Die häufigste Notwendigkeit, die Zeit aus einem datetime-Wert zu entfernen, besteht darin, alle Zeilen abzurufen, die Bestellungen (oder Besuche oder Unfälle) darstellen, die an einem bestimmten Tag aufgetreten sind. Allerdings sind nicht alle Techniken, die dazu verwendet werden, effizient oder gar sicher.
TL;DR-Version
Wenn Sie eine sichere Bereichsabfrage mit guter Leistung wünschen, verwenden Sie einen offenen Bereich oder verwenden Sie CONVERT(DATE) für eintägige Abfragen auf SQL Server 2008 und höher :
DECLARE @today DATETIME; -- only on <= 2005: SET @today = DATEADD(DAY, DATEDIFF(DAY, '20000101', CURRENT_TIMESTAMP), '20000101'); -- or on 2008 and above: SET @today = CONVERT(DATE, CURRENT_TIMESTAMP); -- and then use an open-ended range in the query: ... WHERE OrderDate >= @today AND OrderDate < DATEADD(DAY, 1, @today); -- you can also do this (again, in SQL Server 2008 and above): ... WHERE CONVERT(DATE, OrderDate) = @today;
Einige Vorbehalte:
- Seien Sie vorsichtig mit dem
DATEDIFFAnsatz, da einige Anomalien bei der Kardinalitätsschätzung auftreten können (weitere Informationen finden Sie in diesem Blogbeitrag und der Stack Overflow-Frage, die ihn dazu veranlasst hat). - Während der letzte möglicherweise immer noch eine Indexsuche verwendet (im Gegensatz zu allen anderen nicht sargbaren Ausdrücken, auf die ich je gestoßen bin), müssen Sie vorsichtig sein, wenn Sie die Spalte vor dem Vergleichen in ein Datum konvertieren. Auch dieser Ansatz kann zu grundlegend falschen Kardinalitätsschätzungen führen. Weitere Einzelheiten finden Sie in dieser Antwort von Martin Smith.
Lesen Sie auf jeden Fall weiter, um zu verstehen, warum dies die einzigen beiden Ansätze sind, die ich jemals empfehle.
Nicht alle Ansätze sind sicher
Als unsicheres Beispiel sehe ich dieses hier oft verwendet:
WHERE OrderDate BETWEEN DATEDIFF(DAY, 0, GETDATE()) AND DATEADD(MILLISECOND, -3, DATEDIFF(DAY, 0, GETDATE()) + 1);
Es gibt ein paar Probleme mit diesem Ansatz, aber das bemerkenswerteste ist die Berechnung des „Endes“ von heute – wenn der zugrunde liegende Datentyp SMALLDATETIME ist , dieser Endbereich wird aufgerundet; wenn es DATETIME2 ist , könnten Ihnen am Ende des Tages theoretisch Daten entgehen. Wenn Sie Minuten oder Nanosekunden oder eine andere Lücke auswählen, um den aktuellen Datentyp aufzunehmen, wird Ihre Abfrage ein seltsames Verhalten zeigen, sollte sich der Datentyp später jemals ändern (und seien wir ehrlich, wenn jemand den Typ dieser Spalte ändert, um mehr oder weniger granular zu sein, sie laufen nicht herum und überprüfen jede einzelne Abfrage, die darauf zugreift). Je nach Art der Datums-/Uhrzeitdaten in der zugrunde liegenden Spalte auf diese Weise codieren zu müssen, ist fragmentiert und fehleranfällig. Es ist viel besser, dafür offene Datumsbereiche zu verwenden:
Ich spreche viel mehr darüber in ein paar alten Blogbeiträgen:
- Was haben BETWEEN und der Teufel gemeinsam?
- Bad Habits to Kick:Misshandlung von Datums-/Bereichsabfragen
Aber ich wollte die Leistung einiger der gebräuchlicheren Ansätze vergleichen, die ich da draußen sehe. Ich habe immer offene Bereiche verwendet, und seit SQL Server 2008 können wir CONVERT(DATE) verwenden und trotzdem einen Index für diese Spalte verwenden, was ziemlich leistungsfähig ist.
