Der Schwerpunkt dieses Artikels liegt auf der Verwendung von JOINs. Wir beginnen damit, ein wenig darüber zu sprechen, wie JOINs ablaufen werden und warum Sie JOIN-Daten benötigen. Dann werfen wir einen Blick auf die JOIN-Typen, die uns zur Verfügung stehen, und wie man sie verwendet.
WERDEN SIE GRUNDLAGEN BEI
JOINs in TSQL werden normalerweise in der FROM-Zeile ausgeführt.
Bevor wir zu irgendetwas anderem kommen, lautet die wirklich große Frage:„Warum müssen wir JOINs durchführen, und wie werden wir unsere JOINs tatsächlich durchführen?“
Wie sich herausstellt, werden die Daten jeder Datenbank, mit der wir jemals arbeiten, in mehrere Tabellen aufgeteilt. Dafür gibt es viele verschiedene Gründe:
- Wahrung der Datenintegrität
- Speicherplatz sparen
- Daten schneller bearbeiten
- Abfragen flexibler gestalten
Daher müssen diese Daten für jede Datenbank, mit der Sie arbeiten werden, zusammengeführt werden, damit sie tatsächlich Sinn ergibt.
Beispielsweise haben Sie getrennte Tabellen für Bestellungen und für Kunden. Die Frage, die sich daraus ergibt:„Wie verbinden wir eigentlich alle Daten miteinander?“ Genau das werden JOINs tun.
WIE JOINS FUNKTIONIEREN
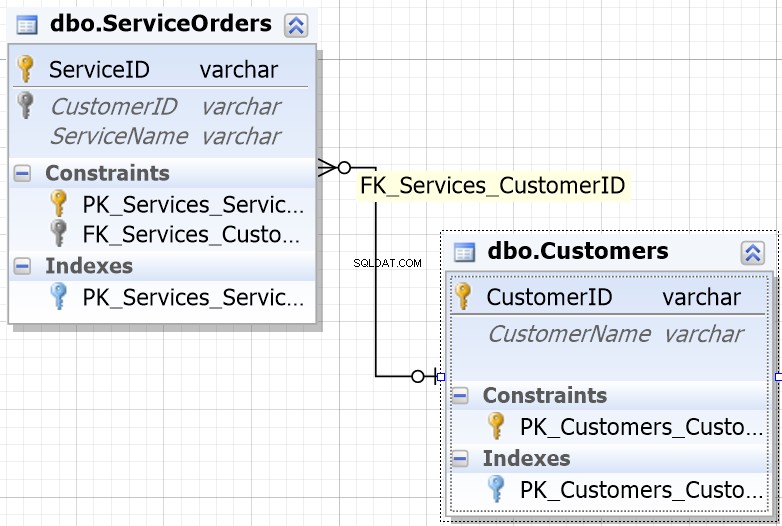
Stellen Sie sich den Fall vor, wenn wir zwei separate Tabellen haben und diese Tabellen durch Erstellen einer Naht zusammengeführt werden.
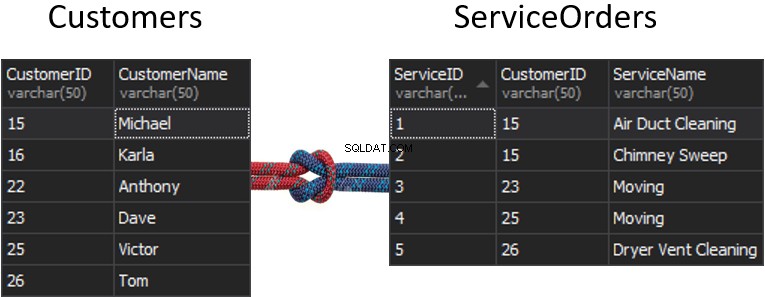
Was passiert mit der Naht, wenn wir eine Spalte aus jeder Tabelle erhalten, die für den Abgleich verwendet wird, und die bestimmt, welche Zeilen zurückgegeben werden und welche nicht? Zum Beispiel haben wir Kunden auf der linken Seite und Serviceaufträge auf der rechten Seite. Wenn wir alle Kunden und ihre Bestellungen erhalten möchten, müssen wir diese beiden Tabellen VERBINDEN. Dazu müssen wir eine Spalte auswählen, die als Naht dient, und natürlich ist die Spalte, die wir verwenden werden, CustomerID.
Die Kunden-ID wird übrigens als Primärschlüssel bezeichnet für die linke Tabelle, die jede einzelne Zeile innerhalb der Customers-Tabelle eindeutig identifiziert.
In der ServiceOrders-Tabelle haben wir auch die CustomerID-Spalte, die als Fremdschlüssel bekannt ist . Ein Fremdschlüssel ist einfach eine Spalte, die auf eine andere Tabelle zeigen soll. In unserem Fall zeigt es zurück auf die Customers-Tabelle. Auf diese Weise werden wir all diese Daten zusammenführen, indem wir diese Naht bereitstellen.
