Zunächst ist es wichtig zu wissen, nach welchen Spalten Sie gruppieren möchten und wie Sie sie gruppieren möchten. Das müssen Sie wissen, um die CASE STATEMENT einzurichten schreiben wir als Spalte in unsere select-Anweisung. In unserem Fall möchten wir in einer Gruppe von E-Mails, die auf unsere Seite zugreifen, wissen, wie viele Klicks jeder E-Mail-Anbieter seit Anfang August verbucht hat. Wir möchten auch einen einzelnen E-Mail-Dienstleister mit den anderen vergleichen. In diesem Beispiel verwenden wir Google Mail als Dienstanbieter.
In unserem SELECT -Anweisung benötigen wir das DATE , der PROVIDER und die SUM der CLICKS zu unserer Seite. Diese können wir den TEST E MAILS entnehmen Tabelle in unserer Datenquelle.
Das DATE Spalte ist ziemlich einfach:
"Test E Mails"."Created_Date" AS "DATE
Und da wir nach der SUM suchen der CLICKS , müssen wir eine SUM umwandeln Funktion über die CLICKS Spalte.
SUM("Test E Mails"."Clicks") AS "CLICKS"
Das bringt uns zu unserem CASE STATEMENT . Wir wissen aus der PostgreSQL-Dokumentation, dass ein CASE STATEMENT oder eine bedingte Anweisung wie folgt aufgebaut sein muss:
CASE
WHEN condition THEN result
[WHEN ...]
[ELSE result]
END
Unsere erste und in diesem Fall einzige Bedingung ist, dass wir wissen wollen, dass alle E-Mail-Adressen, die von Gmail bereitgestellt werden, von allen anderen E-Mail-Anbietern getrennt werden. Also das einzige WHEN ist:
WHEN "Test E Mails"."Provider" = 'Gmail' THEN 'Gmail'
Und die else-Anweisung wäre für jeden anderen E-Mail-Adressanbieter „Andere“. Die resultierende Tabelle dieses CASE STATEMENT allein mit entsprechenden E-Mails. Würde so aussehen:
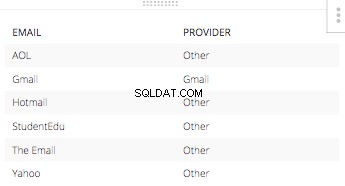
Wenn Sie alle drei dieser Spalten zu einem SELECT STATEMENT zusammenfügen und fügen Sie den Rest der notwendigen Teile hinzu, um eine SQL-Abfrage zu erstellen, alles nimmt unten Gestalt an.
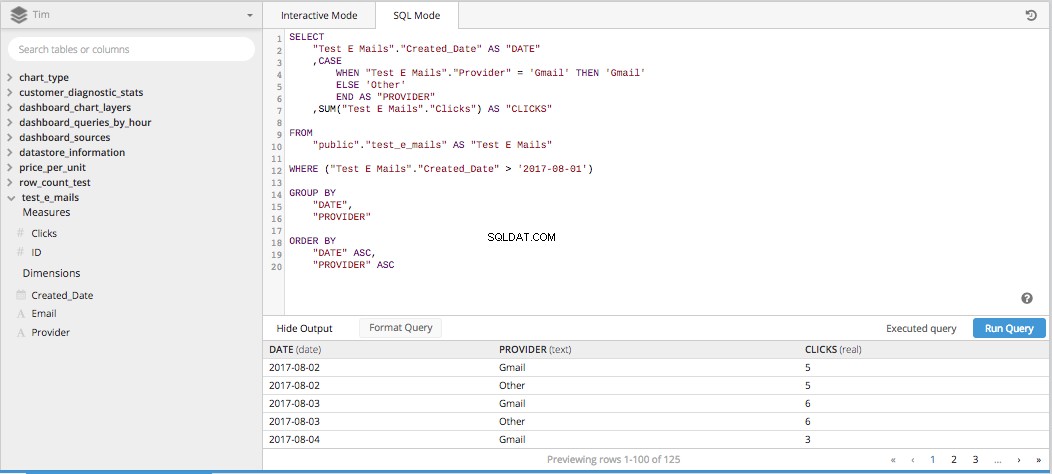
Dann nach dem Hinzufügen von PIVOT DATA Wenn Sie in die Datenpipeline einsteigen, erhalten wir eine ordnungsgemäß angeordnete Tabelle im richtigen Format, um ein Liniendiagramm zu erstellen, das zeigt, wie Klicks im Zeitverlauf verglichen werden.