SELECT CONVERT(CHAR(8), CURRENT_TIMESTAMP, 112); SELECT CONVERT(CHAR(10), CURRENT_TIMESTAMP, 120); SELECT CONVERT(DATE, CURRENT_TIMESTAMP); SELECT DATEADD(DAY, DATEDIFF(DAY, '19000101', CURRENT_TIMESTAMP), '19000101'); SELECT CONVERT(DATETIME, DATEDIFF(DAY, '19000101', CURRENT_TIMESTAMP)); SELECT CONVERT(DATETIME, CONVERT(INT, CONVERT(FLOAT, CURRENT_TIMESTAMP))); SELECT CONVERT(DATETIME, FLOOR(CONVERT(FLOAT, CURRENT_TIMESTAMP)));
Ein einfacher Leistungstest
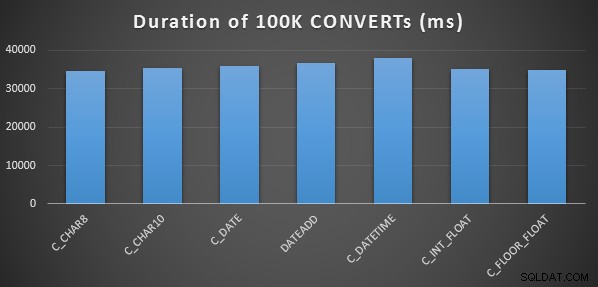
Um einen sehr einfachen anfänglichen Leistungstest durchzuführen, habe ich für jede der obigen Anweisungen Folgendes getan, wobei ich 100.000 Mal eine Variable auf die Ausgabe der Berechnung gesetzt habe:
SELECT SYSDATETIME(); GO DECLARE @d DATETIME = [conversion method]; GO 100000 SELECT SYSDATETIME(); GO
Ich habe dies dreimal für jede Methode gemacht, und sie liefen alle im Bereich von 34 bis 38 Sekunden. Genau genommen gibt es bei diesen Methoden also sehr vernachlässigbare Unterschiede bei der Durchführung der Operationen im Speicher:
Ein aufwändigerer Leistungstest
Außerdem wollte ich diese Methoden mit unterschiedlichen Datentypen vergleichen (DATETIME , SMALLDATETIME , und DATETIME2 ), sowohl gegen einen gruppierten Index als auch gegen einen Heap und mit und ohne Datenkomprimierung. Also habe ich zuerst eine einfache Datenbank erstellt. Durch Experimentieren habe ich festgestellt, dass die optimale Größe für die Verarbeitung von 120 Millionen Zeilen und allen möglicherweise auftretenden Protokollaktivitäten (und um zu verhindern, dass automatische Vergrößerungsereignisse den Test stören) eine 20-GB-Datendatei und ein 3-GB-Protokoll ist:
CREATE DATABASE [Datetime_Testing] ON PRIMARY ( NAME = N'Datetime_Testing_Data', FILENAME = N'D:\DATA\Datetime_Testing.mdf', SIZE = 20480000KB , MAXSIZE = UNLIMITED, FILEGROWTH = 102400KB ) LOG ON ( NAME = N'Datetime_Testing_Log', FILENAME = N'E:\LOGS\Datetime_Testing_log.ldf', SIZE = 3000000KB , MAXSIZE = UNLIMITED, FILEGROWTH = 20480KB );
Als nächstes habe ich 12 Tabellen erstellt:
-- clustered index with no compression: CREATE TABLE dbo.smalldatetime_nocompression_clustered(dt SMALLDATETIME); CREATE CLUSTERED INDEX x ON dbo.smalldatetime_nocompression_clustered(dt); -- heap with no compression: CREATE TABLE dbo.smalldatetime_nocompression_heap(dt SMALLDATETIME); -- clustered index with page compression: CREATE TABLE dbo.smalldatetime_compression_clustered(dt SMALLDATETIME) WITH (DATA_COMPRESSION = PAGE); CREATE CLUSTERED INDEX x ON dbo.smalldatetime_compression_clustered(dt) WITH (DATA_COMPRESSION = PAGE); -- heap with page compression: CREATE TABLE dbo.smalldatetime_compression_heap(dt SMALLDATETIME) WITH (DATA_COMPRESSION = PAGE);
[Wiederholen Sie dann erneut für DATETIME und DATETIME2.]