In diesen Tabellen haben wir die folgenden Übereinstimmungen:2 Bestellungen für 15 und 1 Bestellung für 23, 25 und 26. 16 und 22 werden ausgelassen.
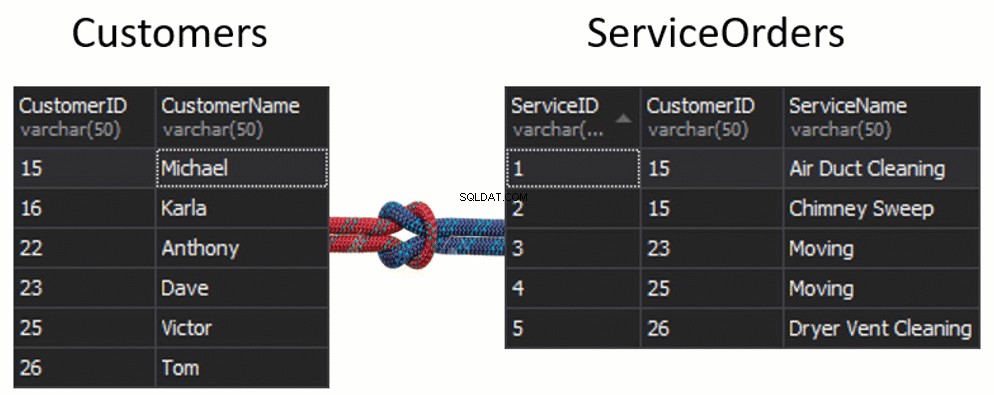
Eine wichtige Sache, die hier zu beachten ist, ist, dass wir mehrere Tische VERKNÜPFEN können . Tatsächlich ist es durchaus üblich, mehrere Tabellen miteinander zu verknüpfen, um jede Form von Informationen zu erhalten. Wenn Sie sich die gängigsten Datenbanken ansehen, müssen Sie möglicherweise vier, fünf, sechs und mehr Tabellen miteinander verknüpfen, um die gesuchten Informationen zu erhalten. Ein Datenbankdiagramm wird hilfreich sein.
Um Ihnen in den meisten Datenbankumgebungen zu helfen, werden Sie feststellen, dass die Spalten, die zum Verknüpfen vorgesehen sind, denselben Namen haben.
JOIN-SYNTAX
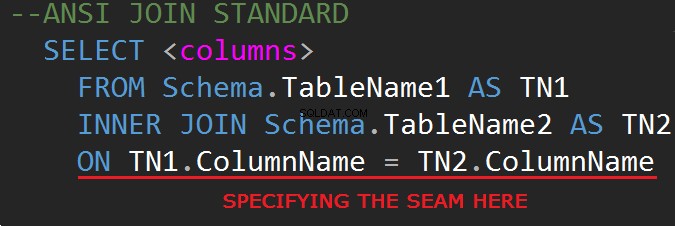
Die dritte Revision der SQL-Datenbank-Abfragesprache (SQL-92) regelt die JOIN-Syntax:
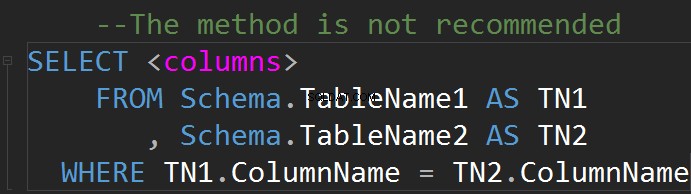
Es ist möglich, JOINs in der WHERE-Zeile auszuführen:
Eine Relation hat normalerweise eine einfache grafische Interpretation in Form einer Tabelle.
Best Practices und Konventionen
- Aliastabellennamen.
- Verwenden Sie zweiteilige Namen für Spalten
- Platzieren Sie jeden JOIN in einer separaten Zeile
- Platzieren Sie Tabellen in einer logischen Reihenfolge
JOIN-TYPEN
SQL Server bietet die folgenden Arten von JOINs:
- INNER JOIN
- OUTER JOIN
- SELBST BEITRETEN
- CROSS JOIN
Weitere Informationen zu diesem Thema finden Sie in diesem Artikel über die Join-Typen in SQL Server und erfahren Sie, wie einfach es ist, solche Abfragen mit Hilfe von SQL Complete zu schreiben.
INNERER JOIN
Der erste JOIN-Typ, den wir möglicherweise ausführen möchten, ist der INNER JOIN. Normalerweise bezeichnen Autoren diese Art von SQL Server-JOINs als regulären oder einfachen JOIN. Sie lassen einfach das Präfix INNER weg. Diese Art von JOIN kombiniert zwei Tabellen miteinander und gibt nur Zeilen von beiden Seiten zurück, die übereinstimmen .
