Was bewirkt die Indizierung?
Indizieren ist der Weg, um eine ungeordnete Tabelle in eine Reihenfolge zu bringen, die die Effizienz der Abfrage beim Suchen maximiert.
Wenn eine Tabelle nicht indiziert ist, wird die Reihenfolge der Zeilen wahrscheinlich in keiner Weise von der Abfrage als optimiert erkennbar sein, und Ihre Abfrage muss daher die Zeilen linear durchsuchen. Mit anderen Worten, die Abfragen müssen jede Zeile durchsuchen, um die Zeilen zu finden, die den Bedingungen entsprechen. Wie Sie sich vorstellen können, kann dies lange dauern. Jede einzelne Zeile durchzusehen ist nicht sehr effizient.
Die folgende Tabelle stellt beispielsweise eine Tabelle in einer fiktiven Datenquelle dar, die vollständig ungeordnet ist.
| company_id | Einheit | Stückkosten |
|---|---|---|
| 10 | 12 | 1.15 |
| 12 | 12 | 1.05 |
| 14 | 18 | 1.31 |
| 18 | 18 | 1.34 |
| 11 | 24 | 1.15 |
| 16 | 12 | 1.31 |
| 10 | 12 | 1.15 |
| 12 | 24 | 1.3 |
| 18 | 6 | 1.34 |
| 18 | 12 | 1,35 |
| 14 | 12 | 1,95 |
| 21 | 18 | 1.36 |
| 12 | 12 | 1.05 |
| 20 | 6 | 1.31 |
| 18 | 18 | 1.34 |
| 11 | 24 | 1.15 |
| 14 | 24 | 1.05 |
Wenn wir die folgende Abfrage ausführen würden:
SELECT
company_id,
units,
unit_cost
FROM
index_test
WHERE
company_id = 18
Die Datenbank müsste alle 17 Zeilen in der Reihenfolge durchsuchen, in der sie in der Tabelle erscheinen, von oben nach unten, eine nach der anderen. Suchen Sie also nach allen möglichen Instanzen der company_id Nummer 18, muss die Datenbank die gesamte Tabelle nach allen Vorkommen von 18 in der company_id durchsuchen Spalte.
Dies wird nur mit zunehmender Größe der Tabelle immer zeitaufwändiger. Mit zunehmender Ausgereiftheit der Daten könnte schließlich passieren, dass eine Tabelle mit einer Milliarde Zeilen mit einer anderen Tabelle mit einer Milliarde Zeilen verknüpft wird; die Abfrage muss jetzt doppelt so viele Zeilen durchsuchen, was doppelt so viel Zeit kostet.
Sie können sehen, wie dies in unserer immer datengesättigten Welt problematisch wird. Tabellen werden größer und die Suche verlängert sich in der Ausführungszeit.
Das Abfragen einer nicht indizierten Tabelle würde, wenn sie visuell dargestellt wird, wie folgt aussehen:
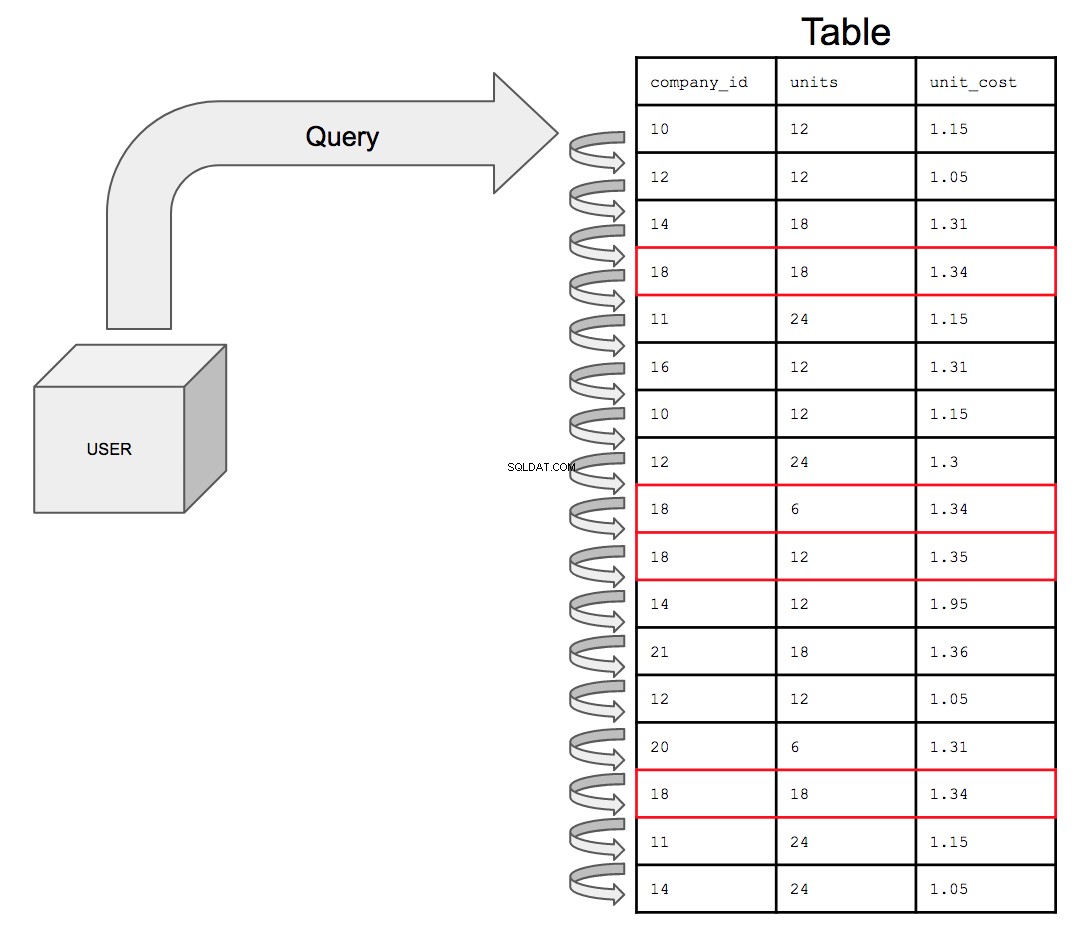
Bei der Indizierung wird die Spalte, in der sich Ihre Suchbedingungen befinden, in einer sortierten Reihenfolge eingerichtet, um die Optimierung der Abfrageleistung zu unterstützen.
Mit einem Index auf die company_id Spalte würde die Tabelle im Wesentlichen so „aussehen“:
| company_id | Einheit | Stückkosten |
|---|---|---|
| 10 | 12 | 1.15 |
| 10 | 12 | 1.15 |
| 11 | 24 | 1.15 |
| 11 | 24 | 1.15 |
| 12 | 12 | 1.05 |
| 12 | 24 | 1.3 |
| 12 | 12 | 1.05 |
| 14 | 18 | 1.31 |
| 14 | 12 | 1,95 |
| 14 | 24 | 1.05 |
| 16 | 12 | 1.31 |
| 18 | 18 | 1.34 |
| 18 | 6 | 1.34 |
| 18 | 12 | 1,35 |
| 18 | 18 | 1.34 |
| 20 | 6 | 1.31 |
| 21 | 18 | 1.36 |
Jetzt kann die Datenbank nach company_id suchen Nummer 18 und geben Sie alle angeforderten Spalten für diese Zeile zurück und fahren Sie dann mit der nächsten Zeile fort. Wenn die comapny_id der nächsten Zeile number ist auch 18, dann werden alle in der Abfrage angeforderten Spalten zurückgegeben. Wenn die company_id der nächsten Zeile 20 ist, weiß die Abfrage, dass sie die Suche beenden soll, und die Abfrage wird beendet.
Wie funktioniert die Indexierung?
In Wirklichkeit ordnet sich die Datenbanktabelle nicht jedes Mal neu, wenn sich die Abfragebedingungen ändern, um die Abfrageleistung zu optimieren:Das wäre unrealistisch. Tatsächlich bewirkt der Index, dass die Datenbank eine Datenstruktur erstellt. Der Datenstrukturtyp ist sehr wahrscheinlich ein B-Baum. Obwohl die Vorteile des B-Baums zahlreich sind, besteht der Hauptvorteil für unsere Zwecke darin, dass er sortierbar ist. Wenn die Datenstruktur der Reihe nach sortiert ist, wird unsere Suche aus den offensichtlichen Gründen, die wir oben aufgezeigt haben, effizienter.
Wenn der Index eine Datenstruktur für eine bestimmte Spalte erstellt, ist es wichtig zu beachten, dass keine andere Spalte in der Datenstruktur gespeichert wird. Unsere Datenstruktur für die obige Tabelle enthält nur die company_id Zahlen. Einheiten und unit_cost wird nicht in der Datenstruktur gespeichert.
Woher weiß die Datenbank, welche anderen Felder in der Tabelle zurückzugeben sind?
Datenbankindizes speichern auch Zeiger, die einfach Referenzinformationen für den Ort der zusätzlichen Informationen im Speicher sind. Grundsätzlich enthält der Index die company_id und die Heimatadresse dieser bestimmten Zeile auf der Speicherplatte. Der Index sieht tatsächlich so aus:
| company_id | Zeiger |
|---|---|
| 10 | _123 |
| 10 | _129 |
| 11 | _127 |
| 11 | _138 |
| 12 | _124 |
| 12 | _130 |
| 12 | _135 |
| 14 | _125 |
| 14 | _131 |
| 14 | _133 |
| 16 | _128 |
| 18 | _126 |
| 18 | _131 |
| 18 | _132 |
| 18 | _137 |
| 20 | _136 |
| 21 | _134 |
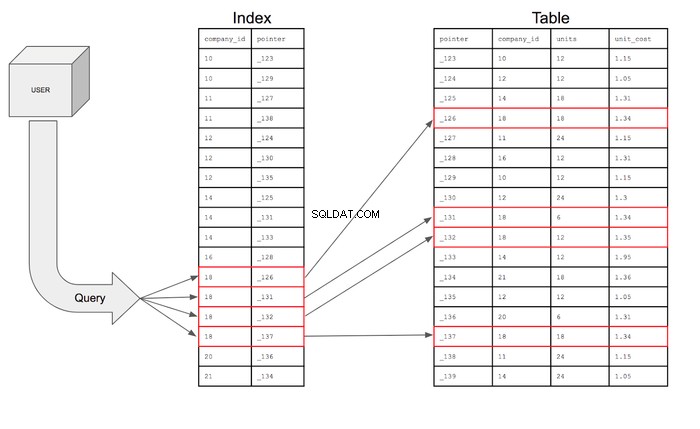
Mit diesem Index kann die Abfrage nur nach den Zeilen in company_id suchen Spalte, die 18 haben und dann mit dem Zeiger in die Tabelle gehen können, um die bestimmte Zeile zu finden, in der sich dieser Zeiger befindet. Die Abfrage kann dann in die Tabelle gehen, um die Felder für die Spalten abzurufen, die für die Zeilen angefordert werden, die die Bedingungen erfüllen.
Wenn die Suche visuell dargestellt würde, würde sie so aussehen:
Zusammenfassung
- Indizierung fügt eine Datenstruktur mit Spalten für die Suchbedingungen und einen Zeiger hinzu
- Der Zeiger ist die Adresse auf der Speicherplatte der Zeile mit den restlichen Informationen
- Die Indexdatenstruktur ist sortiert, um die Abfrageeffizienz zu optimieren
- Die Abfrage sucht nach der bestimmten Zeile im Index; der Index bezieht sich auf den Zeiger, der die restlichen Informationen findet.
- Der Index reduziert die Anzahl der Zeilen, die die Abfrage durchsuchen muss, von 17 auf 4.