Weise verarbeiten kann. Wenn während der Notfallwiederherstellung (oder zu Wartungszwecken) ein Failover erforderlich ist, ist es nicht ungewöhnlich, dass Sie beim Hochstufen eines neuen Masters möglicherweise minderwertige Hardware verwenden. Diese Situation mag vorübergehend in Ordnung sein, aber auf lange Sicht muss der designierte Master zurückgeholt werden, um die Replikation zu leiten, nachdem sie als fehlerfrei erachtet wird (oder die Wartung abgeschlossen ist).
Im Gegensatz zum Failover finden Failback-Operationen normalerweise in einer kontrollierten Umgebung statt, indem Switchover verwendet wird. Es wird selten im Panikmodus gemacht. Dieser Ansatz gibt Ihren Ingenieuren genügend Zeit, um die Übung sorgfältig zu planen und zu proben, um einen reibungslosen Übergang zu gewährleisten. Sein Hauptziel ist es, einfach den guten, alten Master auf den neuesten Stand zu bringen und das Replikations-Setup in seiner ursprünglichen Topologie wiederherzustellen. Da wir es mit Amazon RDS zu tun haben, brauchen Sie sich wirklich keine allzu großen Sorgen um diese Art von Problemen zu machen, da es sich um einen Managed Service handelt, bei dem die meisten Jobs von Amazon abgewickelt werden.
Wie handhabt Amazon RDS Datenbank-Failover?
Bei der Bereitstellung Ihrer Amazon RDS-Knoten können Sie Ihren Datenbank-Cluster mit einer Multi-Availability Zone (AZ) oder einer Single-Availability Zone einrichten. Lassen Sie uns jeden von ihnen überprüfen, wie Failover verarbeitet werden.
Was ist ein Multi-AZ-Setup?
Wenn eine Katastrophe oder ein Desaster eintritt, z. B. ungeplante Ausfälle oder Naturkatastrophen, bei denen Ihre Datenbankinstanzen betroffen sind, wechselt Amazon RDS automatisch zu einer Standby-Replik in einer anderen Availability Zone. Diese AZ befindet sich in der Regel in einem anderen Zweig des Rechenzentrums, oft weit entfernt von der aktuellen Verfügbarkeitszone, in der sich Instanzen befinden. Diese AZs sind hochverfügbare, hochmoderne Einrichtungen, die Ihre Datenbankinstanzen schützen. Die Failover-Zeiten hängen vom Abschluss des Setups ab, das häufig von der Größe und Aktivität der Datenbank sowie anderen Bedingungen abhängt, die zu dem Zeitpunkt vorlagen, als die primäre DB-Instance nicht mehr verfügbar war.
Failover-Zeiten betragen in der Regel 60–120 Sekunden. Sie können jedoch länger sein, da große Transaktionen oder ein langwieriger Wiederherstellungsprozess die Failover-Zeit verlängern können. Wenn das Failover abgeschlossen ist, kann es auch länger dauern, bis die RDS-Konsole (UI) die neue Availability Zone widerspiegelt.
Was ist ein Single-AZ-Setup?
Single-AZ-Setups sollten nur dann für Ihre Datenbankinstanzen verwendet werden, wenn Ihre RTO (Recovery Time Objective) und RPO (Recovery Point Objective) hoch genug sind, um dies zuzulassen. Der Einsatz eines Single-AZ birgt Risiken, wie z. B. große Ausfallzeiten, die den Geschäftsbetrieb stören könnten.
Häufige RDS-Fehlerszenarien
Die Ausfallzeit hängt von der Art des Fehlers ab. Sehen wir uns an, was diese sind und wie die Wiederherstellung der Instanz gehandhabt wird.
Fehler bei behebbarer Instanz
Ein Amazon RDS-Instance-Fehler tritt auf, wenn die zugrunde liegende EC2-Instance einen Fehler erleidet. Bei Auftreten löst AWS eine Ereignisbenachrichtigung aus und sendet Ihnen mithilfe von Amazon RDS-Ereignisbenachrichtigungen eine Warnung. Dieses System verwendet AWS Simple Notification Service (SNS) als Alarmprozessor.
RDS versucht automatisch, eine neue Instanz in derselben Availability Zone zu starten, fügt das EBS-Volume hinzu und versucht eine Wiederherstellung. In diesem Szenario liegt die RTO normalerweise unter 30 Minuten. RPO ist null, da das EBS-Volume wiederhergestellt werden konnte. Das EBS-Volume befindet sich in einer einzigen Availability Zone und diese Art der Wiederherstellung erfolgt in derselben Availability Zone wie die ursprüngliche Instanz.
