Das Konzept von gutem oder schlechtem Design ist relativ. Gleichzeitig gibt es einige Programmierstandards, die in den meisten Fällen Effektivität, Wartbarkeit und Testbarkeit garantieren. In objektorientierten Sprachen ist dies beispielsweise die Verwendung von Kapselung, Vererbung und Polymorphismus. Es gibt eine Reihe von Entwurfsmustern, die sich je nach Situation in einigen Fällen positiv oder negativ auf das Anwendungsdesign auswirken. Auf der anderen Seite gibt es Gegensätze, deren Befolgung manchmal zum Problemdesign führt.
Dieses Design hat normalerweise die folgenden Indikatoren (einen oder mehrere gleichzeitig):
- Starrheit (es ist schwierig, den Code zu ändern, da eine einfache Änderung viele Stellen betrifft);
- Immobilität (es ist kompliziert, den Code in Module aufzuteilen, die in anderen Programmen verwendet werden können);
- Viskosität (es ist ziemlich schwierig, den Code zu entwickeln oder zu testen);
- Unnötige Komplexität (es gibt eine ungenutzte Funktionalität im Code);
- Unnötige Wiederholung (Kopieren/Einfügen);
- Schlechte Lesbarkeit (es ist schwierig zu verstehen, wofür der Code entwickelt wurde, und ihn zu pflegen);
- Zerbrechlichkeit (es ist leicht, die Funktionalität sogar mit kleinen Änderungen zu unterbrechen).
Sie müssen in der Lage sein, diese Merkmale zu verstehen und zu unterscheiden, um ein problematisches Design zu vermeiden oder mögliche Folgen seiner Verwendung vorherzusagen. Diese Indikatoren sind im Buch «Agile Principles, Patterns, And Practices in C#» von Robert Martin beschrieben. Allerdings gibt es in diesem Artikel sowie in anderen Übersichtsartikeln eine kurze Beschreibung und keine Codebeispiele.
Wir werden diesen Nachteil beseitigen, indem wir uns mit jeder Funktion befassen.
Steifigkeit
Wie bereits erwähnt, lässt sich ein starrer Code nur schwer ändern, auch nicht in den kleinsten Dingen. Dies ist möglicherweise kein Problem, wenn der Code nicht häufig oder überhaupt nicht geändert wird. Der Code erweist sich also als recht gut. Wenn es jedoch erforderlich ist, den Code zu ändern, und dies schwierig ist, wird dies zu einem Problem, selbst wenn es funktioniert.
Einer der populären Rigiditätsfälle besteht darin, die Klassentypen explizit anzugeben, anstatt Abstraktionen (Schnittstellen, Basisklassen usw.) zu verwenden. Nachfolgend finden Sie ein Beispiel für den Code:
class A
{
B _b;
public A()
{
_b = new B();
}
public void Foo()
{
// Do some custom logic.
_b.DoSomething();
// Do some custom logic.
}
}
class B
{
public void DoSomething()
{
// Do something
}
} Hier hängt Klasse A stark von Klasse B ab. Wenn Sie also in Zukunft eine andere Klasse anstelle von Klasse B verwenden müssen, erfordert dies einen Wechsel der Klasse A und führt zu einer erneuten Prüfung. Außerdem wird die Situation sehr kompliziert, wenn Klasse B andere Klassen beeinflusst.
Der Workaround ist eine Abstraktion, die das IComponent-Interface über den Konstruktor der Klasse A einführt. In diesem Fall hängt es nicht mehr von der jeweiligen Klasse  ab, sondern nur noch vom IComponent-Interface. Die Klasse В muss ihrerseits die IComponent-Schnittstelle implementieren.
interface IComponent
{
void DoSomething();
}
class A
{
IComponent _component;
public A(IComponent component)
{
_component = component;
}
void Foo()
{
// Do some custom logic.
_component.DoSomething();
// Do some custom logic.
}
}
class B : IComponent
{
void DoSomething()
{
// Do something
}
} Lassen Sie uns ein konkretes Beispiel geben. Angenommen, es gibt eine Reihe von Klassen, die die Informationen protokollieren – ProductManager und Consumer. Ihre Aufgabe ist es, ein Produkt in der Datenbank zu hinterlegen und entsprechend zu bestellen. Beide Klassen protokollieren relevante Ereignisse. Stellen Sie sich vor, dass es zuerst ein Protokoll in eine Datei gab. Dazu wurde die Klasse FileLogger verwendet. Außerdem waren die Klassen in verschiedenen Modulen (Assemblies) untergebracht.