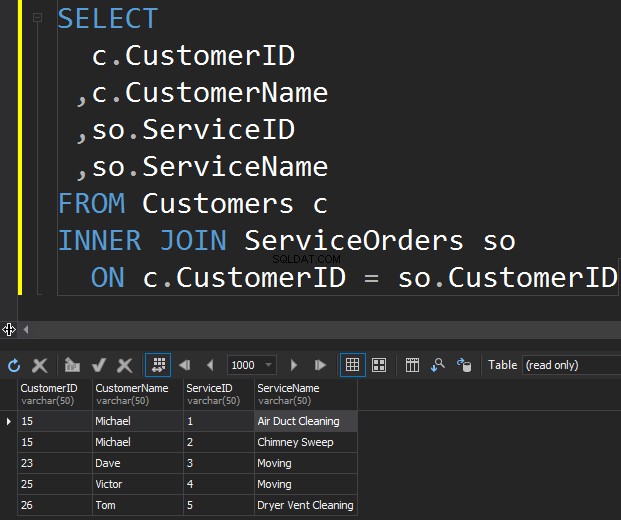
Wir sehen Klara und Anthony hier nicht, weil ihre CustomerID nicht in beiden Tabellen übereinstimmt. Ich möchte auch die Tatsache hervorheben, dass die JOIN-Operation jedes Mal einen Kunden zurückgibt, wenn sie mit der Bestellung übereinstimmt . Es gibt zwei Bestellungen für Michael und jeweils eine Bestellung für Dave, Victor und Tom.
Zusammenfassung:
- INNER JOIN gibt Zeilen nur zurück, wenn es mindestens eine Zeile in beiden Tabellen gibt, die der JOIN-Bedingung entspricht.
- INNER JOIN eliminiert die Zeilen, die nicht mit einer Zeile aus der anderen Tabelle übereinstimmen
OUTER JOIN
Äußere JOINs sind anders, da sie Zeilen aus Tabellen oder Ansichten zurückgeben, selbst wenn sie nicht übereinstimmen. Diese Art von JOIN ist nützlich, wenn Sie alle Kunden abrufen müssen, die noch nie eine Bestellung aufgegeben haben. Oder wenn Sie zum Beispiel ein Produkt suchen, das noch nie bestellt wurde.
Die Art und Weise, wie wir unsere OUTER JOINs ausführen, besteht darin, LEFT oder RIGHT oder FULL anzugeben.
Es gibt keine Unterschiede zwischen den folgenden Klauseln:
- LEFT OUTER JOIN =LINKER JOIN
- RIGHT OUTER JOIN =RIGHT JOIN
- FULL OUTER JOIN =FULL JOIN
Ich würde jedoch empfehlen, die vollständige Klausel zu schreiben, da dies den Code lesbarer macht.
Mit LEFT OUTER JOIN
Es gibt keinen Unterschied zwischen LINKS oder RECHTS außer der Tatsache, dass wir nur auf die Tabelle zeigen, aus der wir die zusätzlichen Zeilen erhalten möchten. Im folgenden Beispiel haben wir Kunden und ihre Bestellungen aufgelistet. Wir nutzen die LINKE, um alle Kunden zu erreichen, die noch nie eine Bestellung aufgegeben haben. Wir bitten SQL Server, uns zusätzliche Zeilen aus der linken Tabelle zu holen.
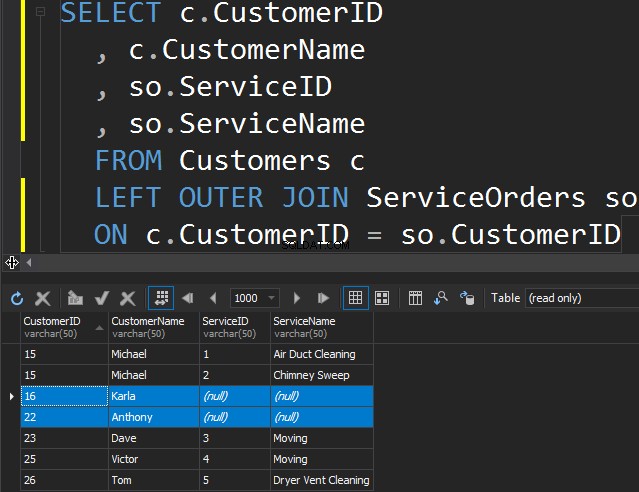
Beachten Sie, dass Karla und Anthony keine Bestellungen aufgegeben haben und wir daher NULL-Werte für ServiceName und ServiceID erhalten. SQL Server weiß nicht, was dort eingefügt werden soll, und fügt NULL-Werte ein.
Mit RIGHT OUTER JOIN
Um den weniger beliebten Service aus der ServiceOrders-Tabelle zu erhalten, müssen wir die RECHTE Richtung verwenden.
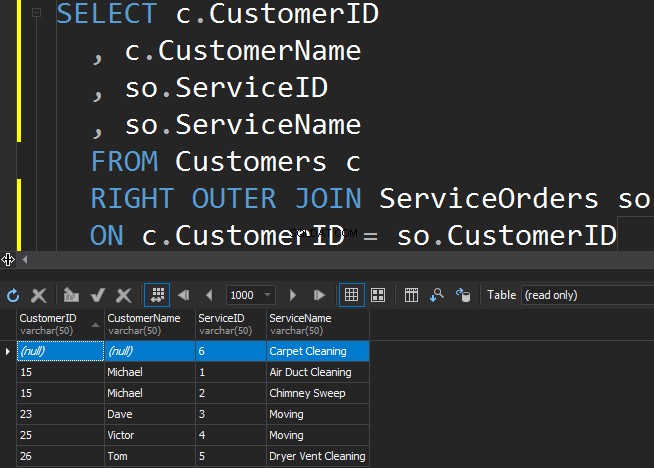
Wir sehen, dass SQL Server in diesem Fall zusätzliche Zeilen aus der rechten Tabelle zurückgegeben hat und der Teppichreinigungsdienst nie bestellt wurde.
FULL OUTER JOIN verwenden
Diese Art von JOIN ermöglicht es Ihnen, die nicht übereinstimmenden Informationen zu erhalten, indem Sie nicht übereinstimmende Zeilen aus beiden Tabellen einbeziehen.
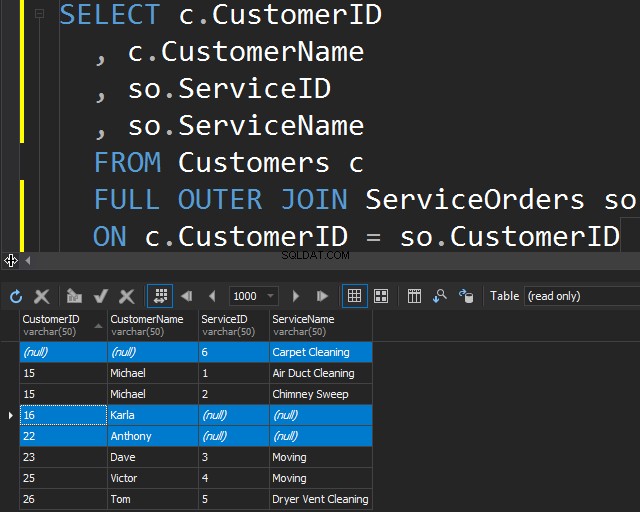
Dies kann auch nützlich sein, wenn Sie eine Datenbereinigung durchführen müssen.
Zusammenfassung:
FULL OUTER JOIN
- Gibt Zeilen aus beiden Tabellen zurück, auch wenn sie nicht mit der JOIN-Anweisung übereinstimmen
LINKS oder RECHTS
- Kein Unterschied außer in der Reihenfolge der Tabellen in der FROM-Klausel
- Richtung zeigt auf eine Tabelle, um nicht übereinstimmende Zeilen abzurufen
SELBST BEITRETEN
Die nächste Art von JOINs, die wir haben, ist SELF JOIN. Dies ist wahrscheinlich die zweithäufigste Art von JOIN, die Sie jemals ausführen werden. Ein SELF JOIN ist, wenn Sie einen Tisch mit sich selbst verbinden. Im Allgemeinen ist dies ein Zeichen für schlechtes Design. Um dieselbe Tabelle zweimal in einer einzigen Abfrage zu verwenden, muss die Tabelle mit einem Alias versehen werden. Der Alias hilft dem Abfrageprozessor zu erkennen, ob Spalten Daten von der rechten oder linken Seite darstellen sollen. Außerdem müssen Sie Reihen eliminieren, die selbst marschieren. Dies geschieht normalerweise mit einem Non-Equi-Join.
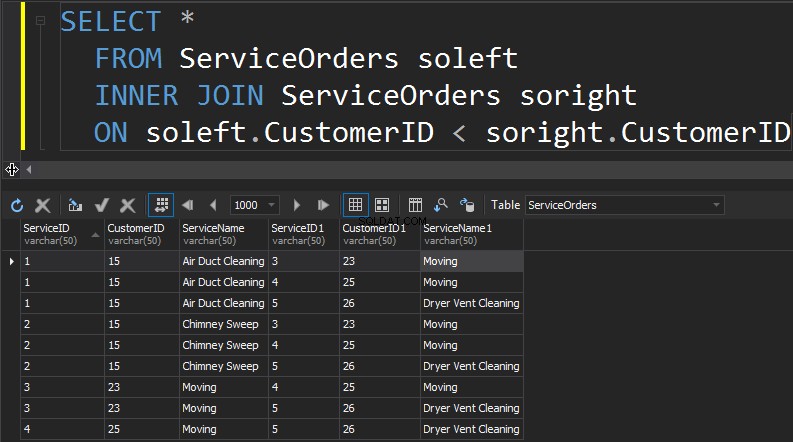
Zusammenfassung:
- Verbindet eine Tabelle mit sich selbst
- Allgemein ein Zeichen für schlechtes Design und Normalisierung
- Tabellen müssen Aliasnamen haben
- Müssen Zeilen filtern, die mit sich selbst übereinstimmen
CROSS JOINS
Diese Art von JOINs hat nicht das ON Erklärung. Jede einzelne Zeile aus jeder Tabelle wird übereinstimmen. Dies wird auch als kartesisches Produkt bezeichnet (falls ein CROSS JOIN keine WHERE-Klausel hat). Sie werden diesen JOIN-Typ in realen Szenarien kaum verwenden, er ist jedoch eine gute Möglichkeit, Testdaten zu generieren.
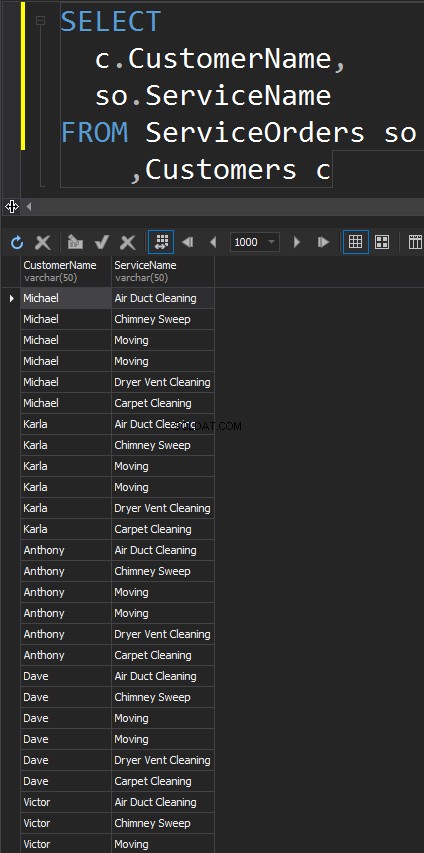
Das Ergebnis ist ein Datensatz, bei dem die Anzahl der Zeilen in der linken Tabelle mit der Anzahl der Zeilen in der rechten Tabelle multipliziert wird. Schließlich sehen wir, dass jeder einzelne Kunde zu jedem einzelnen Service passt.
Wir erhalten dasselbe Ergebnis, wenn wir die CROSS JOIN-Klausel explizit verwenden.
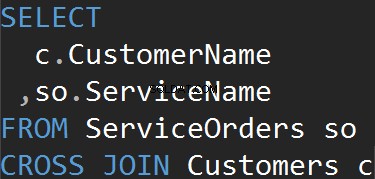
Zusammenfassung:
- Alle Zeilen stimmen aus jeder Tabelle überein
- Keine ON-Anweisung
- Kann verwendet werden, um Testdaten zu generieren
ALGORITHMEN VERBINDEN
Im ersten Teil des Artikels haben wir logisch besprochen JOIN-Operatoren, die SQL Server beim Analysieren und Binden von Abfragen verwendet. Sie sind:
- INNER JOIN
- OUTER JOIN
- CROSS JOIN
Die logischen Operatoren sind konzeptionell und unterscheiden sich von den physikalischen VERBINDET. Ansonsten werden logische JOINs nicht tatsächlich verknüpft bestimmte Tabellenspalten. Ein einzelner logischer JOIN kann vielen physischen JOINs entsprechen. SQL Server ersetzt während der Optimierung logische JOINs durch physische JOINs. SQL Server verfügt über die folgenden physikalischen JOIN-Operatoren:
- VERSCHACHTELTE SCHLEIFE
- VEREINIGUNG
- HASH
Ein Benutzer schreibt oder verwendet diese Arten von JOINS nicht. Sie sind Teil der SQL Server-Engine und werden von SQL Server intern verwendet, um logische JOINs zu implementieren. Wenn Sie den Ausführungsplan untersuchen, stellen Sie möglicherweise fest, dass SQL Server logische JOIN-Operatoren durch einen von drei physischen Operatoren ersetzt.
Nested-Loop-Join
Beginnen wir mit dem einfachsten Operator, nämlich Nested Loop. Der Algorithmus vergleicht jede einzelne Zeile einer Tabelle (äußere Tabelle) mit jeder Zeile der anderen Tabelle (innere Tabelle) und sucht nach Zeilen, die das JOIN-Prädikat erfüllen.
Der folgende Pseudocode beschreibt den inneren verschachtelten Join-Loop-Algorithmus:

Der folgende Pseudocode beschreibt den Algorithmus der äußeren verschachtelten Join-Schleife:
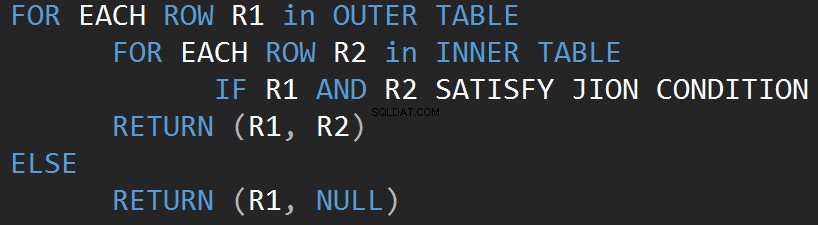
Die Größe der Eingabe wirkt sich direkt auf die Algorithmuskosten aus. Der Input wächst, die Kosten wachsen auch. Diese Art von JOIN-Algorithmus ist bei kleinen Eingaben effizient. SQL Server schätzt ein JOIN-Prädikat für jede Zeile in beiden Eingaben.
Betrachten Sie die folgende Abfrage als Beispiel, die Kunden und ihre Bestellungen abruft.
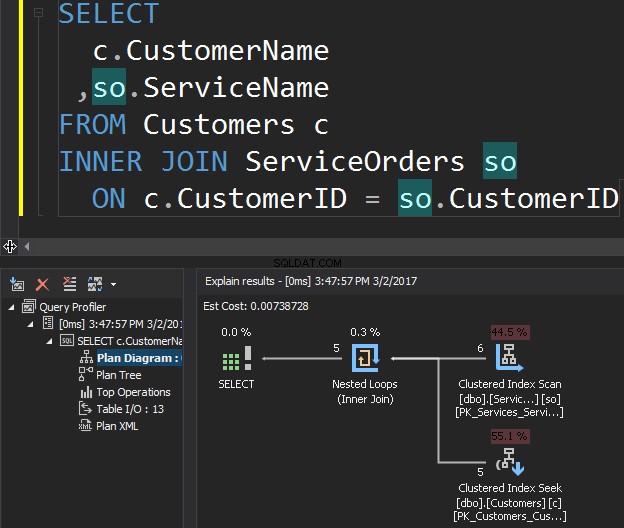
Der Clustered Index Scan-Operator ist die äußere Eingabe und der Clustered Index Seek ist die innere Eingabe . Der Nested-Loop-Operator findet tatsächlich Übereinstimmungen. Der Operator sucht nach jedem Datensatz in der äußeren Eingabe und findet übereinstimmende Zeilen in der inneren Eingabe. SQL Server führt den Clustered Index Scan-Vorgang (äußere Eingabe) nur einmal aus, um alle relevanten Datensätze abzurufen. Clustered Index Seek wird für jeden Datensatz von der äußeren Eingabe ausgeführt. Um dies zu bestätigen, navigieren Sie mit dem Cursor zum Operator-Symbol und sehen Sie sich den Tooltip an.
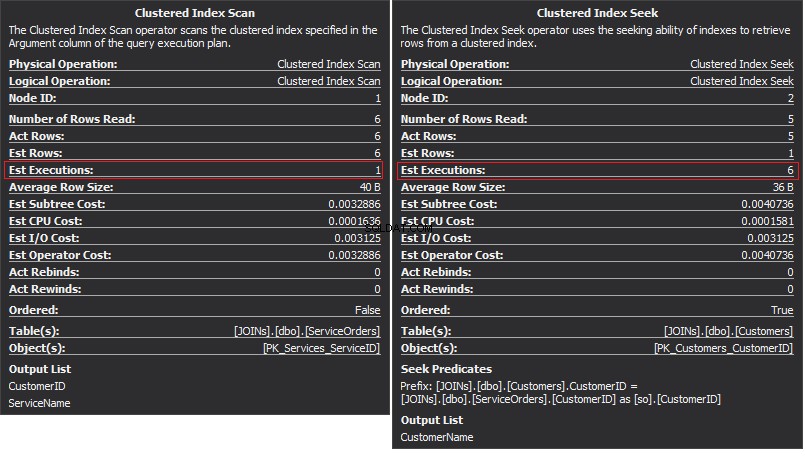
Reden wir über die Komplexität. Angenommen N ist die Zeilennummer für die äußere Ausgabe. M ist die Gesamtzahl der Zeilen in SalesOrders Tisch. Somit ist die Komplexität der Abfrage O(NLogM) wobei LogM ist die Komplexität jeder Suche in der inneren Eingabe. Der Optimierer wählt diesen Operator jedes Mal aus, wenn die äußere Eingabe klein ist und die innere Eingabe einen Index in der Spalte enthält, die als Naht fungiert. Daher sind Indizes und Statistiken für diesen JOIN-Typ unerlässlich, da SQL Server sonst versehentlich denkt, dass in einer der Eingaben nicht so viele Zeilen vorhanden sind. Es ist besser, einen Tabellenscan durchzuführen, anstatt Index Seek 100.000 Mal durchzuführen. Besonders wenn die innere Eingabegröße mehr als 100 KB beträgt.
Zusammenfassung:
Verschachtelte Schleifen
- Komplexität:O(NlogM)
- Wird normalerweise angewendet, wenn eine Tabelle klein ist
- Die größere Tabelle enthält einen Index, der die Suche mit dem Join-Schlüssel ermöglicht
Join zusammenführen
Einige Entwickler verstehen Hash- und Merge-JOINs nicht vollständig und bringen sie häufig mit Abfragen mit schlechter Leistung in Verbindung.
Im Gegensatz zur verschachtelten Schleife, die jedes JOIN-Prädikat akzeptiert, erfordert der Merge-Join mindestens einen Equi-Join. Außerdem müssen beide Eingaben nach den JOIN-Tasten sortiert werden.
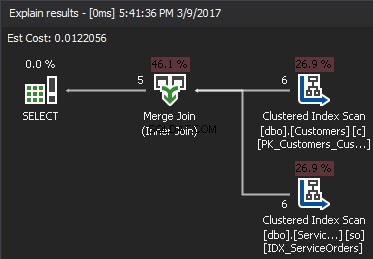
Der Pseudocode für den MERGE JOIN-Algorithmus:
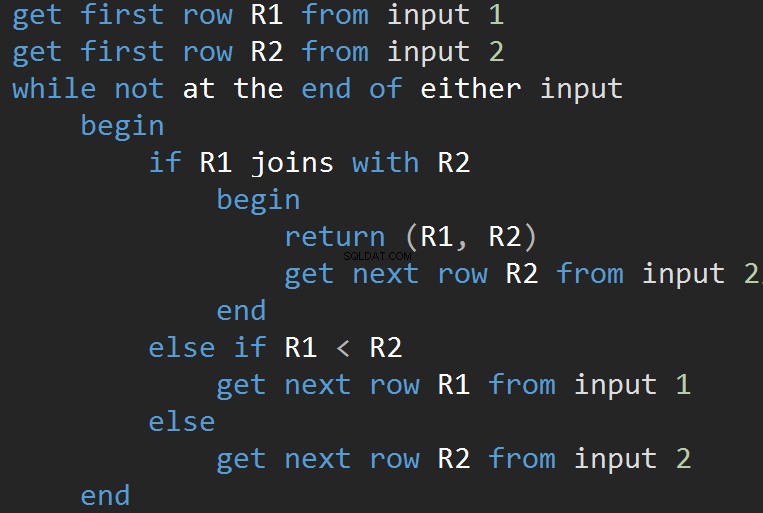
Der Algorithmus vergleicht zwei sortierte Eingaben. Eine Reihe nach der anderen. Falls es eine Gleichheit zwischen zwei Zeilen gibt, gibt der Algorithmus Zeilen verbinden und fortfahren. Wenn nicht, verwirft der Algorithmus die kleinere der beiden Eingaben und fährt fort. Anders als bei der verschachtelten Schleife sind die Kosten hier proportional zur Summe der Anzahl der Eingabezeilen. In Bezug auf die Komplexität – O(N+M). Daher ist diese Art von JOINs oft besser für große Eingaben.
Die folgende Animation zeigt, wie der MERGE JOIN-Algorithmus tatsächlich Tabellenzeilen verbindet.
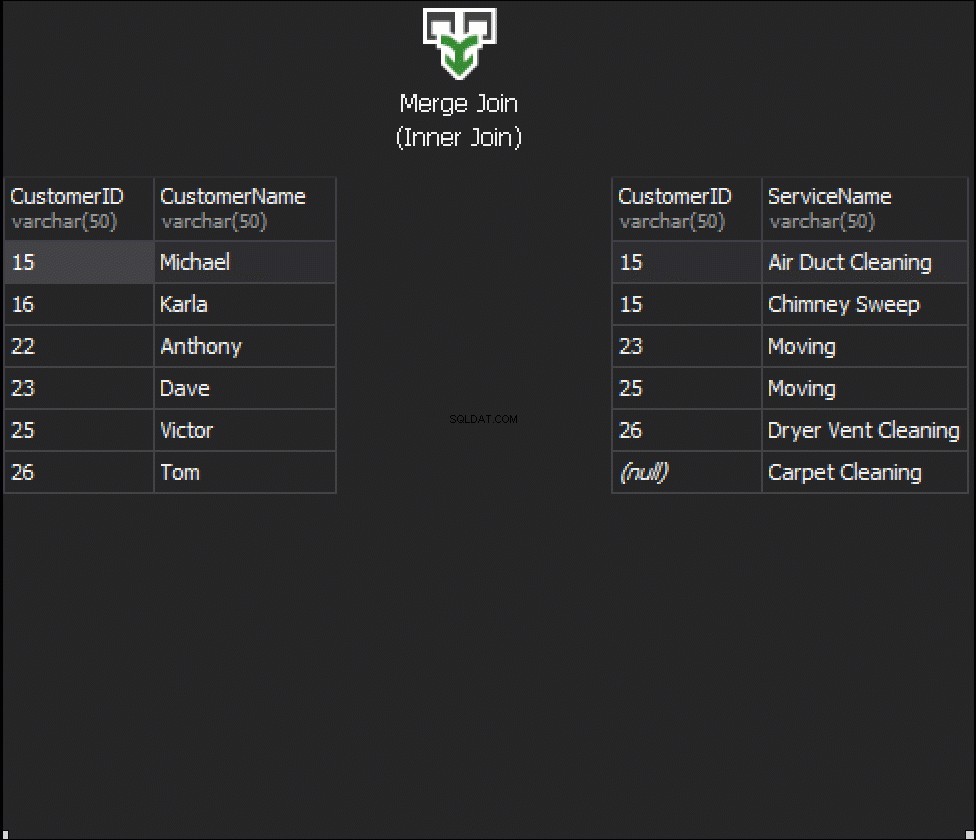
Zusammenfassung
- Komplexität:O(N+M)
- Beide Eingaben müssen nach dem Join-Schlüssel sortiert werden
- Es wird ein Gleichheitsoperator verwendet
- Ausgezeichnet für große Tabellen
Hash-Join
Hash Join eignet sich gut für große Tabellen ohne nutzbaren Index. Im ersten Schritt – Bauphase Der Algorithmus erstellt einen In-Memory-Hash-Index für die Eingabe auf der linken Seite. Der zweite Schritt wird als Probephase bezeichnet . Der Algorithmus durchläuft die Eingabe auf der rechten Seite und findet anhand des während der Erstellungsphase erstellten Index Übereinstimmungen. Ehrlich gesagt ist es kein gutes Zeichen, wenn der Optimierer diese Art von JOIN-Algorithmus wählt.
Es gibt zwei wichtige Konzepte, die dieser Art von JOINs zugrunde liegen:Hash-Funktion und Hash-Tabelle.
Eine Hash-Funktion ist eine beliebige Funktion, die verwendet werden kann, um Daten variabler Größe auf Daten fester Größe abzubilden.
Eine Hash-Tabelle ist eine Datenstruktur, die verwendet wird, um ein assoziatives Array zu implementieren, eine Struktur, die Schlüssel auf Werte abbilden kann. Eine Hash-Tabelle verwendet eine Hash-Funktion, um einen Index in ein Array von Buckets oder Slots zu berechnen, aus dem der gewünschte Wert gefunden werden kann.
Basierend auf den verfügbaren Statistiken wählt SQL Server die kleinste Eingabe als Build-Eingabe aus und verwendet sie zum Erstellen einer Hashtabelle im Arbeitsspeicher. Wenn nicht genügend Arbeitsspeicher vorhanden ist, verwendet SQL Server physischen Speicherplatz in TempDB. Nachdem die Hashtabelle erstellt wurde, ruft SQL Server die Daten aus der Sondeneingabe (größere Tabelle) ab und vergleicht sie mithilfe einer Hash-Match-Funktion mit der Hashtabelle. Als Ergebnis werden übereinstimmende Zeilen zurückgegeben.
Wenn wir uns den Ausführungsplan ansehen, ist das rechte oberste Element die Build-Eingabe , und das rechte untere Element ist die Sondeneingabe . Falls beide Inputs extrem groß sind, sind die Kosten zu hoch.
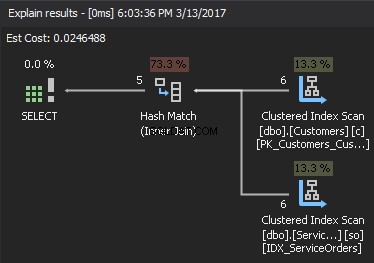
Um die Komplexität abzuschätzen, nehmen Sie Folgendes an:
hc – Komplexität der Erstellung der Hash-Tabelle
hm – Komplexität der Hash-Match-Funktion
N – kleinerer Tisch
M – größere Tabelle
J – Komplexitätszusatz für die dynamische Berechnung und Erstellung der Hashfunktion
Die Komplexität wird sein:O(N*hc + M*hm +J)
Der Optimierer verwendet Statistiken, um die Wertkardinalität zu bestimmen. Dann erstellt es dynamisch eine Hash-Funktion, die Daten in viele Buckets mit gleicher Größe aufteilt. Aufgrund der dynamischen Natur ist es oft schwierig, die Komplexität des Hash-Tabellen-Erstellungsprozesses sowie die Komplexität jeder Hash-Übereinstimmung abzuschätzen. Der Ausführungsplan kann sogar falsche Schätzungen anzeigen, da der Optimierer all diese dynamischen Operationen während der Ausführungszeit durchführt. In einigen Fällen kann der Ausführungsplan zeigen, dass Nested Loop teurer als Hash Join ist, aber tatsächlich wird Hash Join aufgrund der falschen Kostenschätzung langsamer ausgeführt.
Zusammenfassung
- Komplexität:O(N*hc +M*hm +J)
- Joint-Typ des letzten Auswegs
- Verwendet eine Hash-Tabelle und eine dynamische Hash-Match-Funktion, um Zeilen abzugleichen
Nützliche Produkte:
SQL Complete – schreiben, verschönern, refaktorisieren Sie Ihren Code ganz einfach und steigern Sie Ihre Produktivität.