Nicht behebbare Instanzfehler oder EBS-Volume-Fehler
Für eine fehlgeschlagene RDS-Instance-Wiederherstellung (oder wenn das zugrunde liegende EBS-Volume einen Datenverlust erleidet) ist eine Point-in-Time-Recovery (PITR) erforderlich. PITR wird nicht automatisch von Amazon gehandhabt, daher müssen Sie entweder ein Skript erstellen, um es zu automatisieren (mit AWS Lambda), oder es manuell durchführen.
Das RTO-Timing erfordert das Starten einer neuen Amazon RDS-Instance, die nach der Erstellung einen neuen DNS-Namen haben wird, und das Anwenden aller Änderungen seit der letzten Sicherung.
Das RPO beträgt normalerweise 5 Minuten, aber Sie können es finden, indem Sie RDS:describe-db-instances:LatestRestorableTime aufrufen. Die Zeit kann von 10 Minuten bis zu Stunden variieren, abhängig von der Anzahl der Protokolle, die angewendet werden müssen. Sie kann nur durch Testen ermittelt werden, da sie von der Größe der Datenbank, der Anzahl der seit der letzten Sicherung vorgenommenen Änderungen und der Auslastung der Datenbank abhängt. Da die Sicherungen und Transaktionsprotokolle in Amazon S3 gespeichert werden, kann diese Wiederherstellung in jeder unterstützten Availability Zone in der Region erfolgen.
Sobald die neue Instanz erstellt ist, müssen Sie den Endpunktnamen Ihres Clients aktualisieren. Sie haben auch die Möglichkeit, ihn in den Endpunktnamen der alten DB-Instance umzubenennen (dazu müssen Sie jedoch die alte ausgefallene Instance löschen), aber das macht es unmöglich, die Ursache des Problems zu ermitteln.
Unterbrechungen der Verfügbarkeitszone
Unterbrechungen in der Verfügbarkeitszone können vorübergehend sein und sind selten, wenn der AZ-Ausfall jedoch dauerhafter ist, wird die Instanz in einen ausgefallenen Zustand versetzt. Die Wiederherstellung würde wie zuvor beschrieben funktionieren und eine neue Instanz könnte in einer anderen AZ erstellt werden, indem eine Point-in-Time-Wiederherstellung verwendet wird. Dieser Schritt muss manuell oder per Skript ausgeführt werden. Die Strategie für diese Art von Wiederherstellungsszenario sollte Teil Ihrer größeren Notfallwiederherstellungspläne (DR) sein.
Wenn der Ausfall der Availability Zone vorübergehend ist, wird die Datenbank heruntergefahren, bleibt aber im verfügbaren Zustand. Sie sind für die Überwachung auf Anwendungsebene (entweder mit Tools von Amazon oder Drittanbietern) verantwortlich, um diese Art von Szenario zu erkennen. In diesem Fall können Sie warten, bis die Availability Zone wiederhergestellt ist, oder Sie können die Instanz mit einer Point-in-Time-Wiederherstellung in einer anderen Availability Zone wiederherstellen.
Die RTO wäre die Zeit, die benötigt wird, um eine neue RDS-Instanz zu starten und dann alle Änderungen seit der letzten Sicherung anzuwenden. Das RPO kann bis zum Ausfall der Availability Zone länger sein.
Testen von Failover und Failback auf Amazon RDS
Wir haben Amazon RDS Aurora mit db.r4.large mit einer Multi-AZ-Bereitstellung erstellt und eingerichtet (wodurch ein Aurora-Replikat/Reader in einem anderen AZ erstellt wird), auf das nur über EC2 zugegriffen werden kann. Sie müssen sicherstellen, dass Sie diese Option bei der Erstellung auswählen, wenn Sie beabsichtigen, Amazon RDS als Failover-Mechanismus zu verwenden.