Als nächstes fügte ich 10.000.000 Zeilen in jede Tabelle ein. Dazu habe ich eine Ansicht erstellt, die jedes Mal dieselben 10.000.000 Daten generiert:
CREATE VIEW dbo.TenMillionDates AS SELECT TOP (10000000) d = DATEADD(MINUTE, ROW_NUMBER() OVER (ORDER BY s1.[object_id]), '19700101') FROM sys.all_columns AS s1 CROSS JOIN sys.all_objects AS s2 ORDER BY s1.[object_id];
Dadurch konnte ich die Tabellen folgendermaßen füllen:
INSERT /* dt_comp_clus */ dbo.datetime_compression_clustered(dt) SELECT CONVERT(DATETIME, d) FROM dbo.TenMillionDates; CHECKPOINT; INSERT /* dt2_comp_clus */ dbo.datetime2_compression_clustered(dt) SELECT CONVERT(DATETIME2, d) FROM dbo.TenMillionDates; CHECKPOINT; INSERT /* sdt_comp_clus */ dbo.smalldatetime_compression_clustered(dt) SELECT CONVERT(SMALLDATETIME, d) FROM dbo.TenMillionDates; CHECKPOINT;
[Wiederholen Sie dann erneut für die Heaps und den nicht komprimierten gruppierten Index. Ich habe einen CHECKPOINT gesetzt zwischen jedem Einfügen, um die Wiederverwendung des Protokolls sicherzustellen (das Wiederherstellungsmodell ist einfach).]
INSERT Timings &Space Used
Hier sind die Zeiten für jede Einfügung (wie mit Plan Explorer erfasst):
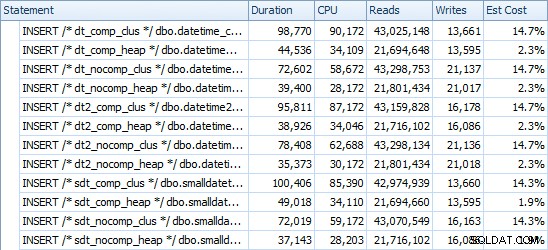
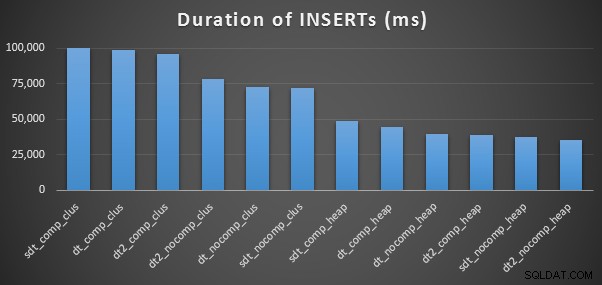
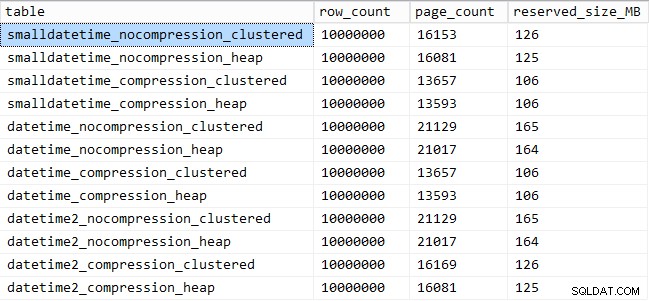
Und hier ist der Speicherplatz, den jede Tabelle einnimmt:
SELECT [table] = OBJECT_NAME([object_id]), row_count, page_count = reserved_page_count, reserved_size_MB = reserved_page_count * 8/1024 FROM sys.dm_db_partition_stats WHERE OBJECT_NAME([object_id]) LIKE '%datetime%';
Suchmusterleistung
Als Nächstes habe ich mich daran gemacht, zwei verschiedene Abfragemuster auf Leistung zu testen:
- Zählen der Zeilen für einen bestimmten Tag unter Verwendung der oben genannten sieben Ansätze sowie des offenen Datumsbereichs
- Konvertieren aller 10.000.000 Zeilen mit den oben genannten sieben Ansätzen sowie nur Zurückgeben der Rohdaten (da die Formatierung auf der Clientseite möglicherweise besser ist)
[Mit Ausnahme von FLOAT Methoden und DATETIME2 Spalte, da diese Umwandlung nicht legal ist.]