// Module 1 (Client)
static void Main()
{
var product = new Product("milk");
var productManager = new ProductManager();
productManager.AddProduct(product);
var consumer = new Consumer();
consumer.PurchaseProduct(product.Name);
}
// Module 2 (Business logic)
public class ProductManager
{
private readonly FileLogger _logger = new FileLogger();
public void AddProduct(Product product)
{
// Add the product to the database.
_logger.Log("The product is added.");
}
}
public class Consumer
{
private readonly FileLogger _logger = new FileLogger();
public void PurchaseProduct(string product)
{
// Purchase the product.
_logger.Log("The product is purchased.");
}
}
public class Product
{
public string Name { get; private set; }
public Product(string name)
{
Name = name;
}
}
// Module 3 (Logger implementation)
public class FileLogger
{
const string FileName = "log.txt";
public void Log(string message)
{
// Write the message to the file.
}
} Wenn es zunächst reichte, nur die Datei zu verwenden, und dann die Anmeldung bei anderen Repositories erforderlich wird, z. B. einer Datenbank oder einem Cloud-basierten Datenerfassungs- und -speicherdienst, müssen wir alle Klassen in der Geschäftslogik ändern Modul (Modul 2), das FileLogger verwendet. Schließlich kann sich das als schwierig herausstellen. Um dieses Problem zu lösen, können wir eine abstrakte Schnittstelle einführen, um mit dem Logger zu arbeiten, wie unten gezeigt.
// Module 1 (Client)
static void Main()
{
var logger = new FileLogger();
var product = new Product("milk");
var productManager = new ProductManager(logger);
productManager.AddProduct(product);
var consumer = new Consumer(logger);
consumer.PurchaseProduct(product.Name);
}
// Module 2 (Business logic)
class ProductManager
{
private readonly ILogger _logger;
public ProductManager(ILogger logger)
{
_logger = logger;
}
public void AddProduct(Product product)
{
// Add the product to the database.
_logger.Log("The product is added.");
}
}
public class Consumer
{
private readonly ILogger _logger;
public Consumer(ILogger logger)
{
_logger = logger;
}
public void PurchaseProduct(string product)
{
// Purchase the product.
_logger.Log("The product is purchased.");
}
}
public class Product
{
public string Name { get; private set; }
public Product(string name)
{
Name = name;
}
}
// Module 3 (interfaces)
public interface ILogger
{
void Log(string message);
}
// Module 4 (Logger implementation)
public class FileLogger : ILogger
{
const string FileName = "log.txt";
public virtual void Log(string message)
{
// Write the message to the file.
}
} In diesem Fall reicht es beim Ändern eines Logger-Typs aus, den Client-Code (Main) zu ändern, der den Logger initialisiert und zum Konstruktor von ProductManager und Consumer hinzufügt. Daher haben wir die Klassen der Geschäftslogik von der Änderung des Loggertyps nach Bedarf ausgeschlossen.
Neben direkten Links zu den verwendeten Klassen können wir bei anderen Varianten eine Starrheit überwachen, die bei Änderungen des Codes zu Schwierigkeiten führen kann. Es kann unendlich viele davon geben. Wir werden jedoch versuchen, ein weiteres Beispiel zu geben. Angenommen, es gibt einen Code, der die Fläche eines geometrischen Musters auf der Konsole anzeigt.