Die Bereitstellung unserer RDS-Instanz dauerte zuvor etwa 11 Minuten die Instanzen wurden verfügbar und zugänglich. Unten ist ein Screenshot der Knoten, die nach der Erstellung in RDS verfügbar sind:
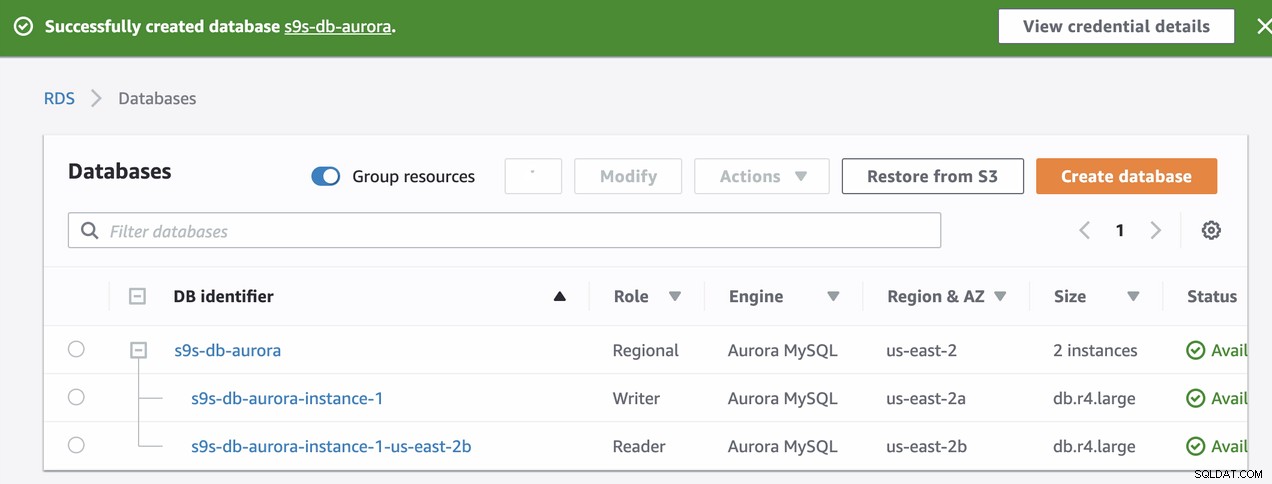
Diese beiden Knoten haben ihre eigenen festgelegten Endpunktnamen, die wir verwenden werden verwenden, um aus der Perspektive des Clients eine Verbindung herzustellen. Überprüfen Sie es zuerst und überprüfen Sie den zugrunde liegenden Hostnamen für jeden dieser Knoten. Um dies zu überprüfen, können Sie diesen Bash-Befehl unten ausführen und einfach die Hostnamen/Endpunktnamen entsprechend ersetzen:
example@sqldat.com:~# host=('s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com'); for h in "${host[@]}"; do mysql -h $h -e "select @@hostname; select @@global.innodb_read_only"; done;
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+Das Ergebnis verdeutlicht sich wie folgt,
s9s-db-aurora-instance-1 = s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com = ip-10-20-0-94 (read-write)
s9s-db-aurora-instance-1-us-east-2b = s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com = ip-10-20-1-139 (read-only)Amazon RDS-Failover simulieren
Simulieren wir nun einen Absturz, um ein Failover für die Amazon RDS Aurora Writer-Instanz zu simulieren, die s9s-db-aurora-instance-1 mit dem Endpunkt s9s-db-aurora.cluster-cmu8qdlvkepg.us ist -east-2.rds.amazonaws.com.
Stellen Sie dazu eine Verbindung zu Ihrer Writer-Instanz her, indem Sie die mysql-Client-Eingabeaufforderung verwenden, und geben Sie dann die folgende Syntax ein:
ALTER SYSTEM SIMULATE percentage_of_failure PERCENT DISK FAILURE [ IN DISK index | NODE index ]
FOR INTERVAL quantity [ YEAR | QUARTER | MONTH | WEEK| DAY | HOUR | MINUTE | SECOND ];Das Ausgeben dieses Befehls hat seine Amazon RDS-Wiederherstellungserkennung und wirkt ziemlich schnell. Obwohl die Abfrage zu Testzwecken dient, kann sie abweichen, wenn dieses Vorkommnis in einem tatsächlichen Ereignis auftritt. Möglicherweise möchten Sie mehr über das Testen eines Instanzabsturzes in der Dokumentation erfahren. Sehen Sie unten, wie wir am Ende landen:
mysql> ALTER SYSTEM SIMULATE 100 PERCENT DISK FAILURE FOR INTERVAL 3 MINUTE;
Query OK, 0 rows affected (0.01 sec)Das Ausführen des obigen SQL-Befehls bedeutet, dass er einen Festplattenausfall für mindestens 3 Minuten simulieren muss. Ich habe den Zeitpunkt zum Beginn der Simulation überwacht und es dauerte ungefähr 18 Sekunden, bis das Failover begann.
Sehen Sie unten, wie RDS den Simulationsfehler und das Failover handhabt,
Tue Sep 24 10:06:29 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
….
…..
………..
Tue Sep 24 10:06:44 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
….
……..
………..
Tue Sep 24 10:06:51 UTC 2019
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
….
………..
…………………
Tue Sep 24 10:07:13 UTC 2019
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+Die Ergebnisse dieser Simulation sind ziemlich interessant. Gehen wir das nach dem anderen durch.
- Um etwa 10:06:29 begann ich, die Simulationsabfrage wie oben beschrieben auszuführen.
- Gegen 10:06:44 zeigt es den Endpunkt s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com mit dem zugewiesenen Hostnamen ip-10-20-1- 139, wo es sich tatsächlich um die Nur-Lese-Instanz handelt, wurde dennoch unzugänglich, weil der Simulationsbefehl unter der Lese-Schreib-Instanz ausgeführt wurde.
- Um etwa 10:06:51 Uhr zeigt es diesen Endpunkt s9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com mit dem zugewiesenen Hostnamen ip-10-20-1- 139 ist aktiv, aber als Lese-Schreib-Zustand gekennzeichnet. Beachten Sie, dass die Variable innodb_read_only für von Aurora MySQL verwaltete Instanzen ihre Kennung ist, um festzustellen, ob der Host ein Lese-/Schreib- oder schreibgeschützter Knoten ist, und Aurora auch nur auf der InnoDB-Speicher-Engine für MySQL-kompatible Instanzen ausgeführt wird.
- Um etwa 10:07:13 hat sich die Reihenfolge geändert. Das bedeutet, dass das Failover durchgeführt wurde und die Instanzen den festgelegten Endpunkten zugewiesen wurden.
Überprüfen Sie das Ergebnis unten, das in der RDS-Konsole angezeigt wird:
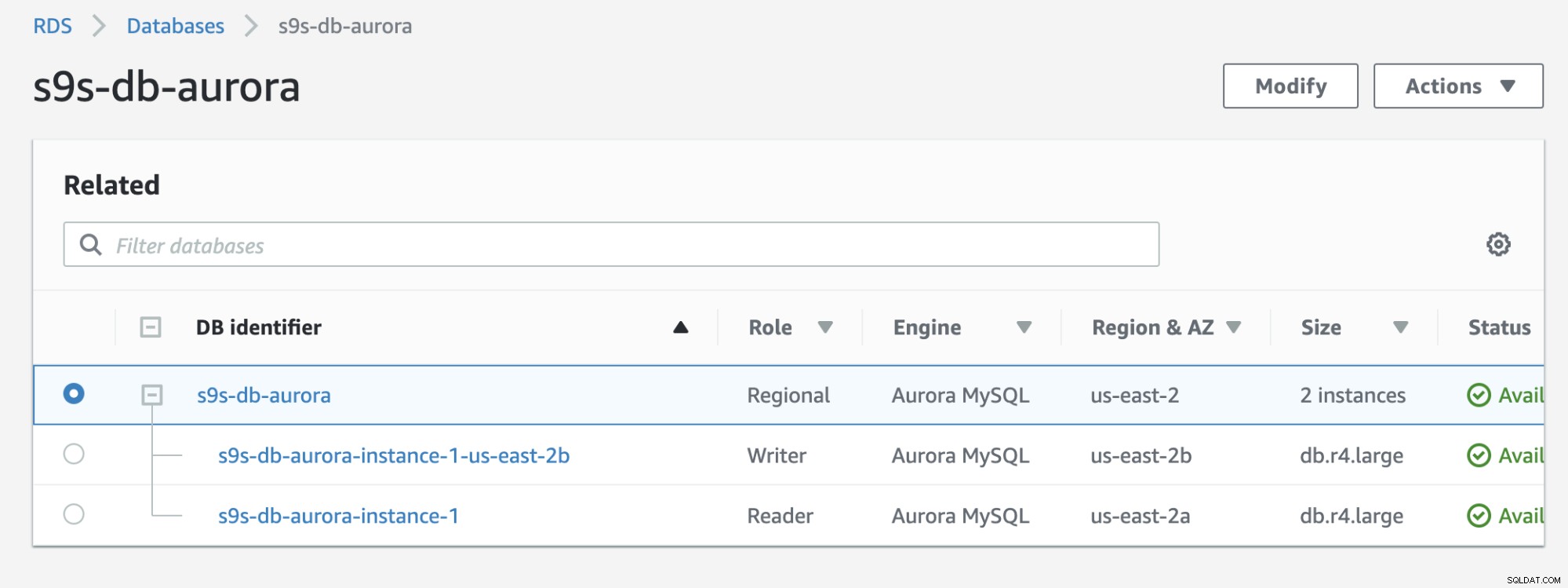
Wenn Sie mit dem früheren vergleichen, ist s9s-db-aurora- instance-1 war ein Leser, wurde dann aber nach dem Failover zum Schreiber hochgestuft. Der Prozess einschließlich des Tests dauerte etwa 44 Sekunden, um die Aufgabe abzuschließen, aber das Failover wurde nach fast 30 Sekunden abgeschlossen. Das ist beeindruckend und schnell für ein Failover, besonders wenn man bedenkt, dass es sich um eine Managed Service-Datenbank handelt; Das bedeutet, dass Sie sich keine Gedanken über Hardware- oder Wartungsprobleme machen müssen.
Durchführen eines Failbacks in Amazon RDS
Failback in Amazon RDS ist ziemlich einfach. Bevor wir es durchgehen, fügen wir eine neue Reader-Replik hinzu. Wir benötigen eine Option zum Testen und Identifizieren, aus welchem Knoten AWS RDS auswählen würde, wenn es versucht, auf den gewünschten Master (oder auf den vorherigen Master) zurückzugreifen, und um zu sehen, ob es basierend auf der Priorität den richtigen Knoten auswählt. Die aktuelle Liste der Instanzen ab sofort und ihre Endpunkte werden unten angezeigt.
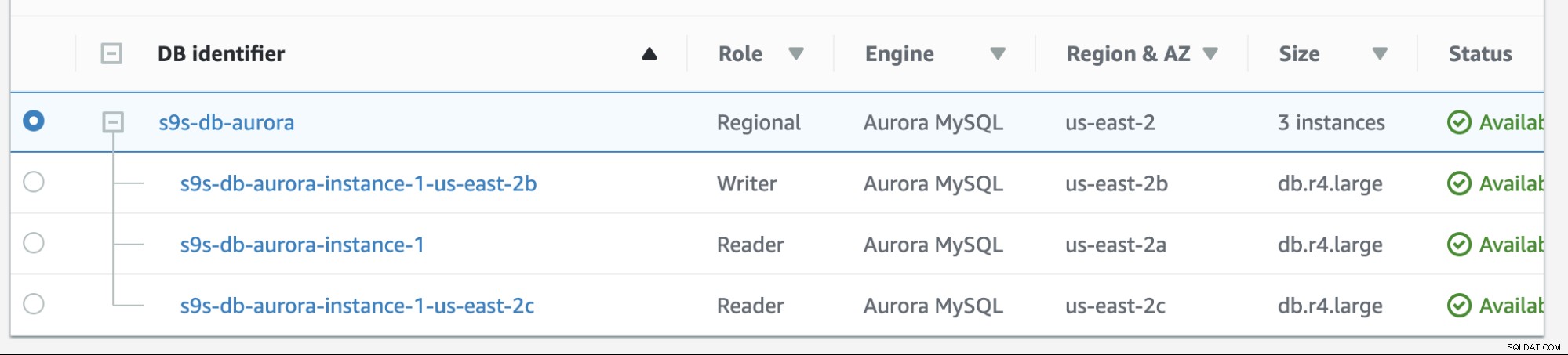

Das neue Replikat befindet sich auf us-east-2c AZ mit dem Hostnamen db von ip-10-20-2-239.
Wir versuchen, ein Failback durchzuführen, indem wir die Instanz s9s-db-aurora-instance-1 als gewünschtes Failback-Ziel verwenden. In diesem Setup haben wir zwei Reader-Instanzen. Um sicherzustellen, dass beim Failover der richtige Knoten abgeholt wird, müssen Sie feststellen, ob Priorität oder Verfügbarkeit oben liegen (Tier-0> Tier-1> Tier-2 usw. bis Tier-15). Dies kann durch Ändern der Instanz oder während der Erstellung des Replikats erfolgen.
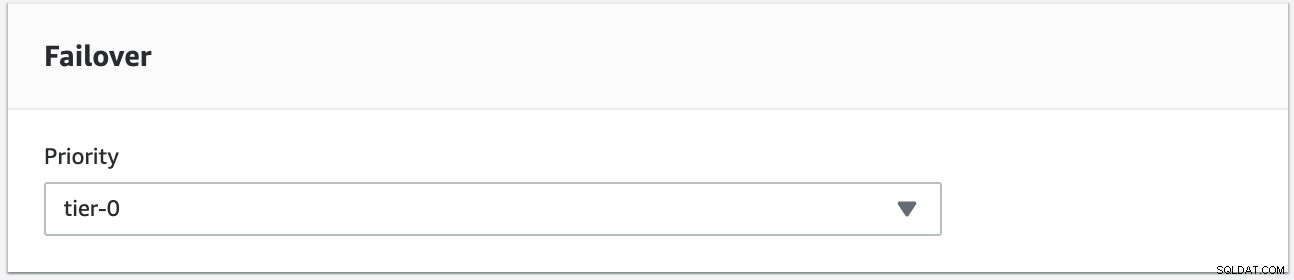
Sie können dies in Ihrer RDS-Konsole überprüfen.
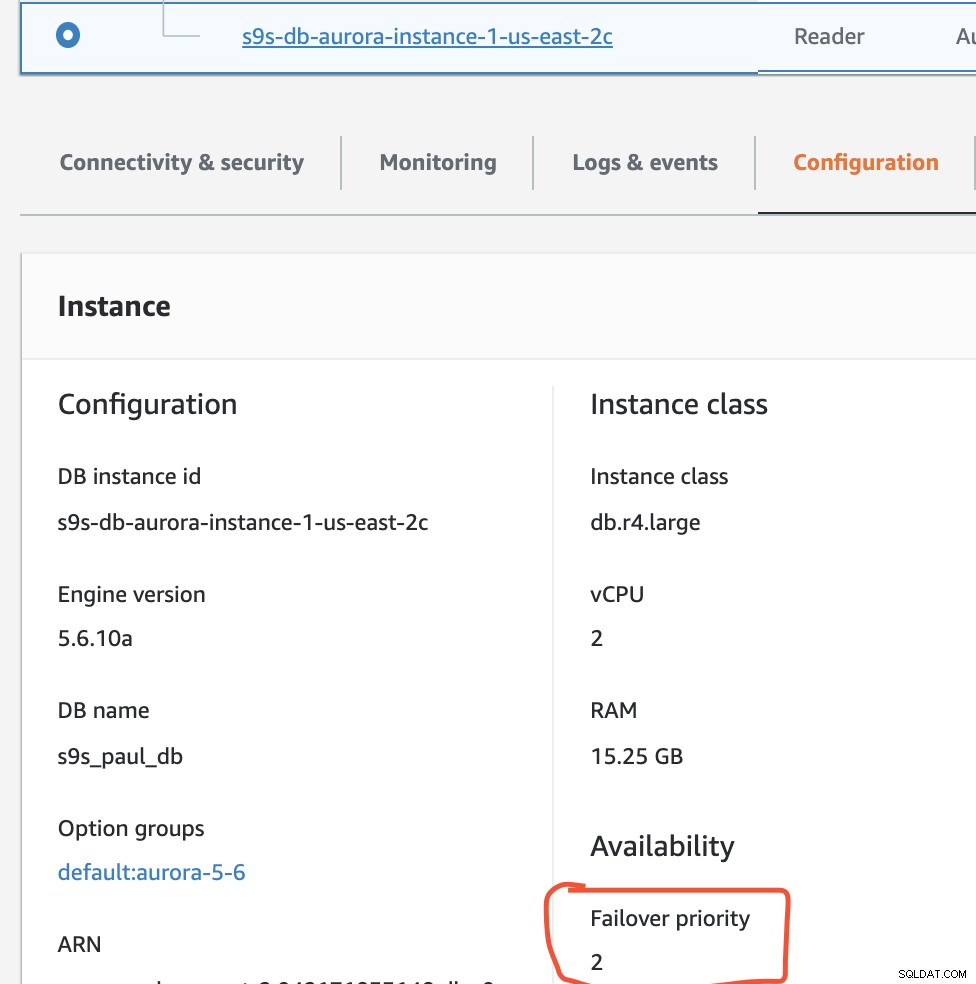
In diesem Setup hat s9s-db-aurora-instance-1 Priorität =0 (und ist eine Read-Replica), s9s-db-aurora-instance-1-us-east-2b hat Priorität =1 (und ist der aktuelle Writer) und s9s-db-aurora-instance-1-us- east-2c hat Priorität =2 (und ist auch eine Read-Replica). Mal sehen, was passiert, wenn wir ein Failback versuchen.
Sie können den Status mit diesem Befehl überwachen.
$ host=('s9s-db-aurora.cluster-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' 's9s-us-east-2c.cluster-custom-cmu8qdlvkepg.us-east-2.rds.amazonaws.com'); while true; do echo -e "\n==========================================="; date; echo -e "===========================================\n"; for h in "${host[@]}"; do mysql -h $h -e "select @@hostname; select @@global.innodb_read_only"; done; sleep 1; done;Nachdem das Failover ausgelöst wurde, erfolgt ein Failback zu unserem gewünschten Ziel, dem Knoten s9s-db-aurora-instance-1.
===========================================
Tue Sep 24 13:30:59 UTC 2019
===========================================
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
…
……
………
===========================================
Tue Sep 24 13:31:35 UTC 2019
===========================================
+----------------+
| @@hostname |
+----------------+
| ip-10-20-1-139 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-db-aurora.cluster-ro-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
ERROR 2003 (HY000): Can't connect to MySQL server on 's9s-us-east-2c.cluster-custom-cmu8qdlvkepg.us-east-2.rds.amazonaws.com' (111)
….
…..
===========================================
Tue Sep 24 13:31:38 UTC 2019
===========================================
+---------------+
| @@hostname |
+---------------+
| ip-10-20-0-94 |
+---------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 0 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+
+----------------+
| @@hostname |
+----------------+
| ip-10-20-2-239 |
+----------------+
+---------------------------+
| @@global.innodb_read_only |
+---------------------------+
| 1 |
+---------------------------+Der Failback-Versuch begann um 13:30:59 und endete um 13:31:38 (nächste 30-Sekunden-Marke). Es endet bei diesem Test mit ~32 Sekunden, was immer noch schnell ist.
Ich habe das Failover/Failback mehrfach verifiziert und es hat seinen Lese-/Schreibstatus ständig zwischen den Instanzen s9s-db-aurora-instance-1 und s9s-db-aurora-instance-1- ausgetauscht. us-ost-2b. Dadurch bleibt s9s-db-aurora-instance-1-us-east-2c ungewählt, es sei denn, bei beiden Knoten treten Probleme auf (was sehr selten vorkommt, da sie sich alle in verschiedenen AZs befinden).
Während der Failover-/Failback-Versuche geht RDS mit einem schnellen Übergangstempo während des Failovers von etwa 15 bis 25 Sekunden (was sehr schnell ist). Denken Sie daran, dass wir auf dieser Instanz keine großen Datendateien gespeichert haben, aber es ist immer noch ziemlich beeindruckend, wenn man bedenkt, dass es nichts weiter zu verwalten gibt.
Fazit
Das Ausführen einer Single-AZ bringt Gefahren mit sich, wenn ein Failover durchgeführt wird. Mit Amazon RDS können Sie Ihr Single-AZ-Setup modifizieren und in ein Multi-AZ-fähiges Setup konvertieren, obwohl dies einige Kosten für Sie verursacht. Single-AZ kann in Ordnung sein, wenn Sie mit einer höheren RTO- und RPO-Zeit einverstanden sind, wird aber definitiv nicht für stark frequentierte, unternehmenskritische Geschäftsanwendungen empfohlen.
Mit Multi-AZ können Sie Failover und Failback auf Amazon RDS automatisieren und Ihre Zeit damit verbringen, sich auf die Abstimmung oder Optimierung von Abfragen zu konzentrieren. Dies erleichtert viele Probleme, mit denen DevOps oder DBAs konfrontiert sind.
Während Amazon RDS in manchen Organisationen ein Dilemma verursachen kann (da es nicht plattformunabhängig ist), ist es dennoch eine Überlegung wert; insbesondere wenn Ihre Anwendung einen langfristigen DR-Plan erfordert und Sie sich keine Gedanken über Hardware- und Kapazitätsplanung machen möchten.