Für die erste Frage sehen die Abfragen so aus (für jeden Tabellentyp wiederholt):
SELECT /* C_CHAR10 - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(CHAR(10), dt, 120) = '19860301';
SELECT /* C_CHAR8 - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(CHAR(8), dt, 112) = '19860301';
SELECT /* C_FLOOR_FLOAT - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATETIME, FLOOR(CONVERT(FLOAT, dt))) = '19860301';
SELECT /* C_DATETIME - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATETIME, DATEDIFF(DAY, '19000101', dt)) = '19860301';
SELECT /* C_DATE - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATE, dt) = '19860301';
SELECT /* C_INT_FLOAT - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATETIME, CONVERT(INT, CONVERT(FLOAT, dt))) = '19860301';
SELECT /* DATEADD - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE DATEADD(DAY, DATEDIFF(DAY, '19000101', dt), '19000101') = '19860301';
SELECT /* RANGE - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE dt >= '19860301' AND dt < '19860302'; Die Ergebnisse für einen gruppierten Index sehen so aus (zum Vergrößern klicken):
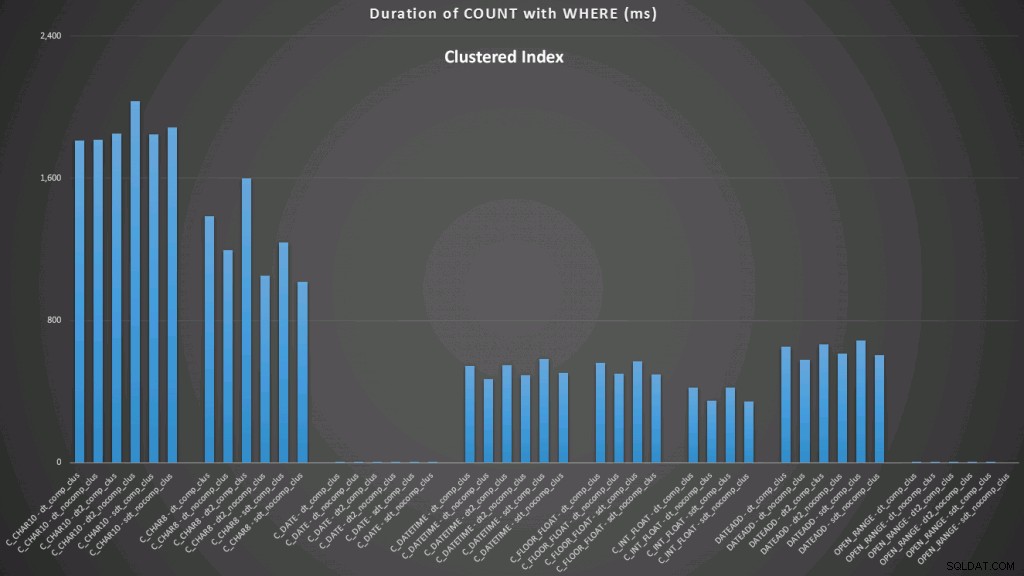
Hier sehen wir, dass die bisherige Konvertierung und die offene Spanne mit einem Index die besten Performer sind. Im Gegensatz zu einem Haufen dauert die Konvertierung in das Datum jedoch tatsächlich einige Zeit, sodass der offene Bereich die optimale Wahl ist (zum Vergrößern klicken):