static void Main()
{
var rectangle = new Rectangle() { W = 3, H = 5 };
var circle = new Circle() { R = 7 };
var shapes = new Shape[] { rectangle, circle };
ShapeHelper.ReportShapesSize(shapes);
}
class ShapeHelper
{
private static double GetShapeArea(Shape shape)
{
if (shape is Rectangle)
{
return ((Rectangle)shape).W * ((Rectangle)shape).H;
}
if (shape is Circle)
{
return 2 * Math.PI * ((Circle)shape).R * ((Circle)shape).R;
}
throw new InvalidOperationException("Not supported shape");
}
public static void ReportShapesSize(Shape[] shapes)
{
foreach(Shape shape in shapes)
{
if (shape is Rectangle)
{
double area = GetShapeArea(shape);
Console.WriteLine($"Rectangle's area is {area}");
}
if (shape is Circle)
{
double area = GetShapeArea(shape);
Console.WriteLine($"Circle's area is {area}");
}
}
}
}
public class Shape
{ }
public class Rectangle : Shape
{
public double W { get; set; }
public double H { get; set; }
}
public class Circle : Shape
{
public double R { get; set; }
} Wie Sie sehen können, müssen wir beim Hinzufügen eines neuen Musters die Methoden der ShapeHelper-Klasse ändern. Eine der Optionen besteht darin, den Rendering-Algorithmus in den Klassen geometrischer Muster (Rechteck und Kreis) zu übergeben, wie unten gezeigt. Auf diese Weise werden wir die relevante Logik in den entsprechenden Klassen isolieren und dadurch die Verantwortlichkeit der ShapeHelper-Klasse reduzieren, bevor Informationen auf der Konsole angezeigt werden.
static void Main()
{
var rectangle = new Rectangle() { W = 3, H = 5 };
var circle = new Circle() { R = 7 };
var shapes = new Shape[]() { rectangle, circle };
ShapeHelper.ReportShapesSize(shapes);
}
class ShapeHelper
{
public static void ReportShapesSize(Shape[] shapes)
{
foreach(Shape shape in shapes)
{
shape.Report();
}
}
}
public abstract class Shape
{
public abstract void Report();
}
public class Rectangle : Shape
{
public double W { get; set; }
public double H { get; set; }
public override void Report()
{
double area = W * H;
Console.WriteLine($"Rectangle's area is {area}");
}
}
public class Circle : Shape
{
public double R { get; set; }
public override void Report()
{
double area = 2 * Math.PI * R * R;
Console.WriteLine($"Circle's area is {area}");
}
} Infolgedessen haben wir die ShapeHelper-Klasse tatsächlich für Änderungen geschlossen, die neue Arten von Mustern hinzufügen, indem sie Vererbung und Polymorphismus verwenden.
Immobilität
Wir können die Unbeweglichkeit überwachen, wenn wir den Code in wiederverwendbare Module aufteilen. Dies kann dazu führen, dass sich das Projekt nicht mehr entwickelt und wettbewerbsfähig ist.
Als Beispiel betrachten wir ein Desktop-Programm, dessen gesamter Code in der ausführbaren Anwendungsdatei (.exe) implementiert und so konzipiert wurde, dass die Geschäftslogik nicht in separaten Modulen oder Klassen aufgebaut ist. Später sah sich der Entwickler mit den folgenden geschäftlichen Anforderungen konfrontiert:
- Um die Benutzeroberfläche zu ändern, indem sie in eine Webanwendung umgewandelt wird;
- Um die Funktionalität des Programms als eine Reihe von Webdiensten zu veröffentlichen, die Drittkunden zur Verwendung in ihren eigenen Anwendungen zur Verfügung stehen.
In diesem Fall sind diese Anforderungen nur schwer zu erfüllen, da sich der gesamte Code im ausführbaren Modul befindet.
Das Bild unten zeigt ein Beispiel für ein unbewegliches Design im Gegensatz zu dem, das diesen Indikator nicht hat. Sie sind durch eine Strichlinie getrennt. Wie Sie sehen können, ermöglichen die Zuordnung des Codes zu wiederverwendbaren Modulen (Logic) sowie die Veröffentlichung der Funktionalität auf der Ebene von Webdiensten die Verwendung in verschiedenen Client-Anwendungen (App), was zweifellos ein Vorteil ist.
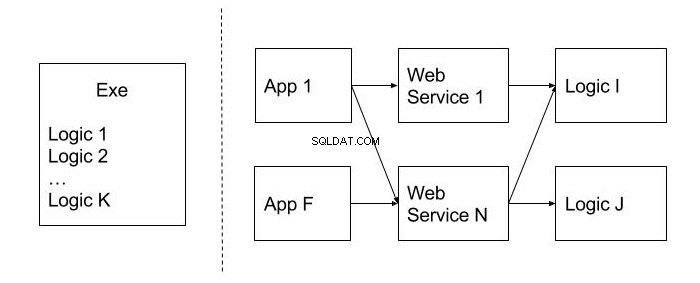
Immobilität kann auch als monolithisches Design bezeichnet werden. Es ist schwierig, ihn in kleinere und nützliche Einheiten des Codes aufzuteilen. Wie können wir diesem Problem ausweichen? In der Entwurfsphase ist es besser, darüber nachzudenken, wie wahrscheinlich es ist, diese oder jene Funktion in anderen Systemen zu verwenden. Der Code, der wiederverwendet werden soll, sollte am besten in separaten Modulen und Klassen platziert werden.
Viskosität
Es gibt zwei Arten:
- Entwicklungsviskosität
- Umgebungsviskosität
Wir können die Entwicklungsviskosität sehen, während wir versuchen, dem ausgewählten Anwendungsdesign zu folgen. Dies kann passieren, wenn ein Programmierer zu viele Anforderungen erfüllen muss, während es einen einfacheren Weg der Entwicklung gibt. Darüber hinaus kann die Entwicklungsviskosität gesehen werden, wenn der Prozess der Montage, Bereitstellung und Prüfung nicht effektiv ist.
Als einfaches Beispiel können wir die Arbeit mit Konstanten betrachten, die (By Design) in einem separaten Modul (Modul 1) platziert werden sollen, um von anderen Komponenten (Modul 2 und Modul 3) verwendet zu werden.
// Module 1 (Constants)
static class Constants
{
public const decimal MaxSalary = 100M;
public const int MaxNumberOfProducts = 100;
}
// Finance Module
#using Module1
static class FinanceHelper
{
public static bool ApproveSalary(decimal salary)
{
return salary <= Constants.MaxSalary;
}
}
// Marketing Module
#using Module1
class ProductManager
{
public void MakeOrder()
{
int productsNumber = 0;
while(productsNumber++ <= Constants.MaxNumberOfProducts)
{
// Purchase some product
}
}
} Wenn der Montageprozess aus irgendeinem Grund viel Zeit in Anspruch nimmt, wird es für Entwickler schwierig sein, zu warten, bis er abgeschlossen ist. Außerdem ist zu beachten, dass das konstante Modul gemischte Entitäten enthält, die zu unterschiedlichen Teilen der Geschäftslogik (Finanz- und Marketingmodul) gehören. Das konstante Modul kann also recht häufig aus voneinander unabhängigen Gründen geändert werden, was zu zusätzlichen Problemen wie der Synchronisierung der Änderungen führen kann.
All dies verlangsamt den Entwicklungsprozess und kann Programmierer stressen. Die Varianten des weniger viskosen Designs wären entweder separate Konstantenmodule zu erstellen – jeweils eines für das entsprechende Modul der Geschäftslogik – oder Konstanten an die richtige Stelle zu übergeben, ohne ein separates Modul dafür zu nehmen.
Ein Beispiel für die Umgebungsviskosität kann die Entwicklung und das Testen der Anwendung auf der virtuellen Remote-Client-Maschine sein. Manchmal wird dieser Arbeitsablauf aufgrund einer langsamen Internetverbindung unerträglich, sodass der Entwickler die Integrationstests des geschriebenen Codes systematisch ignorieren kann, was schließlich zu Fehlern auf der Clientseite führen kann, wenn diese Funktion verwendet wird.
Unnötige Komplexität
In diesem Fall hat das Design tatsächlich ungenutzte Funktionalität. Diese Tatsache kann den Support und die Wartung des Programms erschweren sowie die Entwicklungs- und Testzeit verlängern. Betrachten Sie zum Beispiel das Programm, das das Lesen einiger Daten aus der Datenbank erfordert. Dazu wurde die DataManager-Komponente erstellt, die in einer anderen Komponente verwendet wird.
class DataManager
{
object[] GetData()
{
// Retrieve and return data
}
} Wenn der Entwickler DataManager eine neue Methode hinzufügt, um Daten in die Datenbank zu schreiben (WriteData), die in Zukunft wahrscheinlich nicht verwendet wird, dann wird es auch eine unnötige Komplexität sein.
Ein weiteres Beispiel ist eine Schnittstelle für alle Zwecke. Zum Beispiel werden wir eine Schnittstelle mit der einzelnen Process-Methode betrachten, die ein Objekt des String-Typs akzeptiert.
interface IProcessor
{
void Process(string message);
} Wenn die Aufgabe darin bestünde, einen bestimmten Nachrichtentyp mit einer wohldefinierten Struktur zu verarbeiten, wäre es einfacher, eine strikt typisierte Schnittstelle zu erstellen, als Entwickler diese Zeichenfolge jedes Mal in einen bestimmten Nachrichtentyp deserialisieren zu lassen.
Die übermäßige Verwendung von Designmustern in Fällen, in denen dies überhaupt nicht erforderlich ist, kann ebenfalls zu einem viskosen Design führen.
Warum Ihre Zeit damit verschwenden, einen möglicherweise ungenutzten Code zu schreiben? Manchmal muss QA diesen Code testen, da er tatsächlich veröffentlicht und für die Verwendung durch Clients von Drittanbietern offen ist. Das verschiebt auch den Release-Zeitpunkt. Ein Feature für die Zukunft aufzunehmen lohnt sich nur, wenn sein möglicher Nutzen die Kosten für seine Entwicklung und Tests übersteigt.
Unnötige Wiederholung
Vielleicht sind die meisten Entwickler mit dieser Funktion konfrontiert oder werden darauf stoßen, die darin besteht, dieselbe Logik oder denselben Code mehrfach zu kopieren. Die Hauptbedrohung ist die Schwachstelle dieses Codes beim Ändern – wenn Sie etwas an einer Stelle reparieren, vergessen Sie möglicherweise, dies an einer anderen zu tun. Außerdem dauert es länger, Änderungen vorzunehmen, als wenn der Code diese Funktion nicht enthält.
Unnötige Wiederholungen können auf die Nachlässigkeit der Entwickler zurückzuführen sein, aber auch auf die Starrheit/Zerbrechlichkeit des Designs, wenn es viel schwieriger und riskanter ist, den Code nicht zu wiederholen, als dies zu tun. In jedem Fall ist Wiederholbarkeit jedoch keine gute Idee, und es ist notwendig, den Code ständig zu verbessern, indem wiederverwendbare Teile an gemeinsame Methoden und Klassen übergeben werden.
Schlechte Lesbarkeit
Sie können diese Funktion überwachen, wenn es schwierig ist, einen Code zu lesen und zu verstehen, wofür er erstellt wurde. Gründe für eine schlechte Lesbarkeit können die Nichteinhaltung der Anforderungen an die Codeausführung (Syntax, Variablen, Klassen), eine komplizierte Implementierungslogik etc. sein.
Unten finden Sie das Beispiel des schwer lesbaren Codes, der die Methode mit der booleschen Variablen implementiert.
void Process_true_false(string trueorfalsevalue)
{
if (trueorfalsevalue.ToString().Length == 4)
{
// That means trueorfalsevalue is probably "true". Do something here.
}
else if (trueorfalsevalue.ToString().Length == 5)
{
// That means trueorfalsevalue is probably "false". Do something here.
}
else
{
throw new Exception("not true of false. that's not nice. return.")
}
} Hier können wir mehrere Probleme skizzieren. Erstens entsprechen Namen von Methoden und Variablen nicht den allgemein akzeptierten Konventionen. Zweitens ist die Implementierung der Methode nicht die beste.
Vielleicht lohnt es sich, statt einer Zeichenfolge einen booleschen Wert zu nehmen. Es ist jedoch besser, ihn zu Beginn der Methode in einen booleschen Wert umzuwandeln, anstatt die Methode zur Bestimmung der Länge des Strings zu verwenden.
Drittens entspricht der Ausnahmetext nicht dem amtlichen Stil. Wenn man solche Texte liest, kann man das Gefühl haben, dass der Code von einem Amateur erstellt wurde (trotzdem kann es einen strittigen Punkt geben). Die Methode könnte wie folgt umgeschrieben werden, wenn sie einen booleschen Wert annimmt:
public void Process(bool value)
{
if (value)
{
// Do something.
}
else
{
// Do something.
}
} Hier ist ein weiteres Beispiel für Refactoring, wenn Sie immer noch einen String nehmen müssen:
public void Process(string value)
{
bool bValue = false;
if (!bool.TryParse(value, out bValue))
{
throw new ArgumentException($"The {value} is not boolean");
}
if (bValue)
{
// Do something.
}
else
{
// Do something.
}
} Es wird empfohlen, Refactoring mit dem schwer lesbaren Code durchzuführen, beispielsweise wenn seine Wartung und das Klonen zu mehreren Fehlern führen.
Zerbrechlichkeit
Fragilität eines Programms bedeutet, dass es leicht zum Absturz gebracht werden kann, wenn es modifiziert wird. Es gibt zwei Arten von Abstürzen:Kompilierungsfehler und Laufzeitfehler. Die ersten können eine Kehrseite der Starrheit sein. Letztere sind am gefährlichsten, da sie auf der Client-Seite auftreten. Sie sind also ein Indikator für die Fragilität.
Zweifellos ist der Indikator relativ. Jemand repariert den Code sehr sorgfältig und die Wahrscheinlichkeit seines Absturzes ist ziemlich gering, während andere dies in Eile und nachlässig tun. Dennoch kann ein anderer Code mit denselben Benutzern eine unterschiedliche Anzahl von Fehlern verursachen. Wahrscheinlich können wir sagen, dass der Code umso fragiler ist, je schwieriger es ist, den Code zu verstehen und sich auf die Ausführungszeit des Programms zu verlassen, anstatt auf die Kompilierungsphase.
Darüber hinaus stürzt die Funktionalität, die nicht geändert werden soll, häufig ab. Es kann unter der hohen Kopplung der Logik verschiedener Komponenten leiden.
Betrachten Sie das spezielle Beispiel. Hier befindet sich die Logik der Benutzerautorisierung mit einer bestimmten Rolle (definiert als gerollter Parameter) für den Zugriff auf eine bestimmte Ressource (definiert als resourceUri) in der statischen Methode.
static void Main()
{
if (Helper.Authorize(1, "/pictures"))
{
Console.WriteLine("Authorized");
}
}
class Helper
{
public static bool Authorize(int roleId, string resourceUri)
{
if (roleId == 1 || roleId == 10)
{
if (resourceUri == "/pictures")
{
return true;
}
}
if (roleId == 1 || roleId == 2 && resourceUri == "/admin")
{
return true;
}
return false;
}
} Wie Sie sehen können, ist die Logik kompliziert. Es ist offensichtlich, dass das Hinzufügen neuer Rollen und Ressourcen es leicht brechen wird. Infolgedessen kann eine bestimmte Rolle Zugriff auf eine Ressource erhalten oder verlieren. Das Erstellen der Ressourcenklasse, die intern die Ressourcenkennung und die Liste der unterstützten Rollen speichert, wie unten gezeigt, würde die Anfälligkeit verringern.
static void Main()
{
var picturesResource = new Resource() { Uri = "/pictures" };
picturesResource.AddRole(1);
if (picturesResource.IsAvailable(1))
{
Console.WriteLine("Authorized");
}
}
class Resource
{
private List<int> _roles = new List<int>();
public string Uri { get; set; }
public void AddRole(int roleId)
{
_roles.Add(roleId);
}
public void RemoveRole(int roleId)
{
_roles.Remove(roleId);
}
public bool IsAvailable(int roleId)
{
return _roles.Contains(roleId);
}
} In diesem Fall ist es zum Hinzufügen neuer Ressourcen und Rollen nicht erforderlich, den Autorisierungslogikcode überhaupt zu ändern, d. h. es gibt eigentlich nichts zu brechen.
Was kann helfen, Laufzeitfehler abzufangen? Die Antwort ist manuelles, automatisches und Unit-Testing. Je besser der Testprozess organisiert ist, desto wahrscheinlicher ist es, dass der fragile Code auf der Client-Seite auftritt.
Fragilität ist oft eine Kehrseite anderer Erkennungsmerkmale für schlechtes Design, z. B. Starrheit, schlechte Lesbarkeit und unnötige Wiederholungen.
Schlussfolgerung
Wir haben versucht, die Hauptkennzeichen für schlechtes Design zu skizzieren und zu beschreiben. Einige von ihnen sind voneinander abhängig. Sie müssen verstehen, dass das Thema Design nicht immer zwangsläufig zu Schwierigkeiten führt. Es weist nur darauf hin, dass sie auftreten können. Je weniger diese Kennungen überwacht werden, desto geringer ist diese Wahrscheinlichkeit.