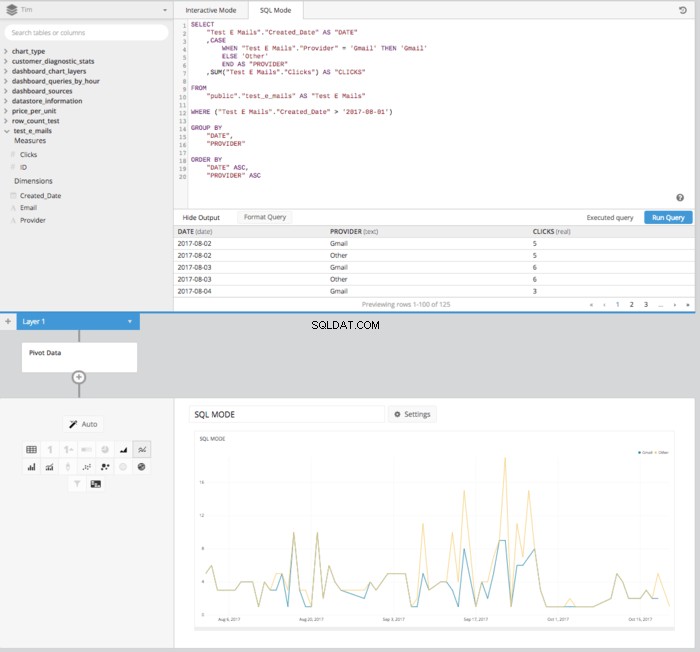
Bei der Verwendung von Chartio können wir all dies tun, ohne SQL zu schreiben, sondern den Daten-Explorer und die Datenpipeline-Funktionen nutzen. Nachdem wir unsere zugrunde liegende Abfrage zum Abrufen aller Spalten erstellt haben, benötigen wir SUM OF CLICKS , DATE und EMAIL ADDRESS Wir können die Datenpipeline verwenden, um diese Daten nach SQL zu manipulieren. Lassen Sie uns zuerst die Abfrage erstellen.
Ziehen Sie die Spalte „Klicks“ in das Feld „Kennzahlen“ und aggregieren Sie sie nach TOTAL SUM der Spalte "Klicks" und benenne sie dann um in "KLICKS".
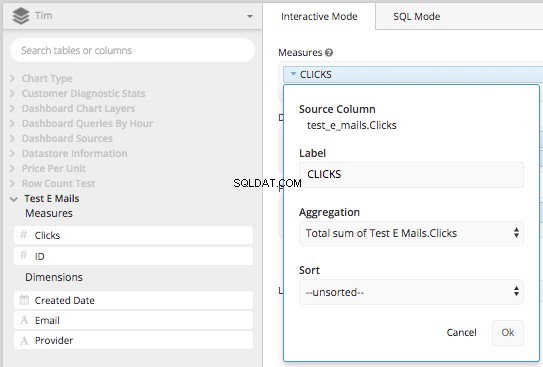
Ziehen Sie dann „Erstellungsdatum“ und „Anbieter“ in das Feld „Dimensionen“ und beschriften Sie sie mit „Datum“ und „E-Mail-Anbieter“. Danach können Sie mithilfe der Spalte „Erstellungsdatum“ die Zeitspanne festlegen (oder Ihre WHERE Klausel) nach dem 01.08.2017 alles sein. Dadurch wird effektiv alles erstellt, was wir in einer zugrunde liegenden Abfrage benötigen, um das CASE STATEMENT zu erstellen wie oben in der Datenpipeline von Chartio.
Hinzufügen einer CASE STATEMENT Pipeline-Schritt ermöglicht es uns, die Bedingungen für WHEN festzulegen und das ELSE genau wie zuvor, ohne die gesamte SQL-Syntax eingeben zu müssen.
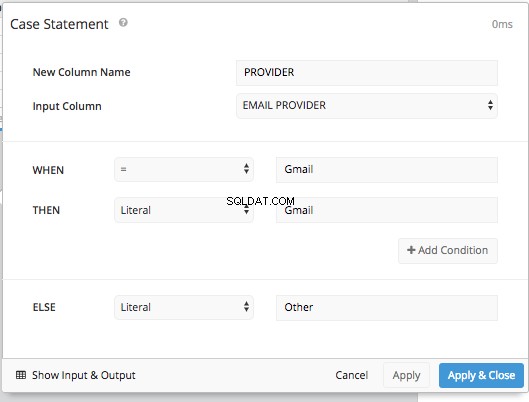
Dann, nachdem Sie die ursprüngliche Spalte „Provider“ ausgeblendet und einen REORDER COLUMNS verwendet haben Schritt und PIVOT DATA Schritt erhalten wir dieselbe Tabellenanordnung wie im SQL-Modus und können dieselbe Tabelle präsentieren wie im SQL-Modus.
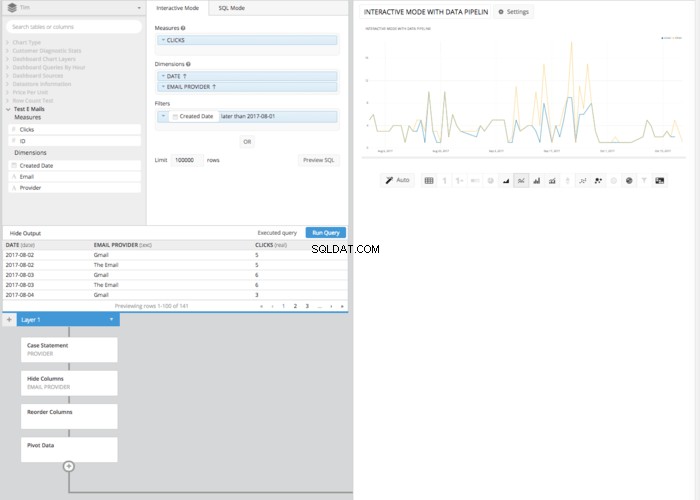
Auch wenn einige Klicks und Schritte mehr erforderlich sind als im SQL-Modus, erfordert das resultierende Liniendiagramm, das im interaktiven Modus erstellt wird, keine Kenntnisse der SQL-Syntax. Stattdessen ist lediglich ein grundlegendes Verständnis der beteiligten Prinzipien erforderlich. Dies ist ein weiteres Beispiel dafür, wie Chartio dazu beiträgt, die Macht der Daten in die Hände aller zu legen, unabhängig von SQL-Kenntnissen.