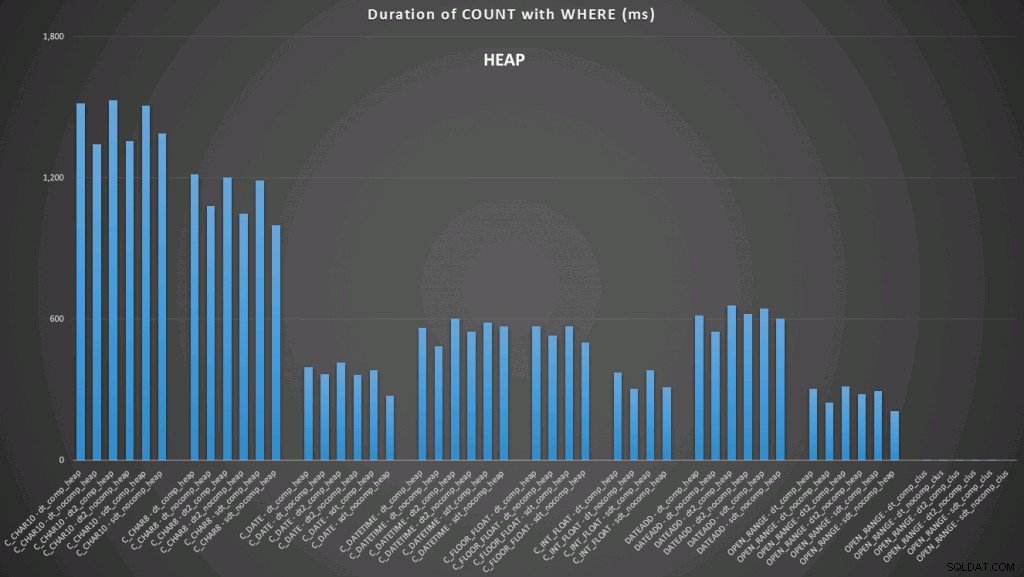
Und hier sind die zweiten Abfragen (wiederum für jeden Tabellentyp wiederholen):
SELECT /* C_CHAR10 - dt_comp_clus */ dt = CONVERT(CHAR(10), dt, 120)
FROM dbo.datetime_compression_clustered;
SELECT /* C_CHAR8 - dt_comp_clus */ dt = CONVERT(CHAR(8), dt, 112)
FROM dbo.datetime_compression_clustered;
SELECT /* C_FLOOR_FLOAT - dt_comp_clus */ dt = CONVERT(DATETIME, FLOOR(CONVERT(FLOAT, dt)))
FROM dbo.datetime_compression_clustered;
SELECT /* C_DATETIME - dt_comp_clus */ dt = CONVERT(DATETIME, DATEDIFF(DAY, '19000101', dt))
FROM dbo.datetime_compression_clustered;
SELECT /* C_DATE - dt_comp_clus */ dt = CONVERT(DATE, dt)
FROM dbo.datetime_compression_clustered;
SELECT /* C_INT_FLOAT - dt_comp_clus */ dt = CONVERT(DATETIME, CONVERT(INT, CONVERT(FLOAT, dt)))
FROM dbo.datetime_compression_clustered;
SELECT /* DATEADD - dt_comp_clus */ dt = DATEADD(DAY, DATEDIFF(DAY, '19000101', dt), '19000101')
FROM dbo.datetime_compression_clustered;
SELECT /* RAW - dt_comp_clus */ dt
FROM dbo.datetime_compression_clustered; Wenn man sich auf die Ergebnisse für Tabellen mit einem gruppierten Index konzentriert, ist klar, dass die bisherige Konvertierung sehr nah dran war, nur die Rohdaten auszuwählen (zum Vergrößern klicken):
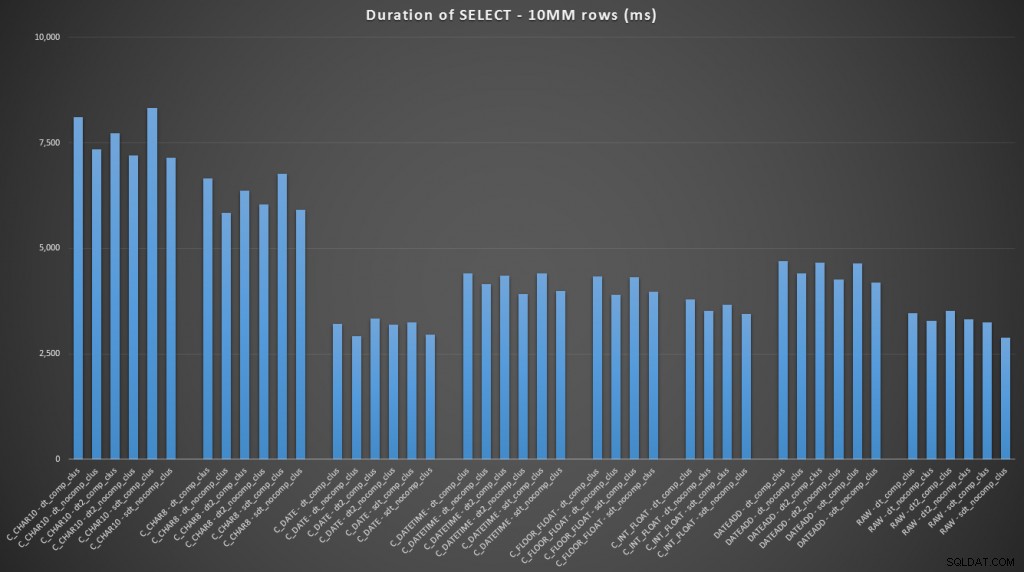
(Für diese Reihe von Abfragen zeigte der Heap sehr ähnliche Ergebnisse – praktisch nicht zu unterscheiden.)
Schlussfolgerung
Falls Sie zur Pointe springen wollten, zeigen diese Ergebnisse, dass Konvertierungen im Speicher nicht wichtig sind, aber wenn Sie Daten auf dem Weg aus einer Tabelle (oder als Teil eines Suchprädikats) konvertieren, kann die von Ihnen gewählte Methode verwendet werden einen dramatischen Einfluss auf die Leistung. Konvertieren in ein DATE (für einen einzelnen Tag) oder die Verwendung eines offenen Datumsbereichs wird in jedem Fall die beste Leistung erzielen, während die beliebteste Methode da draußen – die Umwandlung in eine Zeichenfolge – absolut miserabel ist.
Wir sehen auch, dass die Komprimierung eine anständige Auswirkung auf den Speicherplatz haben kann, mit sehr geringen Auswirkungen auf die Abfrageleistung. Die Auswirkung auf die Einfügeleistung scheint eher davon abhängig zu sein, ob die Tabelle einen gruppierten Index hat oder nicht, als ob die Komprimierung aktiviert ist oder nicht. Mit einem Clustered-Index gab es jedoch einen deutlichen Anstieg in der Dauer, die zum Einfügen von 10 Millionen Zeilen benötigt wurde. Etwas, das Sie im Hinterkopf behalten und mit Speicherplatzeinsparungen ausgleichen sollten.
Natürlich könnten viel mehr Tests mit umfangreicheren und vielfältigeren Arbeitslasten erforderlich sein, die ich in einem zukünftigen Beitrag weiter untersuchen